その他の数理的なエッセイはこちら

生成AIは「量(スピード・処理量)」と「質(判断・説明責任)」の両方に効きますが、現場では混ざります。
同じ作業でも、専門が近い人ほど量側に回しやすく、専門が遠い人ほど質側に張り付きやすいです。
出口条件(E0-E2)とチェックリストを先に決めると、「無条件導入」の議論が場合分けでき、過信と手戻りを抑えられます。
- 量と質で見える専門家の価値
- 専門家で変わる「量と質」の見え方(エンジニアと弁護士)
- 量と質は混ざる前提
- 名称の衝突回避:E0-E2(Exit)
- 無条件導入が強く聞こえる理由(E0前提)
- 出口条件E0-E2の定義
- 量寄りタスクの具体例
- 質寄りタスクの具体例
- 専門距離の採点表(0-3)
- 専門距離の実測校正:自己申告を締める仕組み
- 主要主張の定義:根拠リンク率の分母を固定する
- 提出物チェックリスト:根拠・反証・再現を必須項目にする
- E2向け証跡パッケージ:監査耐性を「提出フォルダ」まで固定する
- セキュリティ・機密の扱い:入力データ・外部送信・保持
- 量寄りタスクにもサンプリング検証を入れる
- 規範・フレームワークとの接続:過信回避を運用に落とす
- 補足:境界線を表すシグモイドモデル(読み飛ばしOK)
- 補足:Pythonで境界線の崖を眺める(読み飛ばしOK)
- FAQ
- まとめ
- 参考文献
- 協働様式(「AIとどう分業するか」を設計する)
- ガバナンス/監査耐性(出口条件=対外・監査を“運用”に落とす)
- 過信・説明責任(「質を自分のスキル以上にブーストすると詰む」を腹落ちさせる)
- 量と質の混入(“数字っぽい正しさ”で壊れる現象を掴む)
- 反証・再現・校正(専門距離0-3を“自己申告”で終わらせないために)
- 量タスクを「運用」へ(workslop対策:手戻りコストを爆発させない)
- セキュリティ/機密(入力データ・外部送信・保持を短くても強くする)
- 複雑系・連続/非線形の見立て(思考フレームを一般語に落とす)
量と質で見える専門家の価値
生成AIの議論は「AIができる/できない」に寄りがちですが、実務では次の分け方が事故を減らします。
- 量寄り:手順化できて、ある程度“回せる”仕事です。
- 質寄り:判断が効き、例外が重く、説明責任が集中する仕事です。
ここに 専門距離 が重なります。
同じ仕事でも、専門が近い人ほど「型」「例外地図」「一次情報ルート」を持っているため、一定範囲を量側に回せます。専門が遠い人ほど、同じ作業が質寄りになりやすいです。
専門家で変わる「量と質」の見え方(エンジニアと弁護士)
同じ“法的なものを扱う”でも、専門によって量・質の配分が変わります。
エンジニアが契約や法務論点に触れる場面
たとえば取引先から契約書の条項が届き、「この一文は受けてよいか」を短時間で判断しなければならない状況です。
法務が専門でない場合、条文の背景や典型的な争点の地図が薄いので、慎重に読み込むしかなく、作業は質寄りに張り付きます。量(処理件数)に寄せようとすると、見落としのコストが急に重くなります。
弁護士や法務が同じものを見る場面
一方で弁護士や法務は、定型条項や過去の失敗パターン、例外条件の勘所を持っています。
「危ない条項だけ濃く見る」「過去事例に当てる」「代替案の型を出す」といった処理ができるため、一定範囲を量側に回せます。もちろん万能ではありませんが、少なくとも“回せる領域”が広がります。
この差を無視して「契約チェックも生成AIで全部いける」とすると、専門が遠い側が過信しやすくなります。
量と質は混ざる前提
量と質は別の観点ですが、現場では混ざります。
- 量のつもりの要約が、取捨選択や言い回しで意思決定を誘導します(質が混入します)。
- 質を上げたい場面で、実はレビューや反証の回数(量)が鍵になります。
「きれいに分け切る」より、どこで質側に踏み込むかを見失わない方が安全です。
名称の衝突回避:E0-E2(Exit)
外部には、LLMエージェントの自律性(agentic behavior)を「L0-L5」のようなレベルで表す枠組みがあります。
ただし、そこでのレベルは「AIがどこまで自分で判断して動くか」という軸です(例:L0~L5でAIエージェントの発展段階を整理する研究など)。
一方、本記事で扱いたいのは 成果物の公開範囲・監査耐性(出口条件) です。意味が違うのに同じ「L0」が出ると混同されやすいので、ここでは名称を E0-E2(Exit) にします。
無条件導入が強く聞こえる理由(E0前提)
「無条件に生成AIを導入すべし!」という強い主張は、誤りというより 暗黙にE0(草稿)を想定していることがあります。
