その他のエッセイはこちら

- 難所の中心、誤答そのものより、情報量増大と暗黙の要約による候補集合の変質
- spec.md や README.md、要約とベクトル合成に対する人間側の制御層
- 実務で効く最小セット、git、spec.md、README.md、必要に応じて AGENTS.md / CLAUDE.md (OpenAI Developers)
AIコーディングと伝達ロス
AIコーディングの難所は、AIの性能だけではありません。人間同士でも、目的、優先順位、暗黙の前提、妥協条件は完全には共有しきれません。相手が AI であっても、この問題は残ります。しかも AIコーディングでは、会話だけでなく、仕様、ソースコード、差分、ログ、テスト結果、画面情報まで一気に扱います。そのため、問題の中心は「その場でうまく話すこと」よりも、「文脈をどう受け渡すか」に移りやすいです。Codex は OpenAI のコーディングエージェントとして案内され、Claude Code はコードベース全体を読み、複数ファイルを編集し、コマンドを実行し、開発ツールと統合する設計です。 (OpenAI Developers)
Codex は AGENTS.md を instruction chain に組み込みます。Claude Code は CLAUDE.md と auto memory を各会話開始時に読み込みます。両者に共通しているのは、会話の外に永続的な指示を置くという思想です。ただし、ファイル名、探索順序、読み込み条件は同一ではありません。したがって、共通仕様というより、近い発想を持つ別設計として理解する方が正確です。 (OpenAI Developers)
情報量増大と暗黙の要約
AIコーディングでは、仕様、ソースコード、差分、ログ、エラーメッセージ、画面情報、過去の指示が一度に流れ込みます。ここで重要なのは、情報が増えればそのまま理解が深まるとは限らないことです。長い文脈では、関連情報が文脈のどこに置かれているかによって利用性能が変わり、中央付近の重要情報が使われにくくなることが報告されています。複雑な instruction following でも、要件を分解して見ないと従い方の細部が見えにくいことが示されています。 (arXiv)
運用上は、AI が大量情報を逐語的に保持していると期待するより、「途中で圧縮や要約に近い再表現が起きうる」とみなす方が安全です。ここでいう要約は、文章を短くすることだけではありません。複数の条件や文脈が内部表現の中で近いものとしてまとめられたり、細かい差が後景に退いたりすることまで含めて考えた方が、AIコーディングの実感に近くなります。これは内部実装の厳密な説明ではなく、運用上の抽象化です。長文脈の利用制約や要件分解の必要性を踏まえた実務寄りの見方です。 (arXiv)
ベクトルの合成と人間の候補集合
ここで「ベクトル」という言葉を、あえて避けずに使います。OpenAI の embeddings ガイドは、テキストを数値表現に変換し、その API reference では embedding vector が float の配列として返ると説明しています。OpenAI の vision ガイドは、複数画像を一つの request に含められることを示しています。これらを踏まえると、文章、コード、画像などが何らかの連続表現へ写像され、その上で関連付けられると考えるのは自然です。 (OpenAI Developers)
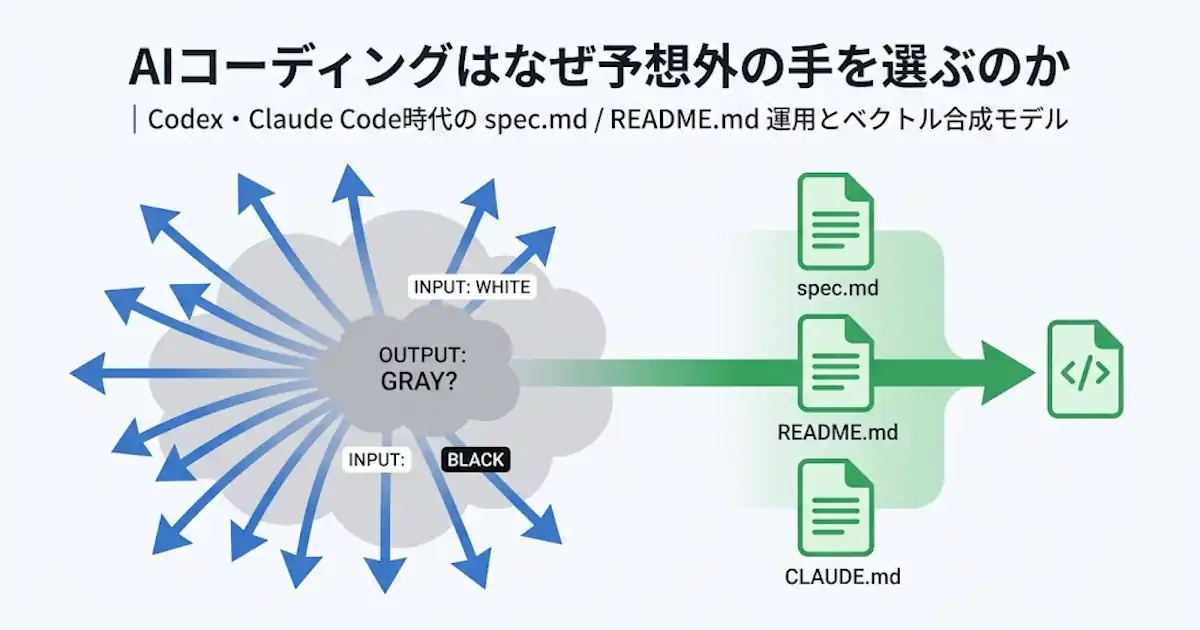
この見方を採ると、AI の問題は「たまに誤答する」だけではありません。もっと重要なのは、人間なら最初から候補に入れない案まで、AI では探索対象に含まれうることです。
たとえば「背景を白かつ黒にして」という指示を考えます。人間ならまず、条件どうしの競合に気づきます。そして多くの場合、次のような候補を考えます。
- どちらを優先するか確認
- 白黒の分割背景
- 白黒のストライプ
- 白黒を活かした別案の提案
一方で AI では、条件がベクトルとして表現され、そこで合成されると考えると、次のような候補が十分に出現しえます。
- グレー
- 無色に近い背景
- 低彩度の背景
- 透明背景
- 黒でも白でもない中立的な背景
- 白と黒の要件を弱く満たした曖昧な中間案
- 一部だけ白黒要素を残した別解釈
重要なのは、「グレーが正しいかどうか」ではありません。重要なのは、人間の対話感覚では自然に除外される候補でも、AI ではベクトル合成の結果として普通に探索対象へ入ることです。
