
「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
バックナンバーはこちら

はじめに
マルチモーダルとは、画像とテキストのように異なる情報様式(モード)を 一つの意味空間 で扱い、横断的な推論や生成を実現する技術である。G検定の文脈では、基盤モデルを起点に、共有表現、マルチタスク学習、Zero-shot、そして具体的タスクと代表モデルへと連なる 因果の流れ をつかむことが要諦である。本稿はその流れを叙述で追い、節ごとに因果関係図の該当部を参照することで、単なる用語集から一歩進んだ理解を与えることを目指す。
動画シリーズ
G検定の究極カンペ関連動画の再生リスト

説明内容
まず概念の地盤を整え、そこからタスクの風景を見渡し、代表モデルの性格を見極め、最後に活用例で地に足をつける。順序は 概念 → タスク → 代表モデル → 活用例 である。各節は相互に独立して読めるが、通読すれば因果の鎖が一本に結び直される構成になっている。
- 概念(基盤モデル/マルチモーダル表現/マルチタスク学習/Zero-shot)
- タスク(画像キャプション/テキスト→画像生成/視覚質問応答 ほか)
- 代表モデル(CLIP/DALL·E/Flamingo/Unified-IO)
- 活用例(検索/クリエイティブ/アクセシビリティ/ロボティクス/Eコマース/医療)
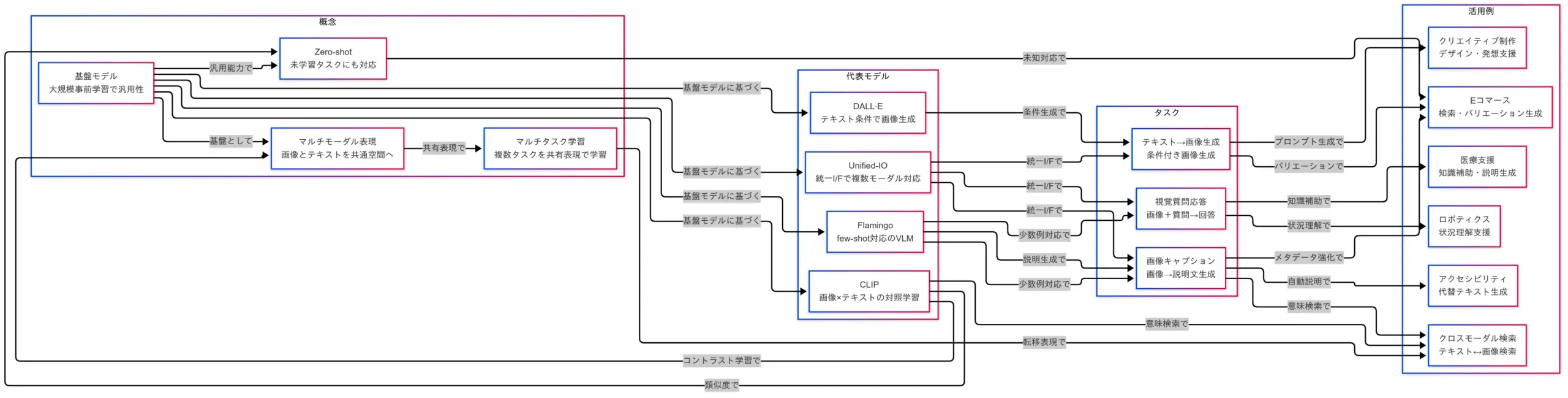
概念
マルチモーダル時代の主役は 基盤モデル である。大規模事前学習により獲得した一般知を、画像・テキストなど複数モーダルにまたがって適用できる。ここで重要なのは、モデルが単に入力形式を増やすのではなく、同一の尺度で比較可能な“共有表現”を内部に持つ点である。画像中の「猫」と単語の「cat」が、統一ベクトル空間で近接するという比喩は、その核心をうまく伝える。
