「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
その他のエッセイはこちら

生成AIパスポート・G検定・AI実装検定B級の位置づけと難易度構造
AI関連の資格はここ数年で急速に増加しています。
特に利用される機会が多いのは次の4つです。
- AI実装検定B級
- 生成AIパスポート
- G検定(JDLA)
- DS検定(データサイエンティスト検定)
これら4つの 試験日・合格率・問題レベル・勉強時間の目安 などの基本情報は、以下の個別記事で詳しくまとめています。
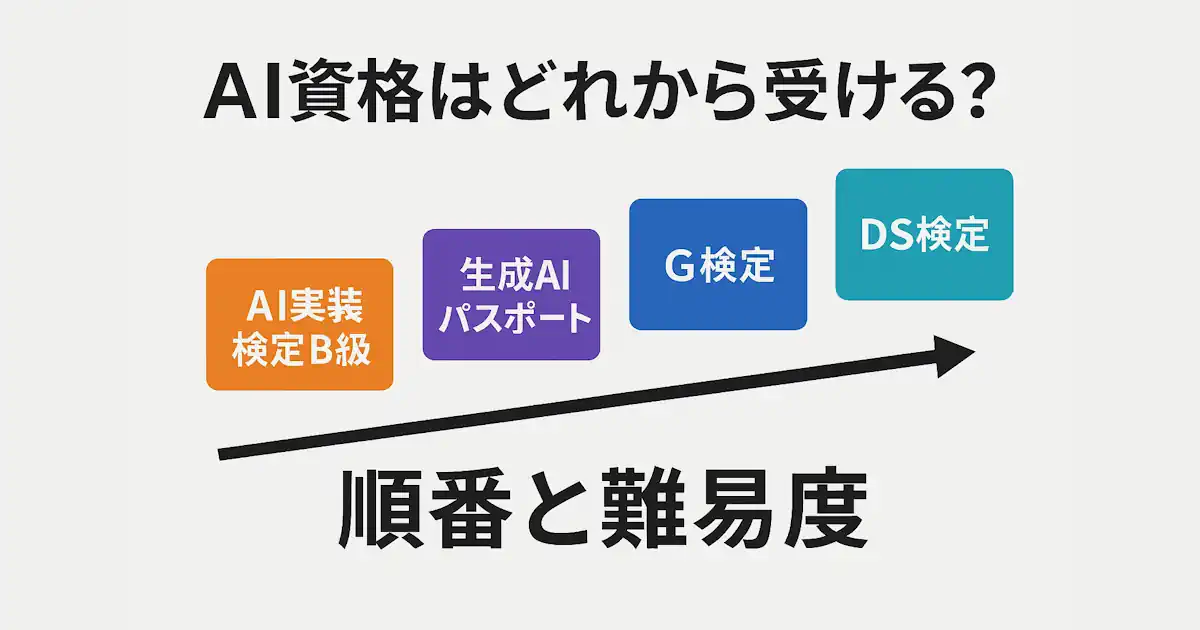
この4つはよく比較されますが、世の中では次のような「ステップアップ」が広まっています。
AI実装検定B級 → 生成AIパスポート → G検定
難易度感だけで見ると、たしかにこの順番は自然です。
しかし、実際の学習プロセスや資格の構造を細分化すると、
必ずしも「生成AIパスポート < G検定」という単線構造ではありません。
この記事では、資格ごとの特性を整理し、
- 難易度順では正しいが
- 学習の筋としては別の“最適ルート”も存在する
という点を、問題例や簡易モデルを交えながら解説します。
一次元(難易度)で並べた場合のステップ
まずは “世の中の一般的認識” に近い整理から。
次のような一次元モデルを仮定します:
- $d_i$:資格 i の「体感難易度」
すると、多くの受験者が抱く印象としては次の順序になります。
$$
d_{\text{B級}} < d_{\text{生成AIパスポート}} < d_{\text{G検定}} \approx d_{\text{DS検定}}
$$
たしかに 「簡単なものから進む」 という視点では自然です。
しかし、このモデルには問題があります。
資格を比較する際の「領域の違い」が欠落しているのです。
二次元モデル:基礎の広さ × 特化の深さ
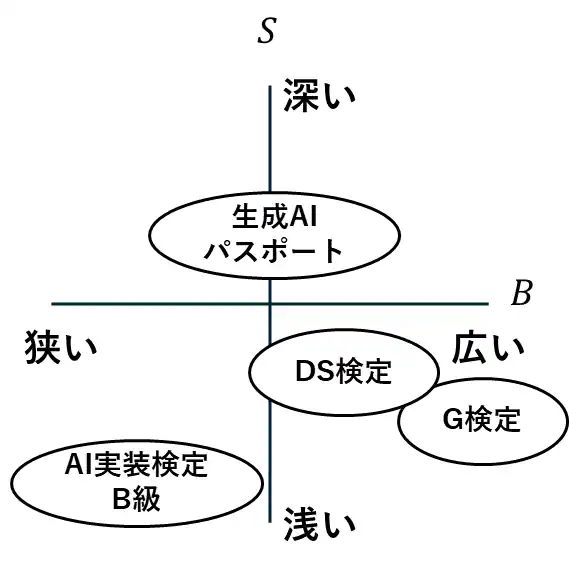
資格をより正確に位置づけるため、以下の2軸を導入します。
- $B_i$:AIまたはデータサイエンスの「基礎をどれだけ広くカバーしているか」
- $S_i$:特定領域(例:生成AI、リスク、統計など)への「特化・深さ」
この視点で4資格を整理すると、以下のようになります(概念図)。
| 資格名 | 基礎の広さ $B_i$ | 特化の深さ $S_i$ | コメント |
|---|---|---|---|
| AI実装検定B級 | 小〜中 | 小 | 初歩・入口 |
| 生成AIパスポート | 中 | 大 | 生成AI+リスク・法務に特化 |
| G検定 | 大 | 中 | AI全般を横断的に学ぶ基礎 |
| DS検定 | 大 | 中 | データサイエンスの全体像 |