ただし、ベクトルの合成そのものが常に問題を生むわけではありません。むしろ適切な合成は、要約や一般化にとって有効です。たとえば「白い猫がいる」から「白猫がいる」への圧縮は、文法も内容もほとんど崩れていません。一方で「白い猫と黒い猫がいる」から「白黒の猫がいる」や「グレーの猫がいる」へ圧縮されると、文法は成立していても、元の内容は変質しています。この例は極端であり、現行の生成AIがそのままこの誤りを起こすと言いたいわけではありません。ここで押さえたいのは、「混ざった後だけ見ると整合しているが、元の条件関係は保たれていないことがある」という点です。
さらに重要なのは、論点を崩さないアンカーの存在です。たとえば「白い猫と黒い猫がいる」に加えて、「猫が $n$ 匹いる」「じゃれあっている」という状況情報が入ると、複数個体が存在し、それらが関係を持っているという骨格が強く固定されます。すると、白黒猫やグレー猫のような混ざった候補はかなり出にくくなります。問題は混ざることそのものではなく、何を保持すべき骨格として固定するかというアンカーが弱いと、混ざった後だけ整合した別物へ変質しうる点にあります。
最近の評価研究でも、LLM は競合条件の検出能力自体は一定水準に達していても、実際にユーザへ競合を明示したり確認を求めたりする行動は少ないと報告されています。つまり、競合をまったく認識できないことだけが問題ではなく、認識していても「確認」より「何らかの出力を返す」方へ寄りやすい、という点が重要です。 (arXiv)
この意味で、AIコーディングの本質的な難しさは、人間の候補集合と AI の探索候補集合が同じではないことにあります。人間は暗黙の常識で候補をかなり絞っていますが、AI はそこを自動では共有しません。さらに情報量が増えるほど、途中の要約や再表現によって候補の広がり方も人間の直感から離れやすくなります。これは論文がそのまま言っていることではなく、長文脈利用と競合条件評価の結果を踏まえた運用上の解釈です。 (arXiv)
各.md という制御層
ここで spec.md や README.md を、単なる説明ファイルとしてではなく、AI の要約やベクトル合成を人間側から制御しようとする試みとして読むと、かなり整理しやすくなります。
もちろん、これらの文書が AI の内部表現そのものを直接操作するわけではありません。ですが、何を優先し、何を候補から外し、どの視点で評価し、競合条件ではどう振る舞うべきかを外部から与えることで、AI が行う要約や合成の前提を人間側で整えられます。Codex の AGENTS.md と Claude Code の CLAUDE.md は、公式 docs 上では build/test コマンド、規約、ワークフロー、プロジェクト文脈を共有する場として位置づけられています。Claude Code 側は、これらを「強制設定」ではなく「コンテキスト」として扱うとも明記しています。 (OpenAI Developers)
この読み方をすると、各.md の役割は次のように見えてきます。
- spec.md
目的、優先順位、非目標、受け入れ条件 - README.md
利用者視点、前提環境、操作手順、運用条件 - AGENTS.md / CLAUDE.md
AI が作業に入る前提となる共通ルール、確認条件、行動規範 - git
過去に何を試し、何を採用し、何を見送ったか
要するに各.md は、AI が避けられない要約や情報合成を行う前提のうえで、その結果が人間の意図から離れにくくなるよう、目的・優先順位・視点・禁止事項を外部から与える制御層だと考えると理解しやすいです。これは本稿の解釈ですが、公式 docs が repo 上の永続的な指示を重視している事実と整合的です。 (OpenAI Developers)
AI間と人間間の引継ぎ
各.md の価値は、AI 間で引継ぎしやすくなることだけではありません。AI 間で引継ぎできるということは、人間間でも引継ぎしやすいということでもあります。つまり、spec.md や README.md、必要に応じて AGENTS.md や CLAUDE.md を整えておくことは、バイブコーディングを他者へ渡せる状態を作ることでもあります。これは公式 docs の直接表現ではなく、永続的指示ファイルと fresh context の仕組みから引ける運用上の帰結です。 (Claude)
もちろん、同一環境、同一セッション、同一担当で進める方が適切な場面は多いです。ですが実務では、それだけを前提にできません。どうしても環境移動が必要なこともありますし、どうしても他者へ渡す必要が出ることもあります。さらに、文脈が積み上がりすぎて、新しいセッションへ移した方がむしろ精度が上がる場面もあります。この現実的な事情は無視できません。Claude Code docs が「各セッションは fresh context で始まる」と明示している点も、会話外の引継ぎ資産を持つ意義を裏づけます。 (Claude)