共有表現が確立すると、学習は マルチタスク へと自然に拡張される。キャプション生成や質問応答など異なる課題が、同じ表現を介して相互に栄養を与え合うからである。さらに、この表現の一般性は Zero-shot 能力として現れる。見たことのない指示や概念に対しても、既存の意味座標を辿って妥当な出力に至るのである。
すなわち、基盤モデル → 共有表現 → マルチタスク学習 → Zero-shot という順に、汎用性の梯子を上がっていく構図である。
ここでの最小要点
- 共有表現は“モードをまたぐ共通言語”である。
- マルチタスクは表現の使い回しによって汎化を促す。
- Zero-shotは表現の地図を頼りに未知へ踏み出す力である。
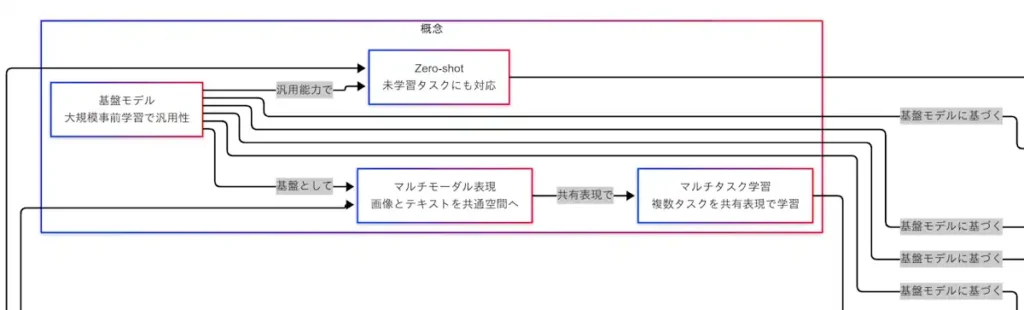
タスク
の地盤の上に、具体的なタスクが生まれる。画像キャプション は視覚から言語へ橋を架け、テキスト→画像生成 は言語から視覚へ橋を架ける。視覚質問応答(VQA)は両方向の橋上で推論を行う。いずれも、共有表現という一本の背骨で支えられている点が共通している。
画像キャプションでは、画像中の対象や関係を言語に写像する過程で、表現の 説明能力 が試される。テキスト→画像生成では、語彙に含まれる意味要素を視覚的特徴に展開し、整合性の取れた画素配列を合成する。VQAは、質問の狙いを言語側で特定し、その射線が向かう視覚領域を同定して答えを組み立てる。三者は方向が異なって見えるが、いずれも 同じ地図上の相互参照 として捉えると理解が速い。
最小要点
- キャプション=説明の写像、T2I=発想の具象化、VQA=照会と根拠づけ。
- 方向は違っても、拠って立つのは同一の共有表現である。
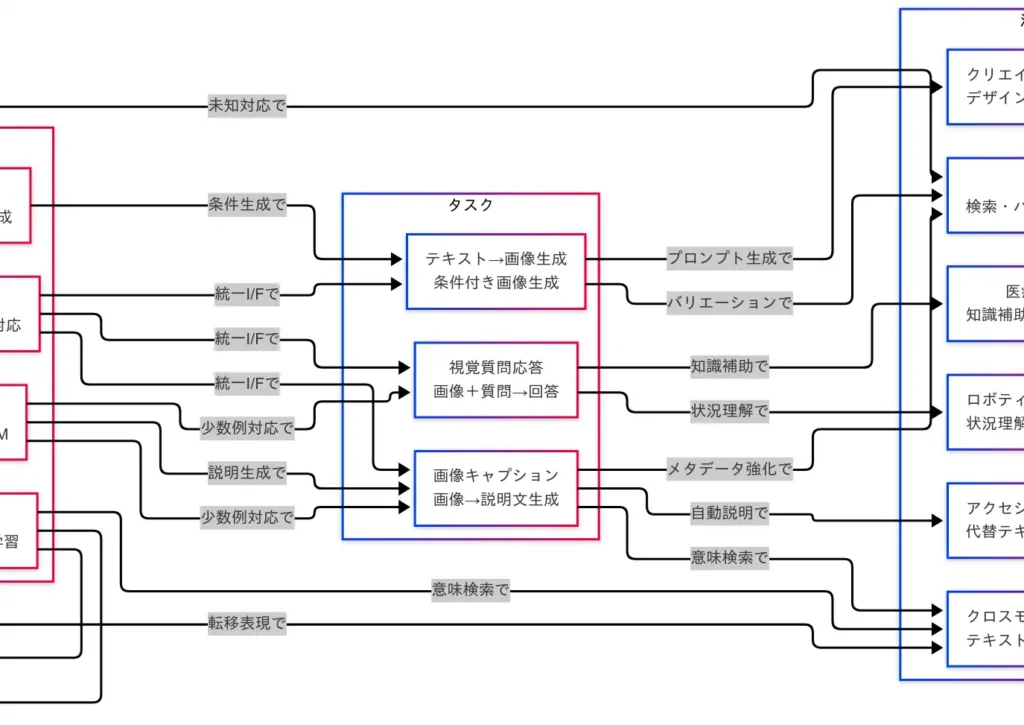
代表モデル