つまり、
- G検定は “広い(Bが大きい)”
- 生成AIパスポートは “特化の深さ(S)が大きい”
という別軸の強みを持つ資格です。
ミニ問題で“難易度順”を確認する
実際の試験とは無関係のオリジナル問題ですが、
「難易度順の階段」感を体感できる問題を3つ用意しました。
■ 問題1(AI実装検定B級レベル)
Q1. 次のうち「生成AI」の説明として最も適切なのはどれか。
A. 推論中に自動的に学習し続けるAI
B. 大量のデータから学習し、新しい文章や画像を生成できるAI
C. ロボット制御専用のAI
D. Webの情報を収集して検索結果を返すAI
解答:B
→ 用語の基本理解が中心。入口レベル。
■ 問題2(生成AIパスポートレベル)
Q2. 外部の生成AIサービスに入力してはいけない最も重大な情報はどれか。
A. 社内で共有されている汎用マニュアル
B. 社内プロンプトガイドライン
C. 顧客名・案件内容など個人情報や企業秘密が含まれる日報
D. 社内報の文章
解答:C
→ 生成AIパスポートが重視する情報管理・リスクの理解。
■ 問題3(G検定レベル)
Q3. 次のうちSelf-Attentionの説明として最も適切なのはどれか。
A. モデルが推論時に自動で再学習する仕組み
B. 入力系列内のすべての単語間の関係性を重み付けて処理する
C. 単語の順序を保持するための固定の重み行列
D. LLMで必ず利用される教師なし最適化手法
解答:B
→ モデル構造に関する理解が必要。
この3問から、
難易度(知識の深さ)では確かに B級 → 生成AI → G検定 の順番
という構造がある程度妥当だと分かります。
しかし:生成AIパスポートは「難しさ」でG検定を超えることができる
ここが本記事の核となるポイントです。
生成AIパスポートは
- 技術内部には深く踏み込まない一方
- リスク・法令・情報管理・ガバナンス などを幅広く扱う
という特徴があります。
これらの領域は、実務に寄せるほどいくらでも難しくできる特徴があります。
以下に、生成AIパスポートのシラバス範囲内で作成した
“高難度”版サンプル問題を示します。
■ 問題4(生成AIパスポート高難度:特許・営業秘密)
Q4. 企業Aは、将来の特許出願を検討している新製品の仕様書(まだ社外非公開)を、海外リージョンで運用されている外部生成AIサービスにアップロードし、「技術的に分かりやすい表現に書き直してほしい」と依頼した。 サービスの利用規約には「利用者が入力した情報は、サービス改善のために二次利用する場合がある」と記載されている。 この状況において、法的・リスク面の評価として最も妥当なものはどれか。
A. 日本国内でのみ特許出願予定であれば、海外リージョンのサービスを利用しても新規性喪失には該当しない
B. 利用規約に同意していれば、秘密保持契約(NDA)よりも生成AIサービス側の利用条件が優先されるため、企業Aは責任を負わない
