
バックナンバーはこちら

はじめに
近年、自然言語処理(NLP)をはじめとする多くの分野において、Transformerアーキテクチャが中心的な役割を果たしている。BERTやGPTといった代表的なモデルは、いずれもTransformerを基盤としており、その性能の高さは多くの実用例によって証明されている。
Transformerの中核にあるのが「Attention」である。しかし、このAttentionという言葉は非常に多義的であり、初学者にとっては混乱のもととなることが多い。Self-Attention、Multi-Head Attention、Encoder-Decoder Attentionなど、似たような名称が並ぶ中で、それぞれの役割や構造を正しく理解することは容易ではない。
本記事では、G検定のシラバスに沿って、TransformerとAttentionの技術体系を因果関係の観点から整理する。単なる用語の暗記ではなく、技術のつながりと背景にある課題解決の流れを理解することを目的とする。
Attentionは「注目」という直感的な意味を持つが、その実態は高度な計算構造と情報処理の仕組みに支えられている。Transformerの理解を深めるためには、Attentionの構造・計算・補助要素を体系的に把握する必要がある。
本記事が、読者のTransformer理解の一助となることを願う。
動画シリーズ
G検定の究極カンペ関連動画の再生リスト

説明内容
本記事では、Transformerアーキテクチャの中核をなすAttention機構について、以下の5つの観点から体系的に解説する。各項目は、G検定の出題範囲に準拠しつつ、技術的な背景と因果関係を重視して構成している。
- モデルアーキテクチャの系譜
- Seq2SeqからTransformerへの進化、そしてEncoderとDecoderの分化を通じて、自然言語処理モデルの構造的変遷を概観する。
- Attentionの基本概念
- Attentionとは何か、なぜ必要とされるのかを明確にし、特にEncoder-Decoder Attention(別名:Source-Target Attention)の役割を整理する。
- 自己注目と多視点処理
- Self-AttentionおよびMulti-Head Attentionの仕組みと意義を解説し、Transformerがどのようにして文脈を多面的に理解しているかを明らかにする。
- Attentionの計算構造
- Query・Key・Valueという3つのベクトルを用いたAttentionの計算手順を、数式とともに直感的に理解できるように説明する。
