
GAN系モデル
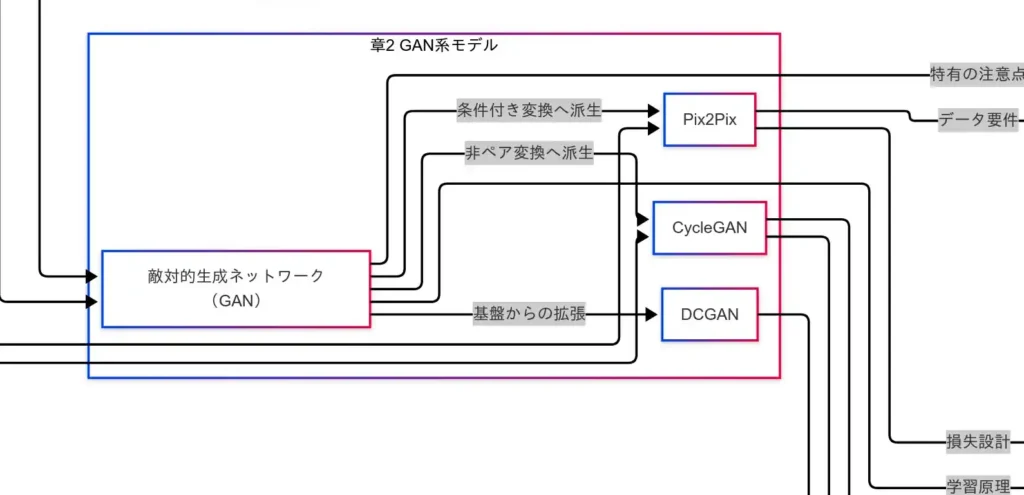
本章では、敵対的生成ネットワーク(GAN)と主要派生(DCGAN/Pix2Pix/CycleGAN)を概観し、タスク適合とデータ要件の観点で整理する。
GANの要点
GANは 生成器(Generator)と識別器(Discriminator)が競合する対立損失 で学習する枠組みである。識別器を欺くほど本物らしいサンプルを生成器が生み出すよう誘導され、学習が進むにつれて生成品質が向上する。画像を中心に、音声・動画など他モダリティにも拡張可能である。一方で、学習不安定や モード崩壊 が課題となりやすい。
DCGAN:畳み込み設計による安定化
DCGAN は畳み込みニューラルネットワーク(CNN)に基づくアーキテクチャ設計(例:全結合の削減、ストライド畳み込み、BatchNorm、活性化関数の統一方針)により、GAN学習の安定性と画像表現力を高めた系統である。自然画像生成の土台として広く参照される。
Pix2Pix:ペア画像必須の条件付き変換
Pix2Pix は入力画像を別ドメインの出力に 条件付きGAN でマッピングする手法であり、ペア画像(入力と正解の対応)が必須 である。スケッチ→写真、白黒→カラー、セマンティックマップ→街景など、対応データが用意できる現場に適する。損失設計はGAN損失に加えL1等の再構成項を併用し、忠実性を担保する。
CycleGAN:非ペアで学べるドメイン変換
CycleGAN は 非ペア データでも学習可能な画像変換である。サイクル一貫性(A→B→Aで元に戻る制約)と識別器を組み合わせ、対応の取れていないコレクション間(例:夏⇔冬、馬⇔シマウマ、写真⇔絵画)のスタイル転移を実現する。ペア収集が困難なケースで有効だが、幾何や細部忠実性の制御には工夫を要する。
使い分けの指針(タスク×データ要件)
- 高品質な新規画像生成:まずは DCGAN系 などの安定化設計を土台に、目的に応じた条件付けや正則化を検討する。
- 画像対画像変換(対応あり):Pix2Pix が第一候補。ペア品質(位置合わせ・露出差)と再構成損失の重みが成否を分ける。
- 画像対画像変換(対応なし):CycleGAN を検討。サイクル一貫性だけに頼らず、アイデンティティ損失や特徴保持の正則化で破綻を抑える。
実務メモ
- 学習安定化:学習率スケジュール、判別器優位の抑制、ラベルスムージング、データ拡張、正則化(Spectral Norm 等)が有効である。
- 多様性確保:ミニバッチ多様化、潜在コードの可視化、FID/ISによる品質と多様性の併観測が実務上の定番である。
- 倫理・法務:生成物・学習データのライセンス、肖像権・著作権、配布ポリシーの整備が前提となる。
次章では、GANとは発想がまったく異なる 拡散モデル を取り上げ、ノイズ付加と逆拡散という生成原理を整理する。
拡散モデル
拡散モデル(Diffusion Model)は、ノイズ付加と逆拡散による復元 を原理とする生成手法である。GANのように生成器と識別器を競わせるのではなく、確率的なノイズ除去を反復 してデータを生成する点が本質的な違いである。
原理:前向き拡散と逆拡散
- 前向きプロセス(拡散):元データに微小なガウスノイズを段階的に付加し、最終的に 完全なノイズ へと埋没させる過程である。
- 逆拡散プロセス(生成):ノイズ状態から段階的に ノイズを取り除き、元データ分布へと戻す過程を 学習 する。実装上は、各時刻のノイズ量(あるいは速度場/スコア)を予測するネットワークを訓練し、その予測を用いてノイズを除去する反復を行う。
この枠組みにより、モデルは「敵と戦う」のではなく「汚れを落とす」ことで高品質なサンプルを得る。直感的には、“逆再生で写真を現像する”イメージである。
代表的発展
- DDPM/DDIM 系:拡散・逆拡散の時間スケジュールや予測対象(ノイズ、$x_0$、速度)を設計し、高品質化とサンプリング高速化を両立する。
