
この記事でわかること(2026年最新)
- G検定の難易度とこれまでの合格率の目安
- 文系・未経験からでも合格できるかどうか
- 合格者が実際に行った勉強ステップと学習時間の目安
- 700問の無料問題集と解説動画の使い方
- カンペ(チートシート)の作り方と注意点
G検定対策の関連記事まとめ
- 【G検定法律問題対策】個人情報保護法・著作権法・特許法・不正競争防止法の要点整理
- 【G検定強化学習対策】強化学習が苦手な人向けの勉強ロードマップ
- 【G検定シラバス比較】2021年版と2024年版シラバスの違いと追加トピック
- 【究極カンペバックナンバー】カンペ作成ノウハウと実例集
- G検定が毎回「難化した!」と言われる理由:作問スタイルのズレを5軸で分解し、コサイン類似度のおもちゃモデルで理解する
- G検定が「難化した」と感じる本当の理由:受験者増×情報過多で起きる“暗記ゴール化”を公式(例題・過去問・シラバス)で較正する勉強法
- G検定のカンペは禁止?「G検定 カンペ禁止」で検索する人向けに、受験規約・利用規約から読み解くNG行為(Google検索・ChatGPTは?)
- G検定 問題集の使い方|究極カンペで漏れ抜け・過学習・領域横断を潰す学習プロセス
- G検定×実務の最短ブリッジで学ぶ ニューラルネット入門エッセンシャル(決定境界・活性化・logits損失・最適化)
- G検定 用語集カンペをコンテキストカンペに強化する方法(用途・つながり・境界)
- G検定 合否を分ける光と影|体感難易度の分解で見える準備の型
- G検定の法律・倫理は頻出問題暗記が危険 シラバス起点で解く仕分けチェックシート
- 生成AIパスポート→G検定:自己回帰・自己教師あり・Transformerと法律倫理を一本線でつなぐ地図
- G検定はカンペ・検索・チャットサービスがないと無理? 問題集と本番の差をオリジナル例題で整理
- G検定に数学は不要? 強化学習・ロジスティック回帰・正則化を数式で理解するメリット
- G検定のカンペ・外部参照問題 緩い解釈はAI法務・倫理にも流れうる
- G検定に数学は不要? JDLA公式例題で分かる KLダイバージェンス・勾配消失・スキップ結合・CNN・PCA の数式理解
- 本記事を読む際の注意点
- はじめに
- 類似の検定
- 検定比較
- 解説動画
- 究極カンペ×用語カンペ関連記事
- 2021年版、2024年版シラバスを比較してみた
- 学習順版の考え方
- G検定 法律問題特化記事
- G検定 強化学習特化記事
- G検定超入門 とりあえず公式例題を解いてみる。
- G検定の評判について
- 世の中のG検定の位置づけ
- G検定の難易度はどのくらい?【過去の合格率と問題の傾向】
- オープンバッジの付与
- 過去問っぽい問題集(ひたすら過去問ふぅ問題で鍛錬する所 一問一答 仮)
- arXivを利用した情報収集方法例
- その他のAI関連記事
- G検定を受ける前準備について
- G検定2020#2について
- G検定2020#3について
- G検定2021#1について
- G検定2021#2について
- G検定2021#3~2023#3
- G検定を受けてみた感想
- G検定(JDLA ディープラーニング ジェネラリスト検定)とは何か?
- G検定の過去も含めた合格率と難易度
- G検定は文系・未経験でも合格可能か?【必要な数学レベルと対策】
- G検定を受けるモチベーション
- G検定対策前の私のスペック
- G検定の勉強時間の目安は?【働きながら合格するためのスケジュール例】
- G検定対策として学習に使用した本(テキスト、問題集、時事)
- 学習のコツ(出題者側の思考)
- 真のG検定対策
- G検定カンペ(チートシート)は作るべき?【作り方と注意点】
- 無料模試によるG検定対策 その1
- 無料模試によるG検定対策その2
- 無料模試によるG検定対策その3
- 無料模試によるG検定対策その4
- 無料対策講座によるG検定対策
- G検定対策としてのその他の活動(カンペ的なものとも言える)
- 人工知能(AI)とは
- 人工知能をめぐる動向
- 人工知能分野の問題
- 機械学習の具体的手法
- ディープラーニングの概要
- ディープラーニングの手法
- ディープラーニングの研究分野
- ディープラーニングの応用に向けて
- ディープラーニングの基礎数学
- その他
- G検定 2020#3で出てきたやや特殊な問題
- G検定 2021#1で出てきたやや特殊な問題
- G検定 2021#2で出てきたやや特殊な問題
- G検定 2021#3で出てきたやや特殊な問題
- G検定 2022#1で出てきたやや特殊な問題
- G検定 2022#2で出てきたやや特殊な問題
- G検定 2022年、2023年以降で出てきたやや特殊な問題
- まとめ
- G検定対策に関するFAQ
- 参考文献
- 参考書籍
本記事を読む際の注意点
※この記事は 2026年4月時点のG検定最新シラバス・試験情報を反映しています。(重要な変更があれば随時更新中)
本記事は2020年から2025年以降含めてG検定関連情報を整理しまくった母艦記事です。
よって情報量としてはアホなことになっています。
時間が無い人は目次を見て必要そうな項目を目次から拾ってください。
時間がある人は斜め読みでも良いので、まずは総なめしてみることをお勧めします。
全体像を把握することで、その後の対策が大きく変わってきます。
はじめに
2020年3月14日に実施された日本ディープラーニング協会ジェネラリスト検定(通称:G検定)に無事合格。
よって、どのように勉強したのかとか感想を記載する。
さらに実際の出題数、難易度等をシラバス単位で解説。
シラバス単位の出題数は、試験当日に走り書きした雑なメモから思い出しながら書き出したので、おおよその値となる。
今後のG検定受験者の役に立てれば幸い。
一応、試験前に作ったノートも貼っている。
使用禁止されているが、カンペ(カンニングペーパー、チートシート)にもならなくはない・・・。
2020#2,#3,2021#1,#2,#3および2023年以降の情報も随時追記している。
過去問っぽい問題集も設置しているので、気軽に解いていってください。(ひたすら過去問ふぅ問題で鍛錬する所)
結論を先に書いてしまうと、おおよそ以下。
- 事前調査。
- 問題数とか1問あたりに使って良い時間
- シラバス。
- 問題傾向。
- テキスト、問題集、AI白書等による知識インプット。
- 問題集問いて満遍なく慣らす。
- 動画見て大雑把に漏れ抜けを拾っていく。
- 上記を元にカンペを作る。
- 当日にそのカンペを使う使わないはお任せ。どちらかというとカンペを作る過程に意味がある。
類似の検定
ディープラーニングでなく、データサイエンスの検定としてデータサイエンティスト検定というものがある。
それについても、記事にしているので興味ある方はどうぞ。

あと、AI実装検定B級の記事も

そしてAI実装検定A級

検定比較
解説動画
試験的に音声合成ソフトウェアVOICEVOXを使用したG検定解説動画を作成。
本動画群に対して合格者の方からお礼メールいただきました。
知識ゼロの状態から頑張って勉強して対策されたようです。
初心者にもとても分かりやすいとご評価いただき誠にありがたいことです。
下の方に設置している過去問っぽい問題集もご利用いただいたようです。
さらに、
Youtubeチャンネル側に、かなりありがたいコメントを頂いています。
(大学生の方のようです。ご本人の自己評価は低めな感じでしたが、ここまで状況の分析と表現ができる方は結構優秀な気はします)
勉強時間20時間
難易度-SyudyAIと同等orやや上?(数問いやらしい長文の問題あり)
問題数-191問 カンペ参照しながらだと時間ぎりぎり最新の問題はそんなにでなかった
ChatGPTとAIイラスト生成にかかわる問題あり。
ChatGPTは使われてるモデルの名前?(忘れた・・・)
AIイラスト生成は(著作権にかかわる問題)簡単な問題が少なかった印象(深く意味知らなくても解ける問題)
法律系がやっぱ鬼門、個人情報やデータの営業秘密についてわかったつもりになるのが一番危険!
浅い理解だと出題内容が変わると混乱する。
その他はカンペや用語集サイトでググれば解けるような問題
数学の問題は中学でた人なら地頭良ければノー勉でも解けそう(ただ標準偏差などについて知っておく必要あり)
公式テキストに載っていない単語2割くらい・・・?合格できたかは5割ってとこです。
G検定対策 シラバスの用語ベースで問題つくろう#12【畳み込みニューラルネットワーク①】(ネオコグニトロン、LeNet)のコメント欄(https://youtu.be/0hz5t1aeECo)
このチャンネルには助けられました。ありがとうございました( *´艸`)
G検定 さっくり解説(真のG検定対策も)

G検定 さっくり対策(究極カンペの作り方)

G検定 出題傾向解説

G検定 法律問題対策(※動画作成環境のメモリ不足に伴い、前編後編に分離)


G検定 法律問題対策 前後編合体版

G検定 強化学習対策(概要編)

G検定対策 問題が無いなら作れば良いじゃないシリーズ



G検定 合否を分ける光と影(合格を勝ち取る人の傾向)

G検定超入門 とりあえず公式例題を解いてみるシリーズ



【見直し戦略が重要】G検定 試験画面について解説【試験前の最低限の前準備】
究極カンペの作り方シリーズ

G検定対策 シラバスの用語ベースで問題つくろうシリーズ
シラバスの用語を元に過去問っぽい出題をする動画シリーズ。
ディープラーニングの社会実装に向けて
「AIと社会」(経営関連、法律関連、その他新技術関連)AI による経営課題の解決と利益の創出、法の遵守、ビッグデータ、IoT、 RPA、ブロックチェーン

「AIプロジェクトの進め方」(ビジネスとAI技術の板挟み関連)CRISP-DM、MLOps、DevOps、AIops、BPR、クラウド、Web API、データサイエンティスト、プライバシー・バイ・デザイン

「データの収集 前編」(法律問題、契約問題関連)オープンデータセット、個人情報保護法、不正競争防止法、著作権法、特許法、個別の契約、データの網羅性

「データの収集 後編」(契約問題関連)転移学習、サンプリング・バイアス、他企業や他業種との連携、産学連携、オープン・イノベーション、AI・データの利用に関する契約ガイドライン

「データの加工・分析・学習 前編」(匿名加工情報、カメラ画像利活用ガイドブック)アノテーション、匿名加工情報、カメラ画像利活用ガイドブック、ELSI、ライブラリ、Python

「データの加工・分析・学習 後編」(ツール、説明可能AI、ポリシー)Docker、Jupyter Notebook、説明可能AI(XAI)、フィルターバブル、FAT、PoC

「実装・運用・評価 前編」(法律問題、著作権法、不正競争防止法、個人情報保護法)著作物、データベースの著作物、営業秘密、限定利用データ、オープンデータに関する適用除外、秘密管理、個人情報

「実装・運用・評価 後編」(GDPR、攻撃、フェイク、バイアス)GDPR、十分性認定、敵対的な攻撃、ディープフェイク、フェイクニュース、アルゴリズムバイアス、ステークホルダーのニーズ

「クライシスマネジメント 前編」(炎上対策、軍事技術)コーポレートガバナンス、内部統制の更新、シリアスゲーム、炎上対策とダイバーシティ、AIと安全保障と軍事技術、実施状況の公開

「クライシスマネジメント 後編」(透明性レポート、Partnership on AI)透明性レポート、よりどころとする原則や指針、Partnership on AI、運用の改善やシステムの改修、次への開発と循環

数理・統計
「数理・統計」(統計検定3級程度の基礎的な知識)母集団、標本、平均、分散、標準偏差、帰無仮説

ディープラーニングの手法
「畳み込みニューラルネットワーク①」(ネオコグニトロン、LeNet)ネオコグニトロン、LeNet、サブサンプリング層、畳み込み、フィルタ

「畳み込みニューラルネットワーク②」(プーリング、Cutout、Random Erasing)最大値プーリング、平均値プーリング、グローバルアベレージプーリング、Cutout、Random Erasing

「畳み込みニューラルネットワーク③」(データ拡張、MobileNet、Neural Architecture Search)Mixup、CutMix、MobileNet、Depthwise Separable Convolution、NAS(Neural Architecture Search)

「畳み込みニューラルネットワーク④」(EfficientNet、NASNet、転移学習)EfficientNet、NASNet、MnasNet、転移学習、局所結合構造

「畳み込みニューラルネットワーク⑤」(ストライド、スキップ結合、パディング)ストライド、カーネル幅、プーリング、スキップ結合、各種データ拡張、パディング

「深層生成モデル」(GAN関連)ジェネレータ、ディスクリミネータ、DCGAN、Pix2Pix、CycleGAN

「画像認識分野①」(AlexNet、GoogLeNet、VGG)ILSVRC、AlexNet、Inceptionモジュール、GoogLeNet、VGG

「画像認識分野②」(ResNet、DenseNet、SENet)スキップ結合、ResNet、Wide ResNet、DenseNet、SENet

「画像認識分野③」(R-CNN、YOLO、SSD)R-CNN、FPN、YOLO、矩形領域、SSD

「画像認識分野④」(Faster R-CNN、各種セグメンテーション)Fast R-CNN、Faster R-CNN、セマンティックセグメンテーション、インスタンスセグメンテーション、パノプティックセグメンテーション

「画像認識分野⑤」(セグメンテーションの具体的なモデル)FCN (Fully Convolutional Netwok)、SegNet、U-Net、PSPNet、Dilation convolution

「画像認識分野⑥」(DeepLab、Open Pose、Mask R-CNN)Atrous Convolution、DeepLab、Open Pose、Parts Affinity Fields、Mask R-CNN

「音声処理と自然言語処理分野①」(LSTM、RNN Encoder-Decoder、BPTT)LSTM、CEC、GRU、双方向RNN、RNN Encoder-Decoder、BPTT

「音声処理と自然言語処理分野②」(Attention、PCM、FFT)Attention、AD変換、パルス符号変調、高速フーリエ変換、スペクトル包絡

「音声処理と自然言語処理分野③」(MFCC,フォルマント,音素)メル周波数ケプストラム係数、フォルマント、フォルマント周波数、音韻、音素

「音声処理と自然言語処理分野④」(隠れマルコフモデル、WaveNet、N-gram)音声認識エンジン、隠れマルコフモデル、WaveNet、メル尺度、N-gram

「音声処理と自然言語処理分野⑤」(BoW、TF-IDF、局所表現、分散表現)BoW(Bag-of-Words)、ワンホットベクトル、TF-IDF、単語埋め込み、局所表現、分散表現

「音声処理と自然言語処理分野⑥」(word2vec、fastText、ELMo)word2vec、スキップグラム、CBOW、fastText、ELMo

「音声処理と自然言語処理分野⑦」(Seq2Seq、Source-Target Attention、Encoder-Decoder Attention)言語モデル、CTC、Seq2Seq、Source-Target Attention、Encoder-Decoder Attention

「音声処理と自然言語処理分野⑧」(Self-Attention、位置エンコーディング、GPT-1,2,3)Self-Attention、位置エンコーディング、GPT、GPT-2、GPT-3

「音声処理と自然言語処理分野⑨」(BERT、GLUE、Vision Transformer、構文解析、形態要素解析)BERT、GLUE、Vision Transformer(ViT)、構文解析、形態素解析

【深層強化学習分野①】「DQN、デュエリングネットワーク、ノイジーネットワーク、Rainbow」DQN、ダブルDQN、デュエリングネットワーク、ノイジーネットワーク、Rainbow

「深層強化学習分野②」(モンテカルロ木探索、AlphaGo、AlphaGo Zero、Alpha Zero、マルチエージェント強化学習)

「深層強化学習分野③」(OpenAI Five、AlphaStar、状態表現学習、連続値制御、報酬成形)

「深層強化学習分野④」(オフライン強化学習、sim2real、ドメインランダマイゼーション、残差強化学習)

「モデルの解釈性、軽量化」(モデルの解釈、CAM、蒸留、モデル圧縮、量子化、プルーニング)

ディープラニングの概要
「ニューラルネットワークとディープラーニング」(単純/多層パーセプトロン、ディープラーニングとは、勾配消失問題、信用割当問題、誤差逆伝播法)

「ディープラーニングのアプローチ」(事前学習、積層オートエンコーダ、ファインチューニング、制限付きボルツマンマシン、深層信念ネットワーク)

「ディープラーニングを実現するには」(CPUとGPU、GPGPU、ディープラーニングのデータ量、TPU)

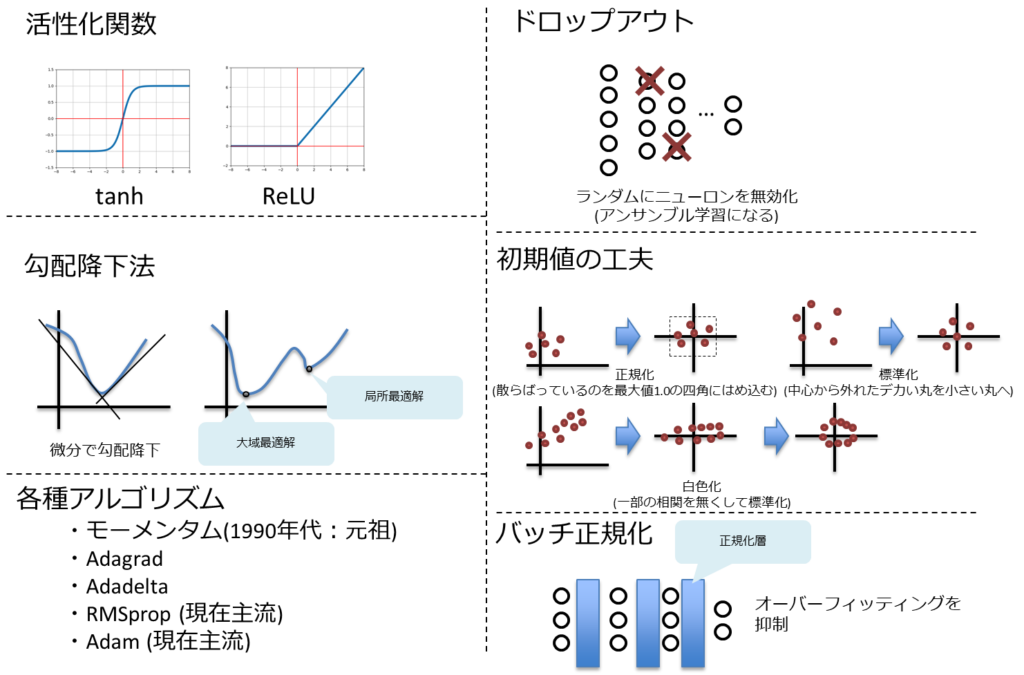
「活性化関数」(シグモイド関数、tanh関数、ReLU関数、ソフトマックス関数、Leaky ReLU関数)

「学習の最適化①」(学習率、誤差関数、交差エントロピー、イテレーション、エポック)

「学習の最適化②」(局所最適解、大域最適解、鞍点、プラトー、モーメンタム)

「学習の最適化③」(AdaGrad、AdaDelta、RMSprop、Adam、AdaBound、AMSBound)

「学習の最適化④」(ハイパーパラメータ、グリッドサーチ、ランダムサーチ、確率的勾配降下法、最急降下法)

「学習の最適化⑤」(バッチ学習、ミニバッチ学習、オンライン学習、データリーケージ)

