
モデルアーキテクチャ
次に扱うのはモデルアーキテクチャである。これは自然言語処理における「頭脳」に相当する部分であり、どのような表現を用いて、どのように処理するかを決定する役割を担っている。
-729x1024.webp)
モデルアーキテクチャが賢くなければ、どれほど優れた表現を用いても、意味のある出力は得られない。
Seq2Seq:系列変換の基本構造
Seq2Seq(Sequence to Sequence)は、入力と出力の両方が系列であるモデルである。例えば、英語から日本語への翻訳のように、入力文をエンコードし、出力文をデコードする構造を持つ。
このモデルは、エンコーダとデコーダの2つの構成要素から成り立っている。
しかし、長い文を扱う際には、情報が途中で失われるという課題が存在する。
Attention:重要語への注目機構
この課題を解決するために登場したのがAttention機構である。Attentionは、入力文の中でどの単語が出力に影響するかを動的に計算する技術である。
これにより、長文であっても意味を保ったまま翻訳が可能となった。人間が話を聞く際に、重要な部分だけを記憶するのと似た仕組みである。
Transformer:並列処理と精度向上の革新
Attentionの登場を契機として、次に進化したのがTransformerである。Transformerは、Attentionを全面的に活用したモデルであり、RNNやLSTMのような逐次処理構造を排除し、すべての単語を一括で処理することで、並列化と精度向上を実現した。
その結果、学習速度が向上し、長文への対応力も強化された。
Transformerは、EncoderとDecoderに分かれており、EncoderはBERTに、DecoderはGPTに応用されている。
因果関係図による技術の流れ
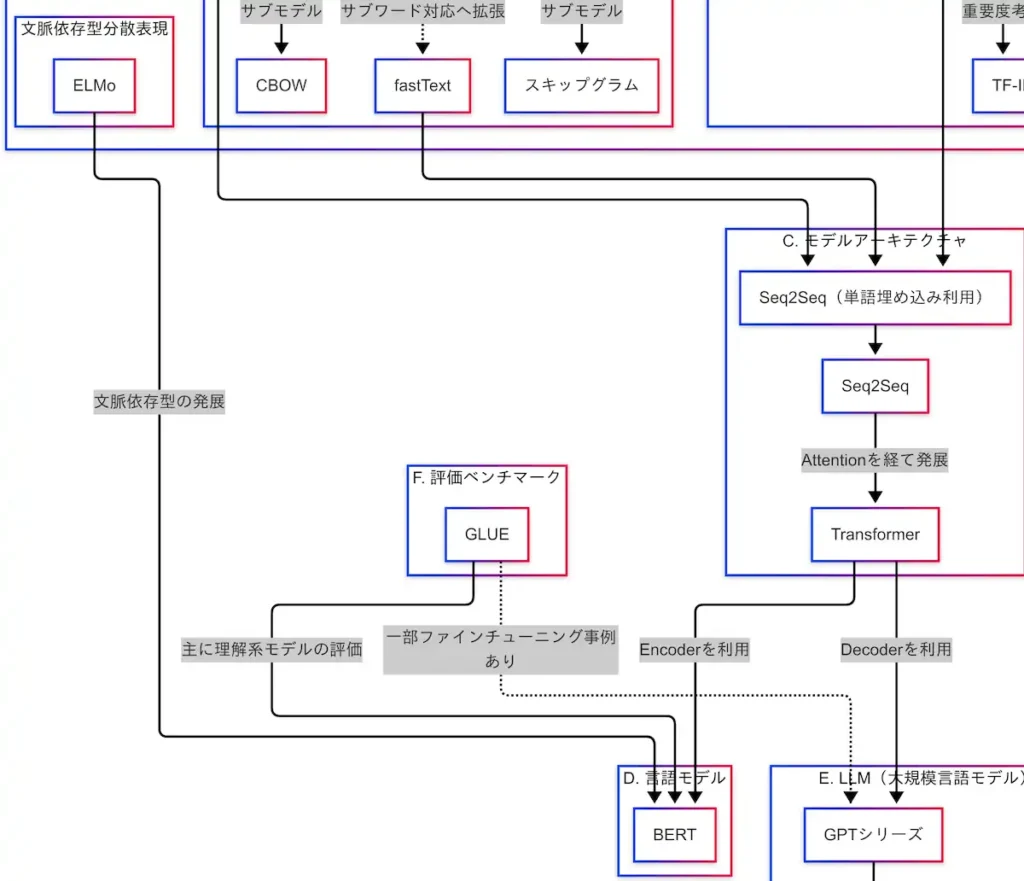
因果関係図を参照すると、BoWやword2vecなどの表現がSeq2Seq(単語埋め込みを利用)に接続され、そこからAttentionを経てTransformerへと進化している。
さらに、TransformerからはBERTとGPTに分岐し、それぞれがLLM(大規模言語モデル)へとつながっている。
このように、モデルアーキテクチャの進化は、言語モデルの進化に直結している。
モデルアーキテクチャは、Seq2Seq → Attention → Transformerという流れで進化してきた。この進化によって、自然言語処理の性能は飛躍的に向上した。
かつては逐次処理が主流であったが、現在では並列処理によって効率と精度の両立が可能となっている。Attentionの導入によって、文脈理解も大きく進化した。
Transformerの登場以降、自然言語処理はまさに「沼」の領域へと突入したと言える。
言語モデル