タスクの手触りを決めるのはモデルの設計思想である。CLIP は画像とテキストを 対照学習 で張り合わせ、意味空間での距離を正す名手である。ゆえにクロスモーダル検索で強い。** DALL·E** は言語条件から画像を生成する創作家であり、プロンプトという楽譜を解釈して視覚楽曲を奏でる。Flamingo は Few-shot を得手として、少数例でもキャプションやVQAをこなす柔軟さを示す。Unified-IO は入出力の窓口を統一し、画像・テキストをまたぐ複数タスクを一体運用する設計である。
この四者は対立ではなく 分担 である。検索を速く確かに行いたい場面ではCLIP、豊かな視覚案を短時間で得たい場面ではDALL·E、データが乏しい現場適用ではFlamingo、ワークフローを簡潔に保ちたいシステム設計ではUnified-IO——といった具合に道具を取り替えるとよい。
覚え筋
- CLIP=意味で探す、DALL·E=条件で描く、Flamingo=少数例で利く、Unified-IO=窓口を一つにする。
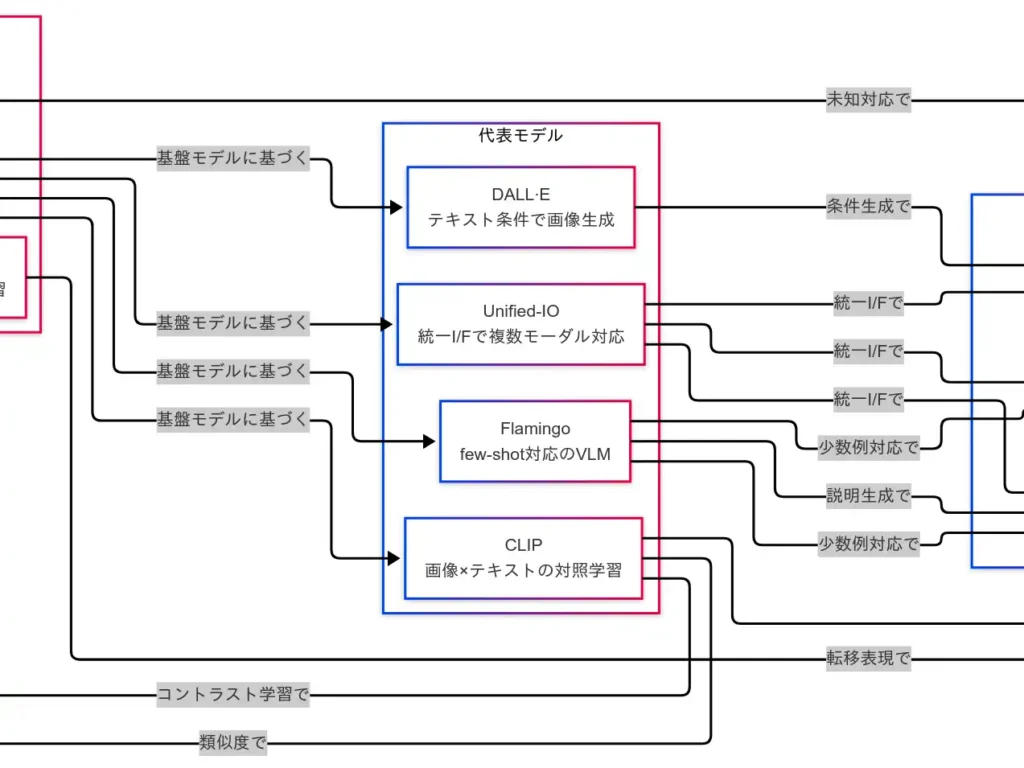
活用例
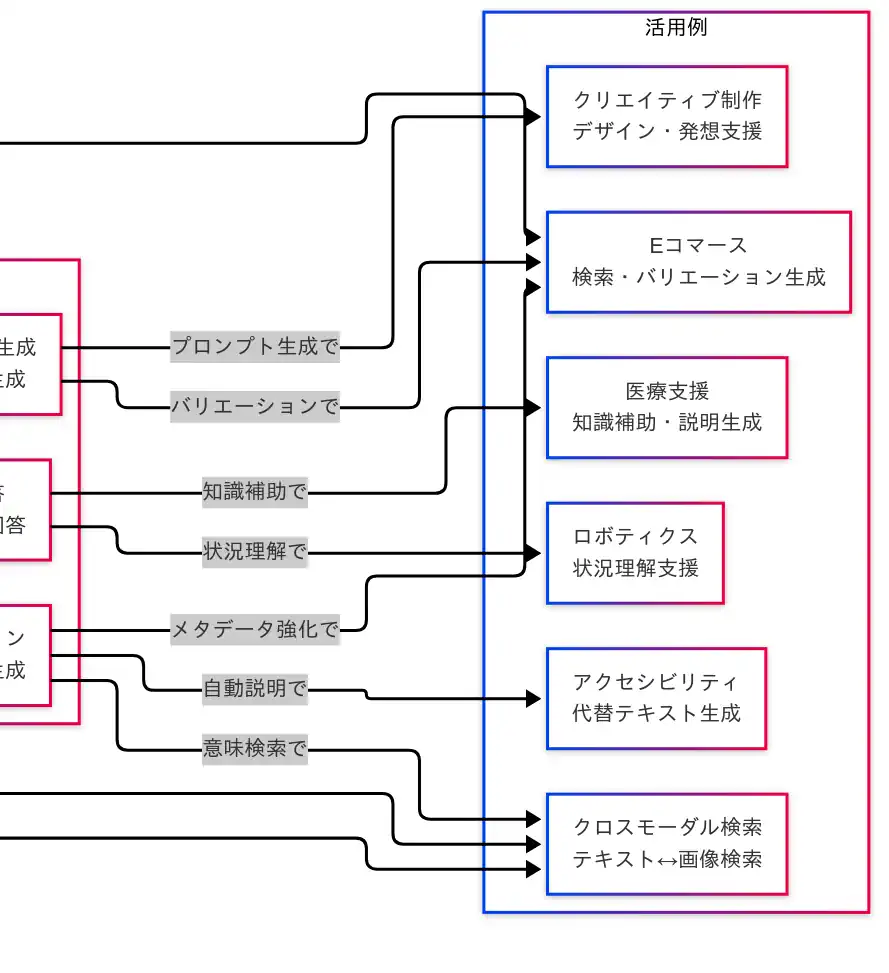
産業の現場では、これらの性格がそのまま価値に転化する。Eコマースでは商品検索が 語と画像の距離 で洗練され、レビュー理解と画像照合が統合される。クリエイティブ制作では、ラフ案の生成やバリエーション展開が秒単位で回り、企画段階の試行錯誤が飛躍的に速くなる。アクセシビリティの文脈では、代替テキストの自動生成が情報アクセスの壁を下げる。ロボティクスでは、カメラ映像に言語のラベルと説明が与えられ、状況理解が 行為決定 へと滑らかにつながる。医療支援では、説明責任を伴うサマリ化や補助的所見提示が専門家の判断を支える。
共通するのは、検索・生成・説明・応答 の四つの営みが、共有表現という一本の骨格で 連結 されている点である。業務フローの切れ目が減るほど、モデルを使い分ける必然性と、統合設計の妙味が同時に立ち上がる。