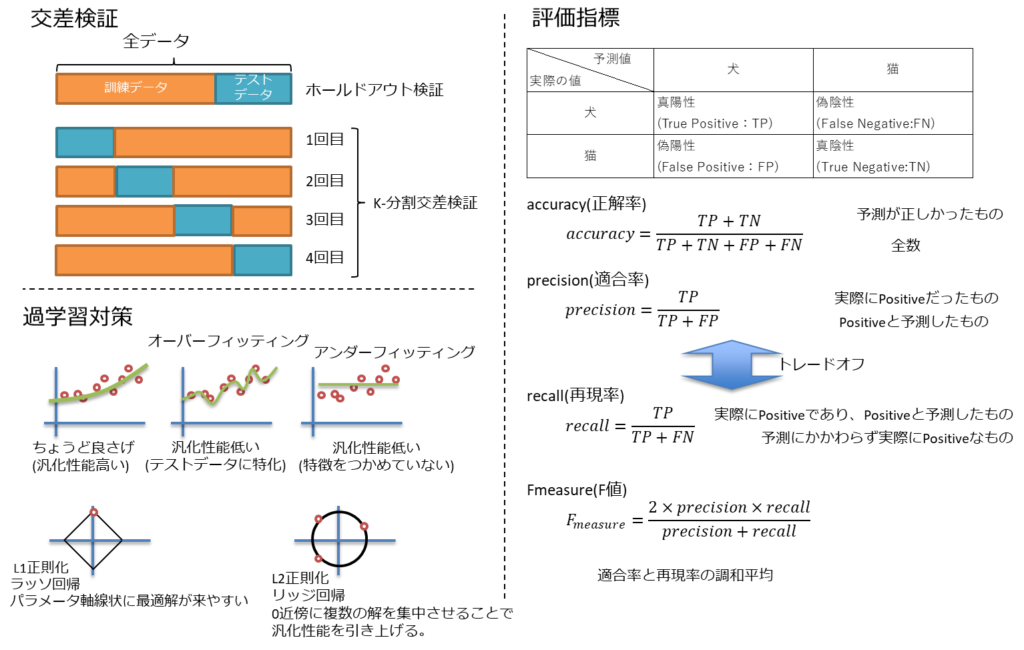
「更なるテクニック①」(過学習、アンサンブル学習、ノーフリーランチの定理、二重降下現象、ドロップアウト)

「更なるテクニック②」(正規化、標準化、白色化、バッチ正規化、早期終了)

機械学習の具体的手法
「教師あり学習①」(分類問題、回帰問題、半教師あり学習、ラッソ回帰、リッジ回帰)

「教師あり学習②」(決定木、アンサンブル学習、ブートストラップサンプリング、バギング、勾配ブースティング)

「教師あり学習③」(マージン最大化、カーネル、カーネルトリック、活性化関数)

「教師あり学習④」(誤差逆伝播法、自己回帰モデル、ベクトル自己回帰モデル、隠れ層)

「教師あり学習⑤」(疑似相関、重回帰分析、AdaBoost、多クラス分類)

「教師なし学習①」(クラスタ分析、k-means法、ウォード法、デンドログラム)

「教師なし学習②」(レコメンデーション、協調フィルタリング、コンテンツベースフィルタリング、コールドスタート問題)

入門 数値解析シリーズ
【入門】行列の存在意義【数値解析】G検定、DS検定で行列嫌いの方々向け
ベクトル、行列、連立方程式、線形代数、数値解析、逆行列、掃き出し法

【入門】線形代数の基礎 前編【数値解析】G検定、DS検定で行列嫌いの方々向け
ベクトル、行列、線形代数、数値解析、内積、余弦定理、三角比の基本公式

【入門】線形代数の基礎 後編【数値解析】G検定、DS検定で行列嫌いの方々向け。ニューラルネットワーク、畳み込み、フーリエ変換も実は・・・。
ベクトル、行列、線形代数、数値解析、内積、連立方程式、ニューラルネットワーク、畳み込み、フーリエ変換、逆フーリエ変換

【入門】ベクトル行列演算(MATLAB,Python(NumPy))【数値解析】G検定、DS検定で行列嫌いの方々向け。ツールに任せれば一撃で解決!

究極カンペ×用語カンペ関連記事


2021年版、2024年版シラバスを比較してみた
単純比較はできなかったので、2021年版シラバスから見て。2024年版で増えた用語を抽出。
増えた用語について簡単に解説。

学習順版の考え方

G検定 法律問題特化記事
受験者を魔境に引き込む法律問題の特化記事を作成。
個人情報保護法、著作権法、特許法、不正競争防止法についての概要とAIとの関連性について記載しているので参考にどうぞ。

G検定 強化学習特化記事
強化学習についての勉強方法を聞かれたんで、とりあえず記事にしてみた。

G検定超入門 とりあえず公式例題を解いてみる。
人工知能をめぐる動向 2問、人工知能分野の問題 2問の計4問

機械学習の具体的手法 4問、ディープラーニングの概要 3問の計7問

ディープラーニングの手法 5問、ディープラーニングの研究分野 2問の計7問

G検定の評判について
※ 読み飛ばし推奨!!
上司&同僚&部下からは特に不評なことは出てきてないが、SNS上では結構酷評されてる。
「G検定のGはゴキ〇リのGだ!!」
とか。
(気持ちは分からなくもない。一般的な試験だと問題集だけで対策としては十分なのだが、
G検定に関してはその経験が結構邪魔をする・・・。)
ゴキ〇リを舐めていけない。
擬人化すると結構かわいいのだ。

身構えるゴキ〇リ

空飛ぶゴキ〇リ
ちゃんとデザイン案もある。(すごい。)
※画像は以下のサイトより拝借致しました。

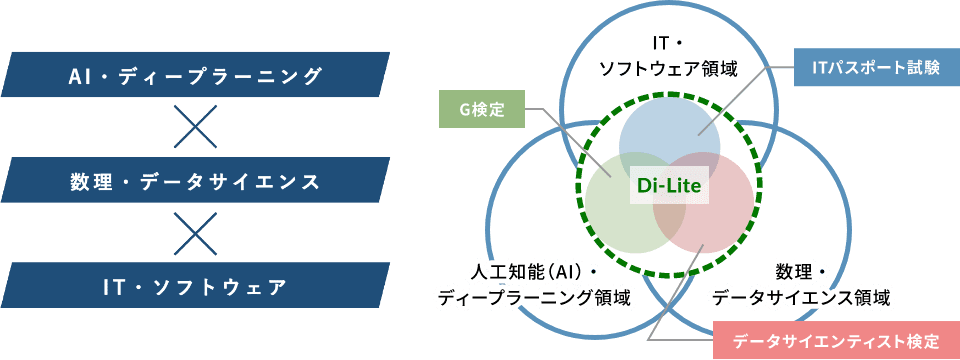
世の中のG検定の位置づけ
経済産業省がオブザーバーとなっている、デジタル人材育成を目的としたデジタルリテラシー協議会というものがある。
そこでデジタルリテラシーDi-Lite(ディーライト)について語られている。

詳細説明は割愛するが、AI、データサイエンス、ITの3つの分野を横断するような人材が求められているということになる。
G検定はこの中でAI・ディープラーニングの領域のリテラシーを保有していることを証明する検定という位置づけになっている。
G検定の難易度はどのくらい?【過去の合格率と問題の傾向】
まずは難易度としてはそれほど難しいものではない。
後の方にも書いてるが、合格率は60%かそれより上なので、まじめに且つ適切に対策していれば問題無いレベルと言える。
ただ、受験者の獲得点数の分布を散らしたいという出題者側の意向がありそうで、問題自体は難しかったり、単語を暗記してる程度では解けないような複合的な出題の仕方になっているので、対策の仕方が単純暗記では乗り越えられないと思った方が良い。
問題の傾向、予想合格ラインも本記事に記載しているので、そこからG検定の難易度を読み取っていただければと思う。
情報量としてはかなりあるので、お手隙に少しずつでも読んでいただければ。
オープンバッジの付与
2021年10月25日以降よりG検定合格者に対してオープンバッジが付与されることとなった。
これは過去の合格者に対しても適用されており、私に対しても付与された。
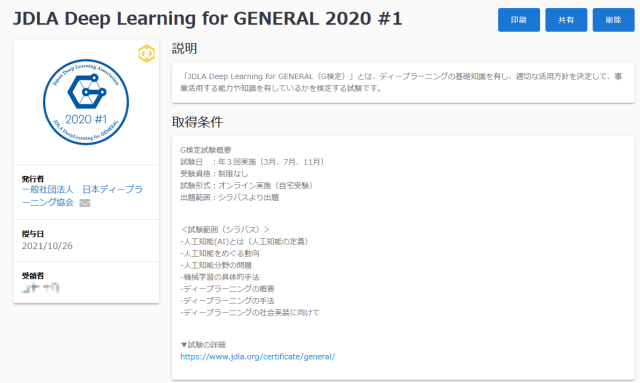
株式会社LecoSのオープンバッジウォレットサービスにて監視されている物らしい。
まぁこれがあるからといって現状では特に優遇されるものはないと思うが、こういうものが存在して、それを付与してもらったというのは中々趣がある。
今後の検定、資格関連は同様にオープンバッジとして付与されるようになるのかもしれない。
一応、オープンバッジの説明↓
オープンバッジ(Open Badges)は、技術標準規格にそって発行されるデジタル証明/認証。資格情報をSNSなどで共有、オープンバッジの内容証明を行うことが可能。もともとはMozillaがマッカーサー財団からの資金提供を受けて開発した規格。オープンバッジ標準では、成果に関する情報をアーカイブして画像ファイル(png、svg)にメタ情報を埋め込むこと。また、バッジ検証のためのインフラを確立する方法について説明している。この標準は2017年1月1日をもって正式にIMS Global Learning Consortiumに移行した。
Wikipediaより(https://ja.wikipedia.org/wiki/%E3%82%AA%E3%83%BC%E3%83%97%E3%83%B3%E3%83%90%E3%83%83%E3%82%B8)
過去問っぽい問題集(ひたすら過去問ふぅ問題で鍛錬する所 一問一答 仮)
勝手に過去問っぽい問題集作成中。実際の問題よりかは難易度低め。
※ 問題の種類は法規/近年の動向にかなり寄せてる。普通の問題を解きたい方は既存お問題集や模試サイトをやった方が良い。実際のG検定を受けた際に時事問題、法規問題に直面した際にショックを受ける方が多いようなので、そのショックをいくらか軽減する目的で設置。
公式テキストや問題集に載ってないような文言が出てくるが、AI白書やarXiv等の文献で出てくるような言い回しを採用しているため。
G検定で求めれるジェネラリストとしては、割と必要と判断しても良い表現だと思う。
(G検定問題文も全てではないが、4割くらいはそんな感じ)
尚、初見では誤答する方が普通。
パッと見わからないのであれば、Google検索してみるのもアリ。
重要なのは、「問題文と答えの関係性だけを暗記する」のだけは避けるべき。
言い回しの違いで知ってるはずなのに解けない現象が発生する。
あと、問題文より選択肢側に罠が仕掛けられていることもしばしば。
選択肢としては消去法で2つまでは容易に絞れて、その後に特定の論点をもって優劣を決定させるパターンを出題者は好む傾向がある。
出題者側からするとこのパターンの出題ができるとうまくハマった感が出るため。
この出題者の趣味趣向を逆手にとって解くというのも一手だろう。
※これは、他の問題集を解くときも一緒。
一応無料です。私が趣味の範疇で書き起こしているだけなので。
法律関連の過去問っぽい問題も入れ始めた。
※ 現在700問程放り込んでる。(新しいネタが見つかり次第随時追加中)

本問題集とYoutube動画を連携させた利用方法の解説動画


AI白書。(用語検索を考えるとkindle版の方が良いかも)
arXivに上がっているような論文を読む際は、
- Introduction(導入文)
- Related Work(関連研究)
のような章がある。
特にRelated Work(関連研究)は過去の経緯などが記載されており、そのくだりがG検定等の問題の表現に近いことがある。
私の所感だが、どうもG検定で求めているスキルのラインはarXivの論文がそこそこ読めるあたりに引いているように感じる。
他ブログやTwitter上でG検定に対して否定的な意見もそこそこあるが、それはそれでその方々の主観/意見であるので否定する気は無い。
しかし、それに引きずられて他人の意見を鵜呑みにして、自身の意見としてしまう前に、今の世の中を見て、何を求めれているのか、どうあれば胸を張ってジェネラリストと言えるのか、という点を一考した方が良いだろう。
arXivを利用した情報収集方法例
「Occlusion Handling in Generic Object Detection: A Review」
を例に挙げる。

左上からPDFの論文がDownloadできる。
この論文のIntroductionの一部を抜粋。
Object detectors are categorized into two types: one-stage detectors, and two-stage detectors. The latter uses region proposal network to produce regions of interest (ROI) and apply a deep neural network to classify each proposal into class categories. The first type, however, considers the object detection as a regression problem, hence it uses a unified framework to learn the class probabilities and coordinates of bounding boxes. This makes one-stage detectors faster compared to its counterpart. The most effective state-of-art detectors are Faster RCNN, SSD and YOLO.
Occlusion Handling in Generic Object Detection: A Review https://arxiv.org/abs/2101.08845
↓日本語訳
物体検出器は、1段階検出器と2段階検出器の2種類に分類される。
後者は、領域提案ネットワークを用いて関心領域(ROI)を生成し、ディープニューラルネットワークを用いて各提案をクラスカテゴリに分類する。
一方、1段階検出器は、物体検出を回帰問題として捉え、クラス確率とバウンディングボックスの座標を統一的なフレームワークで学習する。
これにより、1段階検出器は、他のタイプの検出器よりも高速になる。
最先端の検出器としては,Faster RCNN、SSD、YOLOなどが挙げられる。
これだけで、物体検出器のおおよその分類/性格/関係性が見て取れる。
何となく単語だけで覚えるよりも、はるかに効率的に学習が進むと思われる。
(※G検定対策に特化した場合は、当然非効率にはなるが・・・)
その他のAI関連記事
LSTMを使用した日経平均株価の予測の記事もかいてるので、興味ある方はこちらからどうぞ。

G検定を受ける前準備について
以下の記事で、G検定受験に必要なブラウザ、画面解像度、回線速度について記載。
あと、要らぬリスクを追わないようにするための対策例。
そして、試験画面についてや、試験時の見直し戦略について記載している。
受験予定の人は斜め読みで良いので読んでおいた方が良いでしょう。

G検定2020#2について
本記事を「見ておいてよかった。」「先にこの記事を見つけていれば。」等のコメントを頂いていることから、2020#2に対しても一定の効果はあったもの思われる。
G検定2020#3について
#1,#2と同様に法規、近年の動向に難易度がよっているのは同様。
G検定2021#1について
出題傾向としてはG検定2020#3を酷似したいた様子。
事前にいろいろ調査した方々は比較的に楽に解くことができ、そうでない人は恒例のテキスト、問題集とのギャップにやられたしまったという2極化が起きている。
G検定2021#2について
この回より、おおよその獲得点数率がわかるらしい。
日本ディープラーニング協会 事務局のメールを引用。
G検定の合格発表はこれまで合格/不合格しか開示しておりませんでしたが、今回より、個人ごとの分野別得点率と受験者全体の分野別平均得点率を開示することといたしました。また、不合格だった場合の合格得点率までのおおよそのポイント差も開示致します。開示情報が増えることにより、皆様の継続的な学びのサポートができれば幸いです。是非この機会にチャレンジしてください。
日本ディープラーニング協会 事務局のメールから抜粋
出題傾向は2021#1にかなり近かった様子。
個の回も事前にどれだけ情報収集できていたからで獲得点数が変わりそう。
G検定2021#3~2023#3
シラバスが変更になってからの2回目以降の試験。
傾向としては2021#2と同一。
G検定を受けてみた感想
まずは大まかな感想。
- ネット上の情報から感じた難易度よりも難しかった。
- 一応、年々難易度が上がっているという情報もあったので過去問、問題集だけでは対応できないとは思っていた。
- 公式テキスト、問題集等から得られる基礎的な知識だけでなく、現時点の新しい知識も求められる
- 強化学習あたりがテキスト、問題集ではあまり語られていない反面、出題数が多い印象
- 自然言語処理関連も予想よりも多い印象
- 2019年に流行ったBERT/transformerの影響?
- 法規関連が最初の方に大量に出てきて心を折れかけさせた
- 個人情報保護、匿名加工、自動運転。著作権、ドローン飛行規制、道路交通法改正(2020#2ではドローン関連問題は出なかったもよう。)
(2020#3ではXAI、営業秘密に関連する問題が増加) - 以下3要件がある。
- 秘密管理性
- 有用性
- 非公知性
- 個人情報保護、匿名加工、自動運転。著作権、ドローン飛行規制、道路交通法改正(2020#2ではドローン関連問題は出なかったもよう。)
- ちょっと意外な問題
- 三平方(ピタゴラス)の定理が出た。
- 確かにベクトルのノルムを算出する時には使うのでAIと無関係ということは無い。
- 三平方(ピタゴラス)の定理が出た。
- 出題数は214問/120分
- 1問あたり33.6秒程度、10問あたり5.6分、50問あたり28分
- よって、50問を20分で解くくらいのペース配分にして、分からないものは一旦切り捨てて後でググる
- 2020#2は200問/120分と問題数が減った。
- その分、難易度が上がったと思われる。
- 2020#3~2022#1は191問/120分
- 2020#3~,2022#1は問題数、問題傾向共に似ている。だいぶ落ち着いたか?
- 2024#6(11月)から160問/120分に。
- このタイミングで2021版シラバスから2024年版シラバスへ。
- 生成AIに関連するもの、経産省AI事業者ガイドラインに関連する用語が追加。
- 見た目上、それ以外も多く追加はされているが、追加と言うより明確化されたものという印象。
- このタイミングで2021版シラバスから2024年版シラバスへ。
- 2026年#1(1月)から
- オンライン試験(自宅受験)は145問/100分に。
- オンサイト試験(会場受験)は145問/120分に。
- 1問あたり33.6秒程度、10問あたり5.6分、50問あたり28分
- 問題集を解きまくって反射的に答えを出すと言いう過学習方式は通用しない。
- 意図的に読んで頭にイメージを浮かべないと何を言っているのかわからない問題文になっている。
- 対策
- 既知の問題文を自分でドロップアウト(隠す場所を変えるとか)させて量産。それを持って自分の脳の汎化性能を引き上げておくと良い。
- Google検索用にマルチモニタ推奨。
- 可能であれば3画面で臨めると吉。
- Firefoxとchromeの両方のブラウザを入れて、片方をG検定用、もう片方を検索用。という使い分けもあり。
G検定(JDLA ディープラーニング ジェネラリスト検定)とは何か?
G検定(JDLA ディープラーニング ジェネラリスト検定)試験概要
私が説明するより、「日本ディープラーニング協会」のwebサイトを直接参照した方が良いでしょう。

