
その他のエッセイはこちら

Vision-Language Model(VLM)が画像を「どこまで理解しているのか」、気になりますよね。
- ピクセル単位でセグメンテーションしているのか?
- Self-Attention の中ではどんな形の行列が動いているのか?
- マルチスケールな特徴マップって、畳み込みなのかTransformerなのか?
本記事は、Transformer / Self-Attention を一度は触ったことがあるエンジニア向けに、
VLM(CLIP, LLaVA, GPT-4V など)を題材に トークン・Attention・マルチスケール・セグメンテーションの関係を整理するのが目的です。
※ この記事で言う「暗黙のセグメンテーション」は、
「ある概念(例: dog)に対して、その概念が写っている領域にAttentionが集まりやすい」という
ざっくりした “領域分け” の意味で使います。
ピクセルごとの厳密なラベリングそのものを指すわけではありません。
1. VLMはピクセルではなく「トークン列」を見ている
多くのVLM(CLIP / LLaVA / GPT-4V など)は、中身を見るとほぼ Transformer 系 です。
- テキスト → サブワードトークン列
- 画像 → パッチトークン列(Vision Transformer 的)
- それらを Self-Attention / Cross-Attention で混ぜる
という構造になっています。
ここで重要なのは:
モデルが直接見ているのは「ピクセル」ではなく、 「トークン列 × 埋め込み次元」で表現された行列である
という点です。
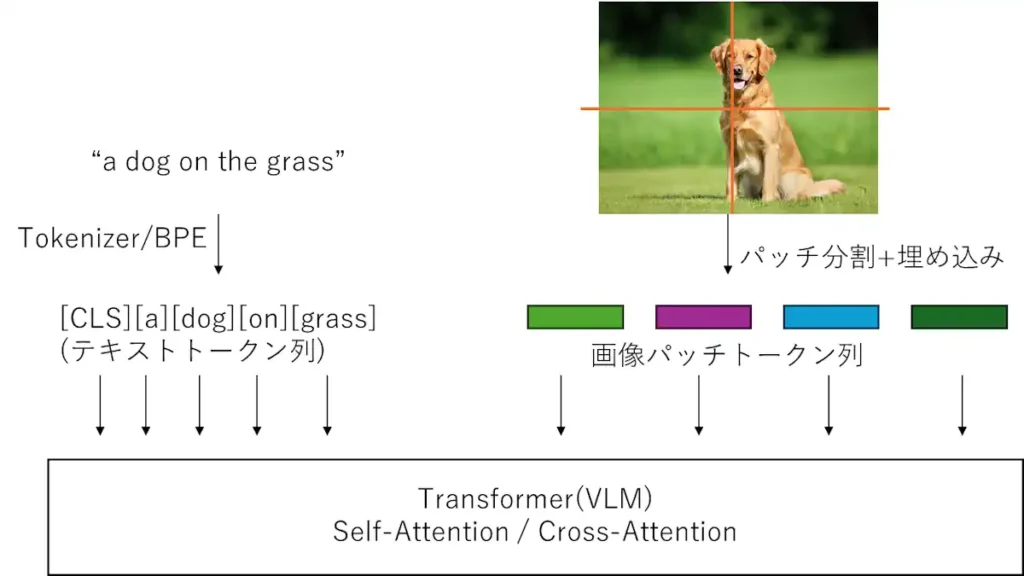
図1:VLMは、テキストトークン列と画像パッチトークン列をまとめてTransformerに入力し、トークン間の関係をSelf-Attentionで学習している。
Self-Attention の入力形状
バッチを 1 つだけ取り出して考えると、Self-Attention の入力はだいたい
$$
X \in \mathbb{R}^{N \times d_{\text{model}}}
$$
と書けます。
- $N$:トークン数(系列長)… 行数
- $d_{\text{model}}$:各トークンの埋め込み次元 … 列数
つまり、
- 1行 = 1トークン
- 列方向に「そのトークンの意味・特徴」が詰まっている
というイメージです。
実装レベルでは、バッチ次元も含めて
$$
X \in \mathbb{R}^{B \times N \times d_{\text{model}}}
$$
となります($B$ はバッチサイズ)。
2. Self-Attention の数式と「トークン間関係」
Self-Attention の中で何が起きているかを、shape 付きで見てみます。
まず、入力 $X$ からクエリ・キー・バリューを作ります:
