
その他のエッセイはこちら

序論:抽象化のジレンマとAttentionの登場
本稿は、自動車業界に従事するエンジニアの視点から、AI技術の中でも特に注目されているAttention機構について、その構造的・機能的意義を探るものである。筆者自身はAIを専門とするわけではないが、車両制御、センサーフュージョン、ドライバー支援技術などに携わる中で、AIの抽象化能力が自動車技術に与える影響の大きさを実感している。
深層学習の発展は、抽象化の技術的進化と密接に関係している。畳み込みニューラルネットワーク(CNN)は局所的な特徴抽出に優れ、全結合層(FC)はグローバルな情報統合を可能にする。しかし、これらはそれぞれに限界を持ち、局所と全体のバランスを取ることは容易ではなかった。
このジレンマを打破したのが、Attention機構である。特にTransformerの登場以降、Attentionは自然言語処理(NLP)をはじめ、画像認識、音声処理、さらには自動運転やドライバー状態推定など、自動車分野にも応用されている。本稿では、AttentionがCNNとFCの「いいとこどり」をしているという仮説を軸に、その構造的・機能的意義を多角的に検討する。
技術的背景:CNN・FC・Attentionの構造比較
畳み込み層(CNN)
CNNは、画像や時系列データなど、局所構造が重要なデータに対して強力な抽象化能力を持つ。畳み込み演算は、カーネル(フィルタ)を用いて入力の局所領域に対して特徴を抽出する。これは空間的な近接性を前提とした構造的バイアス(inductive bias)であり、効率的かつ堅牢な学習を可能にする。
CNNの出力特徴マップの1要素は、以下のように表される:
$$
\begin{equation}
y_{i,j}^{(k)} = \sigma\left( \sum_{m=1}^{M} \sum_{u=1}^{h} \sum_{v=1}^{w} w_{u,v}^{(k,m)} \cdot x_{i+u,j+v}^{(m)} + b^{(k)} \right)
\end{equation}
$$
- $x$ : 入力特徴マップ
- $w$ : カーネル(フィルタ)重み
- $y$ : 出力特徴マップ
- $\sigma$ : 活性化関数(例:ReLU)
- $(i,j)$ : 空間位置
- $(k,m)$ : 出力・入力チャネル
実装例:Sobelフィルタによるエッジ抽出
以下は、Sobelフィルタを用いて画像のエッジを抽出し、Pointwise(1×1)畳み込みでチャネル方向に合成する例である。これはCNNの基本的な処理フローを視覚的に理解するのに有効である。
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import requests
from io import BytesIO
# サンプル画像のURL
image_urls = {
"Dog": "https://raw.githubusercontent.com/eriklindernoren/PyTorch-YOLOv3/master/data/samples/dog.jpg",
"Eagle": "https://github.com/eriklindernoren/PyTorch-YOLOv3/blob/master/data/samples/eagle.jpg?raw=true"
}
# Sobleカーネルの定義
sobel_x = torch.tensor([[[-1., 0., 1.],
[-2., 0., 2.],
[-1., 0., 1.]]])
sobel_y = torch.tensor([[[-1., -2., -1.],
[ 0., 0., 0.],
[ 1., 2., 1.]]])