言語モデルとは、自然言語処理において文章の意味を理解する役割を担う技術である。分類、質問応答、感情分析など、意味に基づく処理を行うための中核的な存在である。
この領域において代表的なモデルがBERTである。
BERT:双方向文脈理解の革新
BERT(Bidirectional Encoder Representations from Transformers)は、TransformerのEncoder部分のみを用いたモデルである。従来のモデルが左から右、あるいは右から左といった一方向の文脈しか扱えなかったのに対し、BERTは前後の文脈を同時に考慮することが可能である。
例えば、「はし」という単語は、「川のはしに座る」と「はしで寿司を食べる」では意味が異なる。BERTはこのような文脈の違いを捉え、適切な意味を理解することができる。
文脈依存型のモデルがなければ、すべての「はし」が「箸」と解釈されるような誤りが生じる。BERTはこの問題を解決するために設計された。
学習プロセス:事前学習とファインチューニング
BERTは、事前学習(Pre-training)とファインチューニング(Fine-tuning)の2段階で学習される。
- 事前学習では、大量のテキストを用いて以下の2つのタスクを実施する:
- Masked Language Modeling(MLM):文中の一部の単語をマスクし、それを予測する
- Next Sentence Prediction(NSP):2つの文が連続しているかどうかを判定する。
この段階で、言語の構造や意味に関する一般的な知識を獲得する。
- ファインチューニングでは、分類・質問応答・感情分析など、特定のタスクに合わせてモデルを調整する。
GLUE:性能評価のベンチマーク
BERTの性能は、GLUE(General Language Understanding Evaluation)というベンチマークによって評価される。GLUEは、文の分類、類似度判定、自然言語推論など、自然言語理解に関する複数のタスクを含む評価セットである。
BERTはこれらのタスクにおいて高いスコアを記録しており、その読解力の高さが実証されている。
因果関係図における位置づけ
因果関係図を確認すると、TransformerのEncoderがBERTに接続されており、さらにそのBERTがGLUEによって評価されている構造が見て取れる。
また、文脈依存型表現の先駆けであるELMoからの技術的進化の延長線上に、BERTが位置づけられている。
言語モデルは、自然言語の意味を理解するための「頭脳」である。その中でもBERTは、双方向の文脈を同時に捉えることで、自然言語理解の性能を大きく引き上げたモデルである。
事前学習によって言語の感覚を身につけ、ファインチューニングによって実務的なタスクに対応する。GLUEによる評価を通じて、その実力が客観的に示されている。
Transformerの構造を活かしたBERTは、理解系モデルの代表格として、自然言語処理の発展に大きく貢献している。


コメント