$$
Q = X W_Q,\quad K = X W_K,\quad V = X W_V
$$
- $X \in \mathbb{R}^{N \times d_{\text{model}}}$
- $W_Q, W_K, W_V \in \mathbb{R}^{d_{\text{model}} \times d_k}$
- よって $Q, K, V \in \mathbb{R}^{N \times d_k}$
Self-Attention 本体は
$$
\mathrm{Attention}(Q, K, V)
= \mathrm{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right) V
$$
ここで
- $QK^\top \in \mathbb{R}^{N \times N}$
- 各要素 $(i, j)$ が「トークン $i$ がトークン $j$ をどれだけ見るか」のスコア
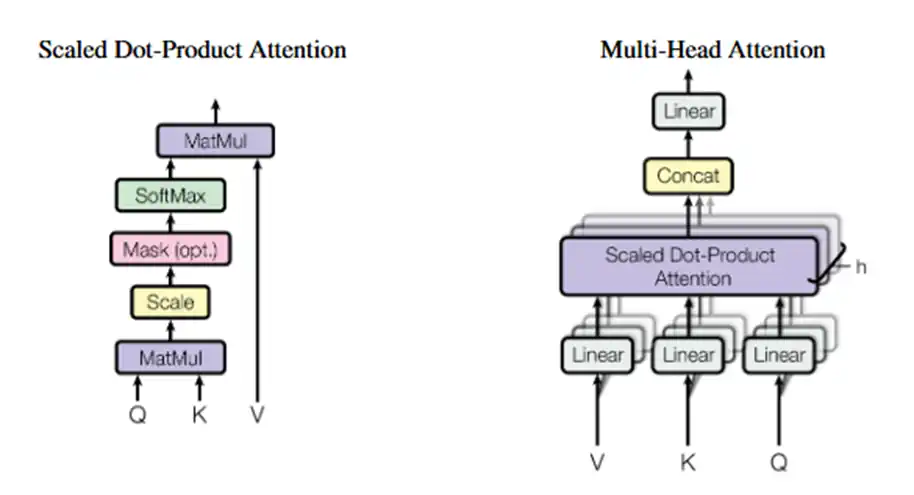
図2:Self-Attentionは、入力 $X \in \mathbb{R}^{N \times d_{\text{model}}}$ から $QK^\top \in \mathbb{R}^{N \times N}$ を作り、「どのトークンがどのトークンをどれだけ見るか」を表現する。(Vaswani et al. (2017) より引用)https://arxiv.org/pdf/1706.03762
つまり、Attention は「トークン × トークン」の関係行列を通して、
どのトークンが、どのトークンにどれくらい注目すべきか
を学習している構造です。
ここまでは テキストだけのTransformer も VLM も同じ。
違いは「トークンに画像が混ざってくる」ことです。
3. 画像はどうやって「トークン」になるのか?(Vision Transformer)
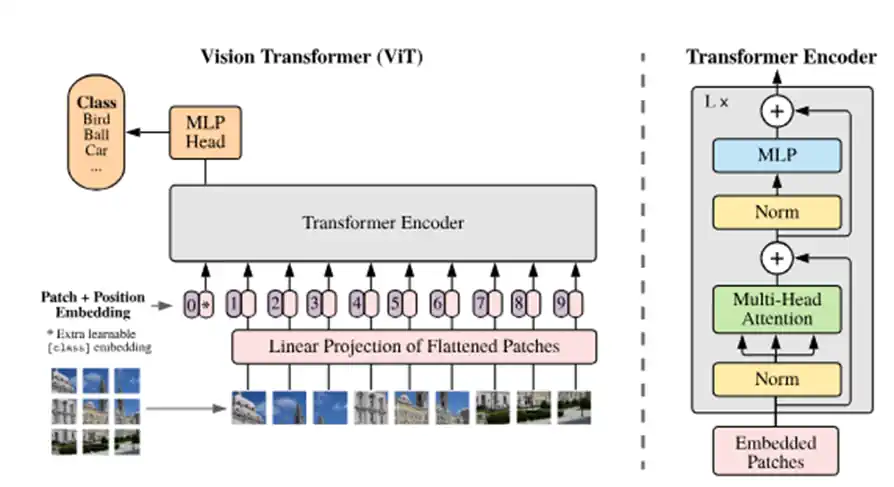
図3:Vision Transformerでは画像をパッチに分割し、各パッチをflatten+線形変換してトークン化する。1枚の画像から $N$ 個のパッチトークンが得られ、Self-Attentionに入力される。https://arxiv.org/pdf/2010.11929
Vision Transformer (ViT) 系のモデルでは、画像もトークン列に変換されます。
- 入力画像
$$
x \in \mathbb{R}^{B \times C \times H \times W}
$$ - 各画像を $P \times P$ のパッチに分割
(元論文だと $P = 16$ がよく使われます) - 1枚の画像あたりのパッチ数は
$$
N = \frac{H \times W}{P^2}
$$ - 各パッチ(形は $P \times P \times C$)を flatten してベクトル化
