
「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
バックナンバーはこちら

はじめに
強化学習は、人工知能(AI)の中でも特に「試行錯誤によって学習する」能力に焦点を当てた分野である。エージェントが環境と相互作用しながら報酬を得て、より良い行動を選択できるようになるという仕組みは、ゲームAIやロボット制御、自動運転など、現代の多くの応用分野において重要な役割を果たしている。
本記事では、G検定対策として、強化学習の技術体系を因果関係図に基づいて整理し、理解を深めることを目的とする。単なる用語の暗記ではなく、技術同士のつながりや進化の流れを把握することで、より実践的かつ体系的な知識の習得が可能となる。
対象とする内容は、強化学習の基本構造から始まり、価値ベースアルゴリズム、方策勾配アルゴリズム、分散・統合型アルゴリズム、補助・拡張技術、学習設定と環境構築、そして応用事例に至るまで、広範囲にわたる。各技術がどのように連携し、どのような課題を解決してきたのかを、因果関係図を通じて明らかにしていく。
次章では、本記事で扱う説明内容の全体像を概観する。
動画シリーズ
G検定の究極カンペ関連動画の再生リスト

説明内容
本記事では、強化学習の技術体系を以下の7つの観点から整理する。
- 強化学習の基本構造
- 価値ベースアルゴリズム
- 方策勾配アルゴリズム
- 分散・統合型アルゴリズム
- 補助・拡張技術
- 学習設定と環境構築
- 応用事例
これらは、単なる技術の羅列ではなく、因果関係によって相互に関連している。強化学習は「報酬をもらって学習する」という直感的な仕組みを持つが、その背後には多様なアルゴリズムと補助技術が存在し、学習の安定性や汎化性能を高めるための工夫が凝らされている。
例えば、ゲームAIの代表例である「OpenAI Five」や「AlphaStar」は、方策勾配アルゴリズムであるPPOをベースに構築されており、複数のエージェントが協調して学習するマルチエージェント環境にも対応している。また、ロボット制御や自動運転といった現実世界への応用においては、連続値制御やsim2real技術が重要な役割を果たしている。
強化学習の理解においては、単語の暗記よりも「技術のつながり」を把握することが重要である。因果関係図を用いることで、各技術がどのように進化し、どのような課題に対応してきたのかを視覚的に理解することが可能となる。
以下に、今回の説明内容を整理した因果関係図を示す。
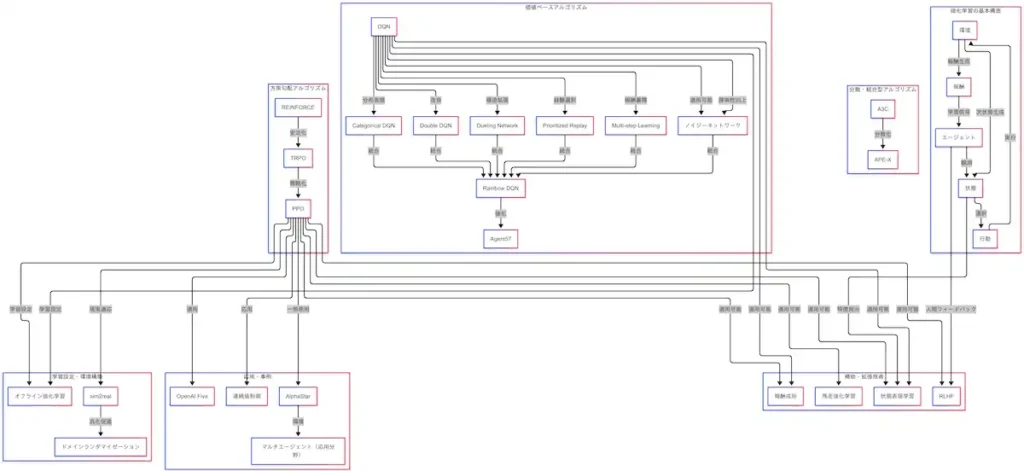
強化学習の基本構造
強化学習の技術体系を理解するうえで、まず押さえておくべきは因果関係図の最も根幹に位置する「基本構造」である。図の中央には、「状態」「行動」「報酬」「環境」「エージェント」という5つの要素が配置されており、これらが強化学習の学習ループを構成している。
