
「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
バックナンバーはこちら

はじめに
「G検定対策 究極カンペをつくろう」
シリーズ3作目になる。
前回は画像認識の因果関係を整理した。
AlexNetから始まって、CNNの進化がヤバかった・・・。
今回は自然言語処理の技術体系を因果関係で整理していく。
形態素解析とかTF-IDFとか、昔からあるやつも出てくるし、
最近はLLMとかChatGPTとか、進化が激しい。
(進化が激しいってことは、沼も深い・・・)
動画シリーズ
G検定の究極カンペ関連動画の再生リスト

説明内容
今回の説明内容を記載しておく。
- 基盤技術(形態素解析・構文解析)
- テキスト表現(BoW、word2vec、ELMoなど)
- モデルアーキテクチャ(Seq2Seq、Transformer)
- 言語モデル(BERT)
- LLM(GPT、ChatGPT、PaLMなど)
- 応用タスク
- まとめ
自然言語処理の全体像を因果関係で整理する感じになる。
例によって用語の意味は別途調べることを推奨。
ここでは「つながり」に注目する。
そして因果関係図全体像はこれになる。
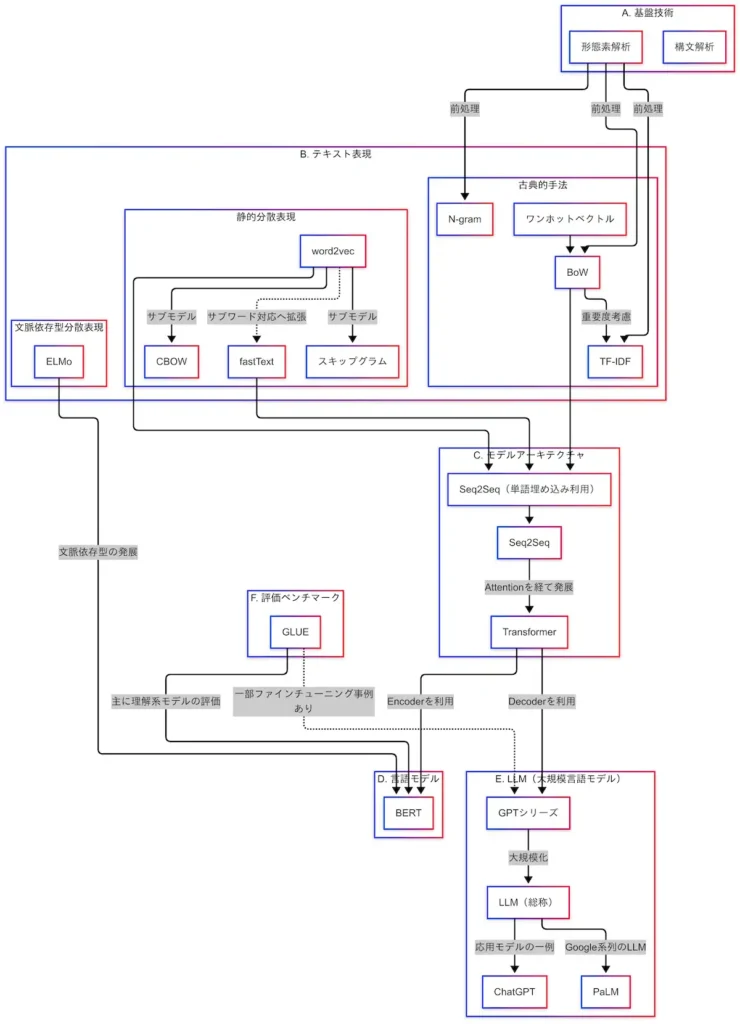
(今回もむっちゃ細かい・・・)
基盤技術
自然言語処理における最初のステップは、形態素解析と構文解析である。これらは、すべての処理の土台となる技術であり、精度が低ければ後続の工程にも悪影響を及ぼす。
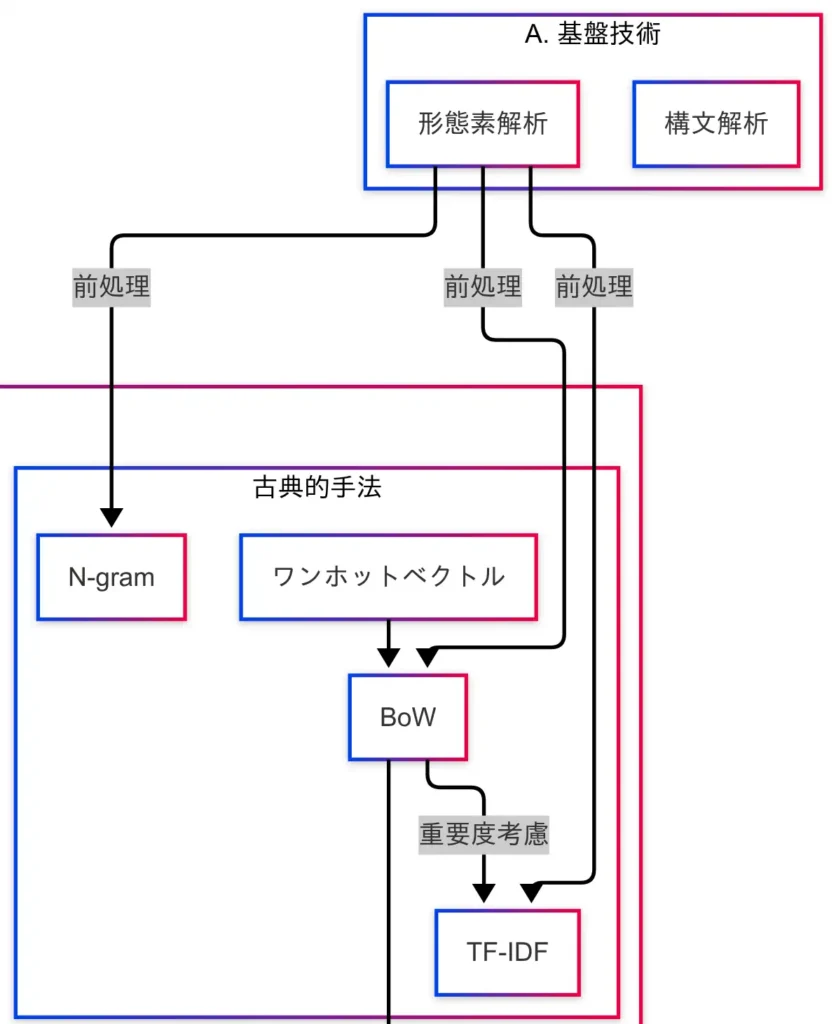
形態素解析とは、文章を単語に分割する処理である。一方、構文解析は文の構造を解析する技術であり、主語・述語・目的語などの関係性を明らかにする。
形態素解析は、文章を「意味を持つ最小単位」に分割するものである。特に日本語の場合、単語の境界が曖昧であるため、英語よりも解析が困難である。
例えば、「私は学校へ行きます」という文は、以下のように分割される。
「私」「は」「学校」「へ」「行き」「ます」
このように、助詞や動詞の活用も正確に分けられる。
形態素解析には、MeCabやJuman++といった解析器が存在する。これらの解析結果は、BoWやTF-IDFなどのテキスト表現手法の入力として利用される。したがって、形態素解析の精度が低い場合、後続の表現もすべて誤ってしまう。
構文解析は、文の構造を解析する技術であり、係り受け解析とも呼ばれる。文の意味を理解するためには不可欠な処理である。
例えば、「太郎が花子に本を渡した」という文では、以下のような関係が抽出される。
「太郎 → 渡した」「渡した → 本」「渡した → 花子」