- 線形変換(あるいはConv)で埋め込み
$$
z_i=E\cdot\mathrm{flatten}(\text[patch]_i) \in \mathrm{R}^{d_{\text{model}}}
$$ - 位置埋め込み(positional embedding)を加えて列に並べる
結果として、1枚あたり
$$
X_{\text{(single image)}} \in \mathbb{R}^{N \times d_{\text{model}}}
$$
となり、バッチ全体としては
$$
X \in \mathbb{R}^{B \times N \times d_{\text{model}}}
$$
という形で Self-Attention に入ります。
ここで用語がややこしいですが、
- バッチ(batch) = 一度に処理する画像の枚数 → $B$
- パッチ(patch) = 画像の中の小さな2D領域 → それを1Dにして埋め込んだものが1トークン
という関係です。
テキスト+画像トークンを一緒に扱う
テキストトークン列を $T \in \mathbb{R}^{N_{\text{text}} \times d_{\text{model}}}$、
画像トークン列を $Z \in \mathbb{R}^{N_{\text{img}} \times d_{\text{model}}}$ とすると、
$$
X_{\text{all}} =
\begin{bmatrix}
T \
Z
\end{bmatrix}
\in \mathbb{R}^{(N_{\text{text}} + N_{\text{img}}) \times d_{\text{model}}}
$$
のように縦に連結して、
テキスト+画像をまとめて1本のシーケンスとして処理する、という設計がよく使われます。
(CLIP, LLaVA 系の図を思い浮かべるとイメージしやすいです)
4. Attention は「暗黙のセグメンテーション」になっているのか?
ここからが本題です。
セグメンテーションとは何が違う?
従来のセマンティックセグメンテーションは、
- 各ピクセルにクラスラベルを割り当てる $$
y_{u,v} \in {0, 1, \dots, K-1}
$$ - U-Net, DeepLab, Mask2Former, SAM などは
ピクセル単位 or マスク単位の正解ラベルで教師あり学習
という世界です。
一方 VLM(CLIP, LLaVA, GPT-4V など)では、
- 画像–テキストの対応(「このキャプションとこの画像はペアか?」)や
- マルチモーダル生成タスク(画像キャプション、画像QAなど)
を通じて、
「どの画像トークンが、どのテキストトークンと強く関連しているか」
が Attention や埋め込みの中に暗黙的に学習されます。
暗黙の「領域分け」=セグメンテーション的な表現