E0は「下書き」「思考整理」「未共有のメモ」が中心で、多少の誤りや曖昧さがあっても、あとで人が直せる前提で回ります。この世界では生成AIの効果が最も分かりやすく、成功体験も積み上がりやすいです。
一方、E1(内輪共有)やE2(対外・監査耐性)では、求められるのはスピードだけではなく 根拠・反証・再現 です。ここを飛ばすと「文章はあるが説明責任がない」状態になりやすく、全乗せの勢いがそのまま事故につながります。
最初から「今の話はE0/E1/E2のどれか」を揃えると、議論が場合分けされ、建設的になりやすいです。
| 前提 | 主な用途 | 生成AIの効き方 | 典型的な落とし穴 |
|---|---|---|---|
| E0(草稿) | 下書き・思考整理 | とにかく速い、試行回数が増える | そのまま共有・提出してしまう |
| E1(内輪共有) | チーム内共有・社内レビュー前 | 速さ+最低限の根拠が必要 | 「それっぽさ」で合意が進む |
| E2(対外・監査耐性) | 対外提出・監査・規制対応 | 説明責任が支配的 | 過信、反証不足、再現不能 |
出口条件E0-E2の定義
E0/E1/E2は、生成AIの使い方そのものではなく、成果物がどこまで耐える必要があるか(出口条件)の段階です。
E0(草稿)
用途:自分用の下書き、思考整理、未共有のメモ
必須:
- 「未確認」「要確認」の明示
- 重要な数値・固有名詞は一次情報で後で確認する前提
推奨:
- 致命になりそうな箇所だけ軽くサンプリング確認
E1(内輪共有)
用途:チーム内共有、社内レビュー前、意思決定の材料
必須:
- 主要主張に根拠リンクを一定割合付けます(目安50%以上)。
- 反証Qを最低3つ入れます(例外・前提崩し・否定ケース)。
- 再現手順(または追試手順)を最低1つ入れます(全部でなくてよいです)。
E2(対外・監査耐性)
用途:対外提出、監査・規制対応、責任が重い意思決定
必須:
- 主要主張の根拠リンク率80%以上(可能なら100%)
- 反証Qを最低5つ(例外、境界条件、失敗パターン、別解、前提破壊)
- 再現手順をテンプレ粒度(他者が実行できるレベル)
- 専門距離0-1の領域は、専門家の承認(レビュー記録)を必須
量寄りタスクの具体例
量寄りは「結論を決める」より、「前に進める材料を整える」で効きます。
朝イチの渋滞解消
未読のメールや依頼が積み上がっている状況で、生成AIに次をやらせます。
- 長文メールを「要点3行」と「要返信アクション」に圧縮します。
- 会議メモを「決定事項」「宿題」「期限」「担当」に整形します。
- 依頼文から「不足している入力情報」を質問として抽出します。
ここでは結論や合意を作らせず、見える化で止めます。
資料作りの下ごしらえ
提案書・報告書の初動を軽くします。
- 目的と前提から目次案を複数作ります。
- 既存メモを章ごとに再配置します。
- 「この章を書くには何が足りないか」を質問に落とします。
“完成”ではなく“材料整備”に寄せます。
仕様差分の抽出・分類
仕様書A/Bの差分を作業化します。
- 章立てをそろえます。
- 変更点を抜き出します。
- 「追加/削除/数値変更/条件変更」で分類します。
正しさの判断は後段(レビュー)に回し、まず比較可能にします。
質寄りタスクの具体例
質寄りは「突っ込まれても耐える」前提です。AIは便利ですが、過信しやすい領域でもあります。
客先レビュー前の想定問答
AIに「穴の発見」をやらせます。
- 想定質問を列挙します(前提、例外、性能、運用、保守、責任分界)。
- 致命度が高い順に並べ替えます。
- 一次情報(ログ、規格、設計根拠)に戻る必要がある質問をマークします。
答えを作るより、穴を見つけて一次情報へ戻る方が安全です。
設計のトレードオフ整理
AIに比較軸をそろえさせます。
- 候補A/B/Cのメリデメを同じ軸で整理します。
- リスクと追加確認事項を出します。
- 判断材料が不足している箇所に「追加調査」を立てます。
最終判断は人間が持ち、根拠へ戻れる形にします。
障害対応の仮説と切り分け
AIに仮説と切り分け案を出させます。
- あり得る原因候補を複数出します。
- 仮説ごとの切り分け手順(追加ログ、再現手順)を提案させます。
- 影響と可能性で優先度をつけます。
確定は検証です。もっともらしい仮説ほど、確定した気になりやすいです。
専門距離の採点表(0-3)
専門距離は「この領域を都合よく近い扱い」しないためのストッパーです。まず自己採点します。
- 0:一次情報ルート無し/失敗パターンを知らない
- 1:一次情報は辿れるが、例外地図が薄い
- 2:代表的例外・レビュー観点を列挙できる
- 3:反証手順・再現手順をテンプレ化できる
ただし自己申告だけだと甘くなりやすいので、次の「実測校正」を入れます。