このため文書化は、単なる補助ではありません。会話の中だけにある文脈を、AI にも人間にも再利用可能な形で repo 側へ移す仕組みです。したがって各.md は、「AI に渡す説明書」であると同時に、「次の担当者に渡す引継ぎ資料」でもあります。これは人間対 AI のコミュニケーション設計にとどまらず、AI 対 AI、人間対人間、人間対 AI のあいだで文脈を受け渡す設計として考えた方が、実務には合っています。 (OpenAI Developers)
Codex・Claude Code運用に効く最小セット
実務でまず効くのは、次の 3 点です。
- git
- spec.md
- README.md
余力があれば、さらに AGENTS.md または CLAUDE.md を加えます。Codex は AGENTS.md を読み、Claude Code は CLAUDE.md を読みますが、前述の通りこれは共通仕様ではなく別設計です。ただ、どちらも repo 上に行動規範を置くという運用思想は共通しています。 (OpenAI Developers)
AIコーディングで文書化が効く理由は、単に引継ぎが楽になるからだけではありません。情報量が増えるほど、重要条件が他の情報に埋もれやすくなり、AI はその都度ある程度の再表現をしながら判断せざるをえません。git、spec.md、README.md、AGENTS.md、CLAUDE.md を整える意味は、その再表現のたびに参照されるべき条件を repo 上に明示しておくことです。これは長文脈利用の弱点と、競合条件での確認不足を考えると、かなり実務的な対処です。 (arXiv)
git に書くこと
git は単なる保存手段ではありません。過去の試行、採用した判断、見送った案の履歴です。
残したいものの例は次のとおりです。
- 変更理由がわかるコミットメッセージ
- 仕様変更の理由
- 破棄した案がある場合の理由
- どのテストで確認したか
- 互換性や移行時の注意
コミットメッセージ例
検索条件を商品コード優先へ変更
CSV取込をバッチ方式から逐次方式へ変更
レポート集計の基準日を受注日へ統一
管理画面の初期案を見送り、一覧先行へ変更spec.md に書くこと
spec.md は「何を作るか」と「何を作らないか」を書く文書です。機能一覧だけでなく、判断基準を明示することが重要です。
入れておきたい項目の例は次のとおりです。
- 背景
- 目的
- 対象ユーザ
- スコープ
- 非目標
- 優先順位
- 受け入れ条件
- 制約
- 未確定事項
spec.md の例
# spec
## 背景
営業担当が顧客検索と面談記録登録に時間を使いすぎています。
## 目的
顧客検索から面談記録登録までを短時間で完了できるようにします。
## 対象ユーザ
社内営業担当者
## スコープ
- 顧客検索
- 面談記録の登録
- 直近履歴の表示
## 非目標
- 外部CRMとの双方向同期
- 詳細な権限管理
- モバイルアプリ化
## 優先順位
1. 登録操作の速さ
2. 必須情報の欠落防止
3. 見た目の完成度
## 受け入れ条件
- 顧客名または顧客コードで検索できる
- 面談記録を3ステップ以内で登録できる
- 直近5件の履歴を同一画面で確認できる
## 制約
- 既存DBスキーマは変更しない
- Chrome最新版を前提とする
## 未確定事項
- 画像添付を初版に含めるか
- 下書き保存を初版に含めるかREADME.md に書くこと
README.md は「どう使うか」を書く文書です。spec.md が企画と判断基準を担うのに対し、README.md は利用者視点と再現手順を担います。
入れておきたい項目の例は次のとおりです。
- プロジェクト概要
- 前提環境
- セットアップ
- 起動方法
- テスト方法
- 主な操作
- よくある注意
- ディレクトリ概要
README.md の例
# README
## 概要
営業担当向けの顧客検索・面談記録ツールです。
## 前提環境
- Python 3.11
- Node.js 20
- PostgreSQL 15
## セットアップ
1. リポジトリを取得
2. .env.example を .env にコピー
3. 依存関係をインストール
4. DBを初期化
## 起動方法
make dev
## テスト
make test
## 主な操作
- 顧客名または顧客コードで検索
- 顧客詳細から面談記録を追加
- トップ画面で直近履歴を確認
## 注意
- 本番用APIキーは .env のみで管理
- CSV一括投入は開発環境では無効AGENTS.md / CLAUDE.md に書くこと
AI 向けの運用ルールは、spec.md や README.md と重複しても構いません。むしろ、AI が最初に参照しやすい形で再掲した方が実務では安定しやすいです。Codex は AGENTS.md を guidance として読み、Claude Code は CLAUDE.md を各セッションの context として読みます。Claude Code の docs は、これらを強制設定ではなくコンテキストとして扱うとも明記しています。 (OpenAI Developers)