# Conv2D のウェイト形状に合うように展開: (out_channels, in_channels, H, W)
sobel_x = sobel_x.unsqueeze(0)
sobel_y = sobel_y.unsqueeze(0)
# 畳み込み層の定義
conv_x = nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False)
conv_y = nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False)
conv_x.weight.data = sobel_x
conv_y.weight.data = sobel_y
# Sobel XとYを結合するPointwise convolution
pointwise_conv = nn.Conv2d(2, 1, kernel_size=1, bias=False)
pointwise_conv.weight.data = torch.ones_like(pointwise_conv.weight.data) # PointWiseを加算として実現させるため
# 活性化関数
relu = nn.ReLU()
# 画像処理機能
def process_image(url):
response = requests.get(url)
img = Image.open(BytesIO(response.content)).convert("L")
img = img.resize((256, 256))
img_tensor = torch.tensor(np.array(img), dtype=torch.float32).unsqueeze(0).unsqueeze(0) / 255.0
edge_x = relu(conv_x(img_tensor))
edge_y = relu(conv_y(img_tensor))
combined = pointwise_conv(torch.cat([edge_x, edge_y], dim=1))
return img, edge_x.squeeze().detach().numpy(), edge_y.squeeze().detach().numpy(), combined.squeeze().detach().numpy()
# プロット結果
fig, axes = plt.subplots(2, 4, figsize=(16, 8))
for i, (label, url) in enumerate(image_urls.items()):
original, ex, ey, combined = process_image(url)
axes[i][0].imshow(original, cmap='gray')
axes[i][0].set_title(f"Original - {label}")
axes[i][0].axis('off')
axes[i][1].imshow(ex, cmap='gray')
axes[i][1].set_title("Sobel X")
axes[i][1].axis('off')
axes[i][2].imshow(ey, cmap='gray')
axes[i][2].set_title("Sobel Y")
axes[i][2].axis('off')
axes[i][3].imshow(combined, cmap='gray')
axes[i][3].set_title("Pointwise Combined")
axes[i][3].axis('off')
plt.tight_layout()
plt.show()
Sobel XとYの出力は、それぞれ水平方向・垂直方向のエッジを強調しており、Pointwise畳み込みによってそれらが統合されることで、画像全体の輪郭が抽出される。これはCNNが局所構造を多視点から抽出し、統合する能力を示している。
しかし、CNNは固定されたカーネルサイズと局所受容野を持つため、画像全体の広範な領域における非局所的な依存関係や、遠く離れたオブジェクト間の複雑な関係性を効率的に捉えることは困難である。
全結合層(Fully Connected Layer)
全結合層は、入力の全ての要素に対して重みを持ち、情報を統合する。これは高い表現力を持つ一方で、パラメータ数が膨大になりやすく、過学習のリスクや計算コストの増大を招く。
数式で表すと:
$$
\begin{equation}
\mathbf{y} = \sigma(\mathbf{W} \mathbf{x} + \mathbf{b})
\end{equation}
$$
- $\mathbf{x}$ : 入力ベクトル(例:Flattenされた画像)
- $\mathbf{W}$ : 重み行列
- $\mathbf{b}$ : バイアス項
- $\sigma$ : 活性化関数(例:ReLU)
実装例:MNIST分類タスク
MNIST手書き数字データセットに対して、2層のFC層を用いた分類モデルを構築し、空間構造を無視した全体的な抽象化の効果を確認する。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, random_split
import random
import matplotlib.pyplot as plt
# 再現性のためにランダムシードを設定
torch.manual_seed(42)
# transformの定義
transform = transforms.ToTensor()
# MNISTデータセットをダウンロード&ロード
mnist_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
# 高速なトレーニングのためにサブセットを使用する(例:20000サンプル)
subset_size = 20000
mnist_subset = torch.utils.data.Subset(mnist_dataset, range(subset_size))
# 訓練セットと検証セットに分割(80%訓練、20%検証)
train_size = int(0.8 * subset_size)
val_size = subset_size - train_size
train_data, val_data = random_split(mnist_subset, [train_size, val_size])
# DataLoaderの作成
train_loader = DataLoader(train_data, batch_size=64, shuffle=True)