専門距離の実測校正:自己申告を締める仕組み
最も危ない層が2-3を名乗れてしまう問題に対して、直近成果物で校正します。
運用コストを上げすぎないために「直近3件」で十分です。
校正の手順(直近3件)
- 対象を3件選びます(設計レビュー資料、障害報告、対外説明など)。
- 第三者(同僚・レビュー担当・専門家)が、次の指標を確認します。
- 自己申告スコアと実測スコアの 低い方 を採用します。
実測指標(軽量に回す)
- 根拠リンク率:主要主張のうち、一次情報へ戻れる参照が付いた割合です。
- 反証Qの質:反対方向の質問が「実際に痛いところ」を突けているかを第三者が判定します。
- 再現手順の完成度:他者がその手順だけで再現・追試できるかを第三者が判定します。
主要主張の定義:根拠リンク率の分母を固定する
根拠リンク率がブレないように、分母の「主要主張」を1行で固定します。
主要主張=反証されたら結論が変わる主張(結論に影響する主張) と定義します。
この定義があると、細部の説明文まで分母に入れて数字が崩れるのを防げます。
提出物チェックリスト:根拠・反証・再現を必須項目にする
「AIに結論を確定させない」だけだと運用が曖昧になります。
そこで、兆候(根拠/反証/再現)を提出物の必須項目に落とします。
設計レビュー資料(例)
- 根拠リンク
- 主要主張ごとに一次情報へ戻れる参照を付けます(ログ位置、規格節、設計根拠、計測結果など)。
- 反証Q
- 例外条件は何か
- その例外が起きたときの影響は何か
- 反対の仮説は何か(別原因・別設計)
- 前提が崩れたらどうなるか
- 既知の失敗パターンは何か
- 再現手順
- 入力(前提・条件・データ)
- 手順(操作、確認ポイント)
- 期待結果(何が再現の判定か)
- 逸脱時の分岐(失敗したら次に何を見るか)
E2向け証跡パッケージ:監査耐性を「提出フォルダ」まで固定する
E2は「ちゃんとやった」ではなく「後から追える」が重要です。
そのため、E2だけは成果物を“証跡パッケージ”としてまとめ、提出フォルダ構成まで固定すると運用が締まります。
証跡パッケージ雛形(例)
00_overview/overview.md(目的、前提、結論、意思決定、責任分界)
01_sources/sources.md(一次情報リンク一覧、参照日、版数)
02_assumptions/assumptions.md(仮定、適用範囲、除外範囲)
03_risk_register/risks.md(リスク、影響、対策、残余リスク)
04_tests_repro/repro_steps.md(再現手順、追試手順、テスト条件)test_results/(ログ、スクショ、計測結果)
05_counterevidence/counter_questions.md(反証Q、回答、未解決事項)
06_ai_usage/ai_usage.md(AI使用範囲、プロンプト方針、禁止事項、確認責任)
07_decisions/decision_log.md(判断の履歴、承認、レビュー記録)
「何をどこに置けばE2か」が決まると、E2運用の摩擦が下がり、属人性も下がります。
セキュリティ・機密の扱い:入力データ・外部送信・保持
ガバナンス系の読者が気にするのは、生成AIそのものより「入力」「送信」「保持」でしょう。
簡単に押さえてみます。
入力データ(入れてよい情報・だめな情報)
- 個人情報、認証情報、顧客の機密、未公開の設計・ソースコードなどは、原則として入力しないルールにします。
- どうしても必要な場合は、マスキング(匿名化)と承認フローを入れます。
外部送信(どこへ飛ぶか)
- 外部サービス利用時は、データが学習に使われるか、ログ保持期間、保存場所、削除手段を確認します。
- 社内のRAGやツール連携がある場合は、権限最小化と監査ログをセットにします。
保持(ログ・履歴・再利用)
- プロンプトや出力がログに残る設計なら、アクセス制御と保存期間を決めます。
- E2では、証跡として残すもの/残さないものを明確にします。
生成AIアプリ特有の論点(プロンプトインジェクション、機密漏えい、過剰な権限付与など)は、OWASPのTop 10が一覧として便利です。
https://owasp.org/www-project-top-10-for-large-language-model-applications/
(Top 10本体ページ)https://genai.owasp.org/llm-top-10/
量寄りタスクにもサンプリング検証を入れる
量寄りタスクでも、誤りが混じると手戻りコストが爆発します。
見た目が整った低品質アウトプットが流通し、受け手に修正コストが転嫁される現象は “workslop” として議論されています。
