
その他のエッセイはこちら

Windows 11 の CPU only 環境でも、Ollama を使ったローカルLLM基盤そのものは問題なく作れました。
ただし、CPU only の小型 qwen2.5-coder と今回の設定では、コード生成から修正完走までを安定して任せるのはまだ厳しい結果でした。
実務で見えてきた主役は LLM 単体よりも、Continue や Aider のようにファイル反映、コマンド実行、結果回収まで担う AIコードアシスタント側でした。
- 検証の結論
- 検証環境
- 構成図
- 処理の流れ
- 実際に使ったコマンド
- qwen2.5-coder 1.5B、3B、7B の見え方
- Qwen2.5 側の代表的な失敗例
- Continue で分かったこと
- Aider で分かったこと
- Continue と Aider で差が出た理由
- 今回ビルドとテストまで通った最小サンプル
- OpenAI API は補足比較
- GPT-5.4 と GPT-5.3-Codex で起きたこと
- Codex と Claude Code を今回の主題から外した理由
- FAQ
- 参考文献
- まとめ
- LLMとローカルLLMの全体像をつかむ本
- AIエージェント / AIコードアシスタントの設計に効く本
- Cの実装品質を上げる本
- テスト、品質、継続実行を整える本
- 迷ったらこの3冊
検証の結論
今回の検証でまず確認できたのは、Windows 11 の CPU only 環境でも、Ollama を使ったローカルLLM基盤そのものは問題なく作れるという点です。Ollama は Windows ネイティブアプリとして動作し、cmd、PowerShell、各種ターミナルから ollama コマンドを利用できます。ローカル API も http://localhost:11434 で利用できます。(Ollama for Windows、Ollama Quickstart)。
一方で、今回のローカル qwen2.5-coder 検証は、実務レベルの自動化としては厳しさが残りました。特に CPU only 環境での小型 qwen2.5-coder と今回の設定では、コード生成からファイル反映、ビルド修正完走までを安定して進めるところまでは届きませんでした。
ただし、これは Continue や Aider 自体の一般的な限界をそのまま示すものではありません。Continue の Agent Mode は、モデル固有の native tool calling に全面依存せず、モデルの能力に応じて native tools と system message tools を自動で使い分ける設計です。Agent Mode では create_new_file、edit_existing_file、run_terminal_command などのツールも扱えます。今回の結果は、あくまで CPU only の小型ローカルモデルと今回の構成条件における到達点として読むのが適切です。(How Agent Mode Works | Continue Docs、Model Setup for Agent Mode | Continue Docs、Quick Start | Continue Docs)。
補足比較として OpenAI API をつないだ場合、今回の環境では Continue では GPT-4.1 が扱いやすく、Aider では GPT-4.1 と GPT-5.4 の双方でビルドとテスト実行まで進められました。したがって、見えてきた差は単純なモデルの優劣というより、AIコードアシスタント側がモデル、ツール、コマンド実行をどう統合しているかの差として捉える方が自然です。GPT-4.1 は OpenAI 公式でも instruction following と tool calling に強い non-reasoning model とされる一方、複雑タスクでは GPT-5 系から試すことも推奨されています。(GPT-4.1 Model | OpenAI API、Models | OpenAI API)。
検証環境
今回の構成は次のとおりです。
- OS
- Windows 11
- ローカルLLM
- Ollama
- qwen2.5-coder:1.5b
- qwen2.5-coder:3b
- qwen2.5-coder:7b
- AIコードアシスタント
- VS Code
- Continue
- Aider
- 補足比較
- OpenAI API
- GPT-4.1
- GPT-5.4
- GPT-5.3-Codex も一部確認
- 検証条件
- CPU only
- Continue はローカル qwen2.5-coder と OpenAI API を比較
- Aider はローカル qwen2.5-coder に加え、GPT-4.1 / GPT-5.4 でも確認
- Aider ではユーザー側で Ollama の追加パラメータを明示設定せず、標準の使い方で確認
Ollama は Windows 上で常駐し、CLI とローカル API を提供します。Continue は複数 provider を切り替えられ、Ollama と OpenAI の両方を扱えます。Aider も Ollama と OpenAI の両方を公式にサポートしています。(Ollama for Windows、Model Providers Overview | Continue Docs、Ollama | aider、OpenAI | aider)。
構成図
今回の検証構成は、AIコードアシスタントを中心に、プロジェクト作業領域、ビルド環境、モデル接続先がぶら下がる形で整理すると分かりやすくなります。
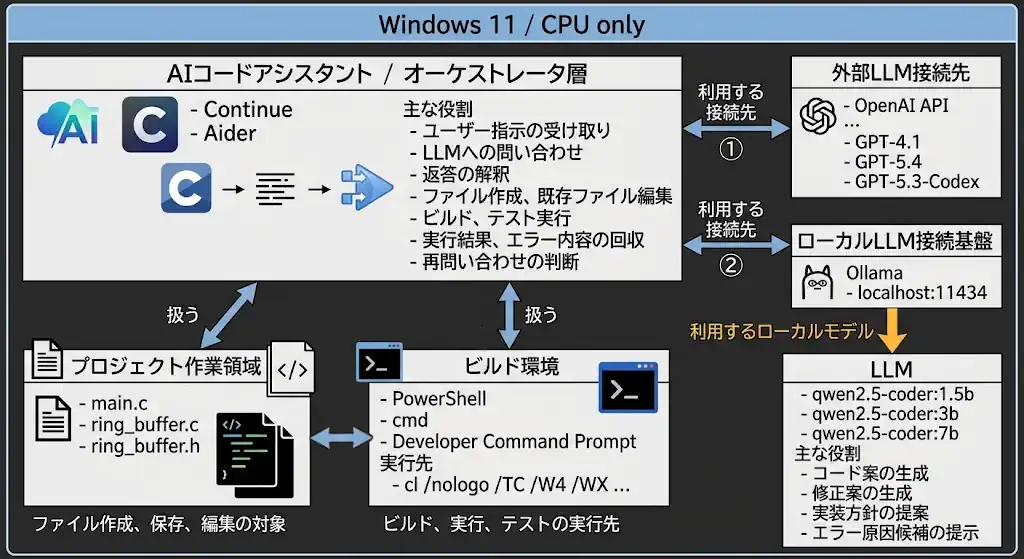
