
「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
その他数理関連(MATLAB、Python、Scilab、Julia比較ページ)はこちら

はじめに
なんとなく思いつきで書いたエッセイ集。
「普通はこうだよね?」「みんなこうだよね?」を別の視点でぶん殴ってみる実験エッセイ
適当なタイミングで更新
エッセイ集
- ソフトウェア設計における因果関係の明確化
- 条件分岐や状態遷移の数理的な記述
- 並列処理やバッチ処理の自然な導入
- AIモデルとの構造的な共通性の理解

- 多項式回帰のハック
- フーリエ級数のハック
- ニューラルネットのハック

「箱」は、プログラミング教育において非常に強力なメタファーである。だが、箱に閉じ込められたままでは、複雑な構造や動的な関係性を見失ってしまう。クラス、オブジェクト、関数、変数——それぞれの概念は、箱として捉えることもできるが、それ以上の意味と構造を持っている。

ロジカルシンキングによって導かれる結果は、現実においては一つの仮説に過ぎない。しかし、その過程と表現には大きな価値がある。誤りを構造的に認識し、他者と共有し、柔軟に修正していくための基盤として、ロジカルシンキングは不可欠な思考技術である。

技術開発の現場において、ロジカルシンキングは強力な武器である。しかし、それが現実という複雑な集合の一部に過ぎないことを理解し、その思考構造を柔軟に「再構成」できる能力こそが、不確実な未来を切り拓くための重要な鍵となるだろう。

Attentionは、技術と知能の本質をつなぐ架け橋であり、AIが人間の認知に近づくための重要なステップである。そして、自動車技術においても、より安全で賢い車両知能の実現に向けた鍵となる。

- Neural ODEとの比較:Skip Connectionを連続時間のモデルとして捉えた場合、Neural ODEとの関係をより厳密に整理することで、深層学習と力学系の接続がさらに明確になる可能性がある。
- 他の構造への応用:TransformerにおけるSkip ConnectionやAttention機構など、他の構造に対してもODE的な視点を適用することで、さらなる数理的理解が得られるかもしれない。
- 構造設計へのフィードバック:数理的な視点から得られた知見を、ネットワーク設計やハイパーパラメータの選定に活かすことで、より効率的なモデル構築が可能になる。

- 損切りは本能的には不快で、「続けていれば良い結果が出たかもしれない」という未練も残りがちだが、
- 「損切り=負け」ではなく「損切り=未来のための資源再配分」と捉え直すと、投資・研究開発・プロジェクト・キャリアなどで共通の判断軸として使える。
- ここで書いたのは筆者の一例にすぎないので、共感できる部分だけ拾って自分の文脈に合わせてカスタマイズし、最終判断は自分自身の責任で行ってほしい。

- メディアを「フィルター」として見る
- “静かな良コンテンツ”を自分で集めておく
- 数字は人気指標としてだけ使う

- 虚数・複素数は「√-1という謎の数」ではなく、回転と周期・位相を扱うために数直線を2次元に拡張した座標。
- sin, cos とオイラーの公式で三角関数を複素平面に閉じ込めることで、微分積分が「iω を掛ける」という代数的な操作に変わる。
- フーリエ変換とラプラス変換はどちらも、信号や微分方程式を「回転(+減衰)」の足し合わせとして見直し、面倒な微分を単なる掛け算にしてくれる道具。
- 「B級 → 生成AI → G検定」は難易度順として妥当
- しかし難易度 = 最適ルートではない
- 学習は
- 基礎の広さ
- 特化の深さ
- コスト
- 目的
に応じて設計すべき
- 生成AIパスポートは
「生成AI×リスク×法務×情報管理」の領域を深掘りできるため、 シラバス内でもG検定より難しい問題を構築可能
- AI要約とゼロクリック検索の広がりで、「基礎情報をメインにした資格記事」の役割は、入口から補足・文脈提供へとシフトしつつある。
- ロジスティック関数を使った簡易モデルからは、Geminiのカバー率がある閾値を超えたあたりで、クリック率が一気に落ちる“ゲームチェンジポイント”が示唆される。
- これからは、公式・一次情報と一次経験、そして資格をどう位置づけるかという視点・モデルを提示できるコンテンツの比重を高めることが重要になる。

