
カテゴライズの仕方
というわけでカテゴライズの仕方の話になる。
究極カンペの作り方の動画の時は、公式テキストにそってカテゴライズする説明にしている。
ただ、昨今だとシラバスがかなり整備されてきているため、
シラバスを元にカテゴライズする方がより適切なはず。
公式テキストもシラバスに沿ったものになっているはずなので、どちらを選んでも良いはずだが、
このシリーズとしてはシラバスに沿った分け方をベースとする。
ちなみに、2024年に改定されたシラバスだとこのような感じ。
シラバスの改定としてはおそらく2回目で、かなり洗練されたものと言える。
比較的全体像が分かりやすい検定になってきている。
カテゴライズの詳細化
先ほど、シラバスによるカテゴライズの話をしたが、
実はシラバスのカテゴライズではやや詳細度が不足している面もある。
つまり、シラバスでは一つのカテゴリだけど、もうちょっと分けた方が良い。
具体例を出すと・・・。
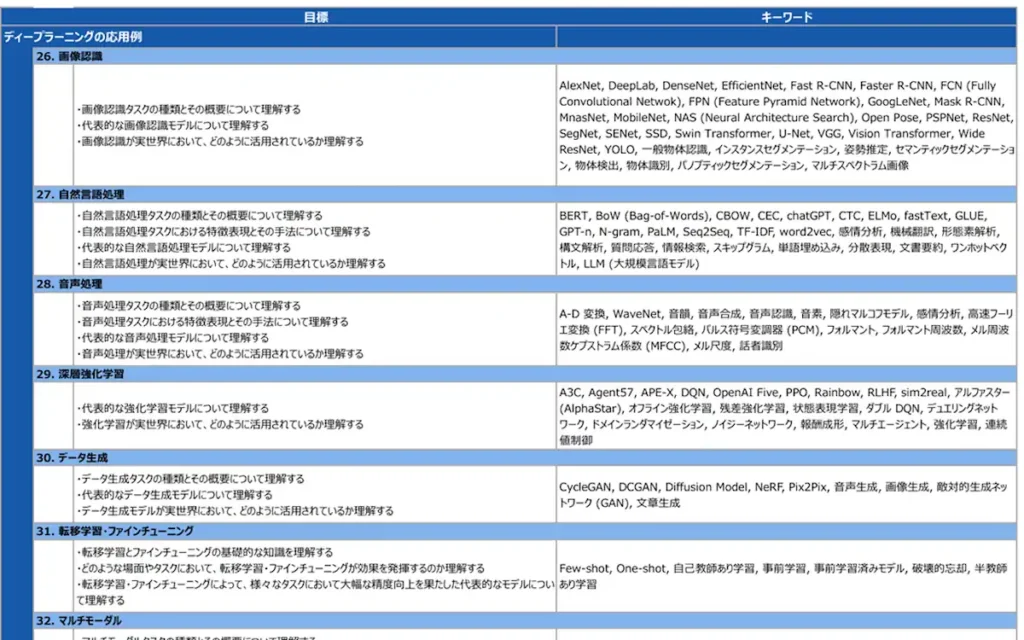
例えば、ディープラーニングの応用例の中の画像認識のカテゴリを見てみる。

キーワードの列に多くの用語が入っているのだが、それぞれ性質が異なるものが多い。
これを私なりに分けるみる。
- 一般物体認識
- AlexNet, VGG, GoogLeNet, ResNet, DenseNet, MobileNet, NAS, SENet, MnasNet, EfficientNet, Vision Transformer, Wide ResNet, Swin Transformer
- 物体検出
- Fast R-CNN, Faster R-CNN, YOLO, SSD
- セマンティックセグメンテーション
- FCN, U-Net, SegNet, DeepLab, PSPNet
- インスタンスセグメンテーション
- Mask R-CNN
- パノプティックセグメンテーション
- FPN
- 姿勢推定
- Open Pose
物体認識、物体検出、セグメンテーション、姿勢推定など、異なる領域がまぜこぜではある。
画像をインプットとするという意味では一緒だが、同一のカテゴリとされるとちょっと辛い。
物体検出やセグメンテーションも、内部的には物体認識の技術要素を入れ込んでいるため、
同一カテゴリであっても妥当とは言えるのだが、
初学者からすると少し厄介なまとめ方ではある。
因果関係
それでは、因果関係の例も示しておく。
先ほどの、一般物体認識ってところが結構用語が多かったので、ここの因果関係を出してみる。
こんな感じの因果関係になる
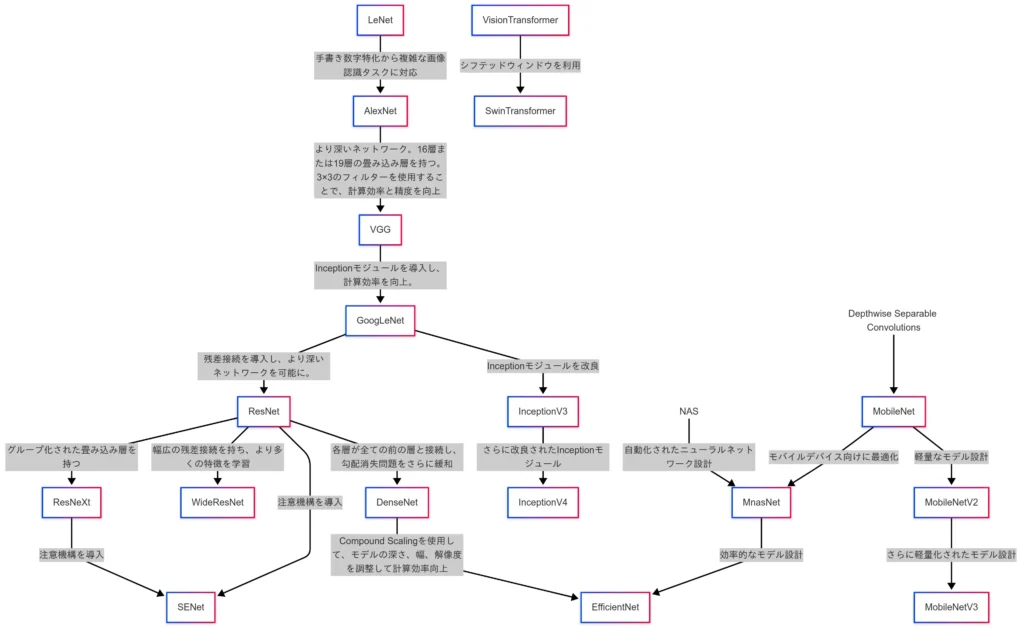
(むっちゃややこしいことになっている・・・。)
これを見ると、確かに用語レベルで暗記しても勉強したことにはならなそうと思った人はそこそこいるではなかろうか?
別にこれを把握していなければならないってことはないから、それほど心配する必要はない。
ただ、これを自分で書けた方がいろいろと話が早いってのはある。
この関係図を簡単に説明すると・・・。
まずは、LeNetやAlexNetを起点とした、層やパラメータ数を増やすことで性能を引き上げていた時代。
そして、ResNetを皮切りとして、残差ブロックを導入することで深層化に成功した時代。
さらにDepthwise Separable Convolutionにより、畳み込み層の計算量を大幅に減らし、
モバイルデバイスに対応した時代。
ほぼ同時期にはなるけど、NASによりアーキテクチャを自動設計した時代。
Transformerを自然言語タスクからビジョンタスクにも転用した時代。
という分け方が代表的。
これを究極カンペに反映できればさらに究極化されるってことになる。
情報量としてはそれほど多くないから、暗記って感じもしないでしょう。(たぶん?)


コメント