因果関係図に従えば、エージェントはまず環境を観測し、「状態」を取得する。次に、その状態に基づいて「行動」を選択し、環境に対して実行する。環境はその行動に応じて「報酬」と「次の状態」を生成し、それらが再びエージェントに返される。この一連の流れが、強化学習の基本ループである。
このループを繰り返すことで、エージェントは報酬を最大化するように行動方針を改善していく。報酬が高かった行動は強化され、低かった行動は抑制される。まさに「試して、褒められて、成長する」仕組みである。
しかし、環境が複雑である場合、状態をそのまま扱うことは困難である。そこで因果関係図では、「状態 → 状態表現学習」という接続が示されている。これは、状態から有用な特徴を抽出し、学習しやすい形式に変換する技術である。画像データであればCNN、時系列データであればRNNやTransformerが用いられる。
さらに、因果関係図には「エージェント → RLHF(人間フィードバックによる強化学習)」という接続も存在する。これは、エージェントの行動に対して人間がフィードバックを与えることで、より望ましい方策を学習させる手法である。ChatGPTなどの大規模言語モデルにも応用されており、AIが人間の価値観に沿った行動を学ぶための重要な技術である。
このように、因果関係図を参照することで、強化学習の基本構造が単なるループではなく、状態の表現や人間の介入といった補助技術と密接に関係していることが理解できる。これらの基礎を押さえておくことで、次章以降に登場する各種アルゴリズムの位置づけや役割も明確になる。
価値ベースアルゴリズム
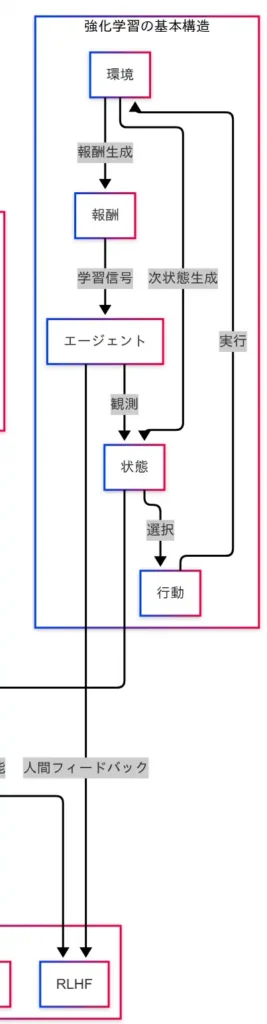
因果関係図において、「価値ベースアルゴリズム」はDQN(Deep Q-Network)を起点として複数の技術が枝分かれし、最終的にはAgent57に至るまでの進化の流れが描かれている。これらはすべて、Q値(行動の価値)を推定することによって、より良い行動を選択するという基本方針に基づいている。
まず、DQNは強化学習における価値ベース手法の代表格であり、状態に対して各行動のQ値を予測することで、最適な行動を選択する。因果関係図では、DQNから以下の技術が派生している。
- Double DQN:Q値の推定を分離することで、過剰な期待値の推定を抑制し、学習の安定性を向上させる。
- Dueling Network:状態の価値と行動の価値を分離して学習する構造であり、行動選択における情報の分解が可能となる。
- Prioritized Experience Replay:重要な経験を優先的に再学習することで、効率的な学習を実現する。
- Multi-step Learning:単一ステップの報酬ではなく、複数ステップ先の報酬を考慮することで、長期的な価値の推定が可能となる。
- Noisy Network:ネットワークにノイズを導入することで、探索性を高める工夫である。
- Categorical DQN:報酬の分布を扱うことで、より豊かな価値表現を可能にする。