構文解析があることで、単語の並びだけでなく、意味のつながりを把握することが可能となる。
この構造情報は、文脈依存型のモデルや文の意味理解に優れたモデルにおいて、特に重要な役割を果たす。因果関係図を参照すると、形態素解析はBoW、TF-IDF、N-gramなどの古典的手法の前処理として位置づけられている。すなわち、テキスト表現の出発点は形態素解析である。
構文解析は因果関係図上では直接的な接続が示されていないが、文の構造を扱うモデルにおいては、裏で活用されている。特にSeq2SeqやTransformerのように文全体の意味を扱うモデルでは、構文解析の結果が暗黙的に反映されていることが多い。
形態素解析と構文解析は、自然言語処理の「土台」である。これらがしっかりしていなければ、どれほど高度なモデルであっても、意味のある出力を得ることはできない。
テキスト表現
次に扱うのはテキスト表現である。代表的な手法として、BoW、TF-IDF、word2vec、ELMoなどが挙げられる。
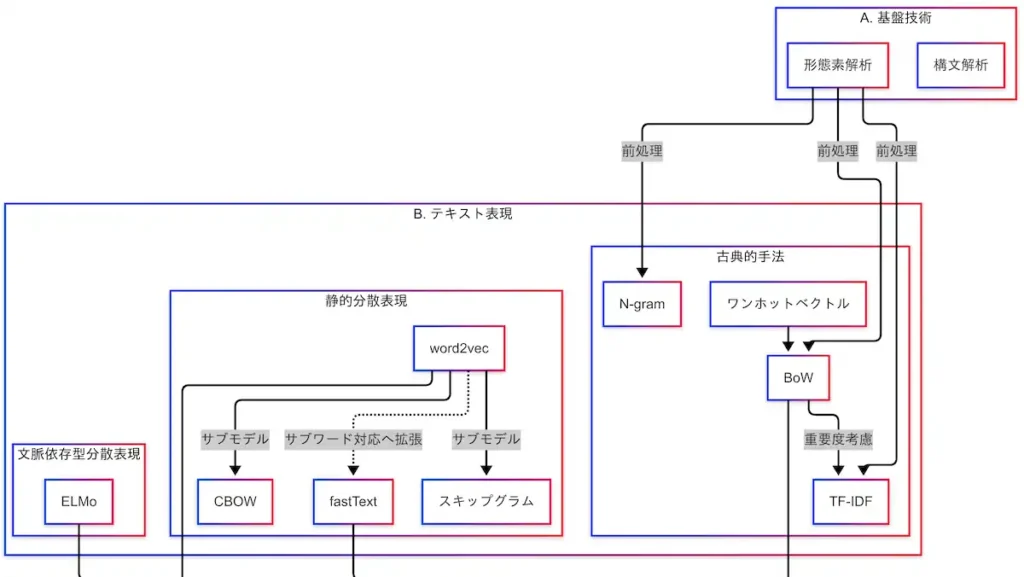
テキスト表現とは、自然言語を数値ベクトルに変換する技術である。この変換が適切に行われなければ、モデルは何も学習できない。すなわち、ここが「言語を機械に理解させる」最初のステップである。
BoW、TF-IDF、N-gram
BoW(Bag of Words)は、文章を単語の集合として扱い、各単語の出現頻度をベクトル化する手法である。文脈は考慮されないが、シンプルかつ高速である。
TF-IDFは、頻出単語の重みを軽くし、希少な単語の重みを重くする手法である。TF(Term Frequency)とIDF(Inverse Document Frequency)を掛け合わせることで、「その文書において重要と思われる単語」に重みを付ける。
N-gramは、隣接する単語をセットで扱う手法である。「自然 言語」「言語 処理」のように、2語や3語の組み合わせで特徴を捉える。文脈をある程度考慮できるが、語順が固定されるため限界も存在する。
因果関係図を見ると、形態素解析の結果がBoW、TF-IDF、N-gramの入力として使われている。したがって、前処理が不正確であれば、これらの表現も誤ってしまう。
BoWからTF-IDFへと進化し、N-gramによって文脈を部分的に考慮する流れが形成されている。
word2vec、fastText
word2vecは、単語の意味をベクトル空間に埋め込む技術である。「王様 – 男 + 女 = 女王」のような意味的な計算が可能であることが特徴である。
word2vecには2つの学習方式がある。CBOWは周囲の単語から中央の単語を予測し、スキップグラムは中央の単語から周囲の単語を予測する。
