バックナンバーはこちら

3行要約
- 生成AIは突然生まれた技術ではなく、古典的な生成モデル、系列モデル、深層学習の積み上げの先にあります。 (arXiv)
- 分岐点は Transformer で、ここから GPT 系と BERT 系を見分けると全体像をつかみやすくなります。 (arXiv)
- ChatGPT は、土台、歴史、整合、周辺機能、主要サービス比較の順に見ると理解しやすくなります。 (OpenAI)
解説動画
※ 近日公開
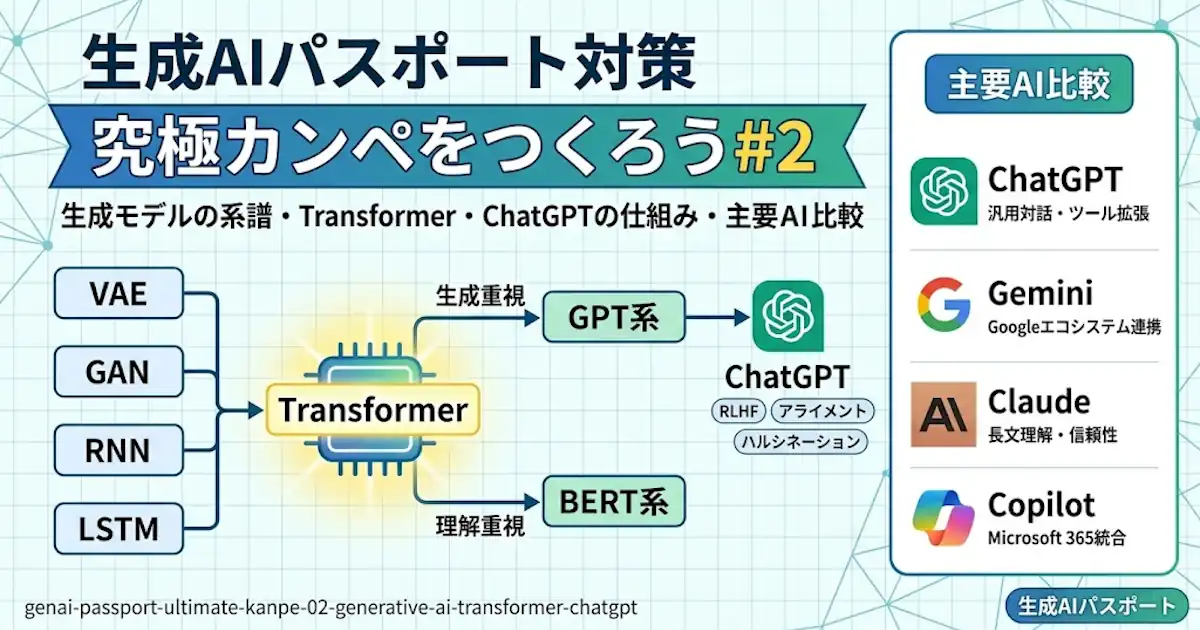
生成AIの全体像
生成AIを理解しにくい理由は、技術の系譜、サービス名、機能名が同じ場所に並んで見えやすいからです。ここを分けて考えると、覚える負担はかなり軽くなります。この記事では、まず生成モデルの流れをたどり、次に ChatGPT の仕組みと歴史を整理し、最後に Gemini、Claude、Copilot との違いを比較できる形にまとめます。 (OpenAI)
見取り図として押さえたいのは3本です。1本目は、古典的な生成モデルから Transformer までの技術の流れです。2本目は、ChatGPT を支える自然言語処理、学習、整合、マルチモーダル化の流れです。3本目は、主要なテキスト生成AIを、どこで使われやすいかという観点で見分ける流れです。 (arXiv)
生成モデルの系譜
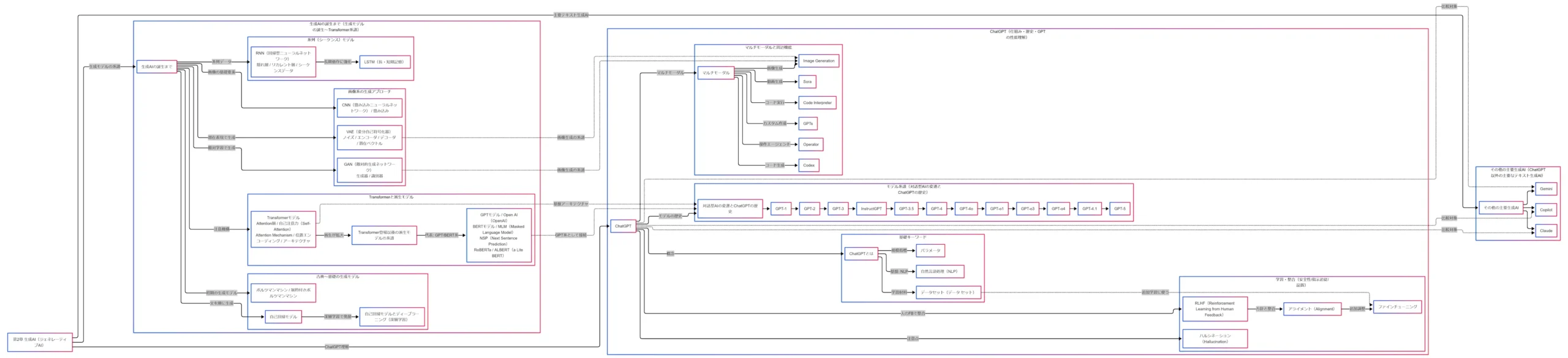
生成AIは突然現れた技術ではありません。古典的な確率モデル、画像生成モデル、系列モデル、そして Attention を中核にした Transformer が積み上がることで、いまの大規模言語モデルや生成AIサービスが成立しています。試験対策では、個別の用語をばらばらに覚えるよりも、どの技術がどの流れに属するかを先に見ておくほうが理解しやすくなります。 (arXiv)
古典〜基礎の生成モデル
古典側では、ボルツマンマシンや制約付きボルツマンマシンが、生成モデルの歴史をたどる中で登場します。現在の主役というより、出発点として見ておく語です。そのうえで、テキスト生成に強くつながる考え方が自己回帰モデルです。自己回帰モデルは、文章全体を一度に作るのではなく、次のトークンを順番に予測しながら文を組み立てていきます。いまの GPT 系モデルにも、この発想が残っています。 (arXiv)
この「次を予測して積み上げる」という見方が入ると、後で ChatGPT を理解しやすくなります。生成AIの中心には、流暢なテキストを次々に出していく仕組みがあり、そこに深層学習が組み合わさることで表現力が高まりました。 (OpenAI)
画像系の生成アプローチ
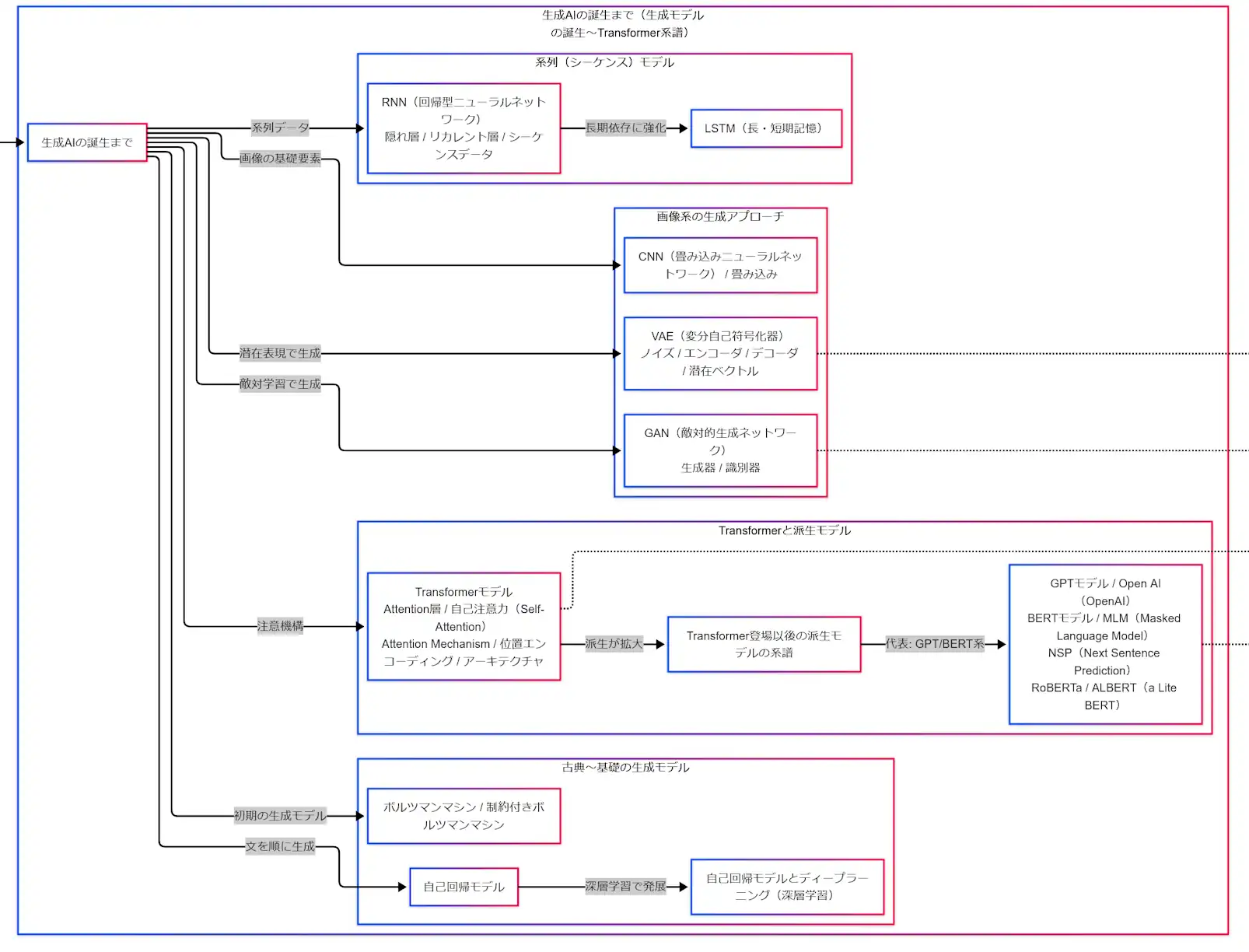