これらの技術は、因果関係図において「Rainbow DQN」に統合されている。Rainbowは、DQNの改良技術群を一つにまとめたアルゴリズムであり、探索性・安定性・表現力のバランスを高次元で実現している。
Rainbowの先には、さらに強化された「Agent57」が位置している。Agent57は、Rainbowの技術をベースに、難易度の高い環境でも学習可能な構造を備えており、強化学習の限界を押し広げる存在である。
このように、因果関係図を参照することで、価値ベースアルゴリズムの技術的進化が一本の道として視覚的に理解できる。DQNを起点とした技術群は、強化学習の中でも特に発展が早く、応用範囲も広い。各技術の役割とつながりを把握することで、G検定対策としても有効な知識体系が構築される。
方策勾配アルゴリズム
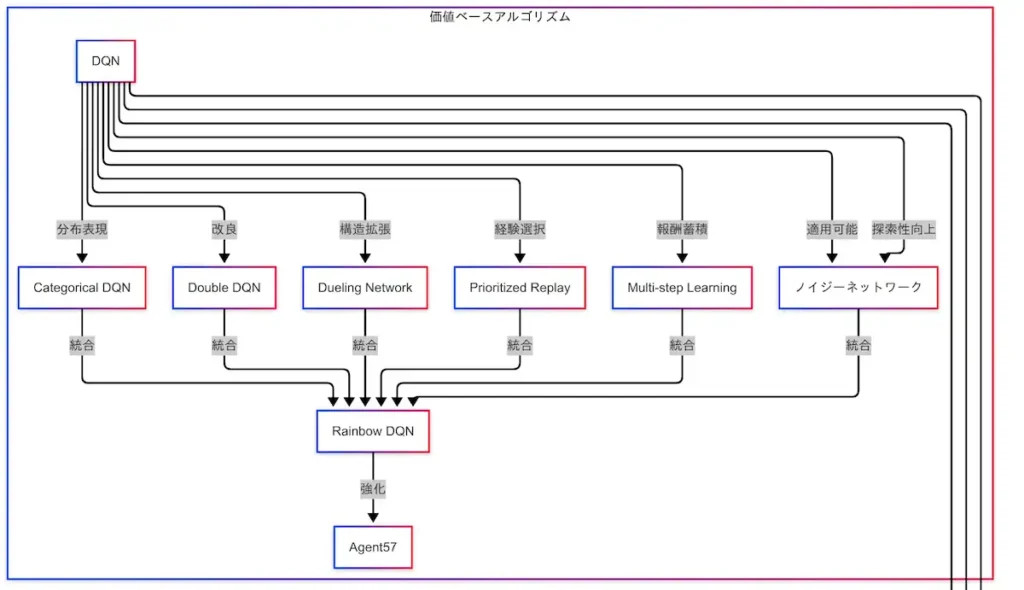
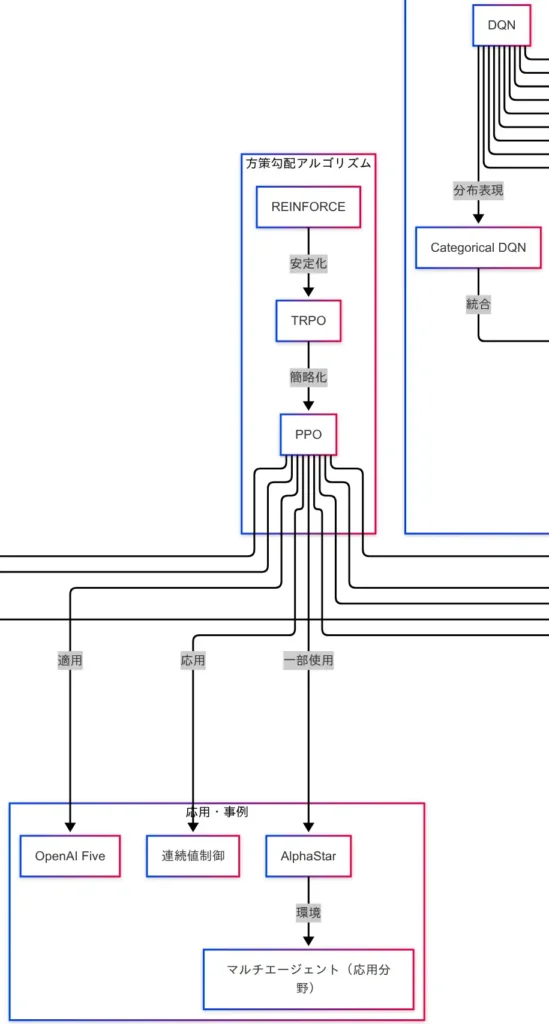
価値ベースアルゴリズムが「どの行動が得か」を推定する手法であるのに対し、方策勾配アルゴリズムは「どう行動するか」を直接学習する手法である。因果関係図においては、REINFORCEを起点として、TRPO、PPOへと進化する流れが描かれている。
まず、REINFORCEは方策勾配法の基本形であり、確率的な方策に基づいて行動を選択し、その方策を報酬に応じて更新する。価値の推定を介さず、方策そのものを最適化する点が特徴である。
次に、TRPO(Trust Region Policy Optimization)は、REINFORCEの課題である学習の不安定性を克服するために導入された。方策の更新を「信頼できる範囲(Trust Region)」に制限することで、性能の急落を防ぎ、安定した学習を実現する。ただし、TRPOは計算コストが高く、実装が複雑である。
この課題を解決するために登場したのが、PPO(Proximal Policy Optimization)である。PPOはTRPOの安定性を維持しつつ、より簡便な手法で方策の更新を行う。現在では、強化学習の実装において最も広く使われているアルゴリズムの一つである。
因果関係図では、PPOが複数の応用事例に接続されていることが確認できる。
- OpenAI Five:Dota2という複雑なゲーム環境において、PPOを用いてプロチームに勝利したAIである。
- AlphaStar:StarCraft IIにおけるAIであり、マルチエージェント環境での学習にPPOが活用されている。
- 連続値制御:ロボットの関節動作や自動運転のハンドル操作など、滑らかな制御が求められる場面において、PPOは高い適応力を示している。
このように、方策勾配アルゴリズムは、現実世界への応用に強みを持つ技術群である。因果関係図を参照することで、REINFORCEからPPOへの技術的進化と、それに伴う応用展開が明確に理解できる。G検定対策においても、方策勾配の流れを押さえておくことは重要である。