fastTextは、サブワード(部分単語)を考慮することで、未知語にも強い表現を可能にする。「自然言語処理」という単語を知らなくても、「自然」「言語」「処理」という構成要素から意味を推測できる。
因果関係図では、word2vecからCBOWとスキップグラムが派生し、さらにfastTextがサブワード対応として進化している様子が示されている。これらはBoWやTF-IDFよりも意味を捉える力が強いが、文脈の考慮はされていない。
ELMo
文脈を考慮する表現として登場したのがELMoである。ELMoは、文脈によって単語の意味が変化することを前提とした技術である。
例えば、「bank」という単語は、「川岸」か「金融機関」か、文脈によって意味が異なる。ELMoはその文脈を考慮し、単語のベクトルを動的に変化させる。すなわち、同じ単語でも使われ方によってベクトルが変わるのである。
ELMoは、文脈依存型の先駆けとして、後のBERTのような言語モデルの基礎となっている。
テキスト表現は、BoWのような単純な手法から始まり、word2vecによって意味を捉え、ELMoによって文脈を考慮するように進化してきた。単語を数えるだけの時代から、意味や文脈まで考える時代へと移り変わってきたのである。
この進化は、モデルの性能にも直結している。BoWだけでもある程度の自然言語処理は可能であるが、文脈が絡むタスクにおいては限界がある。
テキスト表現は、BoWのような単純な手法から始まり、word2vecによって意味を捉え、ELMoによって文脈を考慮するように進化してきた。単語を数えるだけの時代から、意味や文脈まで考える時代へと移り変わってきたのである。
この進化は、モデルの性能にも直結している。BoWだけでもある程度の自然言語処理は可能であるが、文脈が絡むタスクにおいては限界がある。
モデルアーキテクチャ
次に扱うのはモデルアーキテクチャである。これは自然言語処理における「頭脳」に相当する部分であり、どのような表現を用いて、どのように処理するかを決定する役割を担っている。
-729x1024.webp)
モデルアーキテクチャが賢くなければ、どれほど優れた表現を用いても、意味のある出力は得られない。
Seq2Seq:系列変換の基本構造
Seq2Seq(Sequence to Sequence)は、入力と出力の両方が系列であるモデルである。例えば、英語から日本語への翻訳のように、入力文をエンコードし、出力文をデコードする構造を持つ。
このモデルは、エンコーダとデコーダの2つの構成要素から成り立っている。
しかし、長い文を扱う際には、情報が途中で失われるという課題が存在する。