画像系では、VAE と GAN を見分けられるようにすると整理しやすくなります。VAE は潜在変数を使ってデータを表現し、近似推論を通じて生成する枠組みです。GAN は、生成器と識別器を同時に学習させる敵対的な枠組みで、生成器がより本物らしい出力を目指す構成になっています。 (arXiv)
試験では細かな数式まで要らなくても、VAE は潜在表現、GAN は敵対学習、という見分け方ができると混ざりにくくなります。VAE は「潜在ベクトルが中心」、GAN は「生成器と識別器の組み合わせが中心」と考えておくと十分です。 (arXiv)
系列モデルからTransformerへ
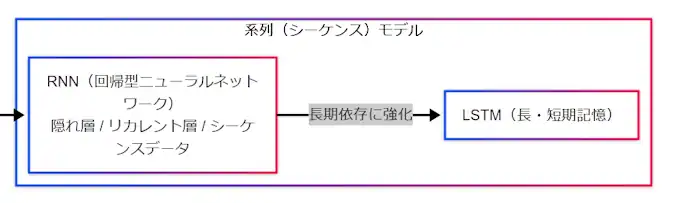
文章や時系列のような順番を持つデータでは、RNN や LSTM が長く重要でした。LSTM は、長い依存関係を扱いにくいという系列モデルの課題に対応するために提案され、前の状態を次へ受け渡す考え方を強めた手法です。 (arXiv)
その後の大きな転換点になったのが、2017年の Transformer です。Transformer は、再帰や畳み込みに頼らず、Attention を中核に置いたアーキテクチャとして提案されました。論文でも、従来の系列変換モデルが再帰や畳み込みを中心にしていたのに対し、Transformer は attention のみを基盤にする構成だと説明されています。 (arXiv)
Transformer を理解するときの要点は3つです。1つ目は Attention で、文中のどこを見るべきかを重みづけする考え方です。2つ目は Self-Attention で、入力どうしの関係を見ます。3つ目は位置エンコーディングで、順番の情報を補います。この3点が言えれば、Transformer を軸にした整理がかなり安定します。 (arXiv)
GPT系とBERT系
Transformer のあと、派生モデルが一気に増えました。ここは慌てず、幹が Transformer で、そこから太い枝として GPT 系と BERT 系が伸びた、と見ると整理しやすくなります。 (arXiv)
GPT 系は生成を重視する流れで、自己回帰的に次の単語を予測する考え方と相性がよい系統です。BERT は双方向の文脈表現を重視するモデルとして提案され、論文では左文脈と右文脈を同時に使った事前学習が強調されています。生成の流れを見るなら GPT 系、文脈理解の流れを見るなら BERT 系、という区別ができると全体像がすっきりします。 (arXiv)
BERT 側では、MLM と NSP が代表的な語として並びます。RoBERTa や ALBERT などの派生名も、この BERT 系の枝に並ぶ名前として把握しておくと、試験本番で復元しやすくなります。 (arXiv)