入れておきたい項目の例は次のとおりです。
- 実装前に読むべき文書
- build/test コマンド
- 変更前に確認すべき制約
- 競合条件では確認を優先すること
- 破壊的変更の扱い
- UI変更で優先する視点
- コミットやPR説明の粒度
AI向け運用ファイルの例
# project rules
## 先に読むもの
1. README.md
2. spec.md
## 実装前のルール
- 受け入れ条件を満たす変更を優先する
- 非目標に入る変更は提案止まりにする
- 競合条件がある場合は確認事項として列挙する
## 実行コマンド
- 起動: make dev
- テスト: make test
- Lint: make lint
## 変更方針
- 既存DBスキーマは変更しない
- UI変更では入力速度を最優先する
- 破壊的変更は理由をコミットに残す抽象モデルによる見取り図
数式モデルと Python コードは補足です。読み飛ばしても本文の主張は追えます。
ここで示す数式モデルと Python コードは、Transformer の内部実装を再現する mechanistic model ではありません。AIコーディング時に観察される「条件競合」「情報圧縮」「候補集合の差」を、運用上の意思決定モデルとして見える形にした toy model です。実際の Transformer は attention を中心にした多段な表現変換を行いますが、本節の式はその内部動作の近似記述ではありません。ここではあくまで、運用理解のための抽象モデルとして使います。 (arXiv)
補足:数式モデル(読み飛ばし可)
人間が自然に候補へ入れる行動集合を $\mathcal{A}*{\mathrm{H}}$、AI が探索しうる行動集合を $\mathcal{A}*{\mathrm{AI}}$ とします。ここで重要なのは、
$$
\mathcal{A}*{\mathrm{H}} \subsetneq \mathcal{A}*{\mathrm{AI}}
$$
となりやすいことです。つまり、AI の探索対象の方が広く、人間が暗黙に除外している案も含みます。
ユーザから来る条件をベクトル $c_{1}, c_{2}, \ldots, c_{n}$ とし、その合成を
$$
z = \sum_{i=1}^{n} w_{i} c_{i}
$$
と置きます。さらに、要約や情報圧縮による再表現を単純化して、補助ベクトル $u$ を
$$
z’ = z + \alpha u
$$
として加えます。ここで $u$ は spec.md や README.md などが与える目的、優先順位、視点、禁止事項の影響だとみなします。
各行動 $a$ に特徴ベクトル $f(a)$ があるとすると、行動スコアを
$$
S(a \mid z’) = {z’}^{\top} f(a) – \lambda \lVert f(a) \rVert^{2} + \rho \chi I[a=\mathrm{ask_clarify}]
$$
と書けます。$\chi$ は条件競合の強さです。すると行動選択確率は
$$
P(a \mid z’) =
\displaystyle\frac{\exp(\beta S(a \mid z’))}
{\sum_{b \in \mathcal{A}} \exp(\beta S(b \mid z’))}
$$
と書けます。
この toy model で言いたいことは単純です。
- 条件は内部でベクトル的に合成されるとみなせる
- 情報量が増えると、要約に相当する再表現も入りうる
- そのとき AI は広い $\mathcal{A}_{\mathrm{AI}}$ から候補を出しやすい
- spec.md や README.md は $u$ として働き、探索の向きを人間側の期待へ寄せると考えられる
要するに各.md は、AI の内部処理そのものを操作するものではなく、AI が要約やベクトル合成を行う前提に対して、人間側から条件を与える制御層として理解できます。
Pythonシミュレーション
Python コードも補足です。読み飛ばしても本文の理解に支障はありません。
以下のコードは LLM の内部実装を再現するものではなく、競合条件と候補集合の差がどのように挙動差として見えるかを示す概念実験です。
補足:Pythonシミュレーション(読み飛ばし可)
import numpy as np
constraints = {
"white": np.array([1.0, 0.0]),
"black": np.array([-1.0, 0.0]),
}
actions = {