この図で重要なのは、LLM とプロジェクト作業領域、LLM とビルド環境を直接つながないことです。コード案や修正案を返すのは LLM ですが、実際にファイルへ反映し、ビルド環境でコマンドを実行し、結果を回収して次の手順につなげる主体は Continue や Aider のような AIコードアシスタント側です。Continue の Agent Mode は tool calls と応答ループを内包したエージェント統合が濃く、Aider は /run、/test、--test-cmd、--auto-test など外部コマンド実行の枠を持っています。今回の比較では、この統合方式の違いが到達点の差として表れました。(How Agent Mode Works | Continue Docs、In-chat commands – aider、Linting and testing – aider)。
処理の流れ
- ユーザーが Continue または Aider に実装指示を出す
- AIコードアシスタントが必要な文脈を整理して LLM に問い合わせる
- LLM がコード案、修正案、実装方針を返す
- AIコードアシスタントが返答をもとにファイルを作成または編集する
- AIコードアシスタントがビルド環境でコンパイルやテストを実行する
- AIコードアシスタントが結果やエラー内容を取得する
- 必要に応じて AIコードアシスタントが LLM へ再問い合わせし、修正を続ける
実際に使ったコマンド
Ollama の導入後に使った基本コマンド
ollama pull qwen2.5-coder:1.5b
ollama pull qwen2.5-coder:3b
ollama pull qwen2.5-coder:7bollama list
ollama run qwen2.5-coder:1.5bOllama の Windows ドキュメントでは、導入後に ollama コマンドが PowerShell などから使えること、API が http://localhost:11434 で提供されることが案内されています。(Ollama for Windows)。
PowerShell からローカル API を呼ぶ例
$body = @{
model = "qwen2.5-coder:1.5b"
prompt = "hello"
stream = $false
} | ConvertTo-Json -Compress
Invoke-RestMethod `
-Uri "http://localhost:11434/api/generate" `
-Method Post `
-ContentType "application/json" `
-Body $bodyOllama の Windows ドキュメントにも、PowerShell から API を呼ぶ例があります。(Ollama for Windows)。
Continue の設定例
ローカル qwen2.5-coder を Continue で使う設定例です。
name: Local Ollama
version: 0.0.1
schema: v1
models:
- name: qwen-coder-3b
provider: ollama
model: qwen2.5-coder:3b
apiBase: http://localhost:11434
- name: qwen-coder-7b
provider: ollama
model: qwen2.5-coder:7b
apiBase: http://localhost:11434OpenAI API を使う設定例です。
name: OpenAI Config
version: 0.0.1
schema: v1
models:
- name: continue-main
provider: openai
model: gpt-4.1
apiKey: <YOUR_OPENAI_API_KEY>Continue は provider を差し替える構成を前提にしていて、Ollama と OpenAI の両方を扱えます。(Model Providers Overview | Continue Docs、config.yaml Reference | Continue Docs)。
Aider の起動例
Ollama を使う例です。
python -m pip install aider-install
aider-install
setx OLLAMA_API_BASE http://127.0.0.1:11434aider --model ollama_chat/qwen2.5-coder:3b ring_buffer.h ring_buffer.cOpenAI API を使う例です。
setx OPENAI_API_KEY <YOUR_OPENAI_API_KEY>aider --model gpt-4.1 ring_buffer.h ring_buffer.cAider は Ollama と OpenAI の両方を公式にサポートし、Ollama では ollama_chat/ の利用が案内されています。(Ollama | aider、OpenAI | aider)。
Aider でビルドとテスト実行を渡す例
今回の環境では、Aider にテストコマンドを明示すると、GPT-4.1 と GPT-5.4 の双方でビルドとテスト実行まで進められました。Aider には /test、--test-cmd、--auto-test があり、テストコマンドが非 0 を返したときはその出力をもとに修正へ進められます。(Linting and testing – aider、Options reference | aider)。
@echo off
cl /nologo /TC /W4 /WX main.c ring_buffer.c
if errorlevel 1 exit /b %errorlevel%
main.exe
exit /b %errorlevel%aider --model gpt-4.1 --test-cmd "test_ring_buffer.bat" --auto-test ring_buffer.h ring_buffer.c main.caider --model gpt-5.4 --test-cmd "test_ring_buffer.bat" --auto-test ring_buffer.h ring_buffer.c main.cqwen2.5-coder 1.5B、3B、7B の見え方