- Latent Diffusion / Stable Diffusion:画像そのものではなく 潜在空間 で拡散を行い、計算量を大幅に削減する。
- 条件付き生成:テキストやクラスラベルによる 条件付け(例:テキストエンコーダ+ガイダンス)で、プロンプト一致度を高める。
GANとの対比
- 学習安定性:識別器との競争がないため、モード崩壊が起きにくく 学習が安定しやすい。
- 計算コスト:多段の反復推論が必要で 計算量が大きい(高速化は活発に研究)。
- 画質と多様性:高解像・高忠実度の生成が得やすい一方、推論時間は長くなりがちである。
タスクへの広がり
- 画像生成:一般画像、超解像、インペインティング、スタイル変換などで高い基準を打ち立てた。
- 音声生成:波形やスペクトログラムに対して ノイズ除去型の生成 を適用し、自然な音質を得る事例が増えている。
- 条件付き画像変換:テキスト条件・画像条件・制御信号(例:エッジ、ポーズ)を用いた 精密制御 が可能である。
実務メモ
- 高速化の鍵:ステップ数削減(例:DDIM風サンプル)、潜在空間化、蒸留・一括予測。
- 制御性:テキスト条件のほか、構造ガイドを併用すると再現性が上がる。
- 評価:画質・多様性は FID/IS 等で把握しつつ、タスクに応じて人手評価を併用する(詳細は「評価指標」章)。
以上の通り、拡散モデルは ノイズを足してから賢く取り除く という発想で高画質と安定性を実現している。次章では、3D/新規視点生成を担う NeRF を取り上げる。
3D生成(NeRF)
本章では、NeRF(Neural Radiance Fields)による 3D/新規視点生成 を概観する。NeRFは、複数視点の観測から 放射輝度場 を推定し、任意視点における画像を 体積レンダリング で合成する手法である。2D画像を直接生成するGANや拡散モデルと異なり、空間そのものを再現 してから任意視点へ投影する点が本質である。
-1024x599.webp)
学習の仕組み:多視点整合と体積レンダリング
- 入力:複数視点から撮影した画像と、それぞれのカメラ姿勢(外部・内部パラメータ)である。
- 表現:3D空間の各位置に対して、密度(不透明度)と放射輝度(色)を返す連続場をニューラルネットで表現する。
- レンダリング:視点ごとに光線を空間へ射出し、線上の密度・色を積分する 体積レンダリング で画像を合成する。
- 最適化:合成画像と観測画像の誤差を最小化することで、多視点整合 を満たす放射輝度場を獲得する。
この過程により、学習後は未観測の視点からでも一貫した見えを生成できる。
データ要件
- 多視点画像:対象物やシーンを覆う十分な視差を持つ画像群が必要である。
- 正確なカメラ姿勢:外部・内部パラメータの信頼度が品質を左右する。推定誤差はゴーストやブレとして顕在化する。
- 被写体条件:大きな動きや非剛体変形が連続的に発生する場合は前処理や拡張手法を要する。
評価指標
- 再構成誤差/PSNR:レンダリング結果と実写の画素差にもとづく画質指標である。一般に PSNRが高いほど良好 であり、視点補間の忠実度を測る。必要に応じてSSIM等の構造指標も併用する。
応用
- AR/VR:任意視点のリアルタイム提示により没入感を向上させる。
- デジタルツイン/文化財保存:現実環境の写実的再現。
- 自動運転・ロボティクスのシミュレーション:環境再現に基づくセンサ模擬や経路検証。
- コンテンツ制作:フォトグラメトリ代替・補完として、背景や小物の再現に活用される。
まとめ
NeRFは「画像を作る」のではなく「空間を再現する」 アプローチであり、多視点画像+カメラ姿勢が学習の前提条件である。品質評価は 再構成誤差/PSNR を基本に据え、用途に応じて指標を追加する。次章では、テキストを生み出す 言語生成(自己回帰モデル) を取り上げる。

コメント