val_loader = DataLoader(val_data, batch_size=64)
# シンプルな全結合モデルを定義
model = nn.Sequential(
nn.Flatten(),
nn.Linear(28*28, 128),
nn.ReLU(),
nn.Linear(128, 10)
)
# 損失関数とoptimizerを定義
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# トレーニングループ
num_epochs = 5
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for images, labels in train_loader:
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
avg_loss = running_loss / len(train_loader)
print(f"Epoch {epoch+1}/{num_epochs}, Training Loss: {avg_loss:.4f}")
# 検証セットでの評価
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in val_loader:
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = correct / total * 100
print(f"Validation Accuracy: {accuracy:.2f}%")
# 1サンプルで推論&可視化
sample_image, sample_label = val_data[random.randint(0, val_size)]
sample_output = model(sample_image.unsqueeze(0))
predicted_label = torch.argmax(sample_output).item()
plt.figure(figsize=(6, 3))
plt.subplot(1, 2, 1)
plt.title(f"MNIST Digit (True: {sample_label})")
plt.imshow(sample_image.squeeze(), cmap='gray')
plt.axis('off')
plt.subplot(1, 2, 2)
plt.title("Classification Scores")
plt.bar(range(10), sample_output.squeeze().detach().numpy())
plt.xlabel("Digit Class")
plt.ylabel("Score")
plt.suptitle(f"Predicted Label: {predicted_label}")
plt.show()100%|██████████| 9.91M/9.91M [00:00<00:00, 59.9MB/s]
100%|██████████| 28.9k/28.9k [00:00<00:00, 1.65MB/s]
100%|██████████| 1.65M/1.65M [00:00<00:00, 15.6MB/s]
100%|██████████| 4.54k/4.54k [00:00<00:00, 6.01MB/s]
Epoch 1/5, Training Loss: 0.6035
Epoch 2/5, Training Loss: 0.2702
Epoch 3/5, Training Loss: 0.2034
Epoch 4/5, Training Loss: 0.1615
Epoch 5/5, Training Loss: 0.1312
Validation Accuracy: 95.17%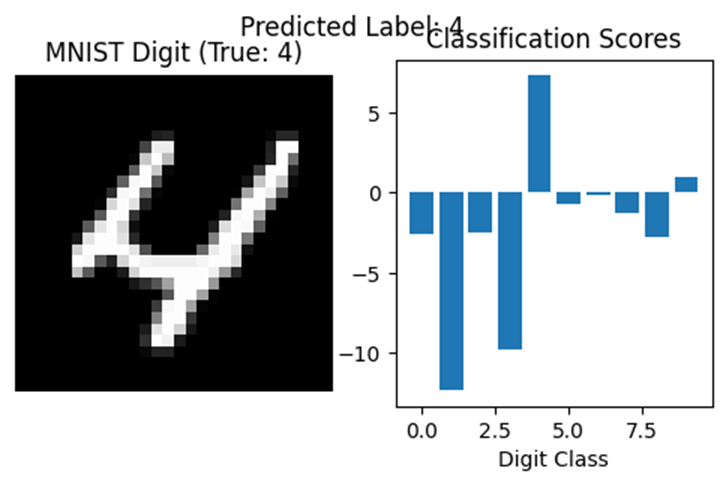
分類スコアのバーグラフを見ると、FC層は画像の空間構造を無視しながらも、全体的なピクセル分布から数字を識別していることがわかる。これは全結合層の強力な抽象化能力を示している。
この高い表現力は、一方で入力の空間的・時間的構造を無視して全ての要素をフラットに扱うため、効率的な特徴抽出が困難であったり、パラメータ数が入力サイズに比例して爆発的に増加するという課題を抱える。
Attention機構
Attentionは、Query・Key・Valueという三つのベクトルを用いて、入力の全ての位置間の関係性を動的に学習する。Scaled Dot-Product Attentionは以下のように定義される:
$$
\begin{equation}
\text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^\top}{\sqrt{d_k}} \right) V
\end{equation}
$$
- $Q$ : Query、$K$ : Key、$V$ : Value (※すべて行列)
- $d_k$ : Keyの次元数(スケーリング因子)
Query ($Q$) は現在の要素が注目したい内容、Key ($K$) は他の要素が持つ情報、Value ($V$) はKeyに対応する実際の情報内容を表します。これらのベクトル間の類似度に基づいて、どの情報にどれだけ注目すべきかを動的に決定する。
この構造は、CNNのような局所性も、FCのような全体性も同時に扱える柔軟な抽象化手法である。
実装例:BERTによるSelf-Attentionの可視化
英語文「The cat sat on the mat.」に対して、BERTモデルのSelf-Attentionがどの単語に注目しているかを可視化することで、文脈的な関係性の抽出を確認する。
#!pip install transformers seaborn
import torch
from transformers import BertTokenizer, BertModel
import matplotlib.pyplot as plt
import seaborn as sns
# 事前に訓練されたBERTモデルとトークナイザをロード
model_name = "bert-base-uncased"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name, output_attentions=True)
# 入力文
sentence = "The cat sat on the mat."