Attention:重要語への注目機構
この課題を解決するために登場したのがAttention機構である。Attentionは、入力文の中でどの単語が出力に影響するかを動的に計算する技術である。
これにより、長文であっても意味を保ったまま翻訳が可能となった。人間が話を聞く際に、重要な部分だけを記憶するのと似た仕組みである。
Transformer:並列処理と精度向上の革新
Attentionの登場を契機として、次に進化したのがTransformerである。Transformerは、Attentionを全面的に活用したモデルであり、RNNやLSTMのような逐次処理構造を排除し、すべての単語を一括で処理することで、並列化と精度向上を実現した。
その結果、学習速度が向上し、長文への対応力も強化された。
Transformerは、EncoderとDecoderに分かれており、EncoderはBERTに、DecoderはGPTに応用されている。
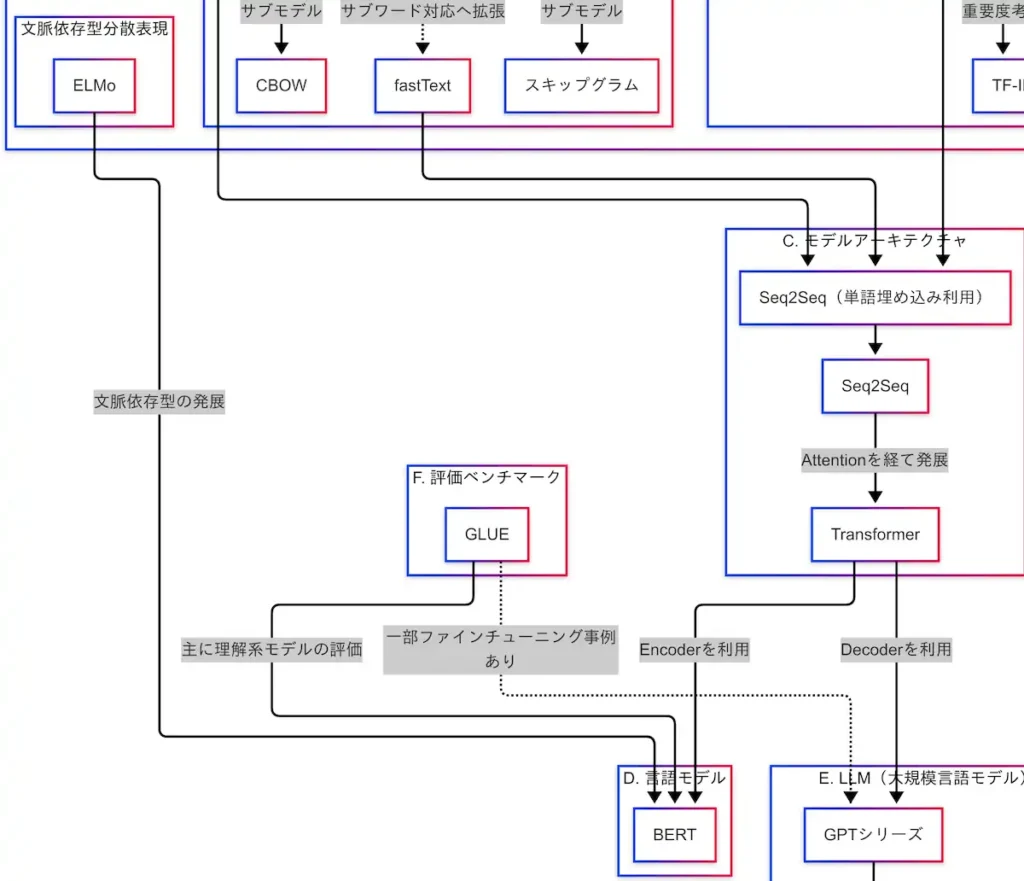
因果関係図による技術の流れ
因果関係図を参照すると、BoWやword2vecなどの表現がSeq2Seq(単語埋め込みを利用)に接続され、そこからAttentionを経てTransformerへと進化している。
さらに、TransformerからはBERTとGPTに分岐し、それぞれがLLM(大規模言語モデル)へとつながっている。
このように、モデルアーキテクチャの進化は、言語モデルの進化に直結している。
モデルアーキテクチャは、Seq2Seq → Attention → Transformerという流れで進化してきた。この進化によって、自然言語処理の性能は飛躍的に向上した。
かつては逐次処理が主流であったが、現在では並列処理によって効率と精度の両立が可能となっている。Attentionの導入によって、文脈理解も大きく進化した。
Transformerの登場以降、自然言語処理はまさに「沼」の領域へと突入したと言える。
言語モデル
言語モデルとは、自然言語処理において文章の意味を理解する役割を担う技術である。分類、質問応答、感情分析など、意味に基づく処理を行うための中核的な存在である。
この領域において代表的なモデルがBERTである。
BERT:双方向文脈理解の革新
BERT(Bidirectional Encoder Representations from Transformers)は、TransformerのEncoder部分のみを用いたモデルである。従来のモデルが左から右、あるいは右から左といった一方向の文脈しか扱えなかったのに対し、BERTは前後の文脈を同時に考慮することが可能である。