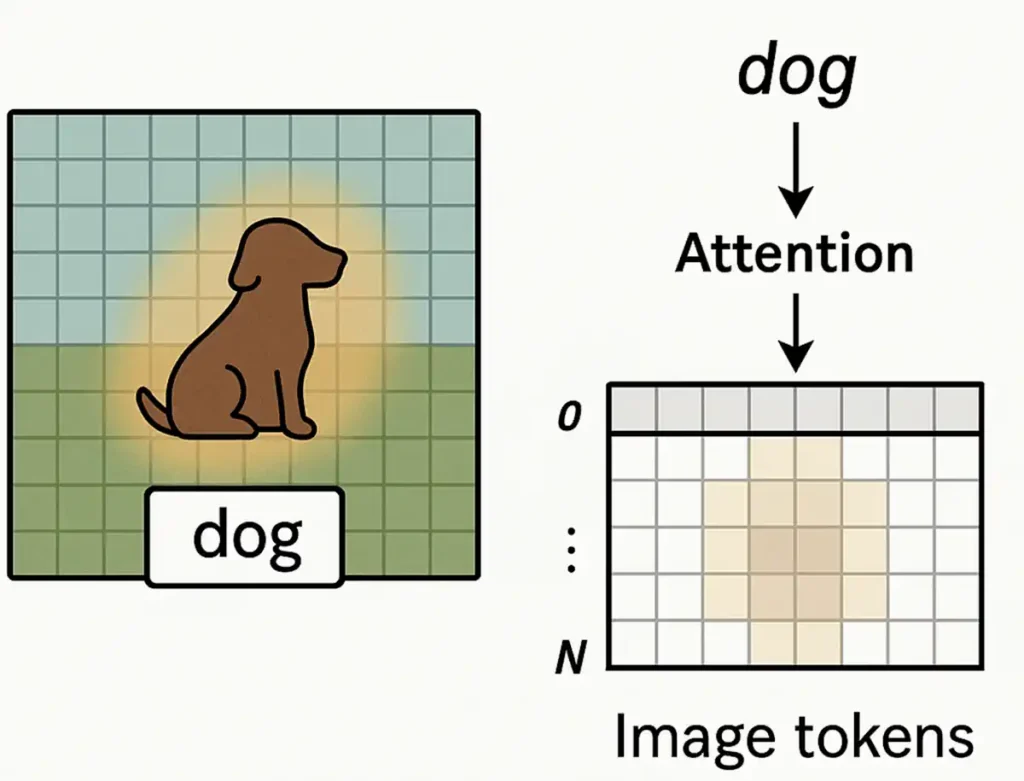
図4:「dog」というテキストトークンに対応するAttentionを画像パッチ側に投影すると、犬の領域に強く反応するヒートマップが得られる。暗黙の「領域分け」はできているが、ピクセル単位のマスクとは異なる。
例えば、「dog」というトークンに対応する Attention マップを画像トークン側に投影すると、
- 犬が写っているあたりのパッチに強い重みが乗る
- それを元の画像位置に戻して可視化すると、「犬っぽい領域」が光って見える
ことがよくあります。
これを二値化したり、後処理を加えると、
- そこそこの品質の「犬マスク」が取れたりする
- 「この辺が対象物」というざっくりした前景・背景分離には使える
という意味で、
✅ Attention の注目分布は、セグメンテーション“的な”効能を持つ
と言えます。
ただし、ここで言う「暗黙のセグメンテーション」はあくまで
「ある概念に対して、それが写っている領域にAttentionが集まる」
くらいの緩い意味であり、
専用セグメンテーションモデルのようなピクセルレベルの精密なラベリングとは別物です。
5. マルチスケール特徴は「行側(トークン)」で表現される
次の疑問:「マルチスケール」はどこでどう表現しているのか?
Self-Attention の形は変わらない
Self-Attention の入力は常に
$$
X \in \mathbb{R}^{N \times d_{\text{model}}}
$$
- 行 = トークン数 $N$
- 列 = 埋め込み次元 $d_{\text{model}}$
マルチスケールだからといって、この形が変わるわけではありません。
変わるのは「どんなトークンを並べて $N$ を構成するか」のほうです。
パターンA:CNNバックボーン由来のマルチスケール(ResNet + FPN)
古典的な検出・セグ系に多い構成です。
- ResNet などのCNNが $$
F_s \in \mathbb{R}^{H_s \times W_s \times C_s}
$$ という解像度の違う特徴マップ($s$ はスケール)を作る
(1/4, 1/8, 1/16, 1/32 … など) - Feature Pyramid Network(FPN)で、高解像度と低解像度の特徴を上方向・下方向に融合して
「各スケールごとにそこそこリッチな特徴マップ」を作る - それぞれを flatten してトークン列に変換 $$
N_s = H_s W_s,\quad
X_s \in \mathbb{R}^{N_s \times d_{\text{model}}}
$$ - 必要に応じて複数スケールの $X_s$ を結合し、Self-Attention に入力
この場合、
- マルチスケールは完全に畳み込み世界で作られた特徴
- Transformer から見ると「スケールの違うトークン列」が来ているだけ
という構造です。