Ollama Library では、qwen2.5-coder は 0.5B、1.5B、3B、7B、14B、32B が公開されていて、1.5B は 986MB、3B は 1.9GB、7B は 4.7GB と掲載されています。モデル説明では、code generation、code reasoning、code fixing の改善がうたわれています。(qwen2.5-coder | Ollama Library)。
今回の検証での見え方は次のとおりです。
- 1.5B
- 疎通確認向け
- 応答は軽い
- Chat でのコード生成はかなり不完全
- 3B
- 1.5B よりは改善
- 条件を細かく書くと、たたき台としては使える
- 仕様違反やコンパイル不能コードはまだ出る
- 7B
- 3B より理解はやや改善
- CPU only では待ち時間がかなり重い
- 完成度の高いコード生成や自動修正が安定するとは言いにくい
今回の前提では、1.5B は導入確認用、3B は試作用、7B は比較評価用という位置づけでした。
Qwen2.5 側の代表的な失敗例
今回の検証では、失敗の傾向がかなり分かりやすく出ました。ここでは代表例を載せます。
失敗例1: リングバッファを依頼したのに、スタック説明へ流れる
短い依頼文で ring buffer 実装を求めると、スタックの説明に流れたり、Python の例を返したりしました。実際には次のような出力がありました。
In programming, particularly in data structures like stacks (or queues), you often need to define certain operations for managing the stack's behavior.
Here's a simple implementation of these operations in Python:このタイプの失敗は 1.5B と 3B で目立ちました。依頼内容は C 言語のリングバッファなのに、データ構造そのものを取り違え、言語も Python や C++ に流れる場面がありました。
失敗例2: Cコードらしく見えるが、コンパイルできない
7B では、それらしい C コードが返る場面もありましたが、実際にはコンパイル不能なコードが混ざりました。代表例はこれです。
bool push(RingBuffer *rb, uint8_t data) {
if (rb->is_full(rb)) return false;
rb->buffer[rb->head] = data;
rb->head = (rb->head + 1) % rb->capacity;
if (rb->head == rb->tail) rb->is_circular = true;
return true;
}この例では rb->is_full(rb) という呼び出しになっていますが、構造体に is_full 関数ポインタは定義されていません。そのため、そのままではコンパイルできません。is_circular の扱いも不十分で、一見まともに見えても実際には破綻しています。
失敗例3: Aider ではファイル生成までは進むが、ローカル qwen2.5-coder では完走性が不安定
Aider は Continue より一歩先まで進みました。ローカル qwen2.5-coder でもファイル生成まではできましたが、include 漏れ、宣言と定義の不一致、戻り値設計の不整合が残り、最後は手でコードを差し替える場面がありました。つまり、ローカル qwen2.5-coder では「雛形生成」は可能でも、「コンパイルエラーを最後まで自律的に解消する」段階までは安定しませんでした。
Continue で分かったこと
Continue は Chat 自体は問題なく動きました。ローカル qwen2.5-coder を設定して、コード生成の会話までは進められました。Continue は model provider の差し替えを前提にしていて、Ollama と OpenAI の両方を扱えます。(Model Providers Overview | Continue Docs)。
また、Continue の Agent Mode は、モデル固有の native tool calling に全面依存する構造ではありません。公式ドキュメントでは、tools をリクエストへ含めて送信し、tool calls と responses を扱う仕組みと、モデル能力に応じて native tools と system message tools を自動で切り替える考え方が説明されています。Agent Mode では create_new_file、edit_existing_file、run_terminal_command などの built-in tools も扱えます。(How Agent Mode Works | Continue Docs、Model Setup for Agent Mode | Continue Docs)。
そのうえで今回のローカル qwen2.5-coder 環境では、Agent 実行の完走性は十分ではありませんでした。create_new_file や run_terminal_command 相当の出力は見えましたが、実ファイル作成やコマンド実行まで安定して進まない場面がありました。
したがって、今回の評価は「Continue が難しい」ではなく、「CPU only の小型 qwen2.5-coder と今回の設定では、Continue の Agent 実行を実用レベルで完走させるのは厳しかった」と書く方が正確です。さらに Continue Docs では、Chat / Edit の推奨 open model として Qwen3 Coder 480B / 30B が挙げられていて、best overall chat experience には 400B+ パラメータ級か frontier models が望ましいと案内されています。今回使った 1.5B / 3B / 7B は、その推奨帯から見るとかなり小さい部類です。(Recommended Models for Chat in Continue)。
