
「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
バックナンバーはこちら

本稿は「G検定対策 究極カンペをつくろう」シリーズの第12回として、シラバス「ディープラーニングの応用例」にあるモデルの軽量化を扱う。究極カンペとは、実在するカンペそのものではなく、学習者の中に立ち上がる知識体系を指す、という立場を取る。バックナンバー一覧は次のページにまとまっている。 https://www.simulationroom999.com/blog/g-test-preparation-make-the-ultimate-cheat-papers-back-number/
今回の狙いは、用語暗記を増やすことではない。背景→必要性→手法→効果→ユースケースが因果で接続され、「なぜ必要か」「どこで効くか」まで一息で説明できる状態を作ることにある。
動画シリーズ
G検定の究極カンペ関連動画の再生リスト

到達目標
- モデルの軽量化が必要になる背景を、現実制約の連鎖として捉えられるようになる
- 軽量化が必要なユースケースを、エッジAIを中心に思い浮かべられるようになる
- 代表的な軽量化手法(プルーニング・量子化・蒸留・宝くじ仮説)を、効果と注意点込みで整理できるようになる
因果関係図で「一本の線」を作る
今回の究極カンペは、次の順に一直線で読む構造となる。
背景 → 必要性 → モデル圧縮 → 代表手法 → 効果(+注意点) → エッジAI → ユースケース
まずは全体像を1枚で固定しておく。