一言でいうならば、
ディープラーニングの基礎知識を有し、適切な活用方針を決定して、事業活用する能力や知識を有しているかを検定する。
というもの。
- 基礎知識を有する。
- 活動方針を決定できる。
- 事業活用できる。
こういった人材を指してジェネラリトと呼ぶ。
G検定の過去も含めた合格率と難易度
| 開催日 | 申込者数 | 受験者数 | 合格者数 | 合格率 |
|---|---|---|---|---|
| 2017 | 1,500 | 1,448 | 823 | 56.87% |
| 2018#1 | 2,047 | 1,988 | 1,136 | 57.14% |
| 2018#2 | 2,745 | 2,680 | 1,740 | 64.93% |
| 2019#1 | 3,541 | 3,436 | 2,500 | 72.76% |
| 2019#2 | 5,387 | 5.143 | 3.672 | 71.40% |
これに対して、2020#1は以下になる。
| 開催日 | 申込者数 | 受験者数 | 合格者数 | 合格率 |
|---|---|---|---|---|
| 2020#1 | ? | 6,298 | 4,198 | 66.66% |
合格率は見事に6が並んで・・・。(獣の数字?)
2019年が70%オーバーに対して、2020#1は66.66%と、やや難易度が高めと言える数値になっている。
3人の内2人が合格ということで、普通であれば難易度低めということになるが、受験者としては結構対策している人が多い気がするので、結構そぎ落とされてる印象にはなる。
合格点は公表されていないので、恐らくは合格率の調整が入っていると思われる。
よって、如何に平均より上に行くかが重要と考えて良い。
2020#2も似たような調整になると思う。なった。
| 開催日 | 申込者数 | 受験者数 | 合格者数 | 合格率 |
|---|---|---|---|---|
| 2020#2 | ? | 12,552 | 8,656 | 68.96% |
どうも200問解き終えなくても合格ラインには乗るようなので、テキストベースで落としてはいけない問題を落とさず、そこからの深堀&拡大が出来ていれば基本的にはOKと思われる。
| 開催日 | 申込者数 | 受験者数 | 合格者数 | 合格率 |
|---|---|---|---|---|
| 2020#3 | ? | 7,250 | 4,318 | 59.56% |
ここにきて、合格率が60%を切ってきた。
2020#2の合格発表後のTwitter上で
「ほとんど解けてないのに合格した。意味あるのかこの検定」
のような追及が多数有ったため、その影響なのか?
| 開催日 | 申込者数 | 受験者数 | 合格者数 | 合格率 |
|---|---|---|---|---|
| 2021#1 | ? | 6,062 | 3,866 | 63.77% |
再度、6割越え。
やはり、出題者側としては66.6%あたりを狙っていると思って良いだろう。
| 開催日 | 申込者数 | 受験者数 | 合格者数 | 合格率 |
|---|---|---|---|---|
| 2021#2 | ? | 7,450 | 4,582 | 61.50% |
ここ3回はおおよそ似た傾向と言える。
出題範囲、難易度といろいろ蛇行してきた検定だが、だいたい落ち着いてきたので、
今後は比較的対策しやすい検定となっていくのだと思う。
尚、本試験を受けた同僚/部下の合格通知は以下。
(そのままの数字を載せるのはアレなので若干弄ってる。)
■合否結果
=================
【 合 格 】
=================
総受験者数 7,450名
合格者数 4,582名
■シラバス分野別得点率(小数点以下切り捨て)
1.人工知能とは.人工知能をめぐる動向.人工知能分野の問題:70%
2.機械学習の具体的手法:65%
3.ディープラーニングの概要:72%
4.ディープラーニングの手法:60%
5.ディープラーニングの社会実装に向けて:72%
6.数理・統計:45%
※総合得点率、設問個別の正解・不正解、本試験の合格ライン等は開示しておりません。あらかじめご承知おきください。
合格した中で一番獲得率の低いものをベースにしている。
何を言いたいかというと、6割取れていれば一応合格圏内と言える。
■合否結果
=================
【 不 合 格 】
=================
■あなたの合格正答率までのおおよそのポイント差
=================
【 A 】
=================
総受験者数 7,450名
合格者数 4,582名
【区分】[A:0%~10%]、[B:11%~20%]、[C:21%~50%]、[D:51%以上]
※合格ライン到達まであと何問程度正当する必要があったかを、問題セット全体に対する割合で表したものとなります。
■シラバス分野別得点率(小数点以下切り捨て)
1.人工知能とは.人工知能をめぐる動向.人工知能分野の問題:51%
2.機械学習の具体的手法:59%
3.ディープラーニングの概要:55%
4.ディープラーニングの手法:57%
5.ディープラーニングの社会実装に向けて:50%
6.数理・統計:39%
※総合得点率、設問個別の正解・不正解、本試験の合格ライン等は開示しておりません。あらかじめご承知おきください。
こちらは落ちた中で最も獲得率が高いパターン。
正答率5割ではやはり危険域ということになる。
| 開催日 | 申込者数 | 受験者数 | 合格者数 | 合格率 |
|---|---|---|---|---|
| 2021#3 | ? | 7,399 | 4,769 | 64.45% |
久々に比較的高い合格率に。
この回は知人で受けた人数が少ないので、合格ラインは分かり難いが、
6割ではやや足りない可能性が高い。
恐らく6割中盤あたりがボーダーライン。
検定の問題傾向が落ち着きはじめ、対策が打ちやすくなったことで、全体の得点率が上がってきたのだと思われる。
| 開催日 | 申込者数 | 受験者数 | 合格者数 | 合格率 |
|---|---|---|---|---|
| 2022#1 | ? | 6,760 | 4,198 | 62.10% |
この回は知人の受験者は1名だけなので情報がかなり少ない。
といあえず印象だけ聞いてみたところ、直近1年とは大きく変わっていないようである。
| 開催日 | 申込者数 | 受験者数 | 合格者数 | 合格率 |
|---|---|---|---|---|
| 2022#2 | ? | 6,398 | 3,917 | 61.22% |
似たような傾向が続いている。
ちょっと気になる点としては、徐々に受験者数が減ってきている点?
| 開催日 | 申込者数 | 受験者数 | 合格者数 | 合格率 |
|---|---|---|---|---|
| 2022#3 | ? | 7,502 | 4,964 | 66.17% |
この回は11/4金、11/4土の2日開催(どちらか片方の日付を選んで受験)であったためか、少し受験者数も多めになっている。
合格率も久々の66%越え。
といっても問題が簡単になったわけではなさそう。
ネットや書籍による情報が増え、うまく対策できる下地ができてきたのかもしれない。
| 開催日 | 申込者数 | 受験者数 | 合格者数 | 合格率 |
|---|---|---|---|---|
| 2023#1(3月) | ? | 7,150 | 4,705 | 65.80% |
| 2023#2(5月) | ? | 3,052 | 2,075 | 67.99% |
| 2023#3(7月) | ? | 4,518 | 3,106 | 68.75% |
| 2023#4(9月) | ? | 3,309 | 2,390 | 72.23% |
| 2023#5(11月) | ? | 5,330 | 3,662 | 68.71% |
| 2024#1(1月) | ? | 3,291 | 2,398 | 72.87% |
| 2024#2(3月) | ? | 5,527 | 3,760 | 68.03% |
| 2024#3(5月) | ? | 3,044 | 2,236 | 73.46% |
| 2024#4(7月) | ? | 4,130 | 3,080 | 74.40% |
| 2024#5(9月) | ? | 4,917 | 3,689 | 75.03% |
2022年までは3月、7月、11月の年3回開催だったが、
2023年からは3月、5月、7月、9月、11月の年5回開催。
2024年からは1月、3月、5月、7月、9月、11月の年6回開催。
3月、7月、11月に関しては金曜日、土曜日の2日開催になっている。
1月、5月、9月は従来ではなかった開催日且つ1日開催であるため、受験者薄は半数以下。
合格率にはそれほど影響してい無さそうだが、2023#4は70%オーバーになっている。
いろいろ情報が出回っているため、皆うまく対策しているのだろう。
| 開催日 | 申込者数 | 受験者数 | 合格者数 | 合格率 |
|---|---|---|---|---|
| 2024#6(11月) | ? | 6,850 | 5,027 | 73.39% |
| 2025#1(1月) | ? | 4,633 | 3,414 | 73.69% |
| 2025#2(3月) | ? | 6,401 | 4,776 | 74.61% |
| 2025#3(5月) | ? | 4,284 | 3,501 | 81.72% |
| 2025#4(7月) | ? | 7,440 | 5,811 | 78.10% |
| 2025#5(9月) | ? | 7,924 | 6,051 | 76.36% |
| 2025#6(11月) | ? | 10,350 | 8,005 | 77.34% |
| 2026#1(1月) | ? | 8,529 | 6,718 | 78.77% |
2024#6(11月)から2024年版新シラバスに変わったタイミングとなる。
しかし、合格率を見るとそれほど影響は無かった様子。
新シラバスに変わったと言っても、
生成AI関連用語が増えた以外はどちらかというと「明確にシラバスに記載された」ものが多いので、
実質的には影響なかったと思われる。
(統計検定3級程度の部分の明確化とAI事業者ガイドライン発行による明確化がされ学習しやすくなった)
| 開催日 | 申込者数 | 受験者数 | 合格者数 | 合格率 |
|---|---|---|---|---|
| 2026#1(1月) | ? | 8,529 | 6,718 | 78.77% |
| 2026#2(3月) | ? | 10,483 | 8,264 | 78.83% |
| 2026#3(5月) | ? | 6,824 | 5,802 | 85.02% |
2026年から、問題数が145問、時間は100分(オンライン)、120(会場)に変更
これも合格率を見るとそれほど影響はなかった様子。
G検定は文系・未経験でも合格可能か?【必要な数学レベルと対策】
良く聞かれる質問ではある。
結論としては文系、理系はあまり関係ないので十分可能。
理由は以下。
- 数学的解釈が必要な項目は少ない。
- 2,3問あるかないか
- どちらかというと歴史や法規に紐づく問題が多い。
言い回しが理系的なだけであって、
実際の内容は歴史、法規の性質が強いため、
実は文系の方が向いているような気がする。
私個人としては
「文系でも受かるG検定」というよりも、
「理系でも受かるG検定」という書籍の方が必要なのでは?
と思ったりする。
※ 当然インパクトの無いタイトルなので売れないでしょうが。
G検定を受けるモチベーション
人によっては目的が無いと頑張れない人いるかと思う。
私もその一人であり、G検定を受ける上のモチベーションありき。
ちなみに私の「G検定を受けるモチベーション」は、
AI関連の案件受ける際のコミュニケーションに必要な知識の獲得。
昨今のAIブームに乗っかり、個人的に既存のアルゴリズムを試したりはしてるが、
全体像を把握しているわけではない。
これが災いしてか、ちょっとしたAI、機械学習の用語が拾えないということもシバシバ。
そもそも言葉を知らないとか、成り立ちを知らないというのが、
結構案件獲得に対して印象を悪くしていた。
これを払拭するために、G検定を受験することを決めた。
つまり、「AI関連知識の全体像と基礎を押さえたい」という部分になる。
これ以外にも様々なモチベーションは考えられる。
- AI関連技術者になるための基礎知識を身に着けたい。
- AI関連事業を興したい。
- 自社の作業効率化にAIを導入したい。
etc
G検定対策前の私のスペック
- 趣味でDNNを少しかじってる。
- 「ディープラーニングの概要」の8割程度の知識
- 「ディープラーニングの手法」の5割程度の知識
- 「ディープラーニングの研究分野」の4割程度の知識
- 上記の絡んでニューラルネットワーク以外の機械学習も知識レベルで少し保有
- 「機械学習の具体的手法」の3割程度の知識
- 微分積分、ベクトル、行列に対しては特に抵抗感は無い。
つまり、素の状態では214問中60問程度で正答率28%程度だったと言える。
これが知識ゼロからスタートする方と比較した際の私のアドバンテージとなる。
微分積分、ベクトル、行列に関して。
問題としてはそれぞれ1問出るか出ないか程度なので、この部分ではアドバンテージはなし。
G検定の勉強時間の目安は?【働きながら合格するためのスケジュール例】
G検定に向けての対策は試験日から2週間前から開始。
一日の学習時間は通勤時間の学習も合わせて2時間程度。
つまり、28時間の学習時間となる。
しかし、正直28時間では不足だったと認識している。
下で紹介している白本、黒本、AI白書をじっくりやって1周しかできず、正直言って知識として定着したかはあやしい。
よって、私と同様に一日に2時間程度しか学習時間を割り当てられない方は試験日1ヶ月前から学習開始して白本、黒本、AI白書を2周した方が良い。
G検定対策として学習に使用した本(テキスト、問題集、時事)
※ 2024年11月より新シラバスに移行しているため、テキスト、問題集も2024年以降のものを選択した方が吉。新しければ良いというわけでもないのが悩ましい・・・。
いわゆる白本と黒本。加えてAI白書。
私の場合は白本側でガッチリと全体像を捕まえて黒本とAI白書で随時補強していく方針で実施。
正直、白本だけでは今回のG検定の問題の半分も解けない。
黒本加えれば半分は解けそう。
AI白書の補強分でやっと6割越えだったかと。
ディープラーニングG検定公式テキスト(通称白本)

白本の第2版が出版されたもよう。(2021年5月11日)
当然、こちらで学習した方が良いだろう。
差分としては、Self-Attention、Transformer、BERT、GPTの明確に追加されていた。

白本の第3版が出版されてもよう。(2024年6月2日)
生成AIに付随する情報が増えているように見える。
Diffusion Model、基盤モデル&転移学習&ファインチューニング関連、マルチモーダル、モデルの軽量化(蒸留、プルーニング、量子化)などなど

徹底攻略 ディープラーニングG検定 ジェネラリスト問題集(通称黒本)

こちらも第3版が出版されたようす。
新しい方が良いだろう。
徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版(通称、黒本)

AI白書
※ 試験中に検索することを想定するとKindle版の方が良いかも。

あと、松尾 豊 先生の「人工知能は人間を超えるか ディープラーニングの先にあるもの」は読んでおいた方が良い。
白本と被る内容は多いが、シナリオとして認識する文系脳の方は相性が良いかと。

短時間でさらっと勘所を捕まえたい場合ははマンガで読むのもあり。

私は持ってないが、AIカルタで学習というのも、取っ掛かりとしては面白いかもしれない。
(G検定頻出ワードを多数収録。JDLA推薦商品。って書いてあった。)

あと、たまたま本屋で立ち読みした本だが、以下などは比較的昨今のG検定の内容を踏襲しているように見受けられた。
BERT/transformer、XAI(Explainable AI:説明可能なAI)についても触れらていたので、今後のG検定の対策としては有効と思われる。

G検定2021#1に於いて8割方網羅されてたと言われる
「最短突破 ディープラーニングG検定(ジェネラリスト) 問題集」
だから大丈夫。とはならないあたりが厄介ではあるが。

2024年以降のテキスト問題集。
・ディープラーニングG検定(ジェネラリスト)最強の合格テキスト[第2版] [徹底解説+良質問題+模試(PDF)]
・ディープラーニングG検定(ジェネラリスト)最強の合格問題集[第2版] [究極の332問+模試2回(PDF)] (まっすぐ合格シリーズ)

ディープラーニング関連の法律、倫理に関する書籍。
タイトル通り、G検定をターゲットとしている。
テキスト、問題集では拾えてない領域をカバーしているので、流し読みだけでもしておいた方が良さそう。

Kindle Unlimitedの利用
Kindle Unlimitedによる\0の書籍を利用するのもあり。
最近は\0のG検定対策本が結構出ている。



Kindle Unlimited自体が月額\980なので本当の意味では\0とは言い難い。
しかし、30日間の無料期間があるので、G検定受験の1か月前に無料登録をして、G検定対策本を読み漁ってから解約という手も使えなくはない。
(Amazon的には迷惑かもしれないが・・・。)
学習のコツ(出題者側の思考)
出題者側の思考を考えてみるのが手っ取り早い。
出題者に課せられた重大ミッションはおおよそ以下になる。
- 合格点はおおよそ〷点にしたい。(たとえば60点)
- 勉強していない受験者を即行で切りたい。
- 上記に伴い、合否を二極化(または三極化)したい。
しかし、普通に出題すると、平均点を中央値とした正規分布になる。
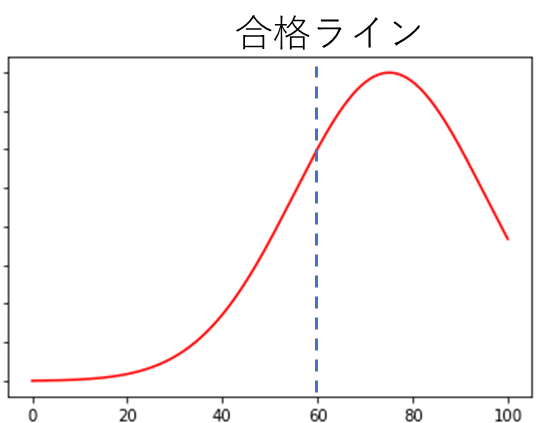
この合格ラインはかなりのボリュームゾーンで、1点の差で合否が分かれる人が多発する。
正直、この状態は避けたい。
よって、以下のような分布したいというのが人情。
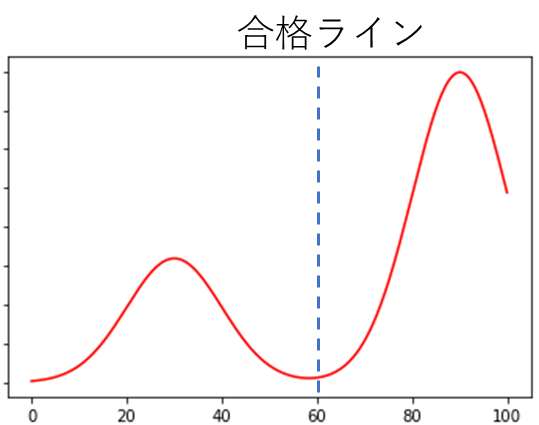
よって、ボリュームゾーンを35点と75点とした、ふた山の分布が望ましい
この場合、60点以上を取らせるためには、過去の問題や巷に流れている問題集から出題用の問題を持ってくる。
つまり、「この問題解いた事ある!ラッキー」ではなく、
「ヤバイ。出題者に解かされている!この問題は絶対落とせない」と考えるべきとなる。
これがほとんど解けない場合は、不合格確定。
次に二極化についてだが、
勉強してきた受験者の傾向も2つに分かれる。
- 問題集をベースに慣らしてきた。(たぶん、8割の人間はこっち)
- 情報を構造化して知識として定着してきた。(のこり2割はこっち)
G検定の場合、合格率66%を狙っているようなので、
前者の半分くらいを合格させる難易度に設定してくる。
つまり、問題集等で語られてはいるが、ちょっと論点、視点をずらす問題を散りばめてくることが予想できる。
これも半分は解けるようにしておかないと少し危険域に入る。
このような受験者の分布を散らしたいという出題者側の思考には注意しておいた方が良い。
合格ライン上で団子状態になるのは、出題者側からすると確実にさけたいはずなので。
そもそもとして、後者の「知識として定着」であれば全く問題は無い。
真のG検定対策
これは意外と盲点になってるのかもしれないが、実はG検定のシラバスに出題される題材が全部記載されている。
ななめ読みするとわかるが、公式テキスト、黒本等の問題集にも載っていない単語が結構ならんでいるはず。
よく、G検定受験後に公式テキストで語られていない問題が出ていることをSNS上で激怒している方々を見受けられるが、その事実は本来受験後のセリフではなく、シラバス確認後に発すべきセリフである。
単に情報収集不足にしか見えないというのが本音である。
つまり、このシラバスを読まずしてテキスト、問題集、チートシートに走ると結構不利な状態になる。
(試験当日に聞いたことも無い単語の連発に心をくじかれる)
最初にシラバスを読み、学習が進んだところでまたシラバスを読み返し、試験直前もシラバスを2,3回読み返すくらいはやっておいた方がよい。
シラバスがJDLA公式のカンペになっているはずである。
もうちょい言うと、試験後にもシラバス見ておくのもおすすめ。
シラバスはJDLAの以下のサイトの一番したでPDFとして公開されている。
(URLが変わるかもしれないので、その場合はJDLAのサイトから探してください。)