Aider で分かったこと
Aider はローカル qwen2.5-coder を使って、ファイル生成までは進められました。加えて今回の環境では、ビルドとテスト用コマンドを与えた構成では、GPT-4.1 と GPT-5.4 の双方でビルドとテスト実行まで進められました。Aider は Ollama と OpenAI の両方を公式にサポートし、CLI ベースでコード編集や実行補助を回せます。(Ollama | aider、OpenAI | aider、Linting and testing – aider)。
一方で、ローカル qwen2.5-coder だけで完走性を見た場合は、include 漏れや宣言・定義の不一致が残ることがあり、自律修正の安定性は十分ではありませんでした。Aider の公式ドキュメントでも、能力の低いモデルでは code edits をうまく返せず、ファイル編集やコミットがうまくいかないことがあると案内されています。(Connecting to LLMs | aider)。
なお、Aider の評価はコンテキスト長条件の影響を受けやすい点に注意が必要です。Aider の Ollama ドキュメントでは ollama_chat/ の利用が推奨されており、Ollama のデフォルト 2k context は小さすぎて、超過分を静かに捨てるので危険だと説明されています。同じページでは、Aider は既定で各リクエストに必要な長さに加えて返信用 8k を見込むよう context window を設定すると案内されています。今回の記事では、ユーザー側で Ollama の追加パラメータを明示設定せず、Aider の標準的な使い方の範囲で確認しました。(Ollama | aider)。
Continue と Aider で差が出た理由
今回の検証では、GPT-5.4 は Continue では reasoning item 関連のエラーに当たった一方で、Aider では GPT-4.1 と GPT-5.4 の双方でビルドとテスト実行まで到達しました。この結果から見ると、今回の差は単純なモデル性能差というより、AIコードアシスタント側の統合方式の違いとして捉える方が自然です。
Continue の Agent Mode は、モデルへのリクエストに tools を含め、tool calls とその応答を扱うインターフェースを持っています。さらに、モデルに応じて native tools と system message tools を自動で切り替える設計です。そのため、モデルとツールの間にある会話状態管理の影響を受けやすい構造です。(How Agent Mode Works | Continue Docs、Model Setup for Agent Mode | Continue Docs)。
一方の Aider は、/run、/test、--test-cmd、--auto-test などで外部コマンド実行を扱いやすく、ビルドやテストはモデルの内部能力というより、外部コマンド実行の結果を chat に戻して修正へつなげる流れになります。今回の環境で GPT-5.4 が Aider では動作したのは、この外部コマンド主体の構造と相性がよかった可能性があります。(In-chat commands – aider、Linting and testing – aider)。
今回の結果を見ると、Aider はツール呼び出しを LLM に全面的に委ねるというより、ユーザーが与えた /test や --test-cmd のような実行枠の中でモデルを使う構造に近いと考えられます。一方の Continue は、モデルが tool call を返し、その結果を再びモデルへ戻すエージェント統合がより濃いため、reasoning を持つモデルでは会話状態管理の影響が表面化しやすい可能性があります。(How Agent Mode Works | Continue Docs、Linting and testing – aider)。
今回ビルドとテストまで通った最小サンプル
今回の検証では、最終的にビルドとテストまで通ったリングバッファ実装が作れました。ここでは、外部バッファを初期化時に渡す形のサンプルを載せます。
ring_buffer.h
#ifndef RING_BUFFER_H
#define RING_BUFFER_H
#include <stddef.h>
#include <stdint.h>
typedef struct {
uint8_t *buffer;
size_t capacity;
size_t head;
size_t tail;
size_t count;
} ring_buffer_t;
void ring_buffer_init(ring_buffer_t *rb, uint8_t *buf, size_t capacity);
int ring_buffer_push(ring_buffer_t *rb, uint8_t value);
int ring_buffer_pop(ring_buffer_t *rb, uint8_t *value);
size_t ring_buffer_size(const ring_buffer_t *rb);
size_t ring_buffer_capacity(const ring_buffer_t *rb);
int ring_buffer_is_empty(const ring_buffer_t *rb);
int ring_buffer_is_full(const ring_buffer_t *rb);
#endifring_buffer.c
#include "ring_buffer.h"
void ring_buffer_init(ring_buffer_t *rb, uint8_t *buf, size_t capacity) {
rb->buffer = buf;
rb->capacity = capacity;
rb->head = 0;