- Transformerの補助構成要素
- 位置エンコーディング、Layer Normalization、残差接続といった補助的な技術が、Transformerの性能と安定性にどのように寄与しているかを示す。
これらの要素を因果関係図とともに整理することで、Transformerの構造的理解を深め、G検定における応用的な出題にも対応できる知識の定着を目指す。
そして因果関係図全体像を以下に示す。
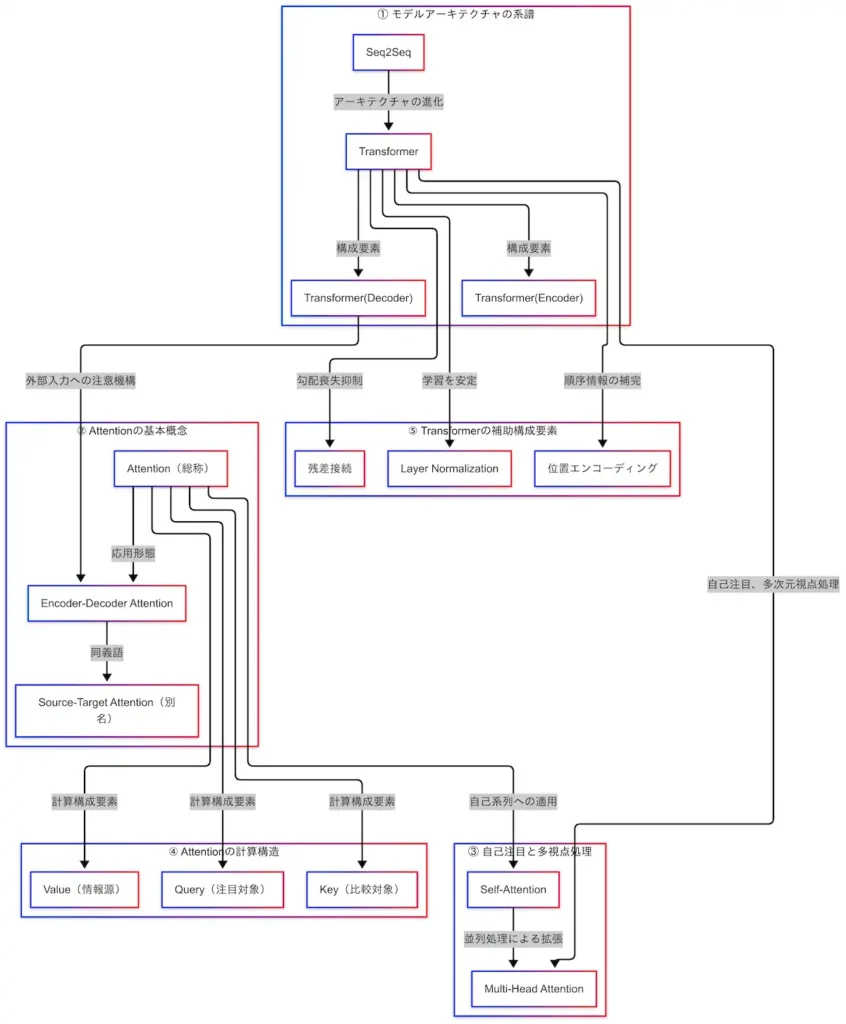
モデルアーキテクチャの系譜
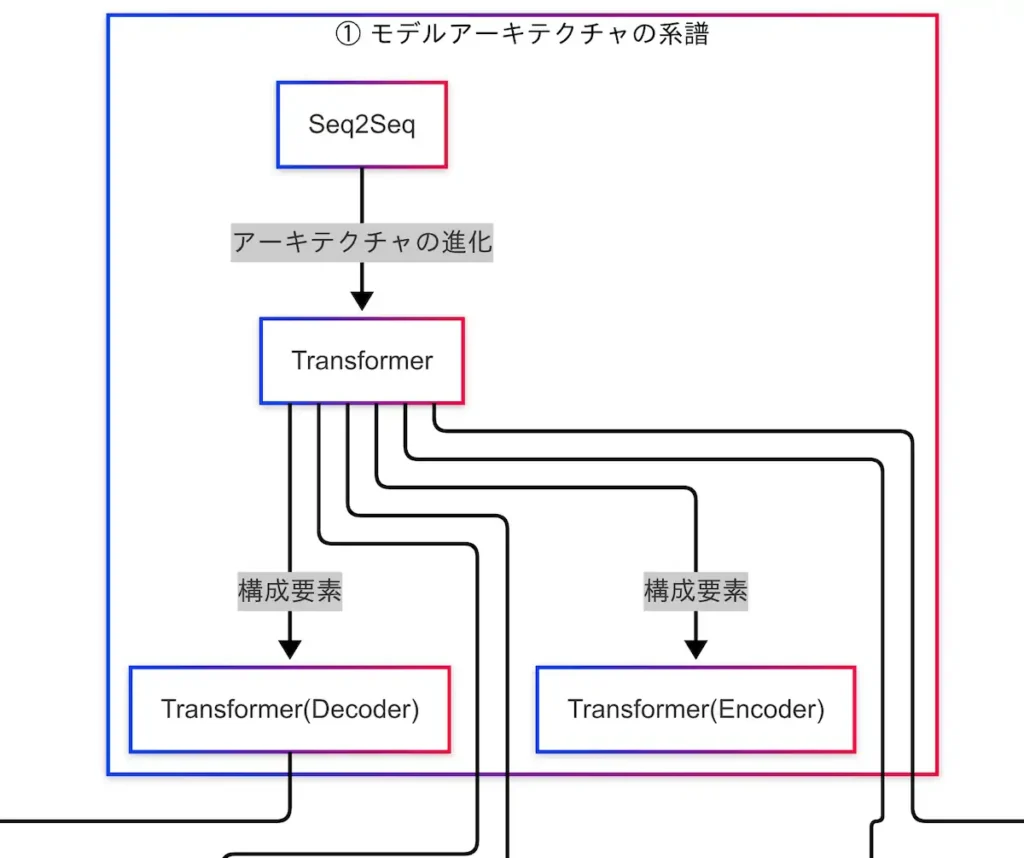
自然言語処理におけるモデルの進化は、Seq2Seq(Sequence to Sequence)からTransformerへの移行によって大きな転換点を迎えた。Seq2Seqは、入力と出力の両方が系列であるタスク(例:機械翻訳)において広く用いられてきた構造であり、エンコーダとデコーダという2つの主要な構成要素を持つ。
しかし、Seq2SeqはRNN(再帰型ニューラルネットワーク)を基盤としているため、長い文脈を扱う際に「勾配消失」や「文脈の忘却」といった問題が生じやすい。これらの課題に対する解決策として登場したのがAttention機構である。Attentionは、入力系列の中で重要な部分に動的に注目することで、情報の保持と抽出を効率化する技術である。
このAttentionを全面的に活用した構造が、Transformerである。TransformerはRNNを排除し、Attentionのみで構成されているため、並列処理が可能であり、長文に対しても高い性能を発揮する。Transformerの登場により、自然言語処理モデルは大きく進化した。
さらに、Transformerはエンコーダとデコーダの構造を明確に分離しており、それぞれが異なる用途に特化して発展している。Transformer Encoderは文の理解に特化しており、BERTなどのモデルに応用されている。一方、Transformer Decoderは文の生成に強みを持ち、GPTなどのモデルに活用されている。
このように、Seq2Seq → Transformer → Encoder/Decoder分化という系譜は、自然言語処理モデルの理解系と生成系への分岐を示しており、BERTとGPTの違いを理解する上でも重要な視点となる。