パターンB:ViT系(Transformer内部でマルチスケール:Swin など)
Swin Transformer のようなViTファミリでは:
- 最初にパッチ埋め込み(実装的にはConvなことも多いが、役割的には線形変換)
- その後、ウィンドウAttentionやパッチマージを繰り返しながら $$
F_s \in \mathbb{R}^{H_s \times W_s \times C_s}
\Rightarrow X_s \in \mathbb{R}^{N_s \times d_{\text{model}}}
$$ という表現を Transformer内部で階層的に生成します。
ここでは、
- マルチスケール特徴の生成も
- それらの相互関係の学習も
ほぼ全部が Attention+MLP の世界で完結しています。
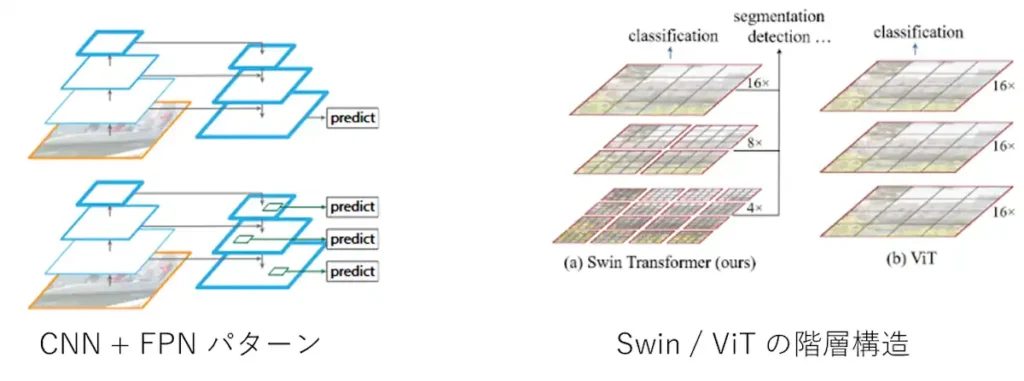
図5:マルチスケール特徴は、ResNet+FPNのようにCNN側で作ってからトークン化するパターン(左)と、Swin TransformerのようにTransformer内部で階層的にトークン数・解像度を変えていくパターン(右)がある。どちらも最終的には「トークン列」としてSelf-Attention系の処理に入っていく。
https://arxiv.org/pdf/1612.03144
https://arxiv.org/pdf/2103.14030
まとめ:マルチスケールの本質
マルチスケールは、「どの解像度の特徴で何個トークンを作るか」という“行側の設計”の話であり、 Self-Attention の入力形状そのものは $N \times d_{\text{model}}$ のまま。
- CNNバックボーンなら
→ 畳み込み+FPNで作ったマルチスケール特徴を flatten してトークン化 - ViT系なら
→ Transformer内部でトークン数・解像度を変えながらマルチスケール化
多くのViT系・マルチモーダルモデルでは、
最終的に 「トークン列」としてSelf-Attentionもしくはそれに準じた機構に入力される 点が共通しています。
6. 実務でどう活かすか
最後に、設計やPoCでの「使いどころ」をざっくり。
6.1 Attentionで済ませていいケース
- 画像キャプション、画像QA(CLIP, LLaVA など)
- 「どこを見て答えていそうか」をざっくり可視化したい
- UIのヒートマップとして「ここを見ています」を出したい
→ VLM + Attention可視化 で十分なことが多いです。
6.2 セグメンテーションが必要なケース
- 医療画像、工業検査、自動運転など
- 境界線や領域そのものがロジックになるタスク
→ 専用のセグメンテーションモデル(DeepLab, Mask2Former, SAM など)を噛ませるのが無難です。
6.3 両者を組み合わせる例(VLM + SAM)
例えばこんなフローが典型です:
- VLM(CLIP / LLaVA など)で「画像内のどの概念が重要か」を判断する
- SAM で画像から多数のマスク候補(オブジェクト候補)を自動生成する
- 各マスク領域に対して、VLMの埋め込みやAttentionを使って
「どのマスクがどの概念(dog, car, person…)に近いか」をスコアリングする - スコアの高いマスクを概念ラベル付きセグメンテーションとして使う
こうすると、
- VLM の「意味の理解」と
- SAM の「境界の精密さ」
のいいとこ取りができます。
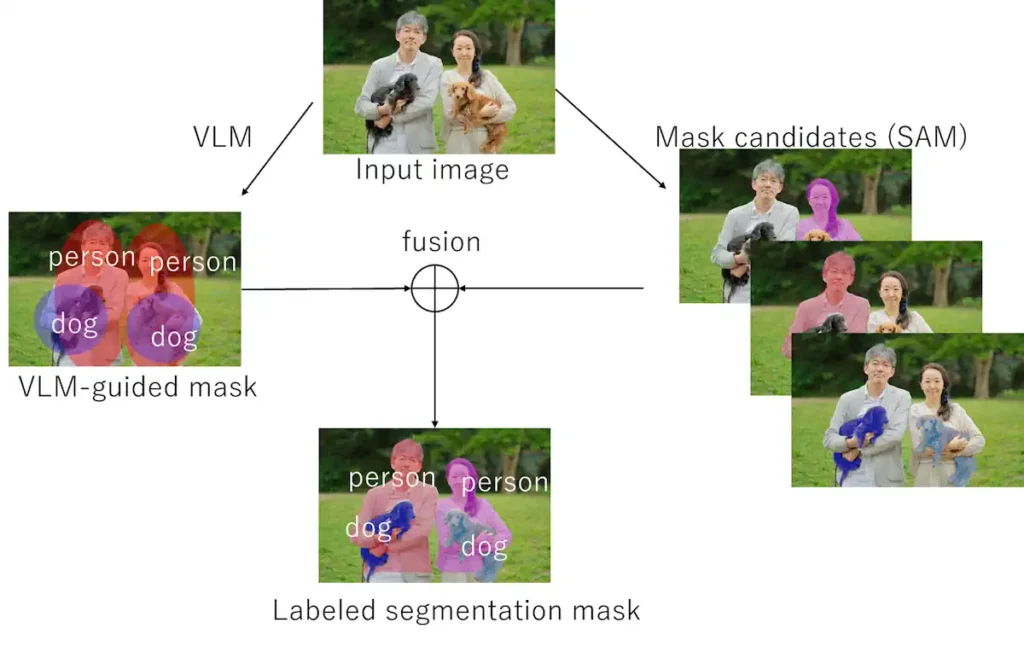
図6:VLMで「person」「dog」などの概念を推定し、SAMで生成した複数のマスク候補と対応付けることで、概念ラベル付きのセグメンテーションマスクを得るイメージ。
7. まとめ
- VLMはピクセルではなくトークン列を入力として扱う
→ $X \in \mathbb{R}^{N \times d_{\text{model}}}$ で、行=トークン、列=特徴次元 - 画像もパッチに分割して画像トークンとしてSelf-Attentionの世界に入る
→ 実装上は $X \in \mathbb{R}^{B \times N \times d_{\text{model}}}$ - Attentionマップは、特定の概念に対する暗黙の「どの領域が重要か」情報を持っており、
セグメンテーション的な効能を持つが、ピクセル精度のマスクの代わりではない - マルチスケールは「どの解像度の特徴マップから何個トークンを作るか」という
トークン側(行側)の設計で実現され、CNN由来の特徴でもTransformer由来の特徴でもOK - 実務では、
- 「ざっくりどこを見ているか」は VLM + Attention
- 「正確な境界が欲しい」は SAM / DeepLab など専用モデル
- その両者の組み合わせで PoC やプロダクト設計を考えるのが現実的
このあたりを押さえておくと、
「このモデルはどこまで“どこを見ているか”を信用していいのか?」
や
「セグメンテーションをやりたいけど、VLMだけでどこまで行けるか?」
を設計段階で見積もりやすくなるはずです。
- VLMは画像もテキストも最終的には「トークン列」として扱い、Self-Attentionでトークン同士の関係(どこをどれだけ見るか)を学習している。
- Attentionマップは「この概念は画像のどの領域に対応していそうか」という暗黙の“領域分け”情報を持つが、ピクセル精度のセグメンテーションの完全な代替ではない。
- マルチスケール特徴は、CNN+FPNでもViT系でも「解像度の異なる特徴から何個のトークンを作るか」という設計の違いであり、実務ではVLMのAttentionと専用セグメンテーション(SAMなど)を組み合わせて使うのが現実的。
よくある質問(FAQ)
Q1. VLMは内部でセグメンテーションを行っていますか?