# 入力をトークン化
inputs = tokenizer(sentence, return_tensors="pt")
input_ids = inputs["input_ids"]
# トークン・ラベルの取得
tokens = tokenizer.convert_ids_to_tokens(input_ids[0])
# フォワードパスでattention weightsを取得
with torch.no_grad():
outputs = model(**inputs)
# 特定のレイヤーとヘッドからAttentionを引き出す
layer_index = 0 # first layer
head_index = 0 # first attention head
attention = outputs.attentions[layer_index][0, head_index] # shape: (seq_len, seq_len)
# Attentionのヒートマップをプロットする
plt.figure(figsize=(8, 6))
sns.heatmap(attention.numpy(), xticklabels=tokens, yticklabels=tokens, cmap="Blues", annot=True, fmt=".2f")
plt.title(f"Attention Weights - Layer {layer_index+1}, Head {head_index+1}")
plt.xlabel("Key")
plt.ylabel("Query")
plt.xticks(rotation=45)
plt.yticks(rotation=0)
plt.tight_layout()
plt.show()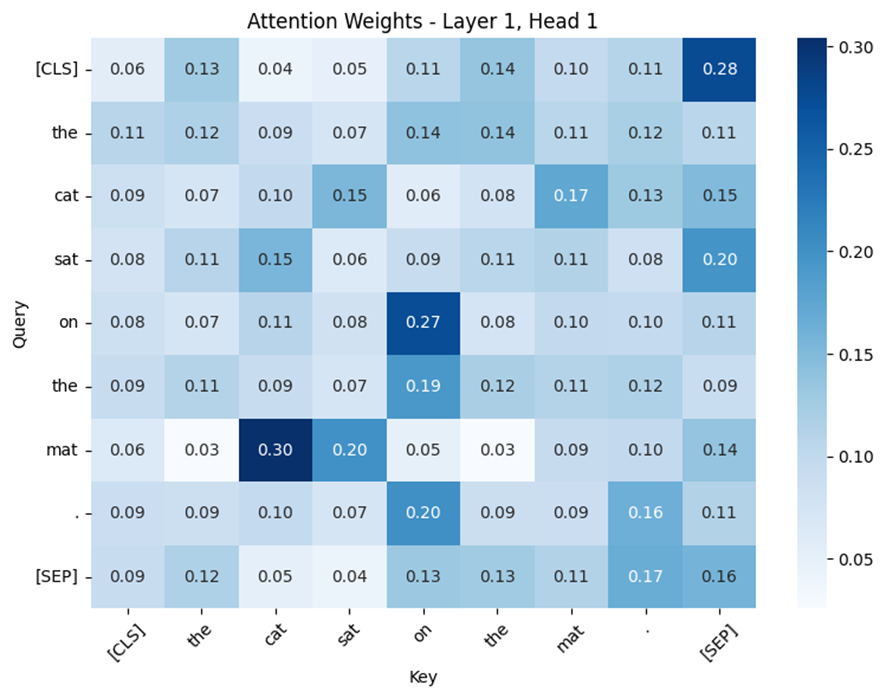
このAttentionマップは、各単語が文中のどの単語に注目しているかを示している。例えば、「cat」が「sat」や「mat」に強く注目している。これは文脈的な関係性(主語と動詞、対象物)を捉えていることを意味する。
このような動的な関係性の抽出は、CNNのような固定的な局所処理や、FCのような一様な全体処理では困難である。Attentionは、局所と全体の抽象化を文脈に応じて融合するという点で、知能モデルの新たな地平を切り開いている。
抽象化の融合:Attentionの「いいとこどり」性の検証
Attentionは構造的には全位置と全位置を結びつけるが、学習された重みは層によって局所的または大域的な傾向を持つ。特に浅層では近接語への強い注意が現れやすく、これは結果としてCNN的局所性を獲得しているように見える。
自動車分野では、例えばセンサーフュージョンにおいて、LiDAR・カメラ・レーダーなど異なるセンサーから得られる情報を、状況に応じて動的に統合する必要がある。Attentionは、これらのセンサー間の信頼度や文脈的関連性を学習し、柔軟に重み付けすることで、環境認識の精度を向上させる。
また、周辺物体の関係性認識においても、Attentionは有効である。例えば、交差点で歩行者が横断しようとしているかどうかを判断するには、歩行者と車両、信号機との関係性を文脈的に理解する必要がある。これは、単なる物体検出ではなく、意味的な関係性の抽象化が求められる場面である。
さらに、近年登場したConformer(音声処理)やCoAtNet(画像認識)などのハイブリッドモデルは、AttentionがCNNの局所抽象化を補完・拡張できることを示している。これらのモデルでは、畳み込みによる局所的な前処理と、Attentionによるグローバルな文脈理解が組み合わされており、抽象化の融合が実現されている。
このように、Attentionは単なる「全体処理」ではなく、文脈に応じて局所と全体を動的に切り替える能力を持つ。これは、従来の手法では困難だった抽象化の柔軟性を提供するものであり、知能モデルの進化において重要なステップである。
応用事例:Attentionの実力を示す領域横断的成功例