例えば、「はし」という単語は、「川のはしに座る」と「はしで寿司を食べる」では意味が異なる。BERTはこのような文脈の違いを捉え、適切な意味を理解することができる。
文脈依存型のモデルがなければ、すべての「はし」が「箸」と解釈されるような誤りが生じる。BERTはこの問題を解決するために設計された。
学習プロセス:事前学習とファインチューニング
BERTは、事前学習(Pre-training)とファインチューニング(Fine-tuning)の2段階で学習される。
- 事前学習では、大量のテキストを用いて以下の2つのタスクを実施する:
- Masked Language Modeling(MLM):文中の一部の単語をマスクし、それを予測する
- Next Sentence Prediction(NSP):2つの文が連続しているかどうかを判定する。
この段階で、言語の構造や意味に関する一般的な知識を獲得する。
- ファインチューニングでは、分類・質問応答・感情分析など、特定のタスクに合わせてモデルを調整する。
GLUE:性能評価のベンチマーク
BERTの性能は、GLUE(General Language Understanding Evaluation)というベンチマークによって評価される。GLUEは、文の分類、類似度判定、自然言語推論など、自然言語理解に関する複数のタスクを含む評価セットである。
BERTはこれらのタスクにおいて高いスコアを記録しており、その読解力の高さが実証されている。
因果関係図における位置づけ
因果関係図を確認すると、TransformerのEncoderがBERTに接続されており、さらにそのBERTがGLUEによって評価されている構造が見て取れる。
また、文脈依存型表現の先駆けであるELMoからの技術的進化の延長線上に、BERTが位置づけられている。
言語モデルは、自然言語の意味を理解するための「頭脳」である。その中でもBERTは、双方向の文脈を同時に捉えることで、自然言語理解の性能を大きく引き上げたモデルである。
事前学習によって言語の感覚を身につけ、ファインチューニングによって実務的なタスクに対応する。GLUEによる評価を通じて、その実力が客観的に示されている。
Transformerの構造を活かしたBERTは、理解系モデルの代表格として、自然言語処理の発展に大きく貢献している。
LLM(大規模言語モデル)
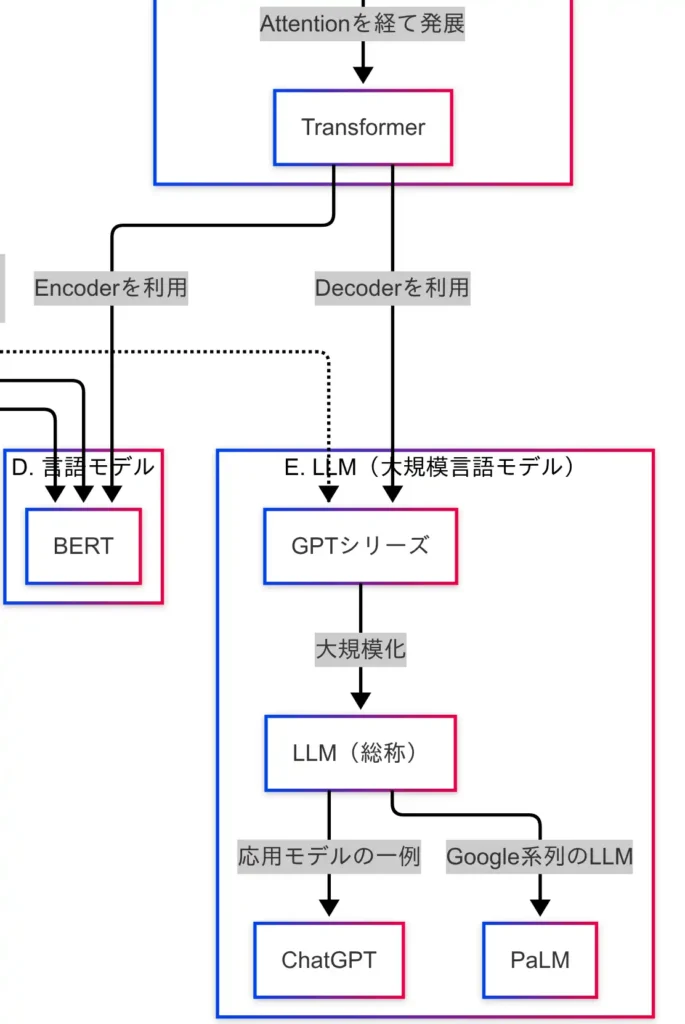
LLM(Large Language Models)は、自然言語処理の総合力を飛躍的に高めた技術である。膨大なパラメータとデータを用いて学習することで、文章の生成・理解・要約・翻訳など、幅広いタスクに対応可能となった。