C. 仕様書の内容がサービス運営者側に複製・保管され、第三者へ利用されることで、特許法上の新規性喪失や、不正競争防止法上の営業秘密性喪失リスクが生じ得る
D. 技術文書は著作物だが「アイデア」は著作権の対象外であるため、入力したとしても法的リスクは生じない
解答:C
難易度が上がっているポイント
- すべての選択肢がそれっぽく見える
- 「特許の新規性」「営業秘密」「利用規約とNDAの関係」「著作権とアイデアの関係」などを区別して考える必要がある
- 単に“なんか危なそう”では選びにくい構成
■ 問題5(生成AIパスポート高難度:情報管理+モデル学習)
Q5. 従業員1.5万人規模の企業Bが、社内Wiki全文(以下の情報を含む)をオンプレミスの生成AIモデルに学習させ、QAボットとして社内公開しようとしている。
- 社内プロジェクト名・コードネーム(機密:中)
- インシデント報告書・再発防止策(機密:高)
- 従業員の氏名・部署・役職(個人情報)
- 外部パートナー企業との契約条件(機密:高)
- 担当者が書いた未検証メモ(誤情報を含む可能性あり)
企業Bの対応として、「生成AIパスポートの観点で適切とは言えないもの」をすべて選べ。
A. 個人情報・契約情報などを自動検出し、機密度に応じてマスキング・削除を行う前処理パイプラインを構築する
B. モデルの学習ログおよび問い合わせログを保存し、アクセス権限を最小限に設定する
C. 「オンプレミスで動かす社内専用モデルであれば、個人情報や機密情報も原則として制限なく学習させてよい」とガイドラインに明記する
D. 未検証メモについては、情報源の信頼度(例:公式文書かどうか)に応じたスコアを付与し、回答生成時にスコアの低い情報の重みを下げる
E. 社内利用であれば、個人情報保護法の適用範囲外とみなされるため、特別な配慮は不要と判断する
解答:C, E
難易度が上がっているポイント
- 「オンプレだから安全」「社内だから個人情報保護法の適用外」というありがちな誤解を見抜けるか
- 他の選択肢(A, B, D)もそれなりに実務的で、簡単には切り捨てできない
- 情報保護・アクセス制御・データ品質(誤情報)など、複数の観点を同時に考える必要がある
■ 問題6(生成AIパスポート高難度:社内ルール・ガバナンス設計・改訂版)
Q6. 企業Cが策定した「生成AI利用ルール(抜粋)」は次のとおりである。 この中で、ガバナンス上、構造的に最も大きな欠陥を含んでいるものはどれか。
- 「顧客名・住所などの“個人名情報”は入力禁止」と明記しているが、契約条件・未発表製品情報・価格情報などの営業秘密については明示的な禁止・制限条項がなく、「それ以外の情報は常識の範囲で判断すること」とだけ記載されている。
