数値計算 AI文章の手抜きは見抜けるか:小さく肉付けした文章と大きく削った文章が似てしまう理由 生成AIで文章が整うほど「見かけ品質」が収束し、小さく肉付けした文章と大きく削った文章が似てしまいます。肉付け・そぎ落としの非対称、見分けの手がかり(判断基準・制約・捨てた案)、ハイブリッド運用の実務ポイントを整理します。 2026.03.17 数値計算
数値計算 数理的なエッセイ集|数理OSで世界認識をアップデートする「破壊系シリーズ」 「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」その他数理関連(MATLAB、Python、Scilab、Julia比較ページ)はこちらはじめになんとなく思いつきで書いたエッセイ集。「普通... 2026.03.17 数値計算
数値計算 無断利用を批判するコンテンツが、別の無断っぽさを抱え込むとき――素材化のフラクタル構造とコンテンツ運用チェックリスト 無断利用を批判する記事や動画が、別レイヤーで同じ「無断っぽさ」を再演してしまうのはなぜか。距離とコストをざっくり式で眺めつつ、具体的なコンテンツ運用チェックリストに落とし込んで整理します。 2026.03.17 数値計算
数値計算 MCPとUSBエニュメレーションで読み解く「AIにとってのUSB-C」比喩 MCPを「AIにとってのUSB-C」と呼ぶ理由を、USBエニュメレーション(記述子取得)とMCPのinitialize/list/通知・購読・認可を電文例と比較表で整理。似ている点とズレる点を明確にします。 2026.03.15 数値計算
G検定 G検定対策 究極カンペをつくろう#14 データの収集・加工・分析・学習(アノテーション/オープンデータセット/コーパス/データリーケージ) G検定 究極カンペ「データの収集・加工・分析・学習」を究極カンペの工程地図で整理。オープンデータセット/コーパスの利用条件、分割と前処理、アノテーション品質、EDAと評価、共同開発の共有ルール、データリーケージ対策をまとめます。 2026.03.10 G検定
G検定 G検定カンペの作り方まとめ|究極カンペ動画&記事バックナンバー一覧 G検定対策で使える「究極カンペ」の作り方をまとめたバックナンバー一覧です。導入編からその他シラバスのカテゴリ単位で解説する動画+記事へのリンクを整理しています。G検定究極カンペを自作したい人向けのナビゲーションページです。また究極カンペ×用語カンペの実用的な二刀流運用へのリンクも含んでいます。 2026.03.04 G検定
G検定 G検定 用語集カンペをコンテキストカンペに強化する方法(用途・つながり・境界) G検定の「究極カンペ×用語集カンペ」二刀流の間にある初心者のつまずき(乖離)を、用語集カンペへ【用途・つながり・境界】の3列を追加して埋める方法を解説します。AlexNet・移動平均・GDPRで記入例も紹介し、サンプルExcelも公開します。 2026.03.04 G検定
数値計算 ニューラルネット入門(シグモイドで基礎をつなぐ):決定境界→逆伝播→BCEWithLogitsLoss→最適化をNumPyで シグモイドで基礎をつなぎ、決定境界の可視化→誤差逆伝播→BCEWithLogitsLoss(logaddexp)→最適化までをNumPyの最小コードで解説します。logが「自信満々の誤り」を強く罰する理由、勾配チェックで逆伝播を検証する方法、AdamWとL2正則化の違い、pos_weightによる不均衡データ対応、NumPyの式がPyTorch APIに一致する最短ブリッジもまとめます。 2026.02.27 数値計算
G検定 G検定×実務の最短ブリッジで学ぶ ニューラルネット入門エッセンシャル(決定境界・活性化・logits損失・最適化) G検定の頻出コア(決定境界・活性化・交差エントロピー・逆伝播・最適化)を、実務の定石であるlogits前提の損失(BCEWithLogitsとsoftmax交差エントロピーは同型の安定化)へ最短でつなぎます。数式とPythonは補足なので読み飛ばしOKです。 2026.02.27 G検定
G検定 G検定が「難化した」と感じる本当の理由:受験者増×情報過多で起きる“暗記ゴール化”を公式(例題・過去問・シラバス)で較正する勉強法 G検定の「難化体感」は実難化だけでなく、情報過多が“用語暗記=ゴール”に見せる暗記ゴール化で増幅します。公式で較正し、3行復習(用途・つながり・境界)で点学習を判断・説明へ戻す最短手順を解説。生成AIパスポートとの差も整理。 2026.02.24 G検定
 数値計算 数値計算
数値計算 数値計算  数値計算
数値計算  数値計算
数値計算  数値計算
数値計算  G検定
G検定  G検定
G検定 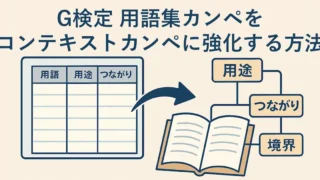 G検定
G検定 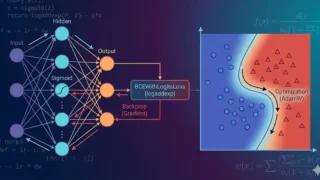 数値計算
数値計算 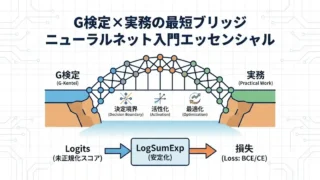 G検定
G検定  G検定
G検定