まとめ
マルチモーダルの理解は、基盤モデルが築く共有表現 を背骨に据え、そこから マルチタスク と Zero-shot へと汎化が波及し、検索・生成・説明・応答 の各タスクが現場の価値に変換される、という 因果の一本線 を見抜くことに尽きる。代表モデルはその線上の役者であり、CLIPは意味距離を整え、DALL·Eは言語を絵にし、Flamingoは少数例で俊敏に利き、Unified-IOは窓口を統一して運用の摩擦を減らす。
試験対策としては、用語を点で覚えるのではなく、図と叙述の往復 で線として刻み込むのが近道である。そうして初めて、呪文のような名称が、現場で使える 設計上の選択肢 へと変わるのである。
- 基盤モデルを起点に共有表現→マルチタスク学習→Zero-shotへと汎化が連鎖し、画像×テキストを同一意味空間で扱う枠組みを整理した記事である。
- 主要タスクは画像キャプション・テキスト→画像生成・視覚質問応答であり、共有表現を背骨に検索・生成・説明・応答へ橋渡しする。
- 代表モデルはCLIP(検索)、DALL·E(生成)、Flamingo(少数例対応)、Unified-IO(統合処理)であり、活用は検索/クリエイティブ/アクセシビリティ/ロボティクス/EC/医療に及ぶ。
「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
バックナンバーはこちら
深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト 第3版

徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版 徹底攻略シリーズ

ディープラーニングG検定(ジェネラリスト) 法律・倫理テキスト



コメント