rb->tail = 0;
rb->count = 0;
}
int ring_buffer_push(ring_buffer_t *rb, uint8_t value) {
if (rb->count == rb->capacity) {
return 0;
}
rb->buffer[rb->head] = value;
rb->head = (rb->head + 1) % rb->capacity;
rb->count++;
return 1;
}
int ring_buffer_pop(ring_buffer_t *rb, uint8_t *value) {
if (rb->count == 0) {
return 0;
}
*value = rb->buffer[rb->tail];
rb->tail = (rb->tail + 1) % rb->capacity;
rb->count--;
return 1;
}
size_t ring_buffer_size(const ring_buffer_t *rb) {
return rb->count;
}
size_t ring_buffer_capacity(const ring_buffer_t *rb) {
return rb->capacity;
}
int ring_buffer_is_empty(const ring_buffer_t *rb) {
return rb->count == 0;
}
int ring_buffer_is_full(const ring_buffer_t *rb) {
return rb->count == rb->capacity;
}main.c
#include <stdio.h>
#include <stdint.h>
#include "ring_buffer.h"
int main(void) {
uint8_t buf[4];
ring_buffer_t rb;
ring_buffer_init(&rb, buf, 4);
printf("== Ring Buffer Test ==\n");
if (!ring_buffer_is_empty(&rb)) {
printf("NG: initial empty\n");
return 1;
}
if (ring_buffer_is_full(&rb)) {
printf("NG: initial full\n");
return 1;
}
if (!ring_buffer_push(&rb, 0x11)) {
printf("NG: push 0x11\n");
return 1;
}
ring_buffer_push(&rb, 0x22);
ring_buffer_push(&rb, 0x33);
ring_buffer_push(&rb, 0x44);
if (!ring_buffer_is_full(&rb)) {
printf("NG: full check\n");
return 1;
}
{
uint8_t v;
if (!ring_buffer_pop(&rb, &v) || v != 0x11) return 1;
if (!ring_buffer_pop(&rb, &v) || v != 0x22) return 1;
if (!ring_buffer_pop(&rb, &v) || v != 0x33) return 1;
if (!ring_buffer_pop(&rb, &v) || v != 0x44) return 1;
}
if (!ring_buffer_is_empty(&rb)) {
printf("NG: final empty\n");
return 1;
}
printf("OK\n");
return 0;
}ビルドコマンド
VS2017 の Developer Command Prompt を前提に、次でコンパイルできます。
cl /nologo /TC /W4 /WX main.c ring_buffer.cOpenAI API は補足比較
今回の記事の主役はローカルLLMです。OpenAI API は主構成ではなく、比較対象としての位置づけです。
ただし、比較としてはかなり有効でした。今回の環境では、Continue では GPT-4.1 が扱いやすく、Aider では GPT-4.1 と GPT-5.4 の双方でビルドとテスト実行まで到達しました。GPT-4.1 は OpenAI 公式でも instruction following と tool calling に強い non-reasoning model とされていて、今回のような IDE / エージェント統合では扱いやすさが出やすい条件でした。(GPT-4.1 Model | OpenAI API)。
したがって、記事としての位置づけは次のとおりです。
- 主役
- Ollama
- qwen2.5-coder
- Continue / Aider のローカル検証
- 補足比較
- OpenAI API
- GPT-4.1
- GPT-5.4
- GPT-5.3-Codex
GPT-5.4 と GPT-5.3-Codex で起きたこと
補足確認として GPT-5.4 に加え GPT-5.3-Codex も試しましたが、Continue 側では同系統のエラーに当たりました。この結果から見ると、今回の問題は単純なモデル性能差というより、reasoning を持つ coding / reasoning 系モデルを Continue 側でどう会話状態付きで扱うか、という統合条件の影響が大きい可能性があります。
OpenAI の現行ドキュメントでは、GPT-5.4 は複雑な reasoning と coding 向けの旗艦モデルで、GPT-5.3-Codex の後継に位置づけられています。また GPT-5.3-Codex は agentic coding tasks in Codex or similar environments 向けに最適化されたモデルで、reasoning effort を持ちます。つまり、どちらも reasoning を含む系統です。(Using GPT-5.4 | OpenAI API、GPT-5.3-Codex Model | OpenAI API)。