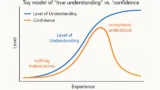
- 暗記偏重は「生徒の怠惰」ではなく、報酬設計の結果として合理的に起きている現象だと、強化学習の視点から説明する。
- 強化学習では「暗記+類題演習=greedyな行動」「本質理解や探究=探索的な行動」とみなせる。
- 個人としては、毎日10〜20分の“探索時間”(ε-greedy) を混ぜることで、テストの点数と長期的な本質理解を両立できる。

- 九九のような基礎暗記は、計算のためだけでなく「思考レイテンシを下げるOS」として残しておく価値がある
- セレンディピティの確率を少しでも上げるには、「まず自分で考える」「雑な知識を頭に撒いておく」といった非効率が効いてくる
- AIは計算や情報整理の強力なツールだからこそ、「どこまで任せてどこから自分で考えるか」を自分でデザインすることが大事

「みんながなんとなく共有しているミーム」を
一度連続関数にして眺めると、
「レバー」や「形の変化」として語り直せる部分も見えてくる
- 「G検定はどこから勉強を始めると挫折しにくいか」
- 「2024のシラバス改訂で“今寄り”になったところはどこか」
- 「生成AI時代に合わせた、現実的な G検定勉強法(2026年版) はどんな形か」

- 難化に見える正体は“ズレ”
- ズレは5軸で測れる
- 対策は較正→観察→耐性

- MCPはLLM向けツール群を標準プロトコルで公開する「配線」、RESTは人間/固定ロジック向けWeb API、LangChainはアプリ内ロジック。
- MCPのツール定義はそのままLLMに読ませるプロンプトなので、ツール名・引数名・descriptionの設計がクリティカル。
- LangChainでのツール/エージェント設計の感覚を起点にMCPを考えると、「MCP=ただのREST API」的なハマりどころを避けやすい。

- 比較は「性能」ではなく 期待値(用途×効用)で決まる
- 体感差は 根拠/概略/提案のデフォルトで説明できるかもしれない
- 重要なのは「どっちが上」より どこで逆転するか

- VLMは画像もテキストも最終的には「トークン列」として扱い、Self-Attentionでトークン同士の関係(どこをどれだけ見るか)を学習している。
- Attentionマップは「この概念は画像のどの領域に対応していそうか」という暗黙の“領域分け”情報を持つが、ピクセル精度のセグメンテーションの完全な代替ではない。
- マルチスケール特徴は、CNN+FPNでもViT系でも「解像度の異なる特徴から何個のトークンを作るか」という設計の違いであり、実務ではVLMのAttentionと専用セグメンテーション(SAMなど)を組み合わせて使うのが現実的。

- 善意の対策情報ほど“始めやすい足場”として有効ですが、足場をゴールと誤認すると失速しやすいです。
- そのズレは本番の適用・横断・境界で露呈し、「難化した」という体感に圧縮されやすいです。
- 「公式で較正」+「用途・つながり・境界」の3行復習で、点を線に戻すのが最短です。

- logits→BCEWithLogitsLoss(logaddexp)は数値安定と実務APIに直結します。
- クラス不均衡はpos_weightで正例の学習信号を強める設計がよく使われます。
- シグモイド統一は入門用で、隠れ層はReLU系へ置き換えるのが普通です。

- 比喩の射程: USB-C=統一された口
- 本文の技術軸: 列挙手順(USB)と機能発見・動的更新(MCP)
- 最大の乖離: 認証・権限とサーバ発見(Registry)

- 距離とコストの組み合わせ次第で、誰でも「素材として扱ってしまう側」に回りうる。
- 「自分はちゃんとしている」という感覚だけではズレを防げないので、仕様と手順で縛った方が安定する。
- 小さな運用(3点セット・クレジット欄・権利系テーマの二重チェック)から変えると、足元の無断っぽさはかなり減らせる。

- 見かけ品質が揃うほど、肉付けとそぎ落としの最終文は似やすくなります。
- 見分けの鍵は、判断基準・制約・捨てた案といった判断材料の痕跡です。
- 広げてから削るハイブリッド運用で、混入と縮小の両方に耐性がつきます。



コメント