多くのVLMは、ピクセル単位のセマンティックセグメンテーションを明示的に行っているわけではありません。ただし、Self-Attentionを通じて「どの画像トークンがどのテキストトークン(例:dog, car)と強く結びついているか」を学習しており、結果として特定の概念に対応する領域を暗黙に分けていると言えます。
その意味で、Attentionマップはセグメンテーション的な効能を部分的に発揮しますが、専用のセグメンテーションモデルの完全な代替ではありません。
Q2. Self-Attentionの入力行列の形状はどうなっていますか?
バッチを1つだけ取り出して考えると、Self-Attentionの入力は次のように表せます。
$$
X \in \mathbb{R}^{N \times d_{\text{model}}}
$$
- $N$ が一度に処理するトークン数(行数)
- $d_{\text{model}}$ が各トークンの埋め込み次元(列数)
テキストトークンも画像パッチトークンも、この「行=トークン、列=特徴ベクトル」という形にそろえて扱われます。
実際の実装では、さらにバッチ次元を含めて $X \in \mathbb{R}^{B \times N \times d_{\text{model}}}$ のような形になります($B$ がバッチサイズ)。
Q3. ViTで言う「バッチ」と「パッチ」は何が違うのですか?
用語が似ていて紛らわしいですが、役割はまったく別です。
- バッチ(batch)
- 一度にGPUに流す画像(サンプル)の枚数
- 形状で言うと $B \times C \times H \times W$ の $B$ にあたる次元です。
- パッチ(patch)
- 1枚の画像の中の小さな2D領域(例:$16 \times 16$)
- 各パッチを flatten してベクトル化し、さらに線形変換して
1つのトークンベクトル($d_{\text{model}}$ 次元)にします。
ViTでは、1枚の画像から $N$ 個のパッチトークンを作り、
$$
X \in \mathbb{R}^{B \times N \times d_{\text{model}}}
$$
という形にしてSelf-Attentionに入力します。
このとき $B$ がバッチ、$N$ が「パッチをトークン化した個数」 という関係になります。
Q4. マルチスケール特徴は畳み込みとTransformerどちらで作られますか?
これはアーキテクチャ次第です。
- ResNet + FPN のような構成では、畳み込みネットワークが解像度の異なる特徴マップを作り、それをflattenしてトークン列化し、Transformerに渡します。
- Swin Transformer などのViT系では、パッチマージなどの操作を通じてTransformer内部でマルチスケールなトークン表現を生成します。
どちらにせよ、最終的には「マルチスケールな特徴マップ」をトークン列にして、
Self-Attention の入力 $X \in \mathbb{R}^{N \times d_{\text{model}}}$ として扱う点は共通です。
Q5. Attentionマップだけでセグメンテーションモデルの代わりになりますか?
Attentionマップから「モデルがどの領域を強く見ているか」はかなりよく分かるので、
- 領域のざっくりした可視化
- UI上のヒートマップ
- 注視領域のデバッグ
といった用途には十分使えます。
一方で、医療画像や自動運転、工業検査など、ピクセルレベルの境界やマスク精度が重要なタスクでは、
SAM や DeepLab などの専用セグメンテーションモデルの方が信頼性・精度の面で有利です。
実務では「VLMのAttentionで領域を絞り、必要に応じて専用セグメンテーションを組み合わせる」という使い方が現実的です。
参考文献
Transformer / Self-Attention の基礎
- Vaswani, A., Shazeer, N., Parmar, N., et al., “Attention Is All You Need,” NeurIPS, 2017.
https://arxiv.org/abs/1706.03762
Vision Transformer・バックボーン / マルチスケール表現
- Dosovitskiy, A., Beyer, L., Kolesnikov, A., et al., “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale,” ICLR, 2021.
https://arxiv.org/abs/2010.11929 - Liu, Z., Lin, Y., Cao, Y., et al., “Swin Transformer: Hierarchical Vision Transformer using Shifted Windows,” ICCV, 2021.
https://arxiv.org/abs/2103.14030 - Lin, T.-Y., Dollár, P., Girshick, R., et al., “Feature Pyramid Networks for Object Detection,” CVPR, 2017.