ちなみに、常にG検定に対するクレームの的になる、法律系、最新動向系は
「ディープラーニングの社会実装に向けて」
というカテゴリの話となる。
これを見た感じだと、これから外れた問題はそうそう出てはおらず、そういう意味ではクレームをつけるほどの話ではないと思う。
G検定カンペ(チートシート)は作るべき?【作り方と注意点】
まず、JDLA的にカンペ(カンニングペーパー、チートシート)を使ったりGoogle検索で答えるのは推奨されてはいない。
禁止が明言されているわけではないが、一般常識と範囲としてそうなってるはずである。
しかし、Web試験という性質上、実質的には許容されているといったところ。
で、カンペ(カンニングペーパー、チートシート)の要否については、用意する分にはOKだと思う。
使う使わないかは本人お任せではあるが、カンペを作ると結果的に脳内で情報が整理されるので、
本番に於いてはカンペに書いたものはカンペを見なくても解ける。という事象が発生する。
これを理由にカンペ作成のみ推奨。
一応、本記事の後ろの方に私が作成したカンペ画像を貼っているので、カンペ作成予定の方は参考にどうぞ。
たぶん、巷のカンペ、チートシートを謳ってるサイトよりもまとまってるかも・・・。
少なくとも単語だけをまとめたカンペはG検定に対しても、合格した後に対しても
あまり意味のあるカンペの作り方では無いというのが私の認識である。
NoteとかでG検定のカンペを販売しているのをたまに見かけるが、
他人が作ったチラ裏カンペを買うのにどれほどの意味があるのかも正直言って疑問。
(ネガキャンではございませぬ。)
あと、一問を37秒のペースで解くG検定の場合、
他人が作ったカンペから出題部分を拾い上げる時間はそもそも無いとも思ってる。
というわけで、良し悪し以前にカンペによる対策は相性があまりよろしくない。
無料模試によるG検定対策 その1
Study-AIさんの無料β版の模試が有名。
※ 要ユーザ登録(無料)

一時期は、ここの問題がそのまま出るような記事もあった。
2019#2か#3か、どのタイミングからかはわからないが、
現在に於いては、さすがに「そのまま出題」ということは無くなった。
上記の学習のコツでも書いたが、
出題者の思考を考えると、受験者がこの模試を受けてきているのは予想に固い。
よって、ちょっと観点をずらした問題を出さざるを得ない状況になっていると推測される。
あと、無料β版であるため、文句を言える義理は全くないのだが、
選択肢に答えがない、選択肢が間違っている問題が散見される。
StudyAIさんの方でメンテナンスされたようで、現在では修正されてます。
以下は「G検定の初期のころはこういうこともあったよ」程度で読み流して下さい。
例えば、以下の問題
(エ)に最もよくあてはまる選択肢を 1 つ選べ.
ニューラルネットワークで用いられる活性化関数について扱う.出力層の活性化関数には,回帰では(ア)が,多クラス分類では(イ)が一般的に利用されてきた.また中間層の活性化関数として,従来は(ウ)などが一般的に利用されてきた.しかし,これらの活性化関数を利用すると勾配消失問題が起きやすいという問題があったため,近年は,入力が 0 を超えていれば入力をそのまま出力に渡し,0 未満であれば出力を 0 とする(エ)や複数の線形関数の中での最大値を利用する(オ)などが利用されている.
選択肢
1.動経基底関数
2.ソフトマックス関数
3.Maxout
4.ステップ関数
Study-AIさんの回答としては4となっており、明らかに回答側が間違っている。
(エ)に入るのはReLUなのだが、
正しい選択肢は以下のどれか。
・ReLU(Rectified Linear Unit)
・正規化線形関数
・整流線形関数
・ランプ関数
恐らくは「ランプ関数」が本来の選択肢になっていたところを
間違って「ステップ関数」としてしまったと思われる。
※ランプ関数、ステップ関数は制御に於いての応答性評価によく使われる関数名称。
この問題は、本来であれば良問で、
ReLUの別名を把握しているかを問うているもの。
しかし、ちょっとしたケアレスミスで悪問と化して、受験者を毎回悩ましているようだ。
無料模試によるG検定対策その2
最近もう一件、無料模試が出てきていた。
※ 要ユーザ登録(無料)

私の方で一通り、解いてみたが、StudyAIさんよりは最近の動向に沿っていはいる。
ただ、これで網羅しているレベルではないので、「繰り返し解いて慣らす」という方法はお勧めできない。
Study-AIさんの模試と併用して、自分の苦手領域の把握に利用した方が良いだろう。
無料模試によるG検定対策その3
G検定特化の模試ではないが、一応紹介。
MATLABで有名なMathworks社の機械学習10問クイズ。
※ 今は存在しないようです。
https://explore.mathworks.com/jp-machine-learning-knowledge-quiz

無料模試によるG検定対策その4
上の方でも紹介したが、法規/時事問題特化問題集。
問題自体は、arXiv等で見かけた文献をベースに、抄読会を実施した際の近年の法規/目玉AIモデルの話を問題文形式にしてるので割と最新情報はキープできていると思う。
無料対策講座によるG検定対策
「資格試験のオンライン対策サイト【資格スクエア】」さんの講座に、まさにそのままのG検定対策講座というのがある。
オンラインの無料体験講義があるので、ここで一回サラッと概念を掴んでしまうというのも一手。
何事も取っ掛かりは重要で、取っ掛かりさえあれば、後は結構自力で学習サイクルを回せると思う。
取っ掛かりが欲しい方は以下サイト参照。

G検定で終わらず、その後にAI関連の転職まで意識している場合は「AIジョブカレ」さんも選択肢にはいってくる。こちらも無料相談会があるので受けてみるもの良いかもしれない。
「G検定直前対策講座」というのもあり、325分(5時間半くらい)の講座と、
200問の予想問題が用意されている。
学習時間が取れない人向けとしては良いかもしれない。

「Aidemy」さんの無料ビデオカウンセリング受講もありでしょう。
講座としては↓こんな感じの演習問題を解いていくイメージ。
-1024x592.png)

G検定対策としてのその他の活動(カンペ的なものとも言える)
あとはインプットだけでなく、アウトプットの方も意識。
簡単に言うと、調べた内容をノートに纏めるなど実施。
本サイトでも掲載しているが、以下のように情報をまとめる作業をしている。
(使用禁止とされているがカンペ(カンニングペーパー、チートシート)にもならなくもない・・・。)
以降、シラバスに則って出題数、難易度、情報量、対策方法等を説明。
G検定(ジェネラリスト) 公式テキスト

徹底攻略 ディープラーニング g検定 ジェネラリスト問題集

AI白書

人工知能は人間を超えるか ディープラーニングの先にあるもの (角川EPUB選書)

ディープラーニングG検定(ジェネラリスト) 法律・倫理テキスト

人工知能(AI)とは
| 項目 | レベル |
|---|---|
| 検定出題数 | 極少(1問) |
| 検定難易度 | 低 |
| Web情報量 | 少 |
| 過去問、問題集だけで対応可? | OK |
さらっと流してOKな部分。

人工知能をめぐる動向
探索・推論、知識表現、機械学習、深層学習
| 項目 | レベル |
|---|---|
| 検定出題数 | 中(19問) |
| 検定難易度 | 低 |
| Web情報量 | 多 |
| 過去問、問題集だけで対応可? | おおよそOK |
情報量が多い割には出題数も少な目で難易度も低い。
逆説的に言うと落としてはいけない部分と言える。
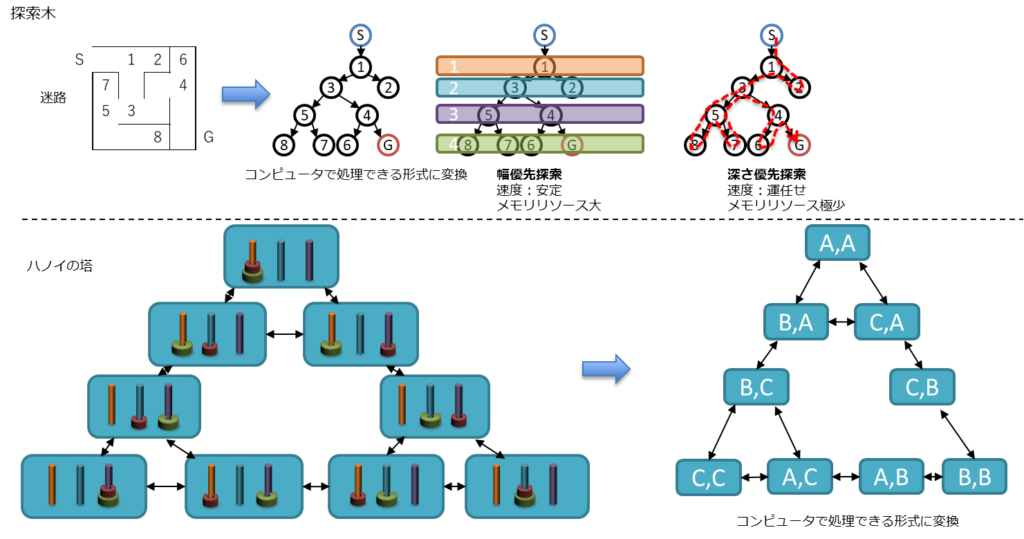
探索木の構造にすることで、コンピュータが処理できる形式にすることが重要。
仕組みが分かると知性は感じられない。と感じるのがAI効果。
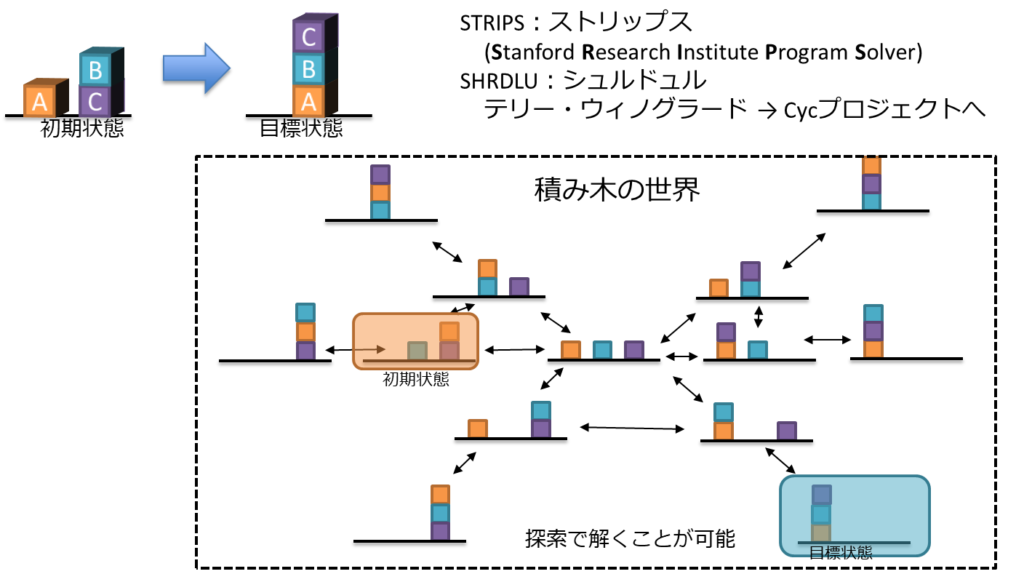
「積み木の世界」を例とされることが多い。
- STRIPS:ストリップス
- SHRDLU:シュルドュル
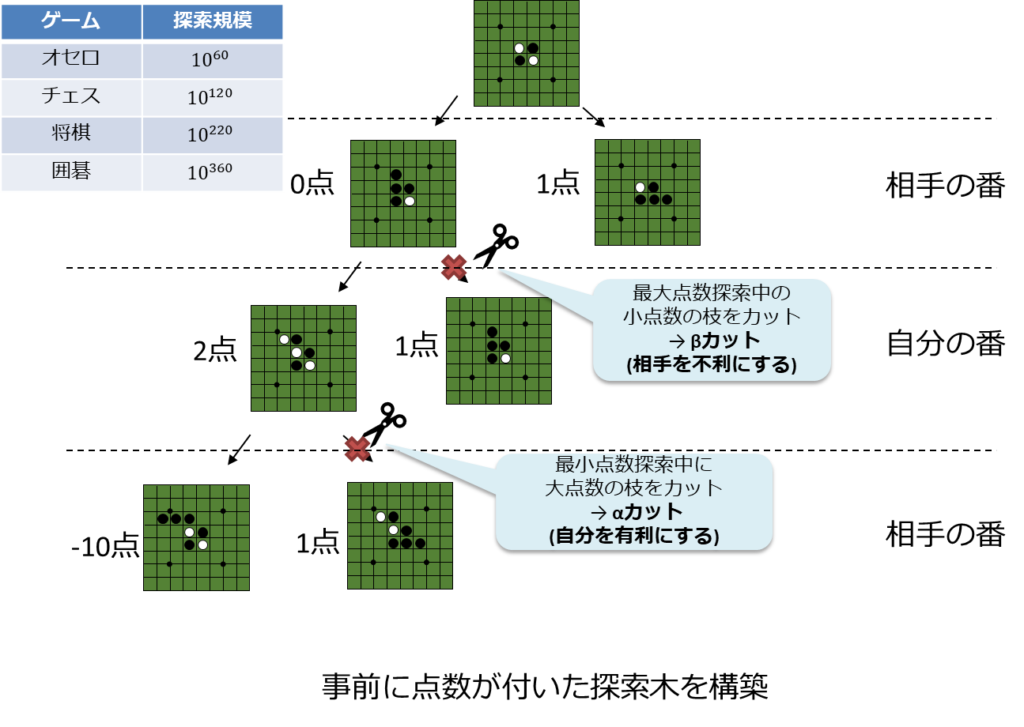
これも基本は探索木になる。
迷路の探索木に似ているが、「行動」と「結果」の連続した探索木となるが、局面が複雑化するタイプになると、それだけ膨大なツリーとなる。
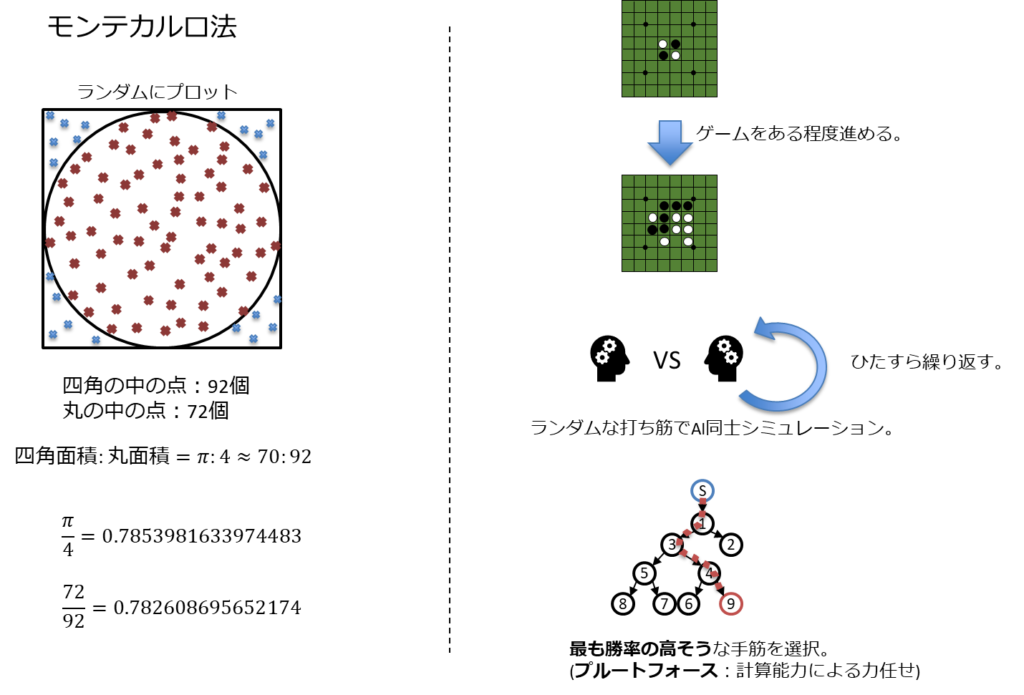
推論、探索の時代は、基本、「初期状態」「行動」「結果」が明確であることをベースにしている。
後期に入るとモンテカルロ法の方な確率論が導入され始める。
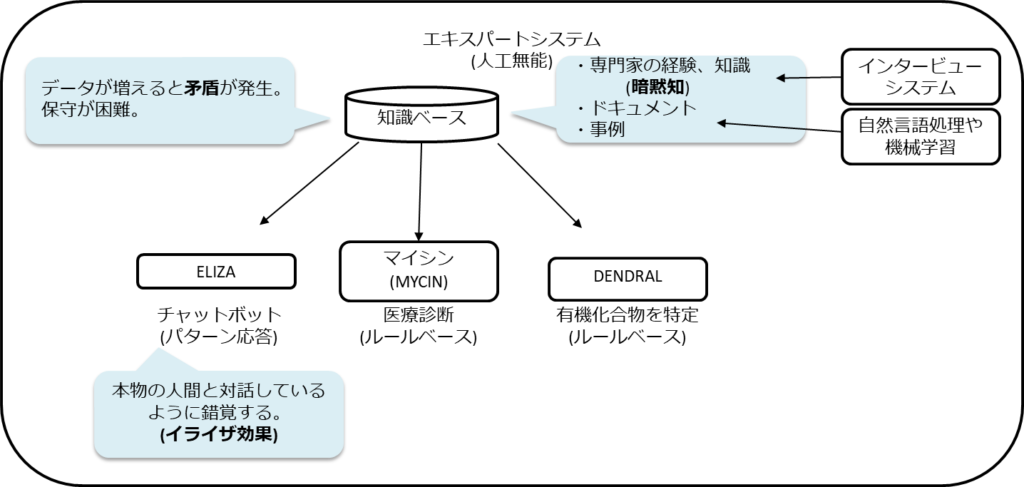
第2次AIブーム初期は単純なパターンマッチで知識を表現しようとした。
しかし、その知識の獲得や管理に課題が出てきた。
それを解決するために意味ネットワークやオントロジーの研究が注目される。
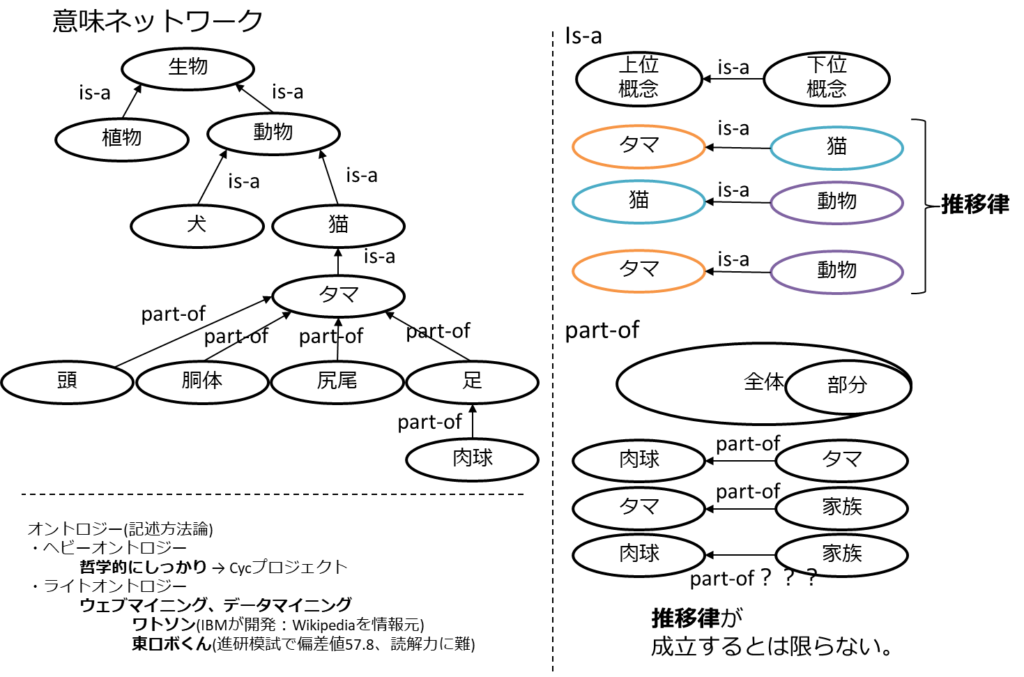
オントロジーにより、意味ネットワークが構築され、人の知識に近いものが出来てきた。
第1次AIブームと比べると現実世界に対して影響を持ち始めた時期となる。
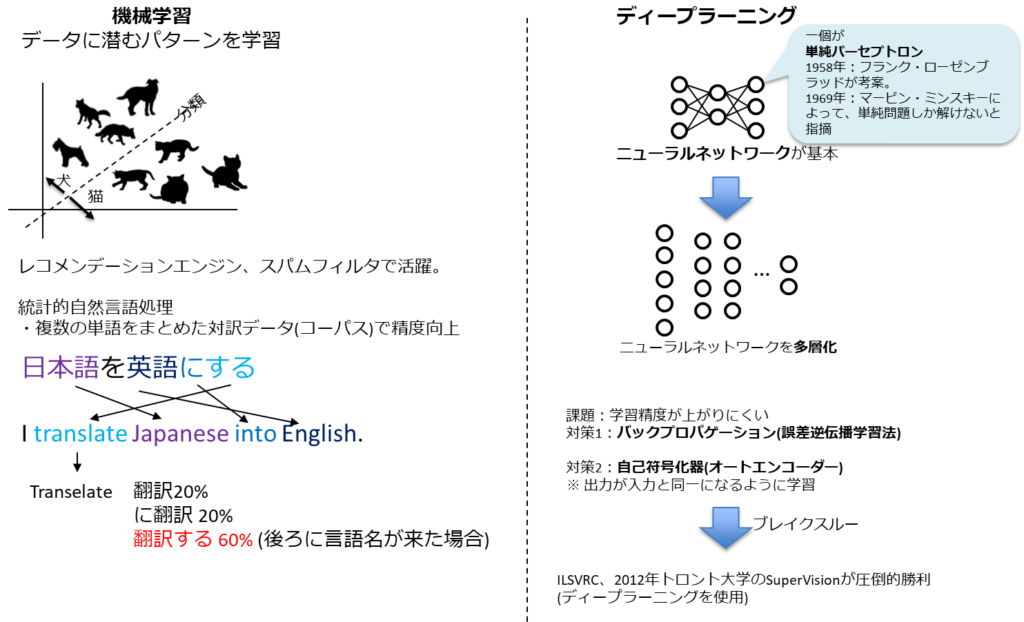
ディープラーニングの元となるニューラルネットワーク自体は第1次AIブーム時から存在していた。
バックプロパゲーションなどの学習方法、コンピュータの処理能力、学習するデータ量により一気に進展し、ブレイクスルーへ。