ChatGPTの仕組みと歴史
ChatGPTの土台
ChatGPT は、対話形式でやり取りできる生成AIです。OpenAI の公式説明でも、ChatGPT は follow-up に答え、誤りを認め、前提に異議を唱え、不適切な依頼を拒否できる対話モデルとして紹介されています。まずは「対話形式のテキスト生成AI」という捉え方で十分です。 (OpenAI)
土台には自然言語処理があり、大規模なデータセットから学習した言語モデルが使われます。理解の入口としては、NLP、データセット、パラメータの3つをまとめて押さえると分かりやすくなります。パラメータはモデルが学習で獲得する重みの集まりで、規模を考えるうえで重要ですが、性能はパラメータ数だけでは決まりません。学習データや学習方法、整合の方法も大きく関わります。 (OpenAI)
ChatGPTの歴史

試験対策としてまず押さえたい流れは、GPT-1、GPT-2、GPT-3、InstructGPT、ChatGPT です。ChatGPT の公式説明でも、ChatGPT は InstructGPT の sibling model とされており、単に大きい言語モデルがそのままサービス化されたのではなく、指示に従う方向へ整えた流れの上にあります。 (OpenAI)
近年は GPT-4o や o1、GPT-4.1 など、用途や特性の異なるモデル群が追加されています。GPT-4o はテキスト、音声、画像、動画をまたぐ入出力に対応する “omni” 系として案内され、o1 は応答前により多くの推論を行うモデル系列、GPT-4.1 はコーディング、指示追従、長文コンテキスト理解の改善を打ち出しています。モデル名は時期によって増えますが、試験勉強では「GPT 系の進化」「対話への最適化」「マルチモーダル化」という流れで見るほうが実用的です。 (OpenAI)
RLHF・アライメント・ファインチューニング・ハルシネーション
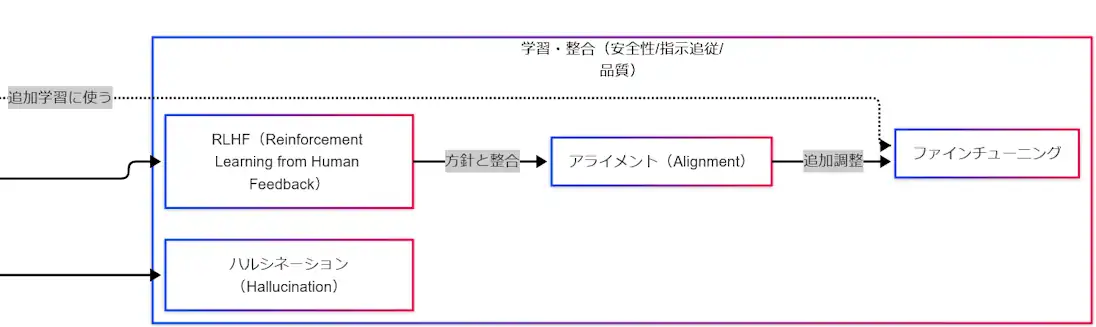
ChatGPT を理解するうえで重要なのが、賢さだけではなく、どう振る舞うように整えているかです。その中心語が RLHF です。InstructGPT の論文では、モデルを単に大きくするだけではユーザーの意図に沿いやすくなるわけではなく、人間のフィードバックを使った fine-tuning が有効だと示されています。 (arXiv)
アライメントは、モデルの応答を人間の期待や安全方針に沿うよう調整する考え方です。ファインチューニングは、その追加調整を実装する手段として理解すると整理しやすくなります。つまり、RLHF は人の評価を取り込み、アライメントは望ましい振る舞いへ近づける考え方、ファインチューニングはその調整方法、という位置づけです。 (arXiv)