例:https://hbr.org/2025/09/ai-generated-workslop-is-destroying-productivity
サンプリング検証(仕様差分抽出の例)
- 抽出結果からランダムに一部を抜き取り、原文と突合します。
- 「数値変更」「条件変更」「否定表現」など事故りやすい箇所は重点サンプルします。
- エラーが一定以上なら、抽出手順(プロンプト、前処理、分割単位)を変えるか、レビュー比率を上げます。
規範・フレームワークとの接続:過信回避を運用に落とす
E2の話は「気をつける」では弱いので、外部の規範と接続しておくと説得力が上がります。
- EU AI Actでは、人による監督(human oversight)において、監視・解釈・介入(オーバーライド)に加え、AI出力への過信(over-reliance)への注意が論点になります。
公式本文:https://eur-lex.europa.eu/eli/reg/2024/1689/oj/eng
解説(Article 14):https://ai-act-service-desk.ec.europa.eu/en/ai-act/article-14 - リスク管理の体系としては、NIST AI RMFやISO/IEC 23894の考え方がE2(証跡パッケージ)と相性が良いです。
NIST AI RMF(PDF):https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.100-1.pdf
ISO/IEC 23894(概要):https://www.iso.org/standard/77304.html
補足:境界線を表すシグモイドモデル(読み飛ばしOK)
ここからの数式は補足です。読み飛ばしても記事は成立します。
AI介入度が上がると、ある点で急に危うくなる“崖”をロジスティック(シグモイド)で表します。
$y = \displaystyle\frac{L}{1 + e^{-k(x-x_0)}}$
- $x$:AI介入度(どれだけAIに任せるか)です。
- $y$:安全に任せられる範囲の指標(概念)です。
- $L$:上限です(無限には任せられない、という飽和です)。
- $x_0$:転機です(この付近で一気に危うくなります)。
- $k$:境界の鋭さです(大きいほど境界が“崖”になります)。
補足:Pythonで境界線の崖を眺める(読み飛ばしOK)
ここからのPythonコードは補足です。読み飛ばしても記事は成立します。
グラフは保存せず表示のみです。
横軸は AI介入度 $x$、縦軸は 安全に任せられる範囲の指標 $y$(概念) を表します。
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0, 10, 400)
L = 1.0
k = 8.0 # 境界を鋭くする(崖っぽさを強める)
# 専門が近い:転機が遅い(より後半まで安全に任せられるイメージ)
x0_expert = 6.5
y_expert = L / (1 + np.exp(-k * (x - x0_expert)))
# 専門が遠い:転機が早い(早めに壁に当たるイメージ)
x0_non_expert = 4.0
y_non_expert = L / (1 + np.exp(-k * (x - x0_non_expert)))
plt.figure()
plt.plot(x, y_expert, label="Expert (later boundary)")
plt.plot(x, y_non_expert, label="Non-expert (earlier boundary)")
plt.xlabel("AI intervention level (x)")
plt.ylabel("Safe delegation index (y, conceptual)")
plt.title("Sharp boundary by sigmoid (conceptual)")
plt.legend()
plt.grid(True)
plt.show()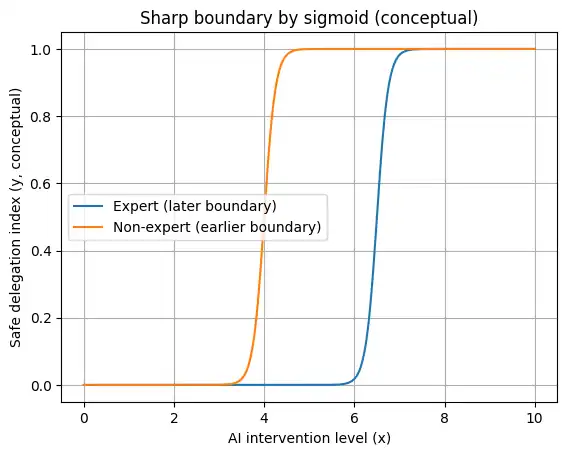
FAQ
E0-E2とは何か
成果物の出口条件(公開範囲・監査耐性)を3段階にしたものです。E0は草稿、E1は内輪共有、E2は対外・監査耐性です。
なぜL0ではなくE0なのか
外部にはAIエージェントの自律性をL0-L5で表す枠組みがあり、混同されやすいからです。本記事は成果物の出口条件なのでE(Exit)にしています。
無条件導入の主張はなぜ強く見えるのか