分散・統合型アルゴリズム
強化学習の実用化に向けて、学習効率とスケーラビリティを高めるために登場したのが「分散・統合型アルゴリズム」である。因果関係図では、A3CからAPE-Xへの技術的進化が一本の流れとして描かれている。
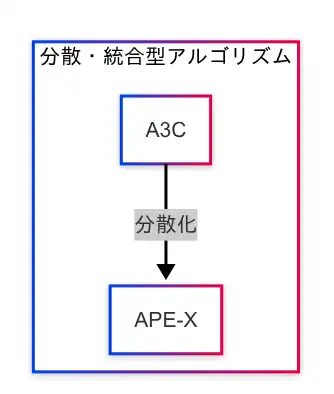
まず、A3C(Asynchronous Advantage Actor-Critic)は、複数のエージェントが非同期に並列学習を行うことで、探索の多様性と学習の安定性を両立させる手法である。各エージェントが独立して環境と相互作用し、得られた経験を共有することで、効率的な学習が可能となる。
この分散学習の考え方をさらに発展させたのが、APE-Xである。APE-Xは、経験の蓄積(リプレイバッファ)と分散処理(複数のワーカー)を組み合わせることで、大規模なデータを高速に処理し、スケーラブルな強化学習を実現する。クラウド環境やGPUを活用することで、従来の手法では困難だった大規模環境への対応が可能となる。
因果関係図における「A3C → APE-X」という接続は、分散化による性能向上の流れを示しており、強化学習の実用化に向けた重要なステップであることがわかる。
このような分散・統合型のアプローチは、単一エージェントによる学習では限界のある複雑な環境において、探索の効率化と学習の高速化を同時に達成するための鍵となる。特に、現代の強化学習では、複数のエージェントが協調して学習するマルチエージェント環境や、大量のシミュレーションを必要とするロボット制御などにおいて、分散処理の重要性が高まっている。
因果関係図を参照することで、A3CからAPE-Xへの技術的進化が明確に理解でき、分散・統合型アルゴリズムが強化学習のスケーラビリティを支える基盤技術であることが把握できる。
補助・拡張技術
強化学習の性能を引き上げるためには、アルゴリズムそのものだけでなく、それを支える補助・拡張技術の理解が不可欠である。因果関係図では、「報酬成形」「残差強化学習」「状態表現学習」「RLHF」が並列に配置されており、複数のアルゴリズムに対して適用可能な技術として示されている。
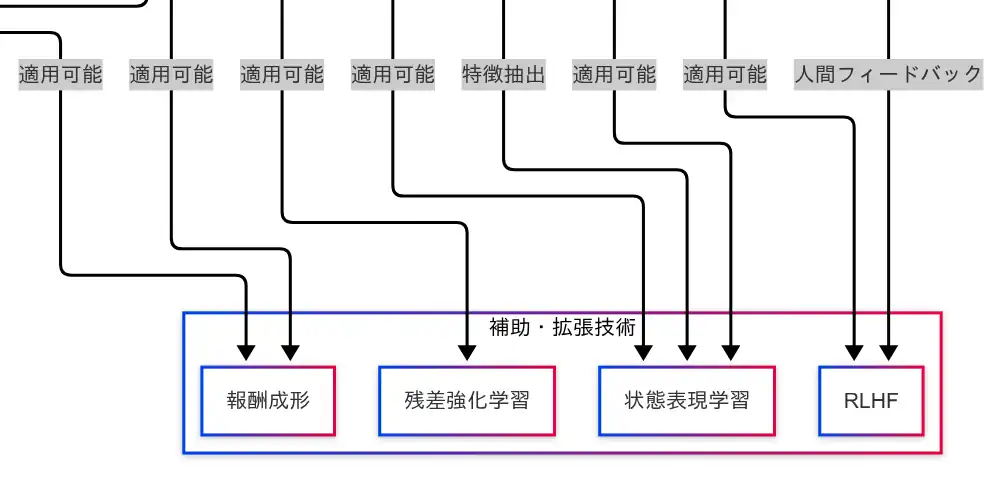
報酬成形(Reward Shaping)
報酬成形は、エージェントが学習しやすくなるように報酬の設計を工夫する技術である。たとえば、ゴールに到達したときだけ報酬を与えるのではなく、途中の行動にも段階的な報酬を与えることで、学習の安定性と効率を高めることができる。因果関係図では、DQNおよびPPOの両方に適用可能な技術として接続されており、アルゴリズムを問わず活用できる汎用性の高い補助技術である。
残差強化学習(Residual Reinforcement Learning)
残差強化学習は、既存の方策に対して差分(残差)を加えることで性能を改善する手法である。これは、すでにある程度機能する方策に対して微調整を加えることで、より高性能な方策を得ることを目的としている。因果関係図では、PPOに対して適用可能な技術として接続されている。