Attention機構は、自然言語処理(NLP)を皮切りに、画像・音声・生物学・ロボティクスなど、多様な分野で成功を収めている。以下に代表的な応用例を示す。
自然言語処理(NLP)
- BERT:文中の単語間の依存関係を捉えることで、文脈理解に優れる。
- GPTシリーズ:文の冒頭と末尾の関係性を保持したまま、自然な文章生成が可能。
画像処理
- Vision Transformer (ViT):画像をパッチに分割し、トークンとして扱うことでCNNに依存せず高精度な認識を実現。
- Segment Anything Model (SAM):任意の領域を柔軟に抽出する画像セグメンテーションモデル。
音声処理
- WhisperやSpeech Transformer:音声信号の時間的依存性を捉え、ノイズ耐性や長距離依存の処理に優れる。
その他の分野
- AlphaFold:タンパク質構造予測にAttentionを活用。
- 医療画像解析:病変部位の検出や診断支援に応用。
- ロボティクス:動作計画や環境理解における関係性抽出に貢献。
自動車分野における応用
- センサーフュージョン:マルチモーダルAttentionにより、異なるセンサー情報を動的に統合。例:夜間はレーダー重視、昼間はカメラ重視。
- ドライバー状態推定:視線追跡や顔表情から、注意散漫・眠気などを検出。Attentionにより、視線の動きと顔の変化の関係性を抽象化。
- 車載カメラ映像解析:Vision Transformerを用いて、危険予兆(例:飛び出し)を検出。Attentionにより、映像内の重要領域に焦点を当てる。
- 経路計画とナビゲーション:地図情報、交通状況、目的地の優先度などを統合し、文脈に応じた経路選択を実現。
これらの応用は、Attentionが「意味的関係性の抽出」に優れていることを示しており、自動車技術においてもその価値は極めて高い。
批判的視点:Attentionの限界と課題
Attentionは非常に強力な手法である一方で、いくつかの課題も抱えている。特に自動車分野では、リアルタイム性と計算資源の制約が大きな課題となる。
計算コストとメモリ使用量
Attentionは非常に強力な手法である一方で、いくつかの課題も抱えている。特に自動車分野では、リアルタイム性と計算資源の制約が大きな課題となる。
- Attentionは $O(n^2)$ の計算量を要するため、車載環境では非効率。
- Sparse AttentionやPerformerなどの効率化手法が注目されている。
- また、CNNのような空間的制約(構造的バイアス)がないため、学習が不安定になることもある。
これらの課題に対して、ConformerやCoAtNetのようなハイブリッドモデルが、自動車分野でも有望視されている。
歴史的・哲学的考察:抽象化の進化と知能の本質
人間の認知においても、「注意(Attention)」は重要な役割を果たす。心理学ではSelective Attentionが情報処理の効率化に寄与するとされ、神経科学では、脳の前頭葉が注意の制御に関与していることが知られている。
自動車分野においても、ドライバーの注意行動は安全運転の鍵であり、AIによる模倣が進んでいる。例えば、視線追跡によって「どこに注意を向けているか」をモデル化することで、注意散漫や危険予兆を検出する技術が開発されている。
AIにおけるAttentionは、これらの人間の認知機能を数理的に再構成したものであり、知能の構造化手法としての位置づけが重要である。
認知科学との比較:人間の注意とAIのAttention
人間の注意は、感覚入力の洪水の中から意味ある情報を選択的に抽出するフィルタ機能を持つ。これは、意識的・無意識的な制御のもとで、目的や感情、記憶などに基づいて動的に変化する。一方、AIのAttentionは、学習された重みによって入力間の関係性を数理的に評価するものであり、選択性と可塑性という点では類似しているが、意識や動機といった内的要因は存在しない。
この違いは、AIが「意味を理解している」のではなく、「意味的関係を数理的にモデル化している」ことを示している。Attentionは、意味の操作ではなく構造の操作であるという哲学的区別が重要である。
進化論的意義:注意は知能の起源か?