また OpenAI の reasoning models ガイドでは、function calling を伴う multi-turn では previous_response_id などを使って reasoning items を適切に引き継ぐことが重要だと案内されています。今回の Continue + GPT-5.4 / GPT-5.3-Codex の失敗は、「GPT-5.4 や GPT-5.3-Codex が GPT-4.1 より弱い」という話ではありません。今回の統合条件では、non-reasoning 系の GPT-4.1 の方が扱いやすく、reasoning を持つモデルでは会話状態管理の影響がより強く出た、と整理する方が公平です。(Reasoning models | OpenAI API)。
Codex と Claude Code を今回の主題から外した理由
今回の検証では、Codex や Claude Code は主役に置いていません。理由は、これらのツールの性能が低いからではありません。Codex CLI には approval や sandbox を含む実行制御の考え方があり、Claude Code も settings や hooks を持っています。つまり、制御機構そのものはあります。(CLI – Codex | OpenAI Developers、Features – Codex CLI | OpenAI Developers、Claude Code settings、Hooks reference – Claude Code Docs)。 ([docs.continue.dev][10])
今回重視したのは、コード生成性能だけではなく、工程ごとの通過条件を外側で扱いやすいかどうかでした。たとえば、UT が終わっていない成果物は IT に進めない、UT / IT の両方が終わっていない成果物はデプロイしない、といったフェーズ間コントロールです。
昨今のコード生成ツールは、読み取り、編集、ビルド、テスト実行までかなり広く扱えます。だからこそ今後は、「何ができるか」だけではなく、「どの工程を通った成果物だけを次工程へ渡すか」を、モデルの外側でルールベースに管理しやすい構造が重要になる可能性があります。この観点では、モデル、プロンプト、ツール、実行手順を分けて考えやすい Continue と Aider の方が、今回の比較対象として扱いやすい構成でした。
FAQ
Q1. Windows 11 の CPU only でもローカルLLMは動きますか
はい、動きます。Ollama は Windows ネイティブで動作し、ローカル API も提供します。CLI と API の両方で応答を確認できます。(Ollama for Windows)。
Q2. qwen2.5-coder は 1.5B、3B、7B のどれから試すべきですか
最初は 1.5B で疎通確認、その次に 3B で試作、7B は比較評価用が現実的です。Ollama Library 上の公開サイズは 1.5B が 986MB、3B が 1.9GB、7B が 4.7GB です。CPU only では 7B の待ち時間がかなり重くなりやすいです。(qwen2.5-coder | Ollama Library)。
Q3. Continue はローカル qwen2.5-coder だけで実用になりますか
Chat での補助用途には使えます。ただし今回の検証では、CPU only の小型 qwen2.5-coder と今回の設定では Agent によるファイル生成やツール実行を安定して完走できませんでした。Continue 自体は system message tools を含む形で幅広いモデルに対応する設計なので、今回の結果は組み合わせ条件に強く依存するものとして読むのが適切です。(How Agent Mode Works | Continue Docs、Model Setup for Agent Mode | Continue Docs)。
Q4. Aider はローカル qwen2.5-coder で使えますか
使えます。今回の検証でもファイル生成までは進められました。ただし、ローカル qwen2.5-coder だけで見た場合、自動修正完走の安定性は十分ではありませんでした。なお、Aider 自体には /test、--test-cmd、--auto-test などの実行支援機能があり、今回の環境では GPT-4.1 と GPT-5.4 の双方でビルドとテスト実行まで進められました。(Linting and testing – aider、Connecting to LLMs | aider)。
Q5. qwen3 系は試すべきですか
性能面では有力ですが、今回の前提は CPU only です。Continue Docs の推奨モデル帯を見ると、Chat / Edit の best open models は Qwen3 Coder 480B / 30B で、今回の 1.5B / 3B / 7B とは前提がかなり変わります。今回の記事では範囲外とする方が自然です。(Recommended Models for Chat in Continue)。
Q6. OpenAI API は必須ですか
必須ではありません。ローカルLLM基盤の確認は Ollama だけで十分です。ただし、今回の補足比較では、Continue では GPT-4.1 が扱いやすく、Aider では GPT-4.1 と GPT-5.4 の双方でビルドとテスト実行まで進められました。比較対象として入れる価値は高いです。(GPT-4.1 Model | OpenAI API)。
Q7. GPT-5.4 や GPT-5.3-Codex を使えばもっと良くなりますか
そうとは限りません。今回の検証では GPT-5.4 だけでなく GPT-5.3-Codex でも Continue 側で同系統のエラーが出ました。この結果からは、モデル単体の優劣というより、reasoning を持つモデルの会話状態管理やツール統合との相性が影響した可能性が高いです。今回の条件では GPT-4.1 の方が扱いやすかった、という書き方の方が公平です。(GPT-5.3-Codex Model | OpenAI API、Reasoning models | OpenAI API)。