"transparent": np.array([0.00, 0.00]),
"gray": np.array([0.00, 0.10]),
"desaturated": np.array([0.00, 0.20]),
"split": np.array([0.10, 0.85]),
"striped": np.array([0.00, 1.00]),
"ask_clarify": np.array([0.00, 0.70]),
}
human_candidates = ["split", "striped", "ask_clarify"]
ai_candidates = ["transparent", "gray", "desaturated", "split", "striped", "ask_clarify"]
def cosine(a, b, eps=1e-9):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b) + eps)
def conflict_score(values):
vals = list(values.values())
score = 0.0
for i in range(len(vals)):
for j in range(i + 1, len(vals)):
score += max(0.0, -cosine(vals[i], vals[j]))
return score
def rank_actions(z, candidate_names, lam=0.15, clarify_bonus=0.0, steering=None):
if steering is None:
steering = np.zeros_like(z)
z_eff = z + steering
scores = {}
for name in candidate_names:
a = actions[name]
score = np.dot(z_eff, a) - lam * np.linalg.norm(a) ** 2
if name == "ask_clarify":
score += clarify_bonus
scores[name] = score
return sorted(scores.items(), key=lambda x: x[1], reverse=True)
z = sum(constraints.values())
chi = conflict_score(constraints)
print("=== naive AI ===")
for name, score in rank_actions(z, ai_candidates):
print(f"{name:12s}: {score:.4f}")
print("\n=== human-like ===")
for name, score in rank_actions(
z,
human_candidates,
clarify_bonus=0.8 * chi
):
print(f"{name:12s}: {score:.4f}")
print("\n=== guided AI ===")
steering = np.array([0.0, 0.80])
for name, score in rank_actions(
z,
ai_candidates,
clarify_bonus=0.8 * chi,
steering=steering
):
print(f"{name:12s}: {score:.4f}")=== naive AI ===
transparent : 0.0000
gray : -0.0015
desaturated : -0.0060
ask_clarify : -0.0735
split : -0.1099
striped : -0.1500
=== human-like ===
ask_clarify : 0.7265
split : -0.1099
striped : -0.1500
=== guided AI ===
ask_clarify : 1.2865
striped : 0.6500
split : 0.5701
desaturated : 0.1540
gray : 0.0785
transparent : 0.0000このコードで見たいのは、AI が必ずグレーを選ぶかどうかではありません。
見たいのは次の 3 点です。
- naive AI
条件競合があっても、広い候補集合からもっともらしい案を出しやすい - human-like
競合時に確認を優先しやすい - guided AI
外部文書によって、人間の期待に近い候補を選びやすくなる
つまり、問題の中心は平均化そのものではなく、候補集合の広さと、要約・合成の前提条件にあります。
FAQ