- 利用を許可する生成AIサービスの一覧と、それぞれの利用範囲(例:試験的利用のみ可、顧客データの入力禁止など)を付録として明記しているが、一覧の更新頻度や、一覧に載っていないサービスの扱い(原則禁止かどうか)がルール本文に書かれていない。
- 重要な意思決定に生成AIの出力を用いる場合、人間による事実確認・妥当性チェックを必須とすることを定めているが、「重要な意思決定」の定義や、チェックの責任者(担当部署)が明記されていない。
- 利用者からの問い合わせ窓口(情報システム部門)を明記し、ルールの更新履歴を管理するプロセスに加え、年1回以上の従業員向け研修でルール内容を周知することを定めている。
解答:1
難しくなっているポイント
- 2と3も「それなりに危うい」要素があり、1だけ露骨に悪者ではない
- 2:シャドーIT/未承認サービスの扱いがあいまい
- 3:責任の所在や適用範囲があいまい
- 4だけはほぼポジティブ要素しかないが、2・3も「改善余地」であって、
“構造的な欠陥”という意味では 1 の「対象範囲の抜け」が最も致命的 - 「個人情報だけNG」にして営業秘密や未公開情報をノールックにしている点が、
ルール全体の前提を誤らせるという意味で一番重い
これらの問題はすべて生成AIパスポートの範囲に収まっていますが、
G検定の“技術寄りの深さ”とは別の軸の難しさがあります。
つまり、
生成AIパスポートは G検定より“簡単”とは限らない。 深掘りの方向が異なり、難度を上げる余地が大きい。
ということです。
簡易モデルでルート選択を考える
資格ルートの「良し悪し」は、個人の目的によって変わります。
そのため、ルートの総合評価を次のように定義できます。
■ 資格ルートのスコア関数
- ルート $R$
- 資格 $i$ の
- 基礎の広さ $B_i$
- 特化の深さ $S_i$
- コスト(時間・金額)$C_i$
スコアを次で定義します:
$$
\text{Score}(R)=
\sum_{i\in R}
\left(
\alpha\frac{B_i}{C_i}
+
\beta\frac{S_i}{C_i}
\right)
$$
- $\alpha$:AIの基礎理解を重視する度合い
- $\beta$:生成AIなど特化領域を重視する度合い
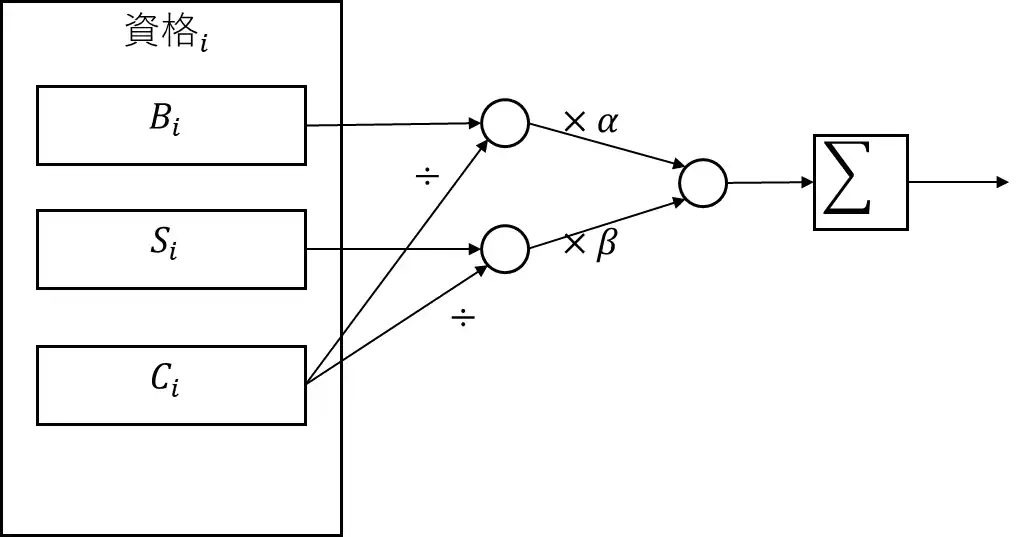
■ “基礎重視”にしても「生成AIを先に取る方が高スコア」の場合がある
仮の値を置くと、次が成立する場合があります。
- B級 → 生成AI → G検定 の方が
- B級 → G検定 → 生成AI より、
基礎重視(α大)でも高スコアになるケースがある
これは、
- 生成AIパスポートが「特化の深さ」を大きく取れる
- コストが比較的低い
- G検定に先に進む心理的ハードルが下がる
ために発生する現象です。
結局、どの順番で受けるべきか?