Q8. Codex や Claude Code を使わなかったのはなぜですか
機能が弱いからではありません。今回の比較軸が、単純な生成性能だけではなく、UT 未完了なら IT に進めない、UT / IT 未完了ならデプロイしない、といったフェーズ間コントロールを外側で扱いやすい構造かどうかにもあったためです。Codex CLI や Claude Code にも approval、settings、hooks などの制御機構はありますが、今回の記事では Continue と Aider を主に扱いました。(CLI – Codex | OpenAI Developers、Claude Code settings、Hooks reference – Claude Code Docs)。
参考文献
- Ollama for Windows https://docs.ollama.com/windows
- Ollama Quickstart https://docs.ollama.com/quickstart
- qwen2.5-coder | Ollama Library https://ollama.com/library/qwen2.5-coder
- Model Providers Overview | Continue Docs https://docs.continue.dev/customize/model-providers/overview
- config.yaml Reference | Continue Docs https://docs.continue.dev/reference
- Quick Start | Continue Docs https://docs.continue.dev/ide-extensions/agent/quick-start
- How Agent Mode Works | Continue Docs https://docs.continue.dev/ide-extensions/agent/how-it-works
- Model Setup for Agent Mode | Continue Docs https://docs.continue.dev/ide-extensions/agent/model-setup
- Recommended Models for Chat in Continue https://docs.continue.dev/ide-extensions/chat/model-setup
- Ollama | aider https://aider.chat/docs/llms/ollama.html
- OpenAI | aider https://aider.chat/docs/llms/openai.html
- Connecting to LLMs | aider https://aider.chat/docs/llms.html
- In-chat commands – aider https://aider.chat/docs/usage/commands.html
- Linting and testing – aider https://aider.chat/docs/usage/lint-test.html
- Options reference | aider https://aider.chat/docs/config/options.html
- GPT-4.1 Model | OpenAI API https://developers.openai.com/api/docs/models/gpt-4.1
- Models | OpenAI API https://developers.openai.com/api/docs/models
- Using GPT-5.4 | OpenAI API https://developers.openai.com/api/docs/guides/latest-model
- GPT-5.3-Codex Model | OpenAI API https://developers.openai.com/api/docs/models/gpt-5.3-codex
- Reasoning models | OpenAI API https://developers.openai.com/api/docs/guides/reasoning
- CLI – Codex | OpenAI Developers https://developers.openai.com/codex/cli
- Features – Codex CLI | OpenAI Developers https://developers.openai.com/codex/cli/features
- Claude Code settings https://code.claude.com/docs/en/settings
- Hooks reference – Claude Code Docs https://code.claude.com/docs/en/hooks
まとめ
Windows 11 の CPU only でも、Ollama と qwen2.5-coder でローカルLLM基盤は十分に作れます。Ollama は Windows でローカル API を提供し、qwen2.5-coder は 1.5B、3B、7B など複数サイズが公開されています。(Ollama for Windows、qwen2.5-coder | Ollama Library)。
ただし、今回の CPU only・小型ローカルモデルという条件では、ローカル qwen2.5-coder だけで生成から修正完走まで安定して回すのは簡単ではありませんでした。ここで重要なのは、これはツールそのものの一般評価ではなく、あくまで今回の条件における到達点だという点です。Continue の推奨モデル帯や Aider のコンテキスト長注意点を踏まえると、この結果は公式ドキュメントの前提とも大きくは矛盾しません。(Recommended Models for Chat in Continue、Ollama | aider)。