現在のAIブームの中心に位置する技術であり、その代表格がGPTシリーズである。
GPT:生成特化型の言語モデル
GPT(Generative Pre-trained Transformer)は、TransformerのDecoder部分を活用したモデルである。「次に来る単語を予測する」ことで文章を生成する構造を持ち、左から右へと順番に処理を行う。
この構造により、自然な文章生成が得意であり、BERTが理解型であるのに対し、GPTは生成型のモデルである。
GPTは、GPT-2 → GPT-3 → GPT-4と進化を重ねており、モデルの規模と性能は年々向上している。例えば、GPT-3は1750億パラメータを持ち、GPT-4ではさらに増加している。学習データもインターネット全体レベルに及び、言語だけでなく、知識や推論まで含まれている。
このような大規模化が、性能向上に直結している。
応用モデル:ChatGPTとPaLM
ChatGPTは、GPTをベースに対話データを追加学習したモデルである。人間らしい応答が可能となるよう調整されており、実用性の高い対話型AIとして広く利用されている。
一方、PaLM(Pathways Language Model)はGoogle系列のLLMであり、Transformerベースの構造を持つ。多言語・多タスクに対応する汎用モデルとして開発されており、GPTとは異なるアプローチで競争を繰り広げている。
このように、LLMはGPTだけでなく、PaLMやClaudeなど、複数のモデルが進化を続けている。
因果関係図における位置づけ
因果関係図を確認すると、TransformerのDecoderがGPTに接続されており、そこからLLM(総称)へと進化し、さらにChatGPTやPaLMなどの応用モデルが派生している。
理解系モデルの評価にはGLUEが用いられるが、GPTのような生成系モデルでは評価軸が異なる点にも留意すべきである。
LLMは、自然言語処理の枠を超え、知識・推論・対話・創造までこなす汎用AIに近づいている技術である。Transformerの力を最大限に引き出した結果が、LLMの登場であり、その進化は今後も続くと考えられる。
GPTをはじめとするLLMは、自然言語処理の可能性を大きく広げており、今や社会のさまざまな場面で活用されている。
応用タスク
自然言語処理(NLP)は、単なる研究対象にとどまらず、実際の業務やサービスに応用されている技術である。本章では、代表的な応用タスクと、それぞれに対応するモデル・手法を整理する。
以下に、主な応用タスクと対応モデルをまとめた。
| 応用タスク | 主なモデル・手法 | 備考 |
|---|---|---|