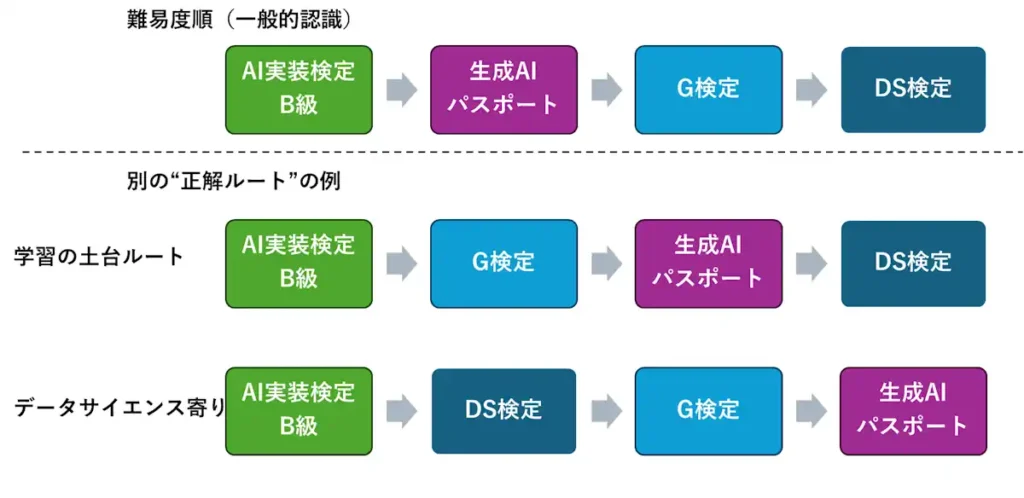
整理すると、目的別の推奨ルートは次の通りです。
■ 難易度順(ライト向け)
B級 → 生成AIパスポート → G検定 → DS検定
■ 学習の土台順(体系的に進めたい方向け)
B級 → G検定 → 生成AIパスポート → DS検定
■ データサイエンス寄り
B級 → DS検定 → G検定 → 生成AIパスポート
それぞれの試験について、試験日・合格率・勉強時間の目安をもう少し具体的に知りたい場合は、次の個別記事も参考にしてください。
本記事の結論
- 「B級 → 生成AI → G検定」は難易度順として妥当
- しかし難易度 = 最適ルートではない
- 学習は
- 基礎の広さ
- 特化の深さ
- コスト
- 目的
に応じて設計すべき
- 生成AIパスポートは
「生成AI×リスク×法務×情報管理」の領域を深掘りできるため、 シラバス内でもG検定より難しい問題を構築可能
以上がこの記事の主旨です。
関連記事
各資格の 試験日・合格率・問題レベル などの詳しい情報はこちらで解説しています。
付録:FAQ
Q1. AI資格はどの順番で受けるのが正解ですか?
目的によって異なります。
- ライト層
→ B級 → 生成AI → G検定 - 体系的に学びたい
→ B級 → G検定 → 生成AI - データ分析寄り
→ B級 → DS検定 → G検定
Q2. 生成AIパスポートはG検定より簡単ですか?
領域によります。
- 技術理解 → G検定の方が上
- リスク・法務・ガバナンス → 生成AIパスポートが深くなり得る
Q3. AI実装検定B級は受ける意味がありますか?
あります。
AI資格群の中で “入口”として位置づけられる唯一の資格です。
Q4. DS検定はどんな人に向いていますか?
統計・データ分析・DXを扱う人全般。
生成AIとは別軸の基礎を固めたい場合に向いています。
Q5. 最終的にどれを優先すべきですか?
- AI全体の基礎 → G検定
- 生成AIの安全活用 → 生成AIパスポート
- データ分析 → DS検定
「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
参考文献
- 日本ディープラーニング協会(JDLA). 「G検定(ジェネラリスト検定)」公式サイト.
https://www.jdla.org/certificate/general/ - 一般社団法人データサイエンティスト協会. 「DS検定® データサイエンティスト検定™ リテラシーレベル」公式サイト.
https://www.datascientist.or.jp/dscertification/ - 生成AI活用普及協会(GUGA). 「生成AIパスポート試験」公式サイト.
https://guga.or.jp/outline/ - AI実装検定実行委員会(AIEO). 「AI実装検定」公式サイト.
https://kentei.ai/ - 個人情報保護委員会. 「生成AIサービスの利用に関する注意喚起等について」.
https://www.ppc.go.jp/news/careful_information/230602_AI_utilize_alert/ - e-Gov法令検索. 『個人情報の保護に関する法律(平成十五年法律第五十七号)』.
https://elaws.jp/view/415AC0000000057 - 経済産業省. 「AIガバナンス」.
https://www.meti.go.jp/policy/it_policy/ai-governance/index.html - 経済産業省. 「AI事業者ガイドライン」.
https://www.meti.go.jp/shingikai/mono_info_service/ai_shakai_jisso/pdf/20241122_1.pdf - 経済産業省. 「不正競争防止法の概要」.
https://www.meti.go.jp/policy/economy/chizai/chiteki/unfaircompetition_new.html - World Intellectual Property Organization (WIPO). Generative AI: Navigating Intellectual Property.
https://www.wipo.int/publications/en/details.jsp?id=4713 - World Intellectual Property Organization (WIPO). Artificial Intelligence and Intellectual Property.
https://www.wipo.int/en/web/frontier-technologies/artificial-intelligence/index - OECD. OECD AI Principles overview.
https://oecd.ai/en/ai-principles
ai実装検定 B級

生成AIパスポート

G検定

DS検定

その他のエッセイはこちら

コメント