人工知能分野の問題
トイプロブレム、フレーム問題、弱いAI、強いAI、身体性、シンボルグラウンディング問題、特徴量設計、チューリングテスト、シンギュラリティ
| 項目 | レベル |
|---|---|
| 検定出題数 | 少(4問) |
| 検定難易度 | 低 |
| Web情報量 | 少 |
| 過去問、問題集だけで対応可? | おおよそOK |
基本的にはお約束的な問題が出るのみ。
テキスト、問題集をやっていれば問題ない。
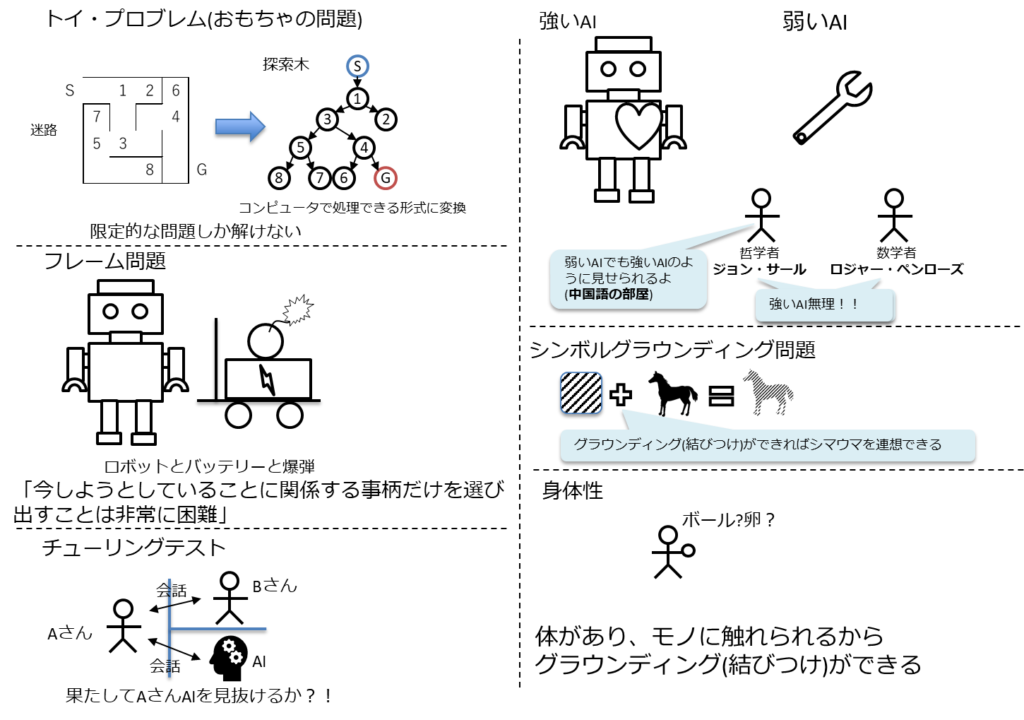
知能、知性に至るのは多くの課題がある。
ゴールを「便利な道具」とするか「人間のパートナー」とするかでも大きく変わる。
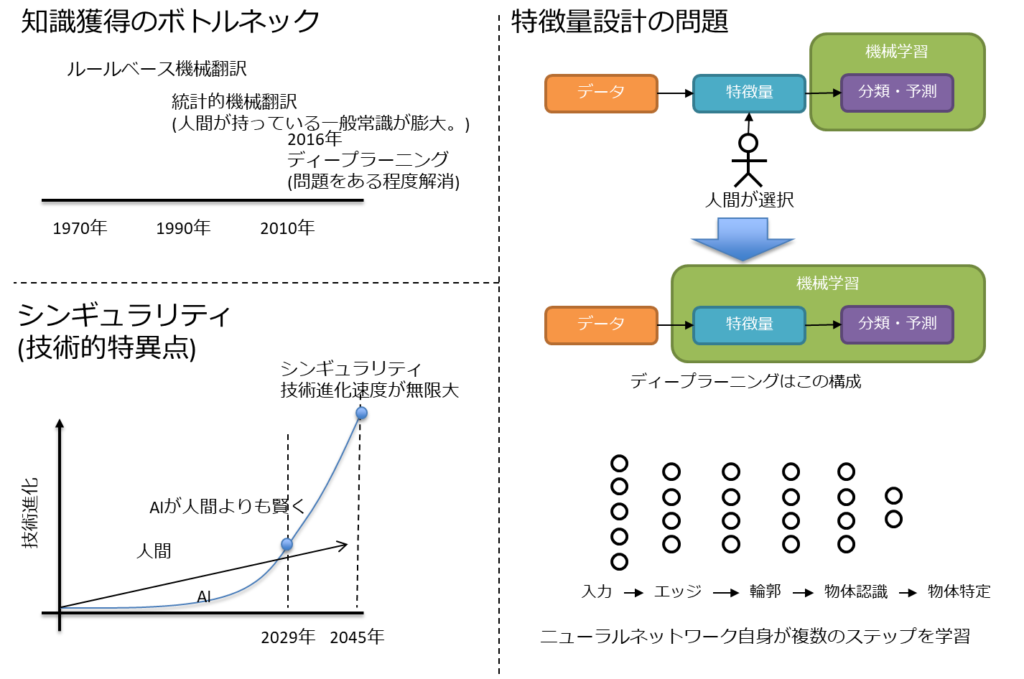
解決していない問題はあるが、ディープラーニングにより解決した問題も多い。
シンギュラリティ(技術的特異点)はもうすぐ。

機械学習の具体的手法
代表的な手法、データの扱い、応用
| 項目 | レベル |
|---|---|
| 検定出題数 | 極多(54問) |
| 検定難易度 | 高 |
| Web情報量 | 多 |
| 過去問、問題集だけで対応可? | 不足 |
出題数は最多の部分となる。
ただし、勉強し易い部分ともいえるので、ここで頑張って点を稼ぐ必要がある。
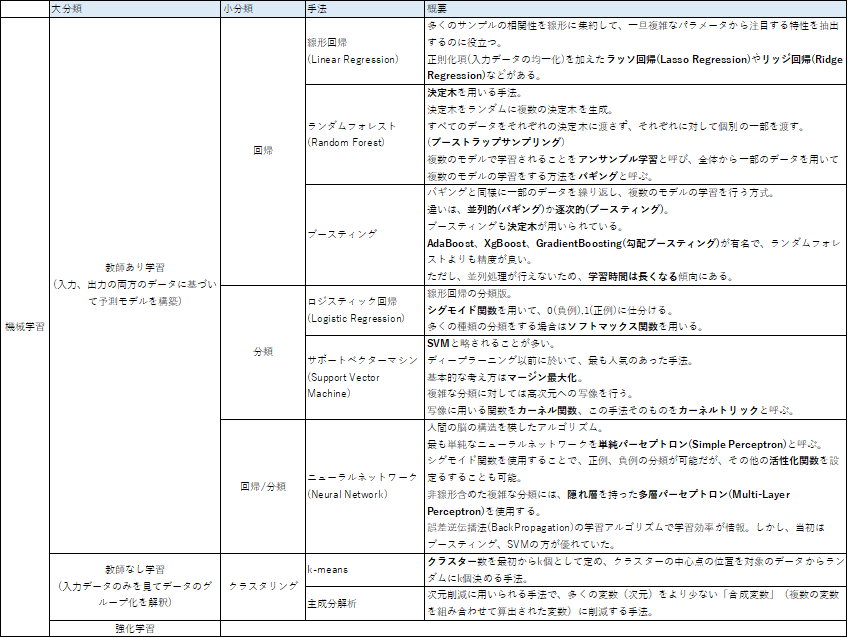
機械学習でも目的別にカテゴリ分けができる。(教師あり:回帰、分類、教師なし:クラスタリング)
ディープラーニングが流行りの世の中ではあるが、可能な限りシンプルな手法による解析が重要な場合を想定して、今回の手法を頭の片隅にでも置いておいた方が良い。
学習する際に学習結果を評価する必要がある。
単に正解率が高いが優秀とは限らず、間違い検知率が高いことが重要な場合もある。

G検定強化学習対策(概要編)
ディープラーニングの概要
ニューラルネットワークとディープラーニング、既存のニューラルネットワークにおける問題、ディープラーニングのアプローチ、CPU と GPU
ディープラーニングにおけるデータ量
| 項目 | レベル |
|---|---|
| 検定出題数 | 少(7問) |
| 検定難易度 | 低 |
| Web情報量 | 少 |
| 過去問、問題集だけで対応可? | おおよそOK |
ここは流してOK。
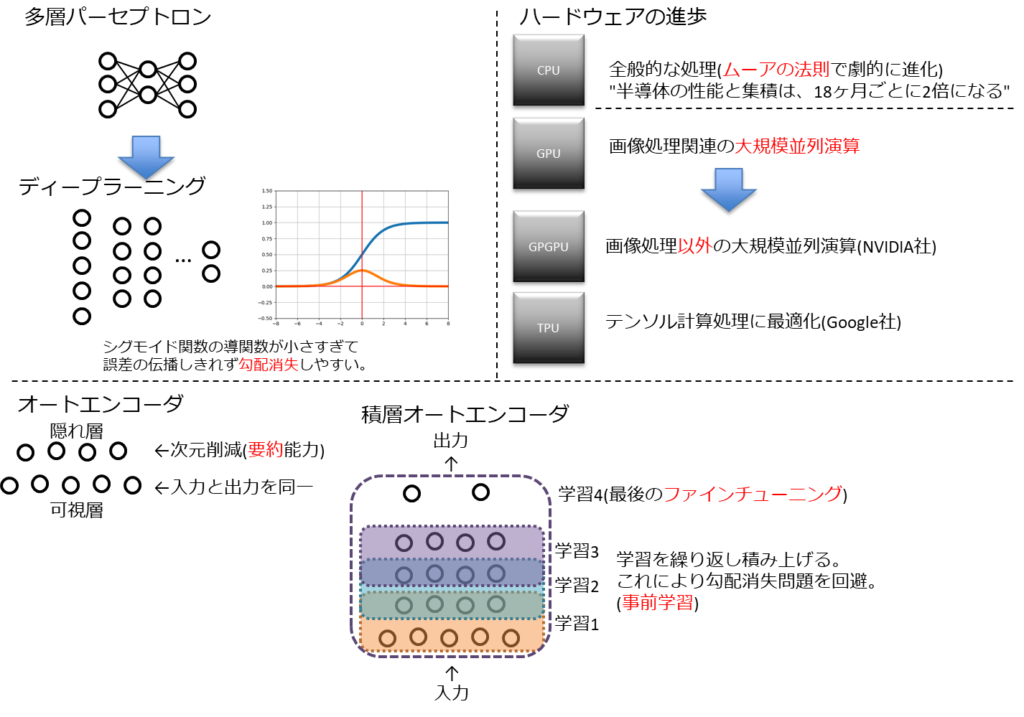
- ニューラルネットワークを元にさらに隠れ層を増やしたディープニューラルネットワークが登場。
- しかし、隠れ層を増やしたことで勾配喪失や計算コストに課題が発生。
- 計算コストはCPUやGPUの発展に助けられた部分はある。

ディープラーニングの手法
活性化関数、学習率の最適化、更なるテクニック、CNN、RNN
深層強化学習、深層生成モデル
| 項目 | レベル |
|---|---|
| 検定出題数 | 極多(46問) |
| 検定難易度 | 高 |
| Web情報量 | 多 |
| 過去問、問題集だけで対応可? | 不足 |
「機械学習の具体的手法」に続いて多い部分。
G検定のメインの部分なので当然と言えば当然。
一番調べやすい部分なので学習はし易い。
- 勾配降下法で楽に誤差関数を0に近づける手法が主流になった。
- 活性化関数のバリエーションを増やすことで勾配を作りやすくした。
- 局所最適解や鞍点に陥らないような学習アルゴリズムが登場。
- さらに精度を高めたり、精度が上がることによるオーバーフィッティング抑制など手法自体も微調整される状況となった。
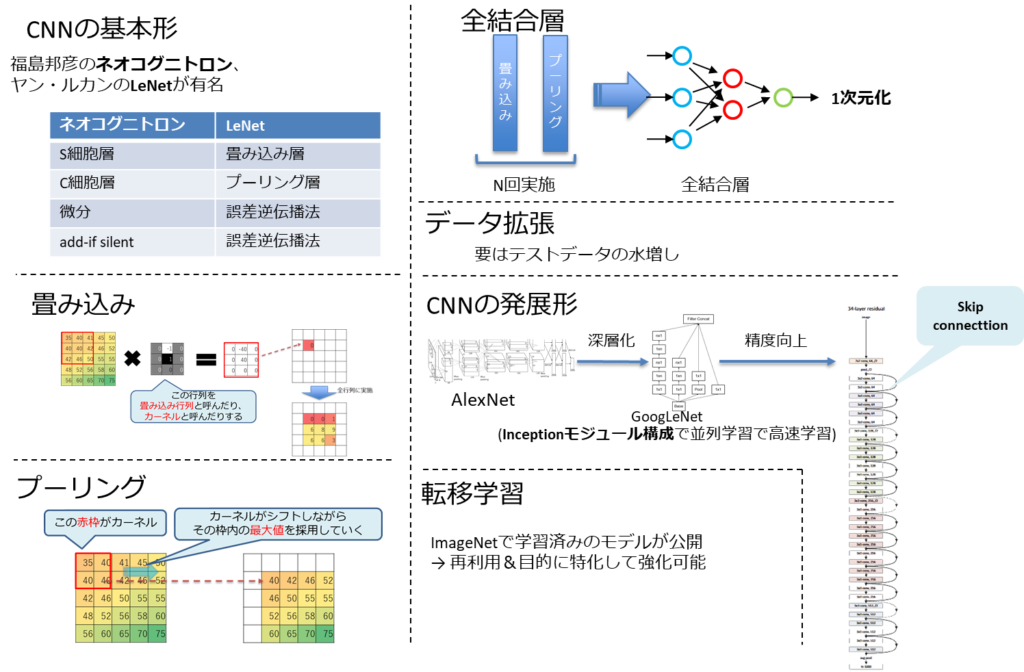
- 画像による物体認識は長年の課題の一つであり、それが解決しつつある。
- しかし、それには膨大な学習が必要となるが、公開されているネットワークも多い。
- 公開ネットワークに層を追加しファインチューニングすることで手早く高性能なネットワークが獲得できる。
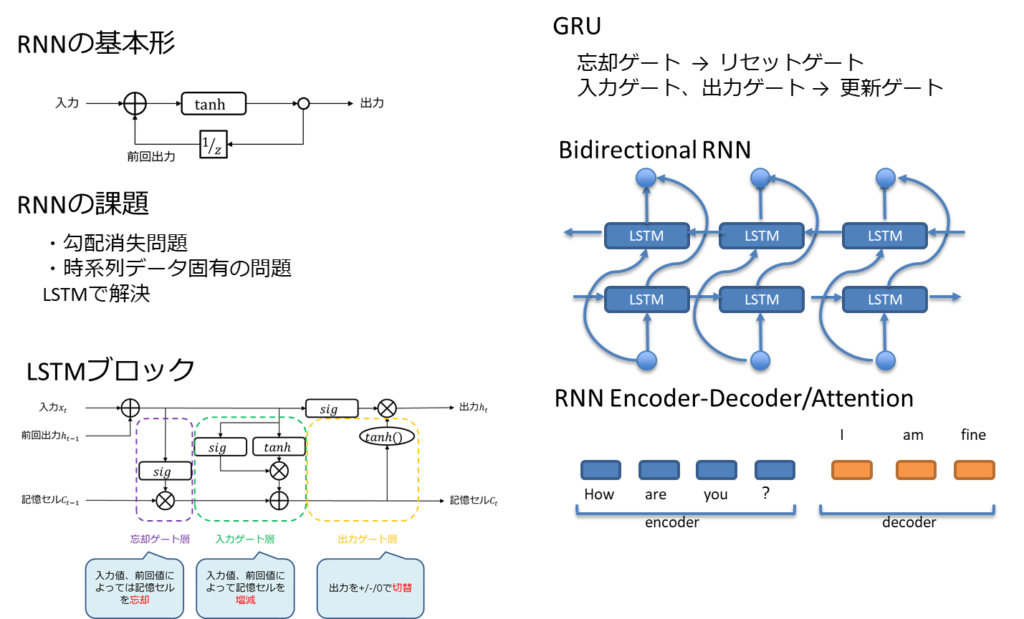
- 時間の概念は本来であれば、微分積分の領域であるが、ニューラルネットワークでも過去、未来をデータとして持つことで表現可能
- LSTMの考え方が重要で、それらの組み合わせ方でRNNの発展形が出来る。