| 感情分析 | BERT、RoBERTa、LSTM、SVM + TF-IDF | 文の極性(ポジ/ネガ)を分類 |
| 機械翻訳 | Seq2Seq、Transformer、MarianMT、mBART | 多言語対応モデルも多数 |
| 質問応答 | BERT(SQuAD)、ALBERT、T5、ChatGPT | 文脈理解と抽出が重要 |
| 情報検索 | BM25、Dense Retriever(DPR)、ColBERT、RAG | 検索+生成のハイブリッドも |
| 文書要約 | T5、BART、PEGASUS、GPT系 | 抽象型と抽出型の2種類あり |
感情分析
感情分析は、SNSやレビューなどのテキストから、ポジティブかネガティブかといった感情の極性を判定するタスクである。近年では、BERTやRoBERTaといった文脈理解に優れたモデルが主流となっている。かつてはTF-IDFとSVMを組み合わせた古典的手法が多く用いられていたが、現在は深層学習ベースの手法が主流である。
機械翻訳
機械翻訳は、自然言語処理の中でも歴史のある応用分野である。Seq2Seqによって実現され、Transformerの登場により精度が飛躍的に向上した。MarianMTやmBARTのような多言語対応モデルは、1つのモデルで複数言語間の翻訳を可能にしている。
質問応答
質問応答は、単なる情報検索とは異なり、文中から答えそのものを抽出することを目的とするタスクである。BERTはSQuADというデータセットで訓練されており、文脈を理解した上で正確な回答を導き出すことができる。
一方、ChatGPTのようなモデルは、抽出ではなく生成型の質問応答を行う。文脈を踏まえた自然な応答が可能であり、対話型AIとしての応用が進んでいる。
情報検索
情報検索は、関連する文書を探し出すタスクである。BM25のような古典的手法に加え、Dense RetrieverやColBERTといったベクトル検索技術が登場しており、検索精度の向上が図られている。
さらに、RAG(Retrieval-Augmented Generation)のように、検索と生成を組み合わせたハイブリッド型のアプローチも注目されている。
文書要約
文書要約は、長文を短く要約するタスクであり、抽出型(重要文を抜き出す)と抽象型(新たな文を生成する)の2種類が存在する。T5、BART、PEGASUSなどが代表的なモデルであり、GPT系モデルは自然な抽象型要約に強みを持つ。
論文やニュース記事の要約など、実務での活用が進んでいる分野である。
自然言語処理は、感情分析・翻訳・質問応答・検索・要約といった多様な応用タスクを通じて、実社会に深く根ざした技術となっている。それぞれのタスクには特化したモデルが存在し、モデルの構造や学習方法によって得意分野が異なる。