一方で、生成AIにはハルシネーションという注意点があります。OpenAI の最新研究でも、ハルシネーションは「もっともらしく聞こえるが正しくない発言」であり、最新モデルでも残る根本課題だと説明されています。重要情報では根拠確認が欠かせない、という理解が試験でも実務でも重要です。 (OpenAI)
マルチモーダルと周辺機能
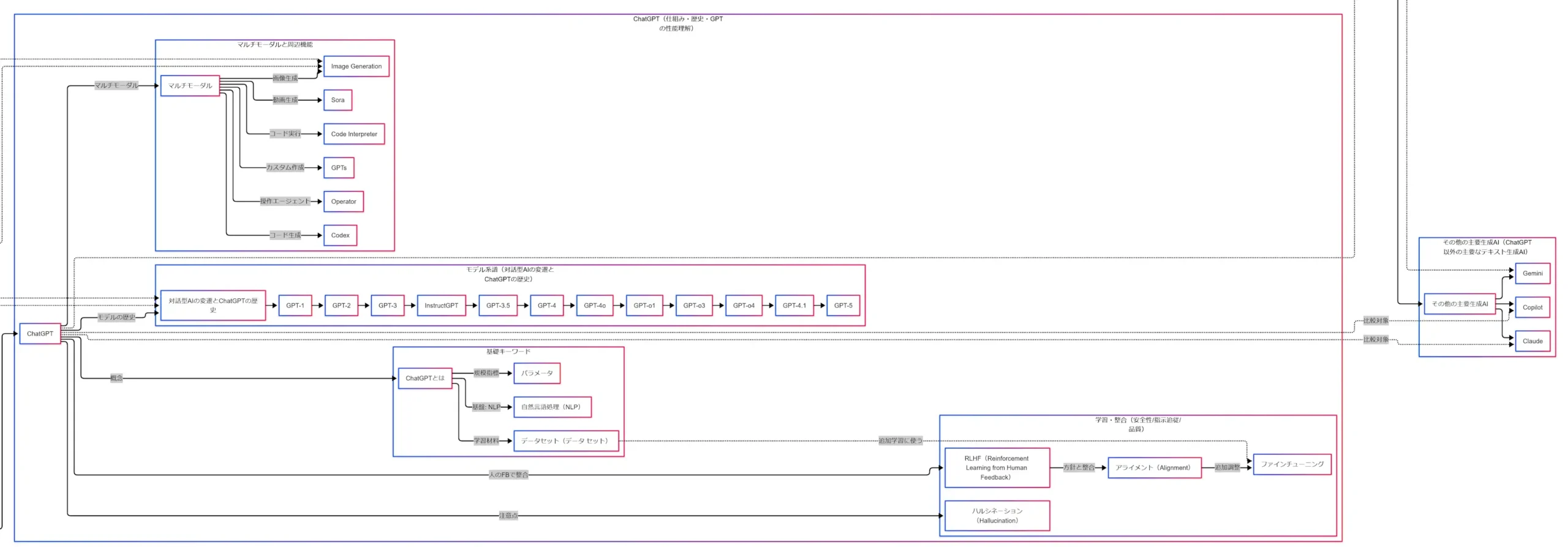
近年の ChatGPT を理解するうえで見逃せないのが、マルチモーダル化です。OpenAI の GPT-4o 紹介では、GPT-4o はテキスト、音声、画像、動画を組み合わせた入力を処理し、テキスト、音声、画像を組み合わせた出力を生成するモデルとして説明されています。つまり、テキスト生成AIという入口から始まりつつ、実際には複数の入出力を扱うAIへ広がっています。 (OpenAI)
この流れの上に、コード実行、画像生成、ファイル解析、検索、カスタムGPTなどの周辺機能があります。OpenAI Help Center でも、ChatGPT はウェブ検索、ディープリサーチ、画像入力と生成、ファイルアップロード、データ分析、カスタムGPTなどの機能を持つと案内されています。個々の機能名を細かく追うより、中心にマルチモーダル化とツール利用の広がりがあると考えるほうが整理しやすくなります。 (OpenAI Help Center)
主要テキスト生成AIの比較
ChatGPT 以外の主要テキスト生成AIとしては、Gemini、Claude、Copilot を押さえておくと整理しやすくなります。試験では細かな優劣の暗記よりも、「何者で、どこで使われやすいか」を説明できることが大切です。 (Google ヘルプ)
Gemini は、Google の Gemini アプリや Gemini API のモデル群とあわせて理解しやすい存在です。Google の公式ヘルプでは Gemini アプリの使い方や連携機能が案内され、Google AI for Developers では Gemini モデルが stable、preview、latest、experimental などの運用区分で提供されていると説明されています。Google サービスや開発基盤とつながる生成AIとして見ると位置づけが分かりやすくなります。 (Google ヘルプ)
Claude は Anthropic の AI プラットフォームです。Anthropic の公式ドキュメントでは、Claude は trustworthy で intelligent な AI platform とされ、言語、推論、分析、コーディングなどに強いと説明されています。文章理解や長文処理、慎重な応答のイメージで覚えると整理しやすくなります。 (Claude API Docs)