- 答えのない目的を持たせた強化学習とディープラーニングの組み合わせとして深層強化学習が存在。
- 生成タスクとして、何もないところからデータを生成する深層生成モデルが存在。(画像生成モデル)

強化学習特化記事
G検定強化学習対策(概要編)
ディープラーニングの研究分野
画像認識、自然言語処理、音声処理、ロボティクス (強化学習)、マルチモーダル
| 項目 | レベル |
|---|---|
| 検定出題数 | 中(38問) |
| 検定難易度 | 高 |
| Web情報量 | 中 |
| 過去問、問題集だけで対応可? | 大きく不足 |
先の「ディープラーニングの手法」が基礎とするならば、こちらは応用側となる。
若干調べにくく、点に差がつくところ。
2020#2ではU-Netの図解が出たらしい。
U-Net以外にFCN、SegNet、SSD、YOLOなどの構成図は一取り見ておいた方が良いだろう。
年々、急速に発展している部分なので、公式テキスト、問題集では直近3年分に関してはフォローできていない。この点を注意して対策する必要がある。
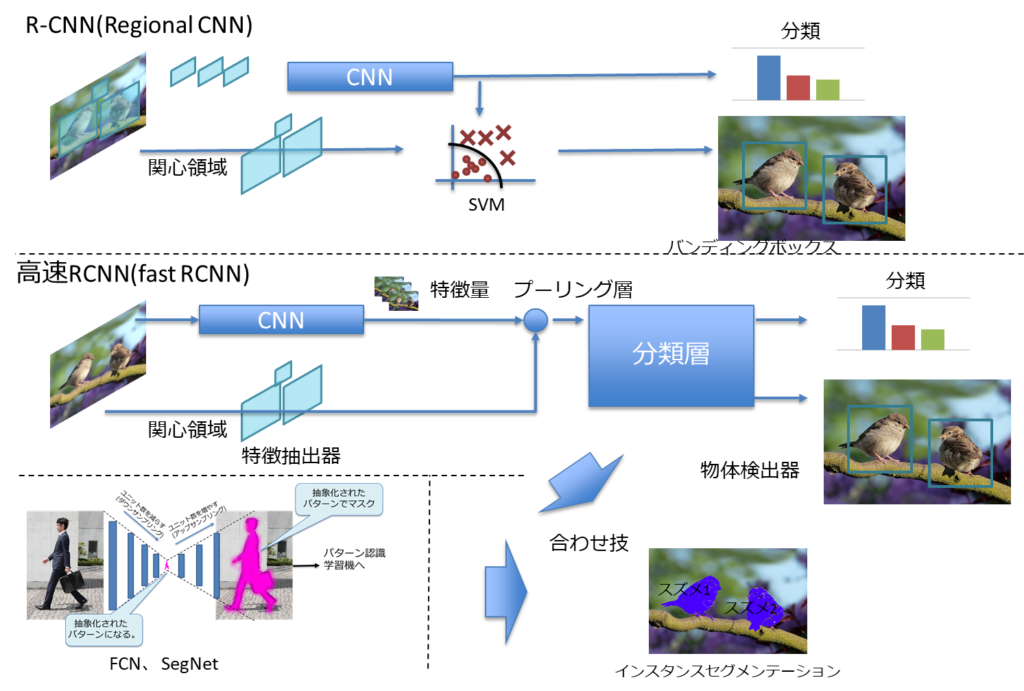
- 物体を検出することと、物体を認識することは別
- しかし、「物体を認識」する過程で「物体を検出」している可能性もある
- 物体検出は矩形のバンディングボックスと画素単位のセマンティックセグメンテーションに分けられる。
- 双方をくみあわせることでインスタンスセグメンテーションが実現可能
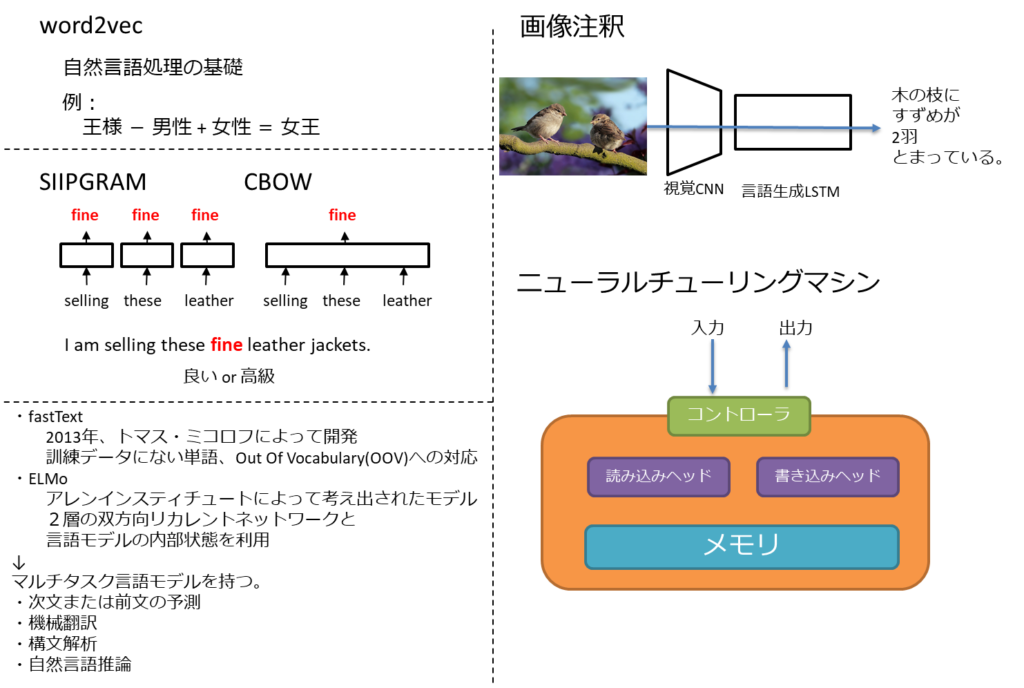
- 自然言語処理の基礎はword2vecことベクトル空間モデル、単語埋め込みモデル
- 発展形のfastText、ELMoはマルチタスク学習が可能
- 画像注釈はCNNとRNNの連携で実現
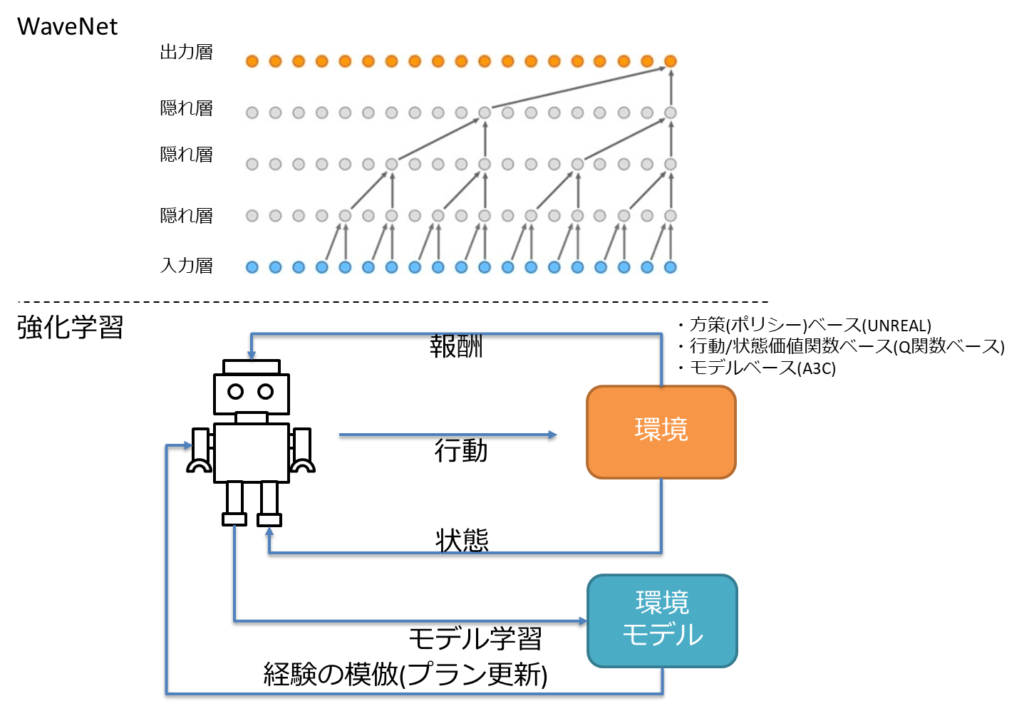
- やや発展中の領域
- 強化学習はセルフプレイにより、無限に強化される可能性を持っている。

ディープラーニングの応用に向けて
産業への応用、法律、倫理、現行の議論
| 項目 | レべる |
|---|---|
| 検定出題数 | 多(42問) |
| 検定難易度 | 極高 |
| Web情報量 | 少 |
| 過去問、問題集だけで対応可? | 激しく不足 |
恐らくは受験者全員を苦しめた大魔境。
テキスト、問題集が完全に無力化される。
Google先生に聞くにしても、適切なキーワードが思い浮かばないこともシバシバ。
この部分のGoogle検索時間を如何に稼ぐかが勝敗を分ける。
2020#2では、ややこの部分の問題数が増えているという情報あり。
70問という話も出ているが、恐らくは50問弱程度の問題数と思われる。
※ 2020#2で、私と同じように受験しながら問題の性質をメモっていた方がいたようで、その方の集計だと、40問弱程度。全体の問題数が減っているので割合としては2020#1と同等。私も2020#1を受けた直後は1/3は法規問題って印象だったが、実際に集計してみると思ったより遥かに少なかった。
2020#1、#2で共通して言えることは、開幕直後に法規問題ラッシュで精神削られるという点。仮に分からなくても、「きっと他の人も分からなくて苦しんでるんだろうな」程度で一旦流してしまった方が良い。ここで精神的に消耗すると後の解かなければならない問題を捌ききれなくなるリスクが上がってしまう。
「道路交通法改正で自動運転レベル3でのスマホ操作を解禁」
「自律型致死兵器システム(LAWS)」
の問題が出たらしい。
無人航空機(ドローン・ラジコン機等)の飛行ルール
は国土交通省のサイトを参照。

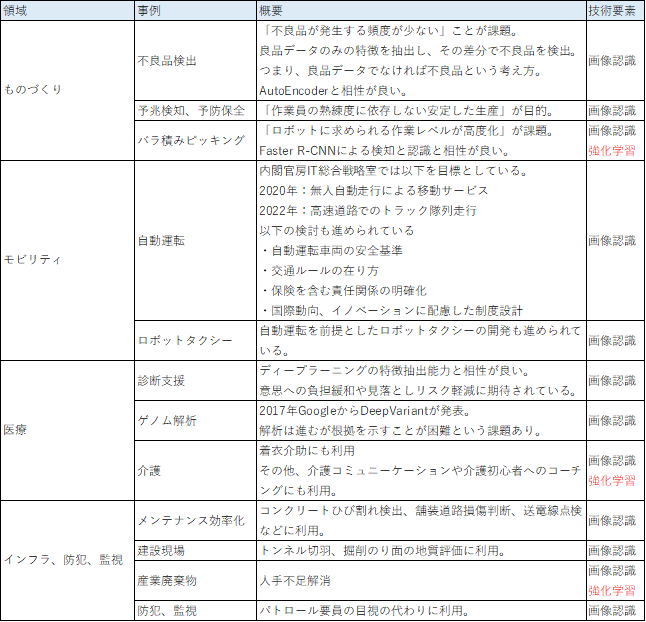
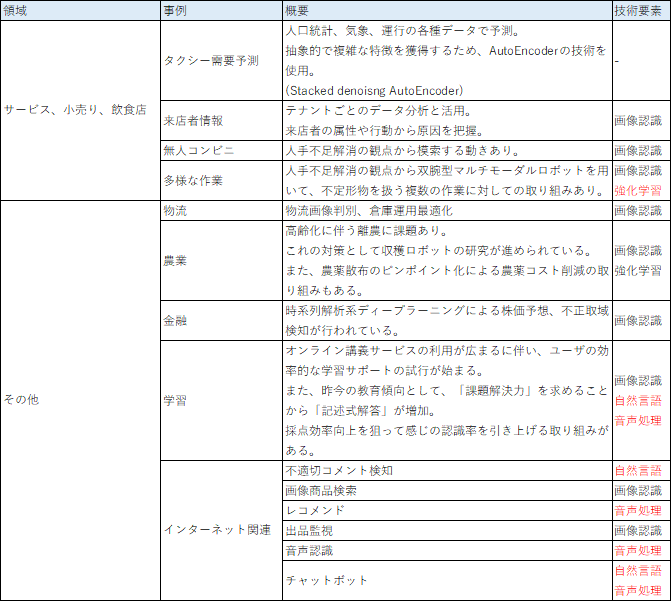
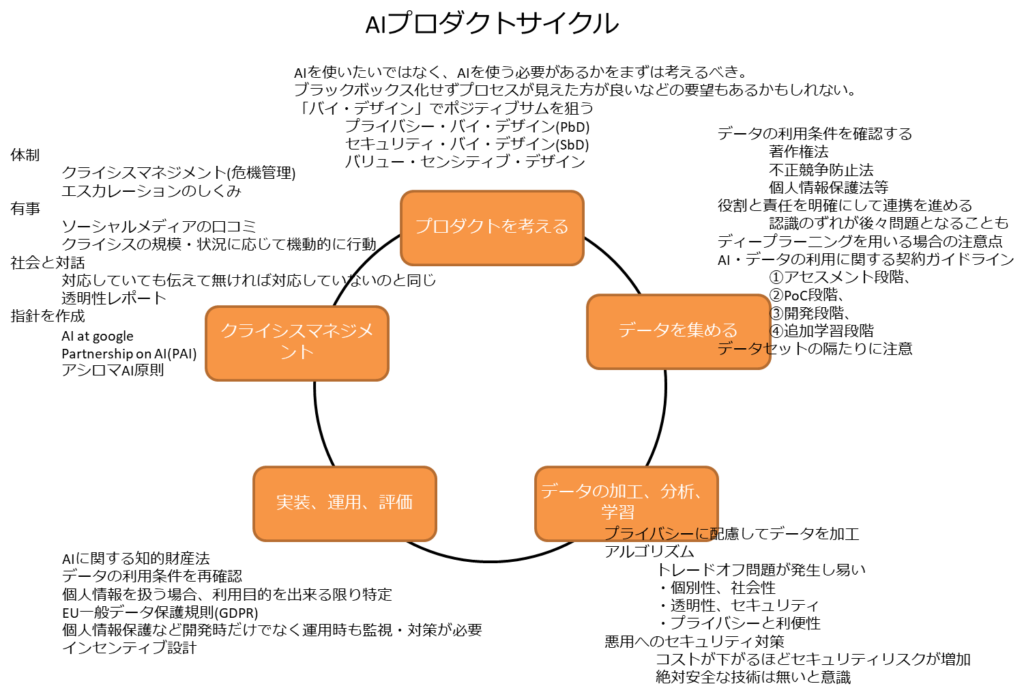
プロダクトは作ったら終わりではない。
そこから得た教訓を運用保守や次のプロダクト開発へと循環させていくサイクルが重要。

法律問題対策ページ
法律問題対策動画 前後編合体版
ディープラーニングの基礎数学
| 項目 | レベル |
|---|---|
| 検定出題数 | 極少(3問) |
| 検定難易度 | 少 |
| Web情報量 | 少 |
| 過去問、問題集だけで対応可? | 不足 |
ここは正直スルーでも良いかもしれない。
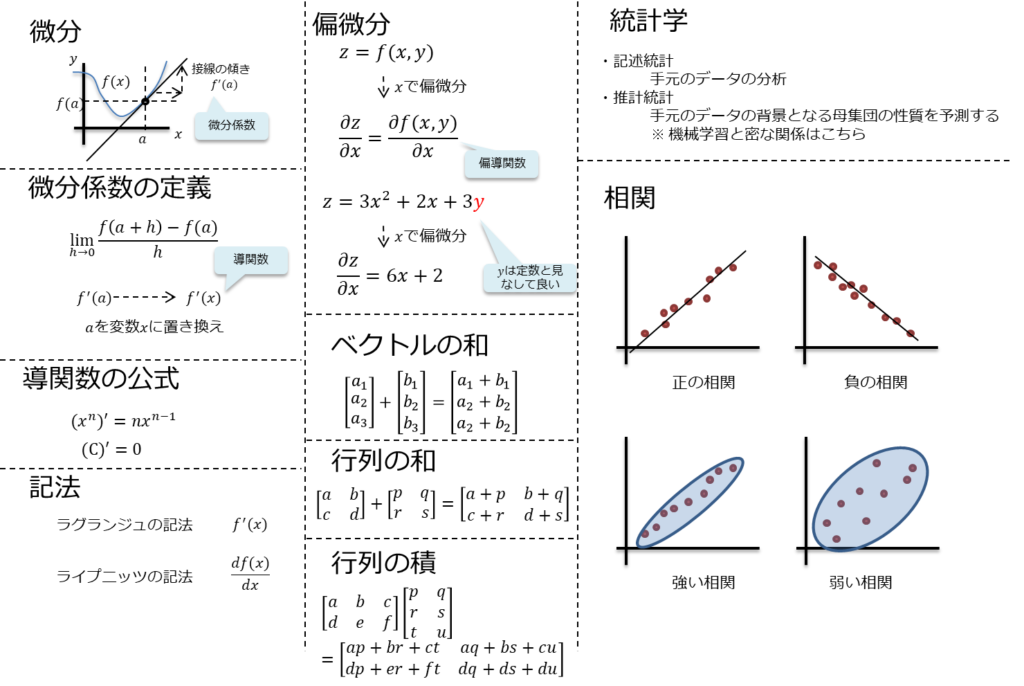
偏微分、ベクトル、行列、統計、ベイズの定理等を覚えておくと良い。