AIコーディングで意図と違う実装が出る理由
AIコーディングでは、コード、ログ、差分、仕様など多くの情報が同時に扱われます。長い文脈では重要情報の位置によって利用性能が変わり、複雑な instruction following でも要件ごとの追跡が必要です。そのうえ、競合条件では確認より先に出力を返す傾向も報告されています。結果として、人間なら候補に入れない案まで探索対象へ入りやすくなります。 (arXiv)
spec.md と README.md の違い
spec.md は、目的、優先順位、非目標、受け入れ条件を書く文書です。README.md は、利用者視点の使い方、前提環境、セットアップ、操作手順を書く文書です。前者は判断基準、後者は再現手順と利用文脈を担います。
AGENTS.md や CLAUDE.md は共通仕様か
共通仕様ではありません。Codex は AGENTS.md を読み、Claude Code は CLAUDE.md を読みます。Claude Code docs は AGENTS.md を直接読むのではなく、必要なら CLAUDE.md 側で管理する前提を取っています。共通しているのは、会話の外にプロジェクト固有の指示を置くという運用思想です。 (OpenAI Developers)
数式や Python コードを読まなくてもよいか
問題ありません。数式と Python は説明を整理するための補助です。本文だけでも、なぜ文書化が必要か、なぜ AI が予想外の候補を選びうるかは理解できます。
参考文献
- OpenAI, Custom instructions with AGENTS.md – Codex
https://developers.openai.com/codex/guides/agents-md - OpenAI, Codex | OpenAI Developers
https://developers.openai.com/codex - OpenAI, Vector embeddings | OpenAI API
https://developers.openai.com/api/docs/guides/embeddings - OpenAI, Create embedding | OpenAI API Reference
https://developers.openai.com/api/reference/resources/embeddings/methods/create - OpenAI, Images and vision | OpenAI API
https://developers.openai.com/api/docs/guides/images-vision - Anthropic, How Claude remembers your project
https://code.claude.com/docs/en/memory - Anthropic, Explore the .claude directory
https://code.claude.com/docs/en/claude-directory - Anthropic, Claude Code overview
https://code.claude.com/docs/ja/overview - Yiwei Qin, Kaiqiang Song, Yebowen Hu, Wenlin Yao, Sangwoo Cho, Xiaoyang Wang, Xuansheng Wu, Fei Liu, Pengfei Liu, Dong Yu, InFoBench: Evaluating Instruction Following Ability in Large Language Models
https://aclanthology.org/2024.findings-acl.772/ - Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, Percy Liang, Lost in the Middle: How Language Models Use Long Contexts
https://arxiv.org/abs/2307.03172 - Xingwei He, Qianru Zhang, Pengfei Chen, Guanhua Chen, Linlin Yu, Yuan Yuan, Siu-Ming Yiu, ConInstruct: Evaluating Large Language Models on Conflict Detection and Resolution in Instructions
https://arxiv.org/abs/2511.14342 - Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin, Attention Is All You Need