状態表現学習(State Representation Learning)
状態表現学習は、環境から得られる状態をそのまま使用するのではなく、特徴抽出を行い、学習に適した形式へと変換する技術である。画像データにはCNN、時系列データにはRNNやTransformerなどが用いられる。因果関係図では、DQNおよびPPOの両方に接続されており、広範なアルゴリズムにおいて活用されている。
RLHF(Reinforcement Learning with Human Feedback)
RLHFは、人間のフィードバックを活用してエージェントの方策を改善する手法である。人間が「この行動は良かった」と評価することで、エージェントはより望ましい行動を学習する。因果関係図では、エージェントから直接RLHFへと接続されており、さらにPPOとの相性が良いことも示されている。ChatGPTなどの大規模言語モデルの学習にも応用されている技術である。
これらの補助・拡張技術は、強化学習の基盤技術に対して横断的に適用可能であり、性能向上や学習安定化に寄与する。因果関係図を参照することで、各技術がどのアルゴリズムに接続されているかを視覚的に把握でき、応用の幅を理解するうえで有効である。
学習設定と環境構築
強化学習を実世界に適用するためには、学習の設定や環境の構築に関する技術が不可欠である。因果関係図では、「オフライン強化学習」「sim2real」「ドメインランダマイゼーション」がこの領域に分類されており、アルゴリズムの応用性を高めるための重要な技術群として位置づけられている。
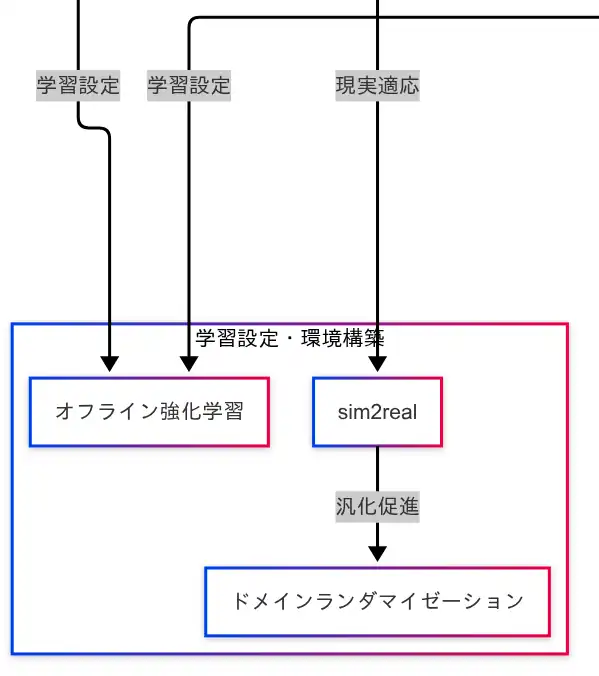
オフライン強化学習(Offline Reinforcement Learning)
オフライン強化学習は、リアルタイムで環境と相互作用することなく、過去に収集されたログデータのみを用いて学習を行う手法である。実環境での試行が困難な場合や、安全性が求められる領域において有効である。因果関係図では、DQNおよびPPOの両方に接続されており、主要なアルゴリズムに対して広く適用可能な技術であることが示されている。
sim2real(Simulation to Reality)
sim2realは、シミュレーション環境で学習したモデルを現実世界に適用する技術である。シミュレーションは安全かつ高速に学習を進めることができるが、現実との乖離が問題となる。因果関係図では、PPOからsim2realへの接続が示されており、PPOが現実世界への応用に強いことが視覚的に理解できる。
ドメインランダマイゼーション(Domain Randomization)