https://arxiv.org/abs/1612.03144
Vision-Language Model / マルチモーダルモデル
- Radford, A., Kim, J. W., Hallacy, C., et al., “Learning Transferable Visual Models From Natural Language Supervision,” ICML, 2021. (CLIP)
https://arxiv.org/abs/2103.00020 - Jia, C., Yang, Y., Xia, Y., et al., “Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision,” ICML, 2021. (ALIGN)
https://arxiv.org/abs/2102.05918 - Yu, J., Wang, Z., Vasudevan, V., et al., “CoCa: Contrastive Captioners are Image-Text Foundation Models,” 2022.
https://arxiv.org/abs/2205.01917 - Alayrac, J.-B., Donahue, J., Luc, P., et al., “Flamingo: A Visual Language Model for Few-Shot Learning,” 2022.
https://arxiv.org/abs/2204.14198 - Li, J., Li, D., Xiong, C., Hoi, S., “BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models,” ICML, 2023.
https://arxiv.org/abs/2301.12597 - Liu, H., Li, C., Li, Y., et al., “Visual Instruction Tuning,” NeurIPS, 2023. (LLaVA)
https://arxiv.org/abs/2304.08485 - OpenAI, “GPT-4 Technical Report,” 2023.
https://arxiv.org/abs/2303.08774
セグメンテーション / マスク生成 / Open-Vocabulary セグメンテーション
- Chen, L.-C., Zhu, Y., Papandreou, G., Schroff, F., Adam, H., “Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation,” ECCV, 2018. (DeepLabv3+)
https://arxiv.org/abs/1802.02611 - Ronneberger, O., Fischer, P., Brox, T., “U-Net: Convolutional Networks for Biomedical Image Segmentation,” MICCAI, 2015.
https://arxiv.org/abs/1505.04597 - Cheng, B., Misra, I., Schwing, A. G., Kirillov, A., Goyal, P., “Masked-attention Mask Transformer for Universal Image Segmentation,” CVPR, 2022. (Mask2Former)
https://arxiv.org/abs/2112.01527 - Kirillov, A., Mintun, E., Ravi, N., et al., “Segment Anything,” ICCV, 2023. (SAM)
論文: https://arxiv.org/abs/2304.02643
プロジェクト: https://segment-anything.com - Lüddecke, T., Ecker, A. S., “Image Segmentation Using Text and Image Prompts,” CVPR, 2022. (CLIPSeg)
論文: https://arxiv.org/abs/2112.10003
コード: https://github.com/timojl/clipseg - Rao, Y., Zhao, W., Chen, G., et al., “DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting,” CVPR, 2022.
論文: https://arxiv.org/abs/2112.01518
コード: https://github.com/raoyongming/DenseCLIP - Xu, J., De Mello, S., Liu, S., et al., “GroupViT: Semantic Segmentation Emerges from Text Supervision,” CVPR, 2022.
論文: https://arxiv.org/abs/2202.11094
コード: https://github.com/NVlabs/GroupViT - Ghiasi, G., Gu, X., Cui, Y., Lin, T.-Y., “Scaling Open-Vocabulary Image Segmentation with Image-Level Labels,” 2021. (OpenSeg)
論文: https://arxiv.org/abs/2112.12143
コード: https://github.com/tensorflow/tpu/tree/master/models/official/detection/projects/openseg - Liang, F., Wu, B., Dai, X., et al., “Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP,” CVPR, 2023. (OVSeg)
論文: https://arxiv.org/abs/2210.04150
コード: https://github.com/facebookresearch/ov-seg - Ding, Z., Wang, J., Tu, Z., “Open-Vocabulary Universal Image Segmentation with MaskCLIP,” ICML, 2023.
論文: https://arxiv.org/abs/2208.08984
コード: https://github.com/mlpc-ucsd/MaskCLIP - Vibashan, V. S., Borse, S., Park, H., et al., “PosSAM: Panoptic Open-Vocabulary Segment Anything,” 2024.
論文: https://arxiv.org/abs/2403.09620
プロジェクト: https://vibashan.github.io/possam-web/
機械学習エンジニアのためのTransformers ―最先端の自然言語処理ライブラリによるモデル開発

Vision Transformer入門 (Computer Vision Library)

大規模言語モデル入門

その他のエッセイはこちら

コメント