Copilot は、Microsoft 365 のアプリ群の中で使う前提で理解しやすい生成AIです。Microsoft Learn では、Word、Excel、PowerPoint、Teams などの Microsoft 365 アプリに組み込まれた機能として説明されており、業務データや仕事の文脈と結びついた支援が中心です。単独のチャットAIというより、仕事の流れに入ってくる相棒として見ると分かりやすくなります。 (Microsoft Learn)
比較の見方は3つあると便利です。1つ目は統合先、2つ目は得意領域のイメージ、3つ目は利用環境です。この見方で見ると、ChatGPT は汎用対話とツール拡張、Gemini は Google エコシステム、Claude は信頼性や長文処理、Copilot は業務ソフト統合という見取り図が作れます。 (OpenAI Help Center)
生成AIパスポート向けの覚え方
試験勉強で有効なのは、用語を単独で覚えないことです。まず「原因」を見ます。なぜその技術が必要になったのか、どんな課題を解こうとしたのかです。たとえば LSTM は長期依存の問題、Transformer は再帰中心の系列処理を越えて文脈関係を扱いやすくする流れで理解できます。 (arXiv)
次に「セット」で覚えます。VAE なら潜在ベクトル、GAN なら生成器と識別器、Transformer なら Self-Attention と位置エンコーディング、BERT なら MLM と NSP、ChatGPT なら RLHF とハルシネーションです。関連語をまとめて置いておくと、試験本番でも思い出しやすくなります。 (arXiv)
最後に「結果」を見ます。その技術が登場したことで、次に何が広がったかです。Transformer のあとに GPT 系と BERT 系が広がり、GPT 系の対話最適化の先に ChatGPT が普及し、さらにマルチモーダル化やツール利用へ発展していく、という順番でつながるようになると、細かな用語が一部あいまいでも全体は崩れにくくなります。 (arXiv)
まとめ
生成AIは、古典的な生成モデル、系列モデル、Transformer、そして大規模言語モデルへとつながる技術の流れの上にあります。Transformer を分岐点として置くと、GPT 系と BERT 系、さらに ChatGPT の理解まで一本につながります。ChatGPT は、土台、歴史、整合、マルチモーダル化、主要サービス比較の順で見ると、情報量の多さに振り回されにくくなります。 (arXiv)
- 生成AIの流れは、古典的生成モデル → 系列モデル → Transformer → GPT系・BERT系