E0(草稿)だけを前提にすると、生成AIの効果が最も分かりやすく、失敗が表に出にくいからです。E1/E2を議論に含めると条件付きになります。
同じ作業でも専門家だと量側に回せるのはなぜか
型、例外地図、一次情報ルートがあるためです。非専門だと同じ作業が質寄りになりやすく、量側に寄せると見落としコストが急に重くなります。
根拠リンク率の分母はどう決めるのか
主要主張を「反証されたら結論が変わる主張」と定義し、それだけを分母にします。
セキュリティで最低限押さえる論点は何か
入力データ(何を入れてよいか)、外部送信(どこへ飛ぶか)、保持(ログ・履歴をどう扱うか)です。LLM特有の脅威一覧はOWASP Top 10が便利です。
まとめ
E0前提の成功体験だけで「無条件導入」を語ると、E1/E2で事故が起きやすくなります。
専門距離は自己申告で終わらせず、直近成果物で実測校正すると制度として締まります。
E2では証跡パッケージとセキュリティ論点まで固定すると、監査耐性が運用に落ちます。
- 出口条件(E0/E1/E2)を最初に合意する
- 専門距離(0-3)+実測校正で過信を抑える
- 証跡パッケージ+セキュリティ論点でE2を運用可能にする
参考文献
- Regulation (EU) 2024/1689 (Artificial Intelligence Act)(EUR-Lex)
https://eur-lex.europa.eu/eli/reg/2024/1689/oj/eng - AI Act Service Desk – Article 14: Human oversight(European Commission)
https://ai-act-service-desk.ec.europa.eu/en/ai-act/article-14 - Artificial Intelligence Risk Management Framework (AI RMF 1.0)(NIST PDF)
https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.100-1.pdf - ISO/IEC 23894:2023 – AI – Guidance on risk management(ISO)
https://www.iso.org/standard/77304.html - OWASP Top 10 for Large Language Model Applications(OWASP Foundation)
https://owasp.org/www-project-top-10-for-large-language-model-applications/
https://genai.owasp.org/llm-top-10/ - The Three Ways Professionals Work with AI – Which One Are You?(Harvard D^3)
https://d3.harvard.edu/the-three-ways-professionals-work-with-ai-which-one-are-you/ - Cyborgs, Centaurs and Self-Automators: The Three Modes of Human-GenAI Knowledge Work(Harvard Business School Working Paper PDF)
https://www.hbs.edu/ris/Publication%20Files/26-036_e7d0e59a-904c-49f1-b610-56eb2bdfe6f9.pdf - Levels of AI Agents: from Rules to Large Language Models(arXiv)
https://arxiv.org/abs/2405.06643 - A Survey of Data Agents: Emerging Paradigm or Overstated Vision?(arXiv)
https://arxiv.org/html/2510.23587v1 - AI-Generated “Workslop” Is Destroying Productivity(Harvard Business Review)
https://hbr.org/2025/09/ai-generated-workslop-is-destroying-productivity
その他の数理的なエッセイはこちら
協働様式(「AIとどう分業するか」を設計する)
『これからのAI、正しい付き合い方と使い方 「共同知能」と共生するためのヒント』(イーサン・モリック/KADOKAWA)