以降の説明は、図1を左から右へ拡大読解する流れになる。
背景:高性能化の副作用としての巨大化
出発点は「DLモデルの高性能化」である。性能向上は歓迎されやすい一方で、高性能化はしばしばモデルの巨大化(パラメータ増・演算増)を伴う。ここから先は、理想ではなく現実の制約が主役になっていく。
巨大化が連鎖させやすい制約は、図1の「背景」ブロックに集約してある。
- 計算資源制約(CPU/GPU/メモリ):そもそも載らない/回らない方向に寄りやすい
- レイテンシ増(応答遅延):間に合わない場面が増えやすい
- 消費電力・発熱増:電池・熱設計の制約に刺さりやすい
- 通信/クラウド依存(帯域・料金):送り続けるほど厳しくなりやすい
- プライバシ/オフライン要件:送れない/送らない事情が現場側に生まれやすい
こうした制約が重なると、「軽量化は贅沢」ではなく「成立条件」へ寄っていく。特にエッジ側でAIを成立させる議論は、エッジコンピューティングとAIの接合(Edge Intelligence)として整理され、端末側推論や端末側学習まで含む課題が俯瞰されている。
ユースケース:軽量化の目的地はエッジAIになる
軽量化で得たいものは、図1の右側にあるエッジAI(オンデバイス推論)の要求と直結しやすい。ここを補助的に見える化する。
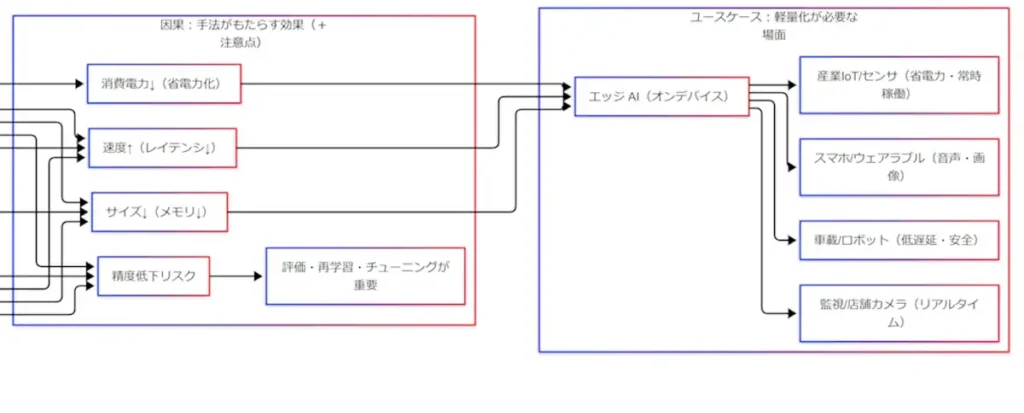
エッジAIの代表例としては、次のような場面が想起しやすい。
- スマホ/ウェアラブル:端末内で音声・画像を即応したい
- 監視/店舗カメラ:リアルタイム性と帯域制約が同時に効きやすい
- 産業IoT/センサ:省電力で常時稼働したい
- 車載/ロボット:遅延が安全要件に近くなりやすい
この段階で「軽量化が必要 → エッジAI」という矢印が、単なる知識ではなく現場の論理として見えやすくなる。
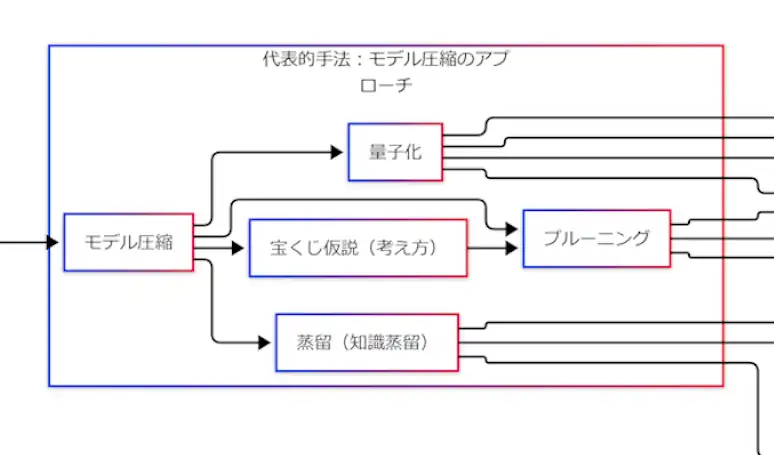
代表的手法:モデル圧縮を“作用”で整理する
図1の中央にある「モデル圧縮」は、軽量化を実現する代表的な枠組みである。G検定のキーワードとしては、次の三本柱に加えて宝くじ仮説(考え方)が並びやすい。
- プルーニング:重み・ニューロン・チャネルなどを刈り込む
- 量子化:重みや演算を低ビットで表現する(例:FP32→INT8)
- 蒸留(知識蒸留):大モデル(教師)の知識を小モデル(生徒)へ移す
- 宝くじ仮説:巨大モデル内に「当たりサブネット」が潜むという見方
ここは「名称」で覚えるより、「何にどう作用するか」で束ねた方が混ざりにくい。
プルーニング:刈り込む発想
プルーニングは、重要度の低い結合や構造を削って軽くしていく発想となる。代表例として、剪定→量子化→符号化を組み合わせる「Deep Compression」の三段パイプラインが挙げられ、剪定後・量子化後に再調整(再学習)を挟む構成が明示されている。
量子化:ビット幅を下げる発想
量子化は、重みや活性、演算を低精度化して計算・メモリを軽くする方向になる。整数演算のみで推論できる設計と、精度劣化を抑える学習設計がセットで語られることも多い。
また実務上は、PTQ(学習後量子化)やQAT(量子化対応学習)などの整理が、モバイル実装の文脈でまとまっている。
蒸留:大きい教師から小さい生徒へ
蒸留(知識蒸留)は、教師モデルの出力分布などを手掛かりに、生徒モデルが近い振る舞いを学ぶ枠組みになる。元の議論は「アンサンブルの知識を単一モデルへ圧縮する」方向として提示され、展開の中心に蒸留が置かれている。
宝くじ仮説:当たりサブネットという見方
宝くじ仮説は「直接の圧縮手順」というより、密なネットワークの中に、学習がうまく進みやすい疎なサブネット(winning ticket)が含まれうる、という見方になる。これを知っていると、プルーニング系の議論が「ただ削る」から「当たり構造を残す」へ読み替えやすい。
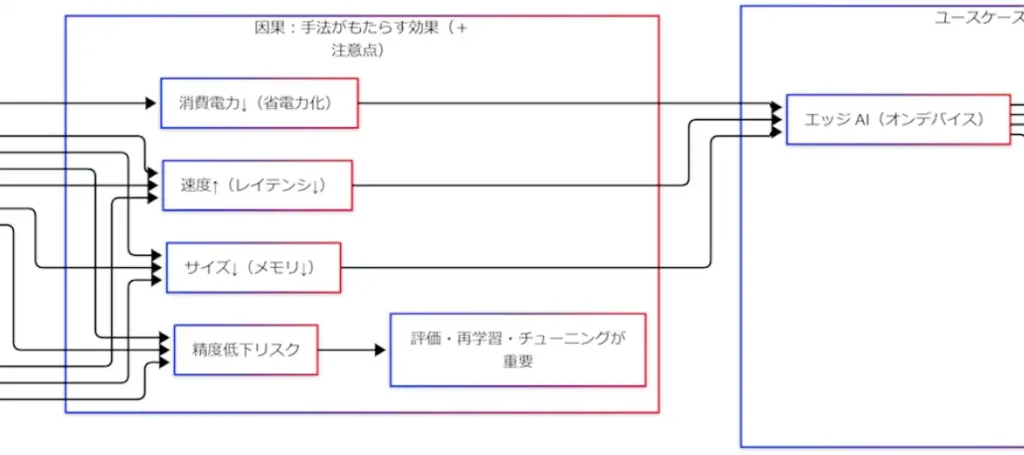
因果:効果は三つに収束し、注意点は一つに集まる
手法が違っても、軽量化で得たい効果は次の三つに寄りやすい。
- 速度↑(レイテンシ↓)
- 消費電力↓
- サイズ↓(メモリ↓)
この三点セットが揃うほど、エッジAIの成立条件を満たしやすくなる。端末側推論の重要性が語られる文脈でも、計算資源・遅延・通信などの制約が中心に置かれやすい。