- ChatGPTの理解は、土台 → 歴史 → RLHF・アライメント → マルチモーダル
- 主要AIの比較は、ChatGPT・Gemini・Claude・Copilot を統合先と得意領域で見る
FAQ
生成AIとChatGPTは同じ意味か
同じ意味ではありません。生成AIは、テキスト、画像、音声、動画などを生成するAI全体を指す広い概念です。ChatGPT はその中でも、対話形式で使う生成AIサービスの一つです。 (OpenAI)
Transformerが重要と言われる理由は何か
Transformer は、Attention を中心にした構成によって、系列データの関係をより扱いやすくし、その後の GPT 系や BERT 系の土台になったからです。生成AIの歴史の中で、大規模言語モデルへの分岐点として理解すると分かりやすくなります。 (arXiv)
RLHFはなぜ重要か
モデルを大きくするだけでは、人の意図に沿った応答や安全な応答が十分に得られないためです。RLHF は、人間のフィードバックを使って望ましい応答へ近づける考え方で、InstructGPT や ChatGPT を理解するうえで重要です。 (arXiv)
VAEとGANはどう見分けるか
VAE は潜在表現を使って生成するモデル、GAN は生成器と識別器を競わせて生成するモデル、と分けて覚えると見分けやすくなります。 (arXiv)
ChatGPT以外で押さえるべき主要テキスト生成AIは何か
まずは Gemini、Claude、Copilot です。Gemini は Google 系サービスとのつながり、Claude は信頼性や長文処理、Copilot は Microsoft 365 など業務ツールとの統合、という観点で整理すると覚えやすくなります。 (Google ヘルプ)
参考文献
- Attention Is All You Need
https://arxiv.org/abs/1706.03762 - Auto-Encoding Variational Bayes
https://arxiv.org/abs/1312.6114 - Generative Adversarial Nets
https://proceedings.neurips.cc/paper_files/paper/2014/file/f033ed80deb0234979a61f95710dbe25-Paper.pdf - Long Short-Term Memory
https://direct.mit.edu/neco/article/9/8/1735/6109/Long-Short-Term-Memory - BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