その他
以下の情報も整理しておく必要がある。
- フレームワーク
- Define-by-runタイプ
- PyTorch
- chainer
- Define-and-runタイプ
- TensorFlow
- Caffe
- Define-by-runタイプ
- CIFAR
- 一般物体認識のベンチマーク用データセット
- MNIST
- 手書き数字画像データセット
次にG検定2020#3以降から出てきたやや特殊な問題について。
G検定(ジェネラリスト) 公式テキスト
徹底攻略 ディープラーニング g検定 ジェネラリスト問題集
AI白書
人工知能は人間を超えるか ディープラーニングの先にあるもの (角川EPUB選書)
ディープラーニングG検定(ジェネラリスト) 法律・倫理テキスト
G検定 2020#3で出てきたやや特殊な問題
- EfficientNet
- 既存のネットワークより高速で高精度なネットワーク。
- 今まで成されていなかった解像度・深さ・チャネル数を同時に最適化することによって、高速かつ高精度なネットワークを構築。
- パラメータ探索はグリッドサーチで行う。
- ガウシアンピラミッド・ラプラシアンピラミッド
- 縮小する過程でガウシアンぼかしを入れたものがガウシアンピラミッド、ガウシアンピラミッドに解像度間の差を取ったものがラプラシアンピラミッド。
- ガウシアンピラミッドがローパスフィルタ、ラプラシアンピラミッドがバンドパスフィルタのような特性になる。
- HOG特徴量
- 画像認識における特徴量の1つ。
- 「ピクセル毎の輝度の変化の方向と強さ」を「セル単位でヒストグラム化」した後「ブロック単位で正規化」する。
- 画像からの人体・車両検出には、この特徴量をSVM(Support Vector Machine)で分類する手法がメジャー。
- コサイン類似度
- ベクトル同士のなす角の近さを表現するため、三角関数の普通のコサインの通り、1に近ければ類似しており、0に近ければ似ていないことになる。
- Meta-Learning
- 「少しのデータ・学習ステップの後,すぐに新しいタスクに適応できるモデル」を学習
- MAML(Model-Agnostic Meta-Learning)
- 「(微分可能な)任意の形式のモデル」について,新しいタスクに素早く適応できるようなMeta-Learningの手法
- RNNにおける教師強制(Teacher forcing)
- 訓練の際に”1時刻前”の正解データを現時点の入力として用いる手法を指す。
- とくに自然言語の領域では、教師強制は”翻訳”のモデルなどに適用される。
- RNN Encoder-Decoder
- ソース系列をEncoderと呼ばれるLSTMを用いて固定長のベクトルに変換(Encode)し,Decoderと呼ばれる別のLSTMを用いてターゲット系列に近くなるように系列を生成するモデル。
- 中間層はメモリ的な機能を持ち、Attentionメカニズムと呼ばれる。
- SMOTEアルゴリズム(Synthetic Minority Over-sampling Technique)
- 不均衡データの分類に使用される。
- 少ない方のラベルが付いた各データ点同士を線でつなぎ、その線分上の任意の点をランダムに人工データとして生成。
- 営業秘密(トレードシークレット)
- 不正競争防止法第2条第6項に「この法律において営業秘密とは、秘密として管理されている生産方法、販売方法その他事業活動に有用な技術上又は営業上の情報であって、公然と知られていないものをいう」と定義
- 以下3要件がある。
- 秘密管理性
- 有用性
- 非公知性
- https://www.simulationroom999.com/blog/g-test-measures-against-legal-issues/
- https://youtu.be/Rdb8IrOa68w
- actor-critic法
- 深層強化学習の一種。
- 他にQ学習、SARSA、方策勾配法がある。
- TD学習(時間的差分学習: Temporal Difference Learning)の手法の一つ。
- メリット
- 行動選択に最小限の計算量しか必要ない。
- 確率的な行動選択を学習できること。
- https://www.simulationroom999.com/blog/g-test-reinforcement-learning/
- https://youtu.be/vV62YH1Bq_c
- 深層強化学習の一種。
- ポアソン回帰
- ある現象が一定時間内に起こった回数を数え上げたデータのことをカウントデータ(count data)と呼ぶ。
- 発生頻度と、それに影響する要因との関係を分析する手法のことをカウントデータ分析(analysis of count data)
- ポアソン回帰分析は稀にしか起こらない現象に関するカウントデータを分析するための手法。
- 状態空間モデル
- 時系列データの中に隠れた因果関係を発見し、それをモデル化するもの。
- もともとは物理システムの記述に使われていたもの
- カルマンフィルター
- 観測値から状態を推定するフィルタリング手法。
- 音声認識系のメル尺度
- MFCC(メル周波数ケプストラム係数)
- メル尺度は、音高の知覚的尺度である。メル尺度の差が同じであれば、人間が感じる音高の差が同じになることを意図している
- ベイズ推定
- ベイズ確率の考え方に基づき、観測事象(観測された事実)から、推定したい事柄(それの起因である原因事象)を、確率的な意味で推論する。
- データリーケージ
- 入ってはいけないデータが混入する状態。
G検定 2021#1で出てきたやや特殊な問題
- FCN
- CVPR 2015, PAMI 2016で発表された Fully Convolutional Networks for Semantic Segmentationで提案されたSemantic Segmentation手法。
- 画像の領域を分割するタスクをSegmentation(領域分割)と呼び、Semantic Segmentationは「何が写っているか」で画像領域を分割するタスクのことを指す。
- https://youtu.be/m-m0iRc7jJo
- 説明可能なAI(XAI)への研究開発投資プログラム
- ディープラーニングの特徴として、モデルが行う推論の理由・根拠が説明困難な場合がある。
- これを理由にディープラーニングの活用が敬遠される場合もあるが、改善に向けた研究開発は行われている。
- 例えば2016年にはアメリカ国防高等研究計画局(DARPA)がXAIへの投資プログラムを発表し、推論の根拠の可視化や文章化による説明を可能にするなどの試みが行われている。
- 個人情報保護法
- 個人情報の有用性に配慮しつつ、個人の権利利益を保護することを目的とした個人情報の取扱いに関連する法律
- 背景
- 情報化社会の進展とプライバシー問題の認識
- 個人情報保護法制定の世界的潮流
- OECD 理事会のプライバシー保護勧告
- 地方公共団体の個人情報保護条例の増加
- EU一般データ保護規則(欧州連合指令)
- 電子商取引におけるプライバシー保護の要請
- 住民基本台帳法の改正による個人情報保護法制の要請
- https://www.simulationroom999.com/blog/g-test-measures-against-legal-issues/
- https://youtu.be/Rdb8IrOa68w
- マルチクラス物体認識(R-CNN以降の物体検出)
- 物体検出
- バウンディングボックスにより複数の正解ラベルを特定
- https://youtu.be/m-m0iRc7jJo
- 物体検出
- Depthwise畳み込み
- 通常の畳み込みは任意の数×チェンネル数のが総フィルター数。
- Depthwise畳み込みはチェンネル数のが総フィルター数。
- よって、必要となるパラメータが激減し、演算が高速化。
- 伸縮マッチング手法
- 変形に対する不変性を解決する手法。
- DeepLearningの弱点は、画像中のオブジェクトの変換特性を十分に利用できない点。
- オブジェクトごとに変換不変性を学習しなければならない。
- 変形したバージョンを大量に追加する、データ増強法を実施しなければならない。
- CNNの推定根拠可視化手法
- XAI(Explainable AI)の手法の一つであり、判断根拠をハイライトする方法としてCAM(Class Activation Map)と言うものがある。
- 派生にGrad-CAM
- 基本的にはヒートマップ作成。
- 類似手法にRISE、SIDUがある。
- XAI(Explainable AI)の手法の一つであり、判断根拠をハイライトする方法としてCAM(Class Activation Map)と言うものがある。
- 欧州委員会の「AIに関する倫理ガイドライン」
- https://ec.europa.eu/futurium/en/ai-alliance-consultation/guidelines
- 要旨
- 人間の活動(human agency)と監視
- 堅固性と安全性
- プライバシーとデータのガバナンス
- 透明性
- 多様性・非差別・公平性
- 社会・環境福祉
- 説明責任
- 改正著作権法における学習用データの扱い
- 2019年1月1日に改正著作権法の施行。
- 「情報解析」のためであれば、必要な範囲で、著作権者の承諾なく著作物の記録や翻案可能。
- https://www.simulationroom999.com/blog/g-test-measures-against-legal-issues/
- https://youtu.be/Rdb8IrOa68w
- 学習済みモデルの知的財産保護
- 3つのアプローチ
- 技術
- 契約
- 法律
- 特許権、著作権、営業秘密(不正競争防止法)
- 派生モデル、蒸留モデルまで加味すると法律での保護は難しい。
- https://www.simulationroom999.com/blog/g-test-measures-against-legal-issues/
- https://youtu.be/Rdb8IrOa68w
- 3つのアプローチ
- 個人情報保護法に於いてのカメラ画像
- 本人を判別可能なカメラ画像やそこから得られた顔認証データを取り扱う場合、個人情報の利用目的をできる限り特定し、当該利用目的の範囲内でカメラ画像や顔認証データを利用しなければならない。
- つまり利用するのはOKだが、目的と範囲を明確/明言する必要がある。
- https://www.simulationroom999.com/blog/g-test-measures-against-legal-issues/
- https://youtu.be/Rdb8IrOa68w
- 本人を判別可能なカメラ画像やそこから得られた顔認証データを取り扱う場合、個人情報の利用目的をできる限り特定し、当該利用目的の範囲内でカメラ画像や顔認証データを利用しなければならない。
- NAS(Neural Architecture Search)
- 事例としてはGoogle社のCloud AutoML。
- 従来
- ニューラルネットワークは重みを最適化し、目的関数を改善する。
- NAS
- 「パラメータ最適化」の前段階でニューラルネットワークの構造を最適化。
- 正規分布の式
- \(\displaystyle f(x)=\frac{1}{\sqrt{2\pi}}exp(-\frac{x^2}{2})\)
G検定 2021#2で出てきたやや特殊な問題
- CRISP-DM(Cross-Industry Standard Process for Data Mining)
- データマイニングの業界横断的な標準プロセス。
- データマイニングの専門家が使用する一般的なアプローチを記述したオープンスタンダードなプロセスモデル。
- 2015年、IBMはCRISP-DMを改良・拡張したAnalytics Solutions Unified Method for Data Mining/Predictive Analytics(ASUM-DMとも呼ばれる)という新しい方法論を発表した。
- 個人識別符号
- 指紋・手指の静脈・顔・DNAなどの生体情報をデジタルデータに変換したものや、運転免許証・パスポート・各種保険証の番号、住民票コードやマイナンバーなどがこれにあたる。
- 決定木(DT:Decision tree)
- 段階的にデータを分割していき、木のような分析結果を出力する。
- 「情報利得」が最大となる基準を選択。
- 分割後のグループの不純度を一番小さく。
- 音素(phoneme:フォネーム)
- 言語学・音韻論において、音声学的には異なる音価であるが、ある個別言語のなかで同じと見なされる音の集まり。
- 音声認識に於いては特に以下。
- 母音:「あいうえお」
- 撥音:「ん」
- 子音
- ありがとう→a-r-i-g-a-t-o
- ディープフェイク
- 機械学習アルゴリズムのディープラーニングを利用して、2つの写真や動画の一部をスワップ(交換)させる技術。
- モデル圧縮
- ディープニューラルネットワークのモデルを軽量化するための技術。
- 昨今のモデルの大規模化、入力データの高解像度化,エッジデバイスなどへの適用など、演算時間の短縮と演算時のメモリ削減の需要が高まっている。
- モデル圧縮手法
- プルーニング(Pruning:枝刈り)
- ノードや重みを削除することでパラメータ数を減少。
- 記憶する必要があるパラメータが減少することによって、計算する回数が削減され、メモリ使用量が少なくなる。
- クオンタイズ(Quantize:量子化)
- 重みなどのパラーメータをより小さいビットで表現することで、モデルの軽量化を図る手法。
- ネットワークの構造を変えずにメモリ使用量を削減。
- 32ビット浮動小数点精度 → 8bit固定小数点 など(1%程度の性能低下しかしない)
- ディスティレーション(Distillation:蒸留)
- 大きいモデルやアンサンブルモデルを教師モデルとして、その知識を小さいモデル(生徒モデル)の学習に利用する方法。
- 大きいモデルに匹敵する精度を持つ小さいモデルを作ることが期待できる。
- 一度学習したモデルの知識(予測結果)を別の小さいモデルに継承する。
- プルーニング(Pruning:枝刈り)
- OpneAIがGPT-2の一般公開に対する懸念
- フルモデルのパラメータ数は15億パラメータ。
- 対して一般公開したのは1億2400万。
- フルモデルは性能が高すぎるためテロリスト、ハッカーなどの悪意ある攻撃者に悪用される恐れがあった。
- Adversarial Examples
- 微小なノイズを加えることで、人には差異は認識できなくともAIに誤認させることのできる。
- これを利用した脆弱性攻撃。
- 相関係数
- 2つのデータまたは確率変数の間にある線形な関係の強弱を測る指標。
- 相関係数は無次元量で、-1以上1以下の実数に値をとる。
- 相関係数が正のとき確率変数には正の相関が、負のとき確率変数には負の相関があるという。
- また相関係数が0のとき確率変数は無相関であるという
- ピアソンの積率相関係数。
- 偏相関
- 別の交絡因子による影響を取り除いた関心のある2つの変数の間の相関を表す概念である。
- 相関係数を使用すると、別の交絡因子がある場合に誤解を招く結果が得られる。
- この誤解を招く情報は、偏相関係数を計算し交絡変数を制御することによって回避できる。
- 分散
- データ(母集団、標本)、確率変数(確率分布)の標準偏差の自乗
- \(\displaystyle s^2=\frac{1}{n}\sum{(x_i-\bar{x})^2}\)
- 共分散
- 2組の対応するデータ間での、平均からの偏差の積の平均値
- 2組の確率変数 \(X, Y\) の共分散 \(Cov(X, Y)\) は、\(E\) で期待値を表す
- \(Cov(X,Y)=E[(X-E[X])(Y-E[Y])]\)
- A3C(Asynchronous Advantage Actor-Critic)
- 強化学習のActor-Critic系
- 論文
- https://arxiv.org/abs/1602.01783
- シンプルで軽量な深層強化学習のフレームワーク。
- 最適化に非同期勾配降下法を用いる。
- 様々な連続運動制御問題や、視覚入力を用いてランダムな3D迷路をナビゲートするというタスクにも成功。
- https://www.simulationroom999.com/blog/g-test-reinforcement-learning/
- https://youtu.be/vV62YH1Bq_c
- 変分オートエンコーダ(Variational Auto-Encoder: VAE)
- https://www.simulationroom999.com/blog/deeplearning-technic4/#toc7
- ニューラルネットワークを使った生成モデルの1つ。
- 確率分布に対するパラメーター最適化アルゴリズムであるオートエンコーディング変分ベイズアルゴリズム(Auto-Encoding Variational Bayes (AEVB) algorithm)を導入。
- ResNet
- https://www.simulationroom999.com/blog/g-test-measures-trends-in-artificial-intelligence/
- 論文
- https://arxiv.org/abs/1512.03385
- 従来(AlexNet等)よりも大幅に深いネットワークの学習を容易にする残差学習フレームワーク。
- 残差はSkip-Connectionの効能。
- Skip-Connection側がバイアス
- ニューロン側が残差
- https://youtu.be/m-m0iRc7jJo
- Cycle GAN
- 論文
- https://arxiv.org/abs/1703.10593
- 画像のペアを学習して、入力画像と出力画像の間のマッピングを学習することを目的とした、視覚やグラフィックスの問題の一種。
- ペアの例がない場合に、ソースドメインXからターゲットドメインYへの画像の翻訳を学習するためのアプローチ。
- 「馬→シマウマ」に変換とか。
- 論文
G検定 2021#3で出てきたやや特殊な問題
- AD変換
- アナログ電気信号をデジタル電気信号に変換する機能。
- AD変換をする部品のことをADC(ADコンバータ、AD変換器)と呼ぶ
- 現実世界の連続量であるアナログ信号をコンピュータで扱えるように離散化してデジタル化する。
- https://ja.wikipedia.org/wiki/%E3%82%A2%E3%83%8A%E3%83%AD%E3%82%B0-%E3%83%87%E3%82%B8%E3%82%BF%E3%83%AB%E5%A4%89%E6%8F%9B%E5%9B%9E%E8%B7%AF
- BERT(Bidirectional Encoder Representations from Transformers)
- Googleによって開発された、自然言語処理(NLP)の事前学習用ための Transformer ベースの機械学習手法
- NLP絡みにで以下の流れが問われることが多い
- 2018年
- ELMo
- GPT
- BERT
- 2019年
- XLNet
- 2018年
- DeepLab v3
- atrous畳み込みを用いて、深い畳み込みニューラルネットワークによって計算された特徴を任意の分解能で抽出する。
- Mask R-CNN
- 2017年3月20日にarXivにて公開された。
- 2017年4月5日にversion2、2018年1月24日にversion3となっている。
- 画像内のオブジェクトを効率的に検出すると同時に、インスタンスごとに高品質のセグメンテーションマスクを生成する。
- 所謂、インスタンスセグメンテーションを実現する。
- バウンディングボックス認識用の既存ブランチと並行して、オブジェクトマスクを予測するためのブランチを追加することによって、Faster R-CNNを拡張している。
- https://youtu.be/m-m0iRc7jJo
- OpenPose
- カーネギーメロン大学(CMU)の Zhe Caoら が「Realtime Multi-Person pose estimation」の論文で発表した、深層学習を用いて人物のポーズを可視化してくれる手法。
- Source-Target Attention
- Self-Attentionと同様にQuery-Key-Value構造をもっている。
- 両者の違いは、Self-Attentionが同一データ内の照応関係を獲得しているのに対し、Source-Target-Attentionは異なるデータ間の照応関係を獲得しているという点。
- アマダール積
- 数学におけるアダマール積は、同じサイズの行列に対して成分ごとに積を取ることによって定まる行列の積。
- 要素ごとの積、シューア積、点ごとの積、成分ごとの積(英: entrywise product)などとも呼ばれる。
- PythonのNumpy.array同士の掛け算は自動的にアダマール積になる。
- MATLAB、Scilab、Juliaは内積にある。アダマール積にするには「.*」のような演算子を使う。
- パルス符号変調器
- 音声などのアナログ信号を、アナログ-デジタル変換回路により、デジタル信号に変換(デジタイズ)する変調方式の一つ
- フォルマント
- 音声のスペクトル分析において、ある音声を特徴づける特定の周波数領域。
- 周波数の低い順から第1フォルマント、第2フォルマントと名付けられ、音のエネルギーが集中する。
- 音韻の区別に用いられる。
- マハラノビス距離
- 統計学で用いられる一種の距離。
- 「普通の距離を一般化したもの」という意味でマハラノビス汎距離ともいう。
- プラサンタ・チャンドラ・マハラノビスにより1936年導入された。
- 多変数間の相関に基づくものであり、多変量解析に用いられる。
- 新たな標本につき、類似性によって既知の標本との関係を明らかにするのに有用である。
- データの相関を考慮し、また尺度水準によらないという点で、ユークリッド空間で定義される普通のユークリッド距離とは異なる。
- マルチエージェント強化学習
- シングルエージェントで成功した深層強化学習を、マルチエージェントで成功させることは困難である。
- マルチエージェント強化学習は、シングルエージェントシステムとは異なり、環境のダイナミクスが、環境に内在する不確実性に加えて、環境内のすべてのエージェントの共同行動によって決定されるという点が最大の特徴。
- 環境が非定常になると、各エージェントは、他のエージェントの方針が変わると最適な方針が変わるという、ムービングターゲット問題に直面する。
- ほとんどのシングルエージェント強化学習アルゴリズムで要求される定常性の仮定の違反は、マルチエージェント学習問題を解く上での課題となる。
- マルチエージェントの設定では、エージェントを追加するごとに状態行動空間が指数関数的に増加するため、次元の呪いが悪化する。