一方で注意点は、ほぼ一箇所に収束していく。すなわち精度低下リスクである。削る・粗くする・小さく学ばせる以上、性能が揺れる可能性は残る。したがって軽量化は「やって終わり」ではなく、評価→必要なら再学習→チューニングまでを含めて完結すると捉える方が筋が通りやすい。剪定と量子化を組み合わせた圧縮パイプラインでも、再調整(再学習)を挟む設計が明確に述べられている。
まとめ:背景→必要性→圧縮→手法→効果→エッジ→ユースケースが一本になる
本回の要点は、図1を左から右へ一筆書きで説明できる状態になることにある。
- 高性能化は巨大化を招きやすく、計算資源・遅延・電力/発熱・通信依存・プライバシ/オフライン要件が重なって、軽量化が必要になりやすい
- 軽量化の目的地はエッジAIになり、スマホ/ウェアラブル、監視カメラ、産業IoT、車載/ロボットなどの現場に落ちやすい
- 代表手法はモデル圧縮としてプルーニング・量子化・蒸留が軸になり、宝くじ仮説は「当たりサブネット」という見方として押さえると混ざりにくい
- 効果は速度・電力・サイズに集約される一方、精度低下リスクが残るため、評価・再学習・チューニングまで含めて初めて“使える軽量化”となりやすい
これが「実在するカンペではなく、自分の中に生まれる知識体系」としての究極カンペとなる。
FAQ
Q1. モデルの軽量化とは何か?
A. 推論時に必要な計算量・メモリ・電力・遅延を減らし、制約の厳しい環境(特にエッジAI)でもモデルを成立させやすくするための最適化、と整理できる。
Q2. プルーニングと蒸留はどう違う?
A. プルーニングはモデル内部の結合や構造を刈り込んで軽くする方法となる。一方、蒸留は教師モデルの振る舞いを手掛かりに、生徒モデル(小型モデル)へ知識を移し、軽いモデルでも性能を出すことを狙う枠組みといえる。
Q3. 量子化は量子力学と関係がある?
A. ここでの量子化は量子力学というより、重みや演算を低ビット表現(例:FP32→INT8)にして軽くする発想として捉えると理解しやすい。
Q4. 宝くじ仮説の「当たり」とは何を指す?
A. 密なネットワークの中に、学習がうまく進みやすい疎なサブネット(winning ticket)が含まれうる、という見方を指す。
Q5. 軽量化で精度が落ちたらどう回収していく?
A. 評価を行い、必要に応じて再学習(微調整)や量子化対応学習などで回収していく流れになる。軽量化は「圧縮→評価→再調整」まで含めて完結すると考えると、実装・運用の感覚にも合いやすい。
「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
参考文献
- Geoffrey Hinton, Oriol Vinyals, Jeff Dean, “Distilling the Knowledge in a Neural Network”
https://arxiv.org/abs/1503.02531(arXiv) - Song Han, Huizi Mao, William J. Dally, “Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding”
https://arxiv.org/abs/1510.00149(arXiv) - Jonathan Frankle, Michael Carbin, “The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks”
https://arxiv.org/abs/1803.03635(arXiv) - Benoit Jacob et al., “Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference”
https://arxiv.org/abs/1712.05877(arXiv) - Shuiguang Deng et al., “Edge Intelligence: The Confluence of Edge Computing and Artificial Intelligence”
https://arxiv.org/abs/1909.00560(arXiv)
バックナンバーはこちら
深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト 第3版

徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版 徹底攻略シリーズ

ディープラーニングG検定(ジェネラリスト) 法律・倫理テキスト



コメント