https://arxiv.org/abs/1810.04805 - Training language models to follow instructions with human feedback
https://arxiv.org/abs/2203.02155 - ChatGPTの機能概要 | OpenAI Help Center
https://help.openai.com/ja-jp/articles/9260256-chatgpt-capabilities-overview - GPT-4o が登場 | OpenAI
https://openai.com/ja-JP/index/hello-gpt-4o/ - OpenAI o1
https://openai.com/o1/ - Introducing GPT-4.1 in the API | OpenAI
https://openai.com/index/gpt-4-1/ - 言語モデルでハルシネーションがおきる理由 | OpenAI
https://openai.com/ja-JP/index/why-language-models-hallucinate/ - Gemini アプリ ヘルプ – Google Help
https://support.google.com/gemini/?hl=ja - モデル – Gemini API | Google AI for Developers
https://ai.google.dev/gemini-api/docs/models?hl=ja - Intro to Claude – Anthropic Docs
https://docs.anthropic.com/en/docs/welcome - Microsoft 365 Copilot とは? | Microsoft Learn
https://learn.microsoft.com/ja-jp/copilot/microsoft-365/microsoft-365-copilot-overview
試験対策を最短で固める本
生成AIパスポート公式テキスト

改訂シラバス対応版として毎年更新されている。
第2章の生成AIに加えて、最新モデル・主要生成AI・法制度や注意点までつながるので、まず最初に置くならこれ。
公式テキスト対応版 生成AIパスポート テキスト&問題集

公式テキストを読んだあとに、出題感覚を固める相棒として向く。
2026年5月発売の教科書&問題集として出ていて、「過去問題付きで合格力を確実に身につける」と案内されている。
記事の「全体像」を厚くする本
大規模言語モデル入門

ChatGPT の仕組み、LLM の基礎、文埋め込み、質問応答、検索との組み合わせまでを理論と実装の両面から扱う本。