AIを「全自動の魔法」ではなく「チームメンバー」として扱う前提を整えるのに向きます。
ガバナンス/監査耐性(出口条件=対外・監査を“運用”に落とす)
『AIガバナンス入門 ―リスクマネジメントから社会設計まで―』(羽深宏樹/早川書房)

ルールや社会実装の観点で「どこまでAIブーストしてよいか」を整理しやすいです。
『生成AI法務・ガバナンス 未来を形作る規範』(中崎 尚/商事法務)

生成AIの実務論点(組織体制・倫理・情報・国外動向)まで踏み込む“重装備”側。
過信・説明責任(「質を自分のスキル以上にブーストすると詰む」を腹落ちさせる)
『オートメーション・バカ ―先端技術がわたしたちにしていること―』(ニコラス・G・カー/青土社)

自動化が進むほど、非常時の判断力が弱る構造を押さえられます。
『ファスト&スロー』上・下(ダニエル・カーネマン/早川書房)

“速い思考/遅い思考”のズレ=過信の土台を理解しやすい定番です。
『NOISE(ノイズ) ―組織はなぜ判断を誤るのか?―』上・下(カーネマンほか/早川書房)

専門家判断の「ばらつき(ノイズ)」を減らす発想が、レビュー観点・反証手順と相性が良いです。
量と質の混入(“数字っぽい正しさ”で壊れる現象を掴む)
『測りすぎ ―なぜパフォーマンス評価は失敗するのか?―』(ジェリー・Z・ミュラー/みすず書房)

“測定できる=測定すべき”の罠。量寄りタスクでも品質が崩れる理由を言語化できます。
『あなたを支配し、社会を破壊する、AI・ビッグデータの罠』(キャシー・オニール/インターシフト)

モデルが社会に入った瞬間に、量/質が混ざって暴れる例が豊富です。
反証・再現・校正(専門距離0-3を“自己申告”で終わらせないために)
『超予測力 ―不確実な時代の先を読む10カ条―』(テトロック&ガードナー/早川書房)

反証・更新・確率での見立てなど、ループ運用の土台になります。
『統計学が最強の学問である』(西内啓/ダイヤモンド社)

サンプリング検証・再現性・「雑に量を回して壊す」を避ける基礎体力に。
『失敗の本質』(戸部良一ほか/ダイヤモンド社)

失敗パターン(例外地図)を“組織の癖”として捉える視点が増えます。
量タスクを「運用」へ(workslop対策:手戻りコストを爆発させない)
『機械学習システムデザイン』(Chip Huyen/オライリー・ジャパン)

仕様・評価・運用の接続が主題で、量寄りタスクの品質管理に向きます。
『MLOps実装ガイド ―本番運用を見据えた開発戦略―』(Haviv & Gift/オライリー・ジャパン)

“継続運用”を前提にした監視・更新・ガバナンスまで扱うので、量の暴走防止に効きます。
セキュリティ/機密(入力データ・外部送信・保持を短くても強くする)
『セキュアなソフトウェアの設計と開発:脅威モデリングに基づくアプローチ』(ローレン・コンフェルダー/秀和システム)

STRIDE系の発想で「何が壊れうるか」を先に描けます。
『セキュア・バイ・デザイン ―安全なソフトウェア設計―』(マイナビ出版)

設計原則としてセキュリティを入れる系。仕組み化に寄ります。
『体系的に学ぶ 安全なWebアプリケーションの作り方』(SBクリエイティブ)

“典型的なやらかし”の地図が厚くなり、専門距離の自己採点が甘くなりにくいです。
複雑系・連続/非線形の見立て(思考フレームを一般語に落とす)
『世界はシステムで動く――いま起きていることの本質をつかむ方法』(ドネラ・H・メドウズ/英治出版)

つながり、フィードバック、成長と飽和など「線や面」で語る土台になります。

コメント