ドメインランダマイゼーションは、sim2realの課題である「シミュレーションと現実の差」を埋めるための技術である。シミュレーション環境の条件をランダムに変化させることで、学習されたモデルの汎化性能を高め、現実の揺らぎに強いエージェントを育成する。因果関係図では、「sim2real → ドメインランダマイゼーション」という接続があり、現実適応のための補完技術として位置づけられている。
これらの技術は、強化学習を「机上の理論」から「現場の実装」へと橋渡しする役割を果たす。因果関係図を参照することで、各技術がどのアルゴリズムに適用され、どのような目的で導入されているかを体系的に理解することができる。特に、ロボット制御や自動運転など、現実世界での応用を目指す場合には、これらの技術の理解が不可欠である。
応用事例
強化学習の技術は、理論的な枠組みにとどまらず、実際の応用においても大きな成果を挙げている。因果関係図では、「OpenAI Five」「AlphaStar」「マルチエージェント」「連続値制御」が応用事例として示されており、これらはすべてPPO(Proximal Policy Optimization)を中心とした技術の延長線上に位置づけられている。
OpenAI Five
OpenAI Fiveは、Dota2という複雑なマルチプレイヤーゲームにおいて、人間のプロチームに勝利したAIである。因果関係図では「PPO → OpenAI Five」と接続されており、PPOがこのAIの学習に用いられたことが示されている。この事例は、強化学習が戦略性・リアルタイム性・協調性を必要とする環境でも有効であることを証明している。
AlphaStar
AlphaStarは、StarCraft IIにおいて高いパフォーマンスを発揮したAIであり、複数のエージェントが同時に動作するマルチエージェント環境での学習が特徴である。因果関係図では「PPO → AlphaStar」「AlphaStar → マルチエージェント」と接続されており、PPOがマルチエージェント学習にも適用可能であることが視覚的に理解できる。
連続値制御
連続値制御は、ロボットの関節動作や自動運転のハンドル操作など、滑らかな制御が求められる現実世界の応用分野である。因果関係図では「PPO → 連続値制御」と接続されており、PPOが離散的なゲーム環境だけでなく、連続的な物理環境にも適応可能であることが示されている。
これらの応用事例は、強化学習が単なる理論ではなく、実世界の課題解決に貢献できる技術であることを示している。因果関係図を参照することで、技術と応用のつながりが明確になり、「どのアルゴリズムがどのような場面で活用されているか」を体系的に理解することが可能となる。
まとめ
本記事では、強化学習の技術体系を因果関係図に基づいて整理し、各技術のつながりと進化の流れを体系的に解説してきた。最後に、因果関係図を参照しながら、全体像を振り返る。
まず、強化学習の基本構造として、「状態」「行動」「報酬」「環境」「エージェント」が中心に配置されている。この基本ループが、すべての技術の出発点であり、強化学習の根幹を成している。ここには「状態表現学習」や「RLHF」などの補助技術が接続されており、学習の効率化や人間との協調を支えている。