https://arxiv.org/abs/1706.03762
まとめ
AIコーディングの難所は、AI の精度だけではありません。コード、差分、ログ、仕様が一気に流れ込むことで、途中に要約や再表現が入りやすくなり、人間が暗黙に除外している候補まで探索対象へ入りやすくなります。長文脈利用の研究や競合条件の評価研究は、この運用上の見方を後押しします。 (arXiv)
そのため、spec.md、README.md、AGENTS.md、CLAUDE.md は単なる文書ではありません。AI が要約やベクトル合成を行う前提に対して、人間側から目的、優先順位、視点、禁止事項を与える制御層として理解すると、役割が見えやすくなります。ただし AGENTS.md と CLAUDE.md は同じ仕様ではなく、あくまで近い運用思想を持つ別設計として扱う方が正確です。 (OpenAI Developers)
さらに各.md は、AI 間だけでなく人間間の引継ぎ基盤でもあります。同一環境の継続が理想でも、現実には環境移動、担当交代、新しいセッションへの移行が必要になる場面があります。そのとき、会話の中だけにあった文脈を repo 側へ移しておけば、バイブコーディングも継続可能な開発へ近づきます。 (Claude)
- 難所の中心、誤答そのものより、候補集合と要約前提の差
- spec.md や README.md、人間側の制御層であり、同時に引継ぎ基盤
- 実務で効く最小セット、git、spec.md、README.md、必要に応じて AGENTS.md / CLAUDE.md
仕様を言語化してアンカーを打つ本
『[入門+実践]要求を仕様化する技術・表現する技術』

spec.md 論にいちばん直結する1冊。
「要求」と「仕様」の本質から入り、仕様書作りの考え方や表現方法を具体化する本として説明されていて、さらに「振る舞い」や「動詞」を意識して仕様漏れや衝突を減らす視点が強い。
「混ざってはいけない条件を外から固定する」にかなり近い。
境界と優先順位を設計として扱う本
『ソフトウェアアーキテクチャの基礎』

「README.md や spec.md は単なる説明書ではなく制御層」という見方を、設計の側から補強しやすい。
アーキテクチャ定義、役割、モジュールや結合、アーキテクチャスタイルに加えて、チームやステークホルダーとの協働に必要なソフトスキルまで含めて整理するとある。
文書化と設計判断を切り離さずに読みたいときに合う。
『ドメイン駆動設計をはじめよう』

「何をまとめて扱い、何を分けて扱うか」という論点に強い。
事業活動と課題の観点からソフトウェアを構築する方法を扱い、設計方針、実装方法、現場への導入、他手法との関係までを4部構成で解説するとある。spec.md を単なる要求一覧ではなく、業務の意味境界を書く場として考えたいならかなり合う。
引継ぎとチーム間インタラクションを考える本
『チームトポロジー』

「AI間で引継げるなら、人間間でも引継げる」という話を、組織側から支えてくれる本。
4つの基本的なチームタイプと3つのインタラクションパターンに基づく実践モデルとして説明されていて、チーム間の問題をシグナルとして扱い、結果のアーキテクチャをより明確で持続可能にする方向へつなげるとしている。
バイブコーディングを“個人芸”で終わらせず、引継ぎ可能な運用にしたいならかなり刺さる。
人・組織・運用まで含めて全体を見る本
『システム思考の世界へ』

「問題はAI単体ではなく、人間・AI・組織・文脈の相互作用にある」という論点にいちばん自然につながる。
ソフトウェア技術者が向き合うのは単体のソフトウェアではなく、人や組織の中で使われ影響しあうシステムだと説明されている。
コードだけでなく、運用、認識合わせ、引継ぎまで含めて考えるにはかなり相性がいい。
LLM/エージェントを実装寄りに把握する本
『[入門]LLMアプリ開発』

「内部実装の厳密説明ではなく、運用理解の抽象化」と置きつつ、実装側の地面も押さえたいならこれが合う。
LangChain を使った LLM アプリ開発、LLM の仕組み、モデル選定、MCP、AI セキュリティまでを実践的に扱うとしている。
「じゃあ実務ではどう運ぶか」に寄せたい人向け。
人間側のバイアスと判断のクセを補強する本
『情報を正しく選択するための認知バイアス事典』

「AIが悪いだけではなく、人間側にもボトルネックがある」を補強する読み物として合う。
「60の心のクセ」を扱う本として紹介されている。技術書ではないぶん、記事の前半にある「伝達ロス」「暗黙の前提」「人間の候補集合」の話をやわらかく支えやすい。
3冊に絞るなら
- 『要求を仕様化する技術・表現する技術』
- 『チームトポロジー』
- 『システム思考の世界へ』

コメント