注意は、進化的に見ても非常に初期から存在する認知機能であり、昆虫や魚類などにも観察される。これは、環境中の脅威や餌などの重要な情報に素早く反応するための適応機能であり、知能の前提条件とも言える。
AIにおけるAttention機構は、この進化的注意の数理的再構成であり、知能の進化を模倣する重要なステップである。情報の洪水の中から意味ある関係性を抽出する能力は、まさに生物が生存のために獲得してきた認知戦略と通底している。
注意と意識の関係:AIは「意識」を持つか?
哲学的には、「注意」と「意識」は密接に関係している。多くの理論では、注意が意識の前提条件であるとされる(例:Global Workspace Theory)。人間の場合、注意を向けた対象が意識に上るが、AIの場合、Attentionは重みの分布として表現されるだけであり、「意識」は存在しない。
この違いは、AIが「知能らしさ」を持っていても、「意識らしさ」は持たないことを示している。Attentionは、意識の模倣ではなく、意識的処理の一部機能を数理的に再現したものに過ぎない。
Attentionは「知能の構造化」か「意味の構造化」か?
Attentionを「知能の構造化手法」として捉えるか、「意味の構造化手法」として捉えるかによって、AIの未来像が変わる。前者は、情報の関係性を数理的に整理する技術としての位置づけであり、後者は、文脈や目的に応じた意味の抽出を可能にする認知的モデルとしての位置づけである。
この両面性こそが、Attentionの哲学的魅力であり、AIが人間のような柔軟な知能に近づくための鍵となる。
結論:Attentionは抽象化の融合体である
本稿では、Attention機構が畳み込みニューラルネットワーク(CNN)の持つ局所抽象化と、全結合層(FC)の持つ全体抽象化の「いいとこどり」をしているという仮説を軸に、多角的な検証を行った。技術的構造の比較、実装例の提示、応用事例の紹介、批判的視点の整理、そして哲学的考察に至るまで、Attentionの本質を多層的に掘り下げた結果、抽象化の融合体としての意義が理論的にも実践的にも支持されることが明らかとなった。
特に、自動車分野においては、センサーフュージョン、ドライバー状態推定、車載映像解析など、Attentionの柔軟な抽象化能力が安全性・効率性の向上に貢献している。今後は、計算資源とのトレードオフを考慮した効率化や、構造的バイアスの再導入、さらにはマルチモーダル統合などの新たな課題に対して、Attentionの柔軟性が試されることになるだろう。
Attentionは、技術と知能の本質をつなぐ架け橋であり、AIが人間の認知に近づくための重要なステップである。そして、自動車技術においても、より安全で賢い車両知能の実現に向けた鍵となる。
参考文献
- Vaswani, A. et al. (2017). Attention Is All You Need. arXiv:1706.03762
- Gulati, A. et al. (2020).Conformer: Convolution-augmented Transformer for Speech Recognition. arXiv:2005.08100
- Dai, Z. et al. (2021). CoAtNet: Marrying Convolution and Attention for All Data Sizes. arXiv:2106.04803
- Devlin, J. et al. (2019).BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv:1810.04805
- Dosovitskiy, A. et al. (2021).An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale. arXiv:2010.11929
- Kirillov, A. et al. (2023). Segment Anything. arXiv:2304.02643
その他のエッセイはこちら


コメント