「理論と実装の両方を解説した入門書」とされていて、「ChatGPTの土台」「整合」「検索連携」に広く効く。
機械学習・深層学習による自然言語処理入門

NLP の初歩から、Attention、RNN、LSTM、系列変換まで、日本語データで手を動かしながら学べる本。
自然言語処理を基礎から説明し、RNN、LSTM、Attention まで実装しながら理解できる構成だとされている。
「古典→系列→Transformer」のつながりを補強しやすい。
Transformer を深く理解する本
機械学習エンジニアのためのTransformers

Hugging Face を使って Transformer 系モデルを学びたいならかなり実践的。
テキスト分類、NER、生成、要約、質問応答だけでなく、蒸留や量子化、多言語転移まで扱う本になっている。
「Transformerが分岐点」という理解を、実装レベルまで下ろしたい人向け。
Transformerによる自然言語処理

Transformer の利用を基礎から応用まで詳説する本で、アーキテクチャ、事前訓練、機械翻訳、ニュース分析まで含む。より理論寄りに整理したいときに合う。
Transformer を「注意機構・Self-Attention・位置エンコーディング」の中心として説明。
VAE・GAN・生成モデルまで掘る本
ゼロから作るDeep Learning〈5〉生成モデル編

「正規分布から拡散モデルに至るまでの技術をつながりのあるストーリーとして展開」し、最終的に Stable Diffusion のような画像生成AIまで扱う本。
VAE、GAN、拡散モデルを系譜で理解したい人にぴったり。「生成モデルの系譜」を強化するならかなり合う。
生成 Deep Learning 第2版

VAE、GAN、Transformer、GPT、正規化フロー、エネルギーベースモデル、拡散モデルまで含むかなり網羅的な本。
深く支える1冊で、生成モデルを体系的に見たいなら強い。
迷ったときの選び方
- 合格優先なら
「生成AIパスポート公式テキスト 第4版」→「テキスト&問題集」の2冊で十分戦いやすい。 - 記事内容をちゃんと理解したいなら
「公式テキスト」+「大規模言語モデル入門」+「機械学習・深層学習による自然言語処理入門」の3冊がバランス良い。LLM、NLP、系列モデル、質問応答までつながる。 - Transformer と生成モデルまで深掘りしたいなら
「機械学習エンジニアのためのTransformers」+「ゼロから作るDeep Learning〈5〉生成モデル編」+「生成 Deep Learning 第2版」が強い組み合わせ。Transformer から VAE・GAN・拡散まで一本で追いやすい。

コメント