次に、「価値ベースアルゴリズム」では、DQNを起点として、Double DQN、Dueling Network、Rainbow DQN、Agent57へと進化する流れが描かれている。これらはQ値の推定を通じて行動選択を最適化する技術群であり、探索性・安定性・表現力の向上が図られている。
「方策勾配アルゴリズム」では、REINFORCEから始まり、TRPO、PPOへと進化する。方策そのものを直接最適化するこの系列は、現実世界への応用に強く、OpenAI FiveやAlphaStar、連続値制御といった応用事例に接続されている。
「分散・統合型アルゴリズム」では、A3CからAPE-Xへの流れが示されており、複数のエージェントによる並列学習と分散処理によって、スケーラブルな強化学習が実現されている。
「補助・拡張技術」には、報酬成形、残差強化学習、状態表現学習、RLHFが含まれ、DQNやPPOなど複数のアルゴリズムに対して横断的に適用可能である。これらは学習の安定性や効率を高めるための重要な技術である。
「学習設定と環境構築」では、オフライン強化学習、sim2real、ドメインランダマイゼーションが、現実世界への応用を支える技術として位置づけられている。特にPPOとの接続が多く、現場での実装に強いアルゴリズムであることが図からも読み取れる。
最後に、「応用事例」として、OpenAI Five、AlphaStar、マルチエージェント、連続値制御が紹介されている。これらは、強化学習が実際に社会的・産業的な課題に対して成果を挙げていることを示すものである。
因果関係図を活用することで、強化学習の技術がどのように関連し、どのように応用されているかを視覚的かつ体系的に理解することが可能となる。単語の暗記ではなく、技術の関係性を把握することで、G検定対策にも応用しやすく、実務への応用にもつながる知識が得られる。
- 強化学習は「状態・行動・報酬・環境・エージェント」の基本構造を中心に、補助技術と連携して進化してきた。
- DQNやPPOを軸に、価値ベース・方策勾配・分散型アルゴリズムが技術的に発展し、応用事例へとつながっている。
- 因果関係図を活用することで、技術のつながりと応用先が体系的に理解でき、G検定対策にも有効である。
知識確認問題(過去問ふぅ対策道場)
10問中3問をランダムに出題。選択肢の並びもランダム。

対策道場本体はこちら

「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
バックナンバーはこちら
深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト 第3版

徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版 徹底攻略シリーズ

ディープラーニングG検定(ジェネラリスト) 法律・倫理テキスト



コメント