自然言語処理は、もはや専門家だけのものではなく、日常生活やビジネスの現場においても身近な存在となっている。
まとめ
本記事では、自然言語処理の技術体系を因果関係に基づいて整理した。単語の分割から始まり、意味の理解、文の生成、そして実務への応用まで、各技術が連続的に発展していることが明らかとなった。
まずは基盤技術として、形態素解析と構文解析の重要性を確認した。これらは前処理として機能し、精度が低ければ後続の処理すべてに影響を及ぼす。自然言語処理の土台として不可欠な技術である。
次にテキスト表現の進化を辿った。BoWから始まり、TF-IDF、word2vec、ELMo、そしてBERTへと発展してきた。単語の出現頻度を数えるだけの時代から、意味や文脈を捉える時代へと移行している。
モデルアーキテクチャでは、Seq2SeqからAttention、そしてTransformerへの進化が鍵となった。Attentionの導入により文脈理解が飛躍的に向上し、Transformerによって並列処理と精度向上が実現された。
言語モデルの領域では、BERTが文脈理解の代表として登場し、GLUEによる評価を通じてその性能が実証された。文脈を双方向から捉えることで、自然言語理解の精度が大きく向上した。
さらに、LLM(大規模言語モデル)では、GPTシリーズやChatGPT、PaLMなどが登場し、言語モデルの枠を超えた汎用AIとしての可能性が示された。生成能力、知識、推論、対話など、多様な能力を統合したモデルである。
最後に、応用タスクとして、感情分析・機械翻訳・質問応答・情報検索・文書要約など、実務に直結する技術を整理した。それぞれのタスクに特化したモデルが存在し、構造や学習方法によって得意分野が異なる。
自然言語処理の技術は、単なる用語の暗記ではなく、「何を解決するために生まれた技術か」という視点で理解することが重要である。因果関係を意識することで、技術のつながりが明確になり、より深い理解につながる。
問題(過去問ふう対策道場)
10問中3問をランダムで出題。選択肢は常にシャッフル。

問題集本体はこちら

「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
バックナンバーはこちら
深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト 第3版

徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版 徹底攻略シリーズ

ディープラーニングG検定(ジェネラリスト) 法律・倫理テキスト



コメント