因果関係図においては、Seq2SeqからTransformerへの進化が示され、TransformerからEncoderとDecoderへの分岐が明示されている。これにより、技術の流れと構造的な関係性が視覚的に把握できるようになっている。
Attentionの基本概念
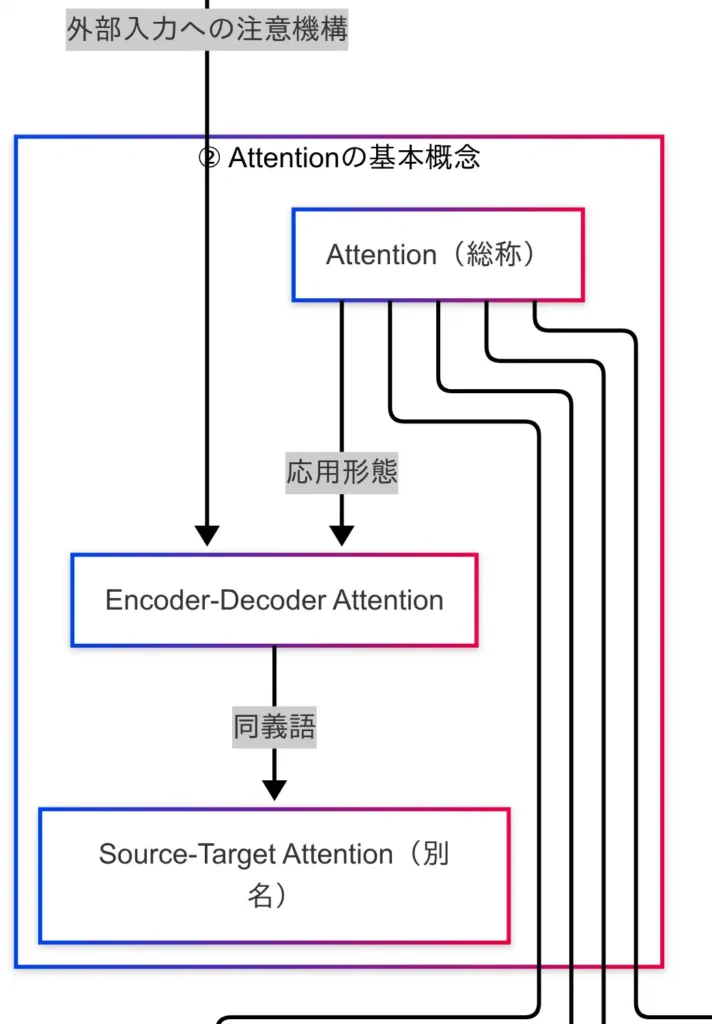
Transformerの中核技術であるAttentionは、入力情報の中から「どの部分が重要か」を動的に判断し、出力に反映する仕組みである。これは、人間が文章を読む際に、文脈に応じて意味のある単語に自然と注目する行為に近い。
Attentionには複数の種類が存在するが、まず理解すべきはEncoder-Decoder Attentionである。これは、エンコーダが処理した入力系列に対して、デコーダが「どこに注目すべきか」を決定する機構である。翻訳タスクを例に取れば、英語の「I love cats」という文を日本語の「私は猫が好きです」と訳す際に、「cats」という単語に注目して「猫」と訳すような処理が行われる。
このEncoder-Decoder Attentionは、Source-Target Attentionとも呼ばれる。G検定では、こうした別名にも注意が必要である。因果関係図においては、Transformer Decoderから「外部入力への注意機構」としてEncoder-Decoder Attentionに矢印が伸びており、Transformerの出力生成における重要な役割を担っていることが示されている。
さらに、TransformerではEncoderにもDecoderにもAttentionが組み込まれており、それぞれがSelf-Attentionという仕組みを用いている。Self-Attentionとは、同一系列内の各単語が他のすべての単語に対して「どれだけ関係があるか」を計算するものである。例えば、「彼は銀行で働いている」という文において、「銀行」と「働く」が意味的に関連していると判断されるような処理が行われる。
このSelf-Attentionは、文の意味を深く理解するための「文脈の内省」とも言える。Transformerでは、EncoderもDecoderもこのSelf-Attentionを活用することで、文脈の全体像を把握し、意味のある出力を生成している。
因果関係図では、AttentionからSelf-Attentionへの矢印が示されており、Transformer内部での自己系列への適用が明示されている。次章では、このSelf-Attentionをさらに拡張したMulti-Head Attentionについて解説する。


コメント