- 同時に、マルチエージェント強化学習は、エージェントが知識を共有し、他の学習エージェントから模倣または直接学習する可能性があるため、新たな機会を導入する。
- これは、学習プロセスを加速し、その後、ゴールに到達するより効率的な方法をもたらす可能性がある。
- マルチエージェント深層強化学習は、急速に拡大している新しい分野を生み出している。
- 多くの実世界の問題はマルチエージェント強化学習問題としてモデル化することができ、深層強化学習の出現により、研究者は単純な表現からより現実的で複雑な環境に移行することができるようになった。
- ワンホットベクトル
- (0,1,0,0,0,0) のように、1つの成分が1で残りの成分が全て0であるようなベクトルのこと。
- 著作権法30条の4の改正
- 著作物の利用に係る技術開発・実用化の試験のための利用。
- 思想感情の享受を目的としない利用については、原則として、その方法目的を問わず、適法に行うことが可能となった。
- 教師強制
- Seq2SeqのようなEncoder-Decoderモデルに於いて、使用される。
- 訓練の際に”1時刻前”の正解データを現時点の入力として用いる手法を指す。とくに自然言語の領域では、教師強制は”翻訳”のモデルなどに適用される。
- 相互情報量
- 相互情報量または伝達情報量は、確率論および情報理論において、2つの確率変数の相互依存の尺度を表す量である。最も典型的な相互情報量の物理単位はビットであり、2 を底とする対数が使われることが多い。
- 離散確率変数Xと相互情報量Yの定義
- \(\displaystyle I(X;Y)=\sum_{y\in Y}\sum_{x\in X}p(x,y)log\frac{p(x,y)}{p(x)p(y)’}\)
G検定 2022#1で出てきたやや特殊な問題
- DCGAN
DCGAN(Deep Convolutional GAN)は、2015年にA.Radfordらによって発表された敵対的生成ネットワークの一種であり、生成ネットワーク(generator)と識別ネットワーク(discriminator)の2つのネットワークに畳み込みニューラルネットワーク(CNN)を用いたモデル。DCGANにおける生成モデルは100次元の一様分布Zを入力とし、転置畳み込みによって徐々に画像空間へ投影していく仕組みである。また識別モデルは同じくプーリング層を使わずに畳み込みによってダウンサンプリングしていき、活性化関数にはReLUの代わりに漏洩ReLU(Leaky ReLU)を使用する。プーリング層や全結合層を使わずにCNNによって学習を進めることで、通常のGANよりも鮮明な画像の生成が可能になった。さらにDCGANによる生成は、その入力のベクトル空間的な性質が極めて良いことが明らかになり、値の近い入力同士なら似たような画像を生成し、二つの入力の間の値によって生成される画像は二つの画像の意味的な中間となる。これにより、入力を適切に調整することでより高次な特徴レベルの画像をコントロールすることができる。
Wikipediaより(https://ja.wikipedia.org/wiki/DCGAN)
- MLOps
- 「機械学習チーム(Machine Learning)/開発チーム」と「運用チーム(Operations)」がお互いに協調し合うことで、機械学習モデルの実装から運用までのライフサイクルを円滑に進めるための管理体制(機械学習基盤)を築くこと。
- DevOpsから発展して生まれた考え方。
- AdaBound
- Adamに学習率の上限と下限を動的に加えたもの。
- 最初はAdamのように動き、後半からSGDのように動く。
- Adamの良さである初期の学習の速さとSGDの良さである汎化能力を両立した最適化手法。
- 二重降下現象
- 従来の機械学習の考えでは過学習しない適度な大きさのモデルが最適だが、ある条件下では訓練誤差ゼロからさらにモデルを大きくしたほうがテスト誤差が小さくなる二重降下現象が起きる。
- https://arxiv.org/abs/1909.11720
- CRISP-DMの6つのステップ
- CRISP-DMは”CRoss-Industry Standard Process for Data Mining”の略で、直訳すると「データマイニングのための業界横断型標準プロセス」
- 以下の6つのステップから構成
- Business Understanding(ビジネスの理解)
- Data Understanding(データの理解)
- Data Preparation(データの準備)
- Modeling(モデリング)
- Evaluation(評価)
- Deployment(展開)
G検定 2022#2で出てきたやや特殊な問題
- MobileNet
- モバイルおよび組み込みビジョンアプリケーション向けのMobileNetsと呼ばれる効率的なモデル。
- Depthwise Separable Convolutioを使用して軽量のディープニューラルネットワークを構築する合理化されたアーキテクチャ。
- https://arxiv.org/abs/1704.04861
- ドメインランダマイゼーション
- シミュレータでレンダリングをランダム化することにより、実際の画像に転送されるシミュレートされた画像でモデルをトレーニングするための簡単な手法。
- シミュレートされたロボット工学をハードウェアでの実験から分離する「現実のギャップ」を埋めることで、データの可用性を向上させることでロボット研究を加速させることができる。
- https://arxiv.org/abs/1703.06907
- 匿名加工情報
- 特定の個人を識別することができないように個人情報を加工し、当該個人情報を復元できないようにした情報のこと。
- 個人情報保護の兼ね合いで出題される。
- そのままでは個人情報保護法で言うパーソナルデータに該当するものを、匿名加工をすることで非パーソネルデータ化することを目的とする。
- https://www.simulationroom999.com/blog/g-test-measures-against-legal-issues/
- https://youtu.be/Rdb8IrOa68w
- OpenAI Five
- 2019年4月14日、対戦型リアルタイムストラテジーゲーム「Dota 2」の2018年度世界大会覇者OGに勝利を収めた。
- OpenAI Fiveと呼ばれるDota2AIは、1万年以上のゲームを自分自身と対戦することで学ぶ。
- 専門家レベルのパフォーマンスを達成し、人間とAIの協力を学び、インターネット規模で運用する能力を実証した。
- https://openai.com/five/
- U-Net
- 生物医学のために開発された、セマンティックセグメンテーション用のモデル。
- Encoder-Decoderタイプのモデル。
- 構造に対称性があり、Contracting path(ResNetのスキップコネクションと同一)を利用している。
- 類似モデルでFCNがあるが、これに対して対称性とスキップコネクションを付加したと思えばOK。
- https://arxiv.org/abs/1505.04597
- https://youtu.be/m-m0iRc7jJo
- GLUE
- 自然言語処理モデルによる言語理解タスクの精度を評価するためのベンチマーク(評価基準)
- BERTやGPTなどのマルチタスク自然言語処理モデルのパフォーマンスを評価する方法として開発された。
- 「2文の類似度の判断」や「ネガポジ判定」など、指定された複数の自然言語処理タスクのそれぞれに対する性能を評価し、それらの評価の総合値によってモデルの性能が表現される。
- https://arxiv.org/abs/1804.07461
- 膨張畳み込み(Dilated Convolution)
- カーネルを膨張させた畳み込み層
- カーネルサイズを膨張させた上で、隙間はアクセスせずに無視し、カーネルのストライド幅も広くとって畳込む。
- これにより,カーネルを移動させた各位置において広い範囲で(疎に)畳み込むので、少ない層数で効率的に広範囲の受容野から畳み込みを行うことができる。
- https://arxiv.org/abs/1511.07122
- 箱ひげ図
- 四角い箱の上下に、ひげが生えている形をしており、データのばらつき具合を示すのに用いる。
- PoC
- PoC(Proof of Concept:概念実証)とは、新たなアイデアやコンセプトの実現可能性やそれによって得られる効果などについて検証すること。
- 準委任契約
- 特定の業務を遂行することを定めた契約のことで、特定の業務の遂行を目的に締結される。
- 準委任契約の場合、業務の内容や成果物に対して完成の義務は負わない。
- そのため、結果または成果物に不備があったとしても、修正や保証を求められない。
- 個人情報に該当するデータ
- 指紋、DNA、顔の骨格などの身体の特徴データ。
- マイナンバー、パスポートや運転免許証の番号など、個々人に対して割り当てられる公的な番号。
- https://www.simulationroom999.com/blog/g-test-measures-against-legal-issues/
- https://youtu.be/Rdb8IrOa68w
- DenseNet
- ResNet進化版。
- スキップコネクションを極端に増やし、勾配消失問題を大きく抑制している。
- https://arxiv.org/abs/1608.06993
- 強化学習の価値関数
- 状態価値観数と行動価値関数の2種類がある。
- 状態価値観数
- 価値関数のうち、状態sにおける価値を示すもの。
- 行動価値関数
- 価値関数のうち、行動aにおける価値を示すもの。
- https://www.simulationroom999.com/blog/g-test-reinforcement-learning/
- https://youtu.be/vV62YH1Bq_c
- ε-greedy法
- 一定の確率でランダムに行動を行う、強化学習の学習手法
- https://www.simulationroom999.com/blog/g-test-reinforcement-learning/
- https://youtu.be/vV62YH1Bq_c
- オープンイノベーション
- 組織内部のイノベーションを促進するために、意図的か つ積極的に内部と外部の技術やアイデアなどの資源の流出入を活用し、その結果組 織内で創出したイノベーションを組織外に展開する市場機会を増やすこと。
- Global Average Pooling
- 特徴マップの空間領域の全体に対する平均プーリングを行うプーリング層であり、物体認識系CNNの終盤層で全結合層による識別層の代わりによく用いられる
- https://arxiv.org/abs/1312.4400v3
- 双方向リカレントニューラルネットワーク
- 信号が双方向に伝わるようにリカレントニューラルネットワークを拡張したものである。正負の時間軸のデータを同時に学習できることが特徴。
- https://youtu.be/_1DNz5Y8OXM
- LIME
- 説明可能AI(XAI)の手法の一種。
- 複雑なモデルを単純な線形回帰で近似することで解釈性の向上を目指す手法。
- つまり、シンプルな数式に置き換えて人間が性質を理解しやすくする。
- マルコフ決定過程
- マルコフ性、マルコフ過程(連鎖)、マルコフ報酬過程を内包し、行動という概念を付加したもの。
- マルコフ性 → 過去の状態は現在の状態に影響を与えない。
- マルコフ過程(連鎖)→ 状態遷移表と状態遷移行列で表現したもの
- マルコフ報酬過程 → マルコフ過程(連鎖)に報酬という概念を付加したもの。報酬は割引率を利用して未来報酬を減衰させる考え方も含まれる。
- https://www.simulationroom999.com/blog/g-test-reinforcement-learning/
- https://youtu.be/vV62YH1Bq_c
- マルコフ性、マルコフ過程(連鎖)、マルコフ報酬過程を内包し、行動という概念を付加したもの。
G検定 2022年、2023年以降で出てきたやや特殊な問題
この回は知人で受けた人がほぼおらず情報が少ないのだが、基本的には2022#2と変わらない印象。
といっても、2日開催のため、両日で同じ問題を出すということは考えずらいので、受けた日によって傾向が異なる可能性はある。
まとめ
基礎的なところから、最新情報まで含まれた試験となる。
普段からAI関連の情報収集も並行して実施する必要がある。
G検定対策に関するFAQ
G検定(JDLA Deep Learning for GENERAL)について、読者の方からよくいただく質問をQ&A形式でまとめました。
Q1. G検定(JDLA Deep Learning for GENERAL)とはどんな試験ですか?
A. 日本ディープラーニング協会(JDLA)が実施するオンライン試験で、ディープラーニングを中心としたAIの基礎知識と、事業での活用方針を考えられるリテラシーを確認するための検定です。AI・ディープラーニング領域の「読み書きそろばん」を証明する位置づけになっています。
Q2. G検定の難易度と合格率の目安は?
A. 記事内で整理している通り、ここ数年の合格率はおおむね6〜7割前後で推移しており、まじめに対策すれば十分に狙えるレベルです。ただし、単語暗記だけでは解けない複合的な問題も多く、「知識を構造化して理解しているか」が問われる試験だと考えた方が良いです。
Q3. 文系・未経験でもG検定に合格できますか?
A. 文系・未経験でも十分合格可能です。数学的な計算問題はごく一部で、むしろ歴史や法律、最新動向に関する問題が多いのが特徴です。言い回しは理系寄りですが、内容としては文系の方が得意とする領域も多く、シラバスに沿って用語と考え方を押さえれば対応できます。
Q4. 勉強時間の目安とスケジュールはどのくらいですか?
A. 本記事の体験談では、本番2週間前から1日約2時間、合計約28時間の学習で合格しています。ただし28時間ではやや不足だったと感じており、同じく1日2時間しか取れない方は、試験1か月前から学習を始めて、公式テキスト(白本・黒本)やAI白書を2周しておくことをおすすめしています。
Q5. どのような教材・ステップで勉強するのが効率的ですか?
A. 推奨している流れは、
- まず公式シラバスを読み全体像を把握する
- 公式テキストや問題集、AI白書で知識をインプットする
- 問題集や無料模試でアウトプットと時間感覚を鍛える
- 不足分野を解説動画や特化記事(法律・強化学習など)で補強する
- 最後に自作のカンペ(チートシート)で知識を整理する
というステップです。
Q6. サイトにある「700問の無料問題集」はどう活用すればよいですか?
A. 記事中の「過去問っぽい問題集(700問無料)」は、シラバス全体を一問一答形式で網羅的にチェックするためのトレーニング場として作っています。特に、法律や最新動向といった市販問題集でカバーしづらい領域の対策に有効なので、本番直前の総仕上げとして活用するのがおすすめです。
Q7. カンペ(チートシート)は作った方がいいですか?
A. JDLAとしてカンペや検索を推奨しているわけではありませんが、自宅Web試験という性質上、実務的にはグレーゾーンです。本記事では、「他人のカンペを買う」のではなく、「自分でカンペを作る」ことを強く推奨しています。作る過程で情報が整理され、本番ではカンペを見なくても解ける状態になることが理想です。
Q8. 法律や強化学習など“魔境”と言われる分野の対策は?
A. 法律分野は、個人情報保護法・著作権法・特許法・不正競争防止法と、それぞれがAI・データ利活用とどう関係するかを押さえることが重要です。強化学習は用語が多く体系化されていないため、当サイトの強化学習特化記事や解説動画で全体の流れとキーワードをまとめてから、問題演習で慣れていくのがおすすめです。
Q9. 記事の情報はどの時点のG検定に対応していますか?
A. 本記事は2020年の受験体験からスタートし、その後の各回の合格率や出題傾向、2024年版シラバスへの切り替えなどを踏まえて随時アップデートしています。冒頭でも触れている通り、内容は2025年11月時点の最新情報を反映しており、重要な変更があれば今後も更新していく予定です。
参考文献
公式試験情報・シラバス
- 日本ディープラーニング協会「G検定とは」 一般社団法人日本ディープラーニング協会(JDLA)
URL: https://www.jdla.org/certificate/general/ - 日本ディープラーニング協会「シラバス:G検定の試験出題範囲(G2024#6~)」 一般社団法人日本ディープラーニング協会
URL: https://www.jdla.org/download-category/syllabus/ - 日本ディープラーニング協会「2024年 第6回 G検定(ジェネラリスト検定)開催結果を発表」2024年11月25日
URL: https://www.jdla.org/news/20241125001/ - 日本ディープラーニング協会「『G検定(ジェネラリスト検定)』シラバス改訂および公式テキスト刊行のお知らせ」2024年5月14日
URL: https://www.jdla.org/news/20240514001/
類似資格・関連試験・オープンバッジ
- 一般社団法人データサイエンティスト協会「DS検定® データサイエンティスト検定™ リテラシーレベル」
URL: https://www.datascientist.or.jp/dscertification/ - 独立行政法人情報処理推進機構(IPA)「ITパスポート試験」
URL: https://www.ipa.go.jp/shiken/kubun/ip.html (情報処理推進機構) - 「AI実装検定」 AI実装検定協会 公式サイト
URL: https://kentei.ai/ (kentei.ai) - 生成AI活用普及協会(GUGA)「生成AIパスポート」
URL: https://guga.or.jp/outline/ (生成AI活用普及協会(GUGA)) - デジタルリテラシー協議会「DX推進パスポート」
URL: https://www.dilite.jp/passport (Di-Lite啓発プロジェクトサイト〖公式〗|デジタルリテラシー協議会) - 独立行政法人情報処理推進機構(IPA)ほか「プレス発表『DX推進パスポート』デジタルバッジの発行を開始します」2024年1月31日
URL: https://www.ipa.go.jp/pressrelease/2023/press20240131.html (情報処理推進機構)
法律・ガイドライン
- 「個人情報の保護に関する法律」 e-Gov法令検索
URL: https://elaws.jp/view/415AC0000000057 (elaws.jp) - 「著作権法」 法令リード(条文サイト)
URL: https://hourei.net/law/345AC0000000048 (hourei.net) - 「特許法」 e-Gov法令検索
URL: https://elaws.jp/view/334AC0000000121 (elaws.jp) - 「不正競争防止法」 e-Gov法令検索
URL: https://elaws.jp/view/405AC0000000047 (elaws.jp) - 経済産業省「AI事業者ガイドライン」
URL: https://www.meti.go.jp/shingikai/mono_info_service/ai_shakai_jisso/20240419_report.html (経済産業省) - 内閣府「AI戦略」
URL: https://www8.cao.go.jp/cstp/ai/index.html (内閣府ホームページ)
AI・ディープラーニング一般(書籍・白書)
- 情報処理推進機構(IPA)「AI白書」シリーズ
URL: https://www.ipa.go.jp/publish/wp-ai/index.html (情報処理推進機構) - 斎藤康毅『ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装』オライリー・ジャパン, 2016年
URL: https://www.oreilly.co.jp/books/9784873117584/ (oreilly.co.jp) - 岡谷貴之『深層学習 改訂第2版』(機械学習プロフェッショナルシリーズ)講談社サイエンティフィク, 2022年
URL: https://www.kspub.co.jp/book/detail/5133323.html (kspub.co.jp) - 情報処理推進機構(IPA)「DX動向2024 進む取組、求められる成果と変革」
URL: https://www.ipa.go.jp/digital/chousa/dx-trend/dx-trend-2024.html (情報処理推進機構)
代表的な研究論文
- Krizhevsky, A., Sutskever, I., & Hinton, G. E.
“ImageNet Classification with Deep Convolutional Neural Networks.”
Advances in Neural Information Processing Systems 25 (NIPS 2012).
URL: https://papers.nips.cc/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html (papers.nips.cc) - Vaswani, A. et al.
“Attention Is All You Need.”
Advances in Neural Information Processing Systems 30 (NIPS 2017).
URL: https://arxiv.org/abs/1706.03762 (arXiv) - Mnih, V. et al.
“Human-level control through deep reinforcement learning.”
Nature, 518, 529–533 (2015).
URL: https://www.nature.com/articles/nature14236 (Nature)
情報収集・論文データベース
- arXiv.org e-Print archive(プレプリント論文リポジトリ)
URL: https://arxiv.org/ (arXiv)
参考書籍
G検定(ジェネラリスト) 公式テキスト
徹底攻略 ディープラーニング g検定 ジェネラリスト問題集
AI白書
人工知能は人間を超えるか ディープラーニングの先にあるもの (角川EPUB選書)
ディープラーニングG検定(ジェネラリスト) 法律・倫理テキスト


コメント
It’s hard to find educated people about this subject, however, you seem like you know what you’re talking about!
Thanks