また、補足比較では Continue で GPT-5.4 / GPT-5.3-Codex が reasoning state まわりの影響を受けた一方、Aider では GPT-4.1 と GPT-5.4 の双方でビルドとテスト実行まで進められました。今回の差はモデル単体の優劣というより、AIコードアシスタント側の統合方式の差として読む方が自然です。(Reasoning models | OpenAI API、How Agent Mode Works | Continue Docs、Linting and testing – aider)。
- ローカル qwen2.5-coder は、基盤確認と軽い補助用途に有効
- 到達点を左右した主因は、モデル単体より AIコードアシスタント側の統合方式
- 実務では、モデル比較と同じくらいオーケストレータ設計の比較が重要
その他のエッセイはこちら
LLMとローカルLLMの全体像をつかむ本
仕組みからわかる大規模言語モデル 生成AI時代のソフトウェア開発入門

「そもそも LLM が何をしているのか」を整理したい
RAG やマルチエージェントまで含めて俯瞰したい
ローカルLLMを単体性能だけでなく、ソフトウェア開発全体の中でどう使うかを考える土台になる
Transformer、学習プロセス、プロンプトエンジニアリング、LangChain を使った RAG 実装やマルチエージェント構築まで扱う入門書と説明されています。
実践 LLMアプリケーション開発

LLM の限界、応用パターン、設計判断を体系的に学びたい
「モデルを呼ぶ」から一段進んで、開発対象として LLM アプリを見たい
OpenAI API とローカルモデルをどう使い分けるか、モデルの限界をどう設計で吸収するかを考えやすい
LLM の構造や限界、活用手法、応用パターンを体系的に紹介する構成です。
AIエージェント / AIコードアシスタントの設計に効く本
LLMの原理、RAG・エージェント開発から読み解く コンテキストエンジニアリング

「モデルが賢いか」より「どういう文脈を渡すか」が重要だと感じた
Continue と Aider の差を、統合設計やコンテキスト管理の視点で理解したい
まさに今回の記事で重要だった「AIコードアシスタント側の統合方式」の理解に直結する
LLM の仕組み、API の挙動、Function Calling、MCP、RAG、AIエージェント、ワークフロー化までをコンテキスト観点で扱っています。
図解まるわかり AIエージェントのしくみ

まずは概念整理をしたい
オーケストレータ層、エージェント、ツール利用の関係を日本語で軽くつかみたい
「LLMが主役に見えるが、構造的にはオーケストレータが主役」という話を読者向けに整理しやすい
AIエージェントの基本概念、最新動向、導入事例、構成技術までを網羅するとされています。
LLMのプロンプトエンジニアリング

prompt を小手先ではなく構造として学びたい
system prompt、制約、出力形式、再現性を強くしたい
Continue / Aider / OpenAI API / ローカルLLM のいずれでも、結局 instruction 設計は効く
LLM の理解から入り、どんな情報をどの構造で組み込むかという本来の意味でのプロンプトエンジニアリングを説明する本です。
Cの実装品質を上げる本
テスト駆動開発による組み込みプログラミング

C でリングバッファのような小さめの部品を堅く作りたい
LLM が出したコードをどうテストで締めるか学びたい
今回のサンプルのような C 実装とテスト実行の相性がかなり良い
制約のある組み込み環境での TDD、C への SOLID 原則、リファクタリング、レガシーコードへのテスト追加まで扱います。
Cクイックリファレンス 第2版

C の仕様、標準ライブラリ、make、デバッガまで辞書的に確認したい
LLM が出したコードの違和感を自分で検証したい
モデルの出力を「なんとなくそれっぽい」で受けず、仕様ベースで判断しやすくなる
C の言語仕様、ライブラリ、コンパイラ、デバッガ、make、IDE まで広く網羅するリファレンスです。
C言語 ポインタ完全制覇

バッファ、ポインタ、配列、関数まわりの基礎を固めたい
LLM が出した C コードの危険箇所を見抜きたい
リングバッファや外部バッファ受け渡しの実装理解に直結しやすい
ロングセラーの新版で、ISO C99 / C11、64bit OS を想定して全面的に見直された内容です。
テスト、品質、継続実行を整える本
ソフトウェアテスト徹底指南書

テストを場当たりではなく体系で学びたい
AI が書いたコードをどう評価するかの軸を持ちたい
「ビルドが通った」だけでは足りず、どんな観点でテストを組むかを補強できる
ソフトウェアテストの知識と技術を体系的に学び、現代的な開発に対応する総合力と基礎力を強化する本です。
入門 継続的デリバリー

ビルド、テスト、リリースを一連の流れで考えたい
「UT が終わっていない成果物は次工程に進めない」のような考え方を整理したい
あなたが重視していたフェーズ間コントロールの話と非常に相性がいい
コード変更を必要に応じて迅速かつ安全に継続的リリースするための知識とベストプラクティスを紹介する入門書です。
AIとソフトウェアテスト 信頼できるシステムを構築するために

生成AIを使う側と、AIをテスト対象として扱う側の両面を見たい
AI 時代の品質保証の観点を補いたい
「AIでコードを書く」だけでなく、「AIが入った開発フローをどう信頼するか」に踏み込める
AI がソフトウェアテストと品質保証に与える影響、テスト自動化、シフトレフトテスト、AIOps などを扱う本です。
迷ったらこの3冊
- LLMの原理、RAG・エージェント開発から読み解く コンテキストエンジニアリング
- テスト駆動開発による組み込みプログラミング
- 入門 継続的デリバリー

コメント