
Transformerの補助構成要素
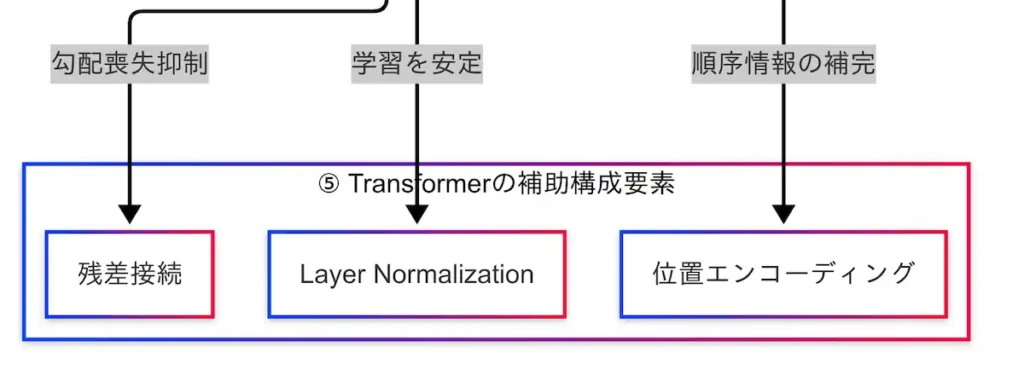
TransformerはAttention機構を中核に据えたアーキテクチャであるが、その性能と安定性を支えるためには、いくつかの補助構成要素が不可欠である。本章では、特に重要な3つの補助要素――位置エンコーディング(Positional Encoding)、Layer Normalization、残差接続(Residual Connection)について解説する。
位置エンコーディング:順序情報の補完
Attentionは並列処理が可能である一方で、系列データにおける語順の情報を直接保持しないという特性を持つ。これは、RNNのような逐次処理型モデルとは異なり、単語の並び順を無視して処理を行うためである。
この欠点を補うために導入されているのが位置エンコーディングである。これは、各単語の埋め込みベクトルに「その単語が文中の何番目に現れるか」という情報を加えることで、語順の意味をモデルに伝える仕組みである。
Transformerの元論文では、サイン波とコサイン波を用いた固定的な位置エンコーディングが提案されており、周期性と連続性を持つ位置表現が可能となっている。近年では、学習可能な位置エンコーディング(Learnable Positional Embedding)も広く用いられており、モデルが自ら位置の意味を学習することで、より柔軟な表現が実現されている。
因果関係図においては、Transformer EncoderおよびDecoderの両方から位置エンコーディングに矢印が伸びており、語順情報の補完が全体構造において重要な役割を果たしていることが示されている。
Layer Normalization:学習の安定化
Transformerでは、各層の出力を正規化するLayer Normalizationが導入されている。これは、層ごとの出力分布を一定に保つことで、勾配の爆発や消失を防ぎ、学習を安定化させる効果を持つ。
特に、Attention層やFeed Forward層の出力に対して適用されることで、深いネットワークにおける情報の伝達がスムーズに行われるようになる。
残差接続(Residual Connection):情報の保持と勾配の安定化
もう一つの重要な補助要素が残差接続である。これは、ある層の出力に対して、その層の入力を加算することで、情報のロスを防ぎ、勾配の流れを安定させる仕組みである。
この手法はResNetでも用いられており、深層学習モデルにおける学習効率の向上に大きく貢献している。Transformerでは、Attention層やFeed Forward層の出力に対して残差接続が適用されており、深い層でも情報が失われにくくなっている。
因果関係図では、TransformerからLayer Normalizationおよび残差接続に矢印が伸びており、これらの補助構成要素がモデルの安定性と性能向上に寄与していることが視覚的に示されている。
まとめ
本記事では、TransformerとAttentionに関する技術体系を、因果関係の視点から体系的に整理した。G検定の出題範囲に準拠しつつ、単なる用語の暗記ではなく、技術のつながりと背景にある課題解決の流れを重視した構成とした。
まず、モデルアーキテクチャの系譜においては、Seq2SeqからTransformerへの進化が自然言語処理の性能向上に大きく寄与したことを確認した。Transformerは、エンコーダとデコーダに分化し、それぞれがBERT(理解系)やGPT(生成系)といったモデルに発展している。
次に、Attentionの基本概念として、Encoder-Decoder Attention(別名:Source-Target Attention)を中心に、入力と出力の関係性を捉える仕組みを解説した。因果関係図では、Transformer Decoderから外部入力への注意機構としてこのAttentionが接続されている。
続いて、自己注目と多視点処理では、Self-AttentionとMulti-Head Attentionの構造と役割を明らかにした。TransformerのEncoderおよびDecoderは、これらの機構を用いて文脈を多面的に理解しており、因果関係図では両者からMulti-Head Attentionへの接続が示されている。
さらに、Attentionの計算構造では、Query・Key・Valueという3つのベクトルを用いた計算手順を整理した。Attentionから直接これらの要素に矢印が伸びており、計算の核となる構造が視覚的に理解できるようになっている。
最後に、Transformerの補助構成要素として、位置エンコーディング、Layer Normalization、残差接続を取り上げた。Transformerは語順を無視して並列処理を行うため、位置エンコーディングによって順序情報を補完している。因果関係図では、Encoder・Decoderの両方から位置エンコーディングへの接続が示されており、補助要素の重要性が強調されている。
以上のように、TransformerはAttentionを中心に、構造・計算・補助要素が複雑に組み合わさったアーキテクチャである。G検定では、こうした技術の「つながり」を理解しているかが問われる。単語単位の暗記ではなく、技術が「どんな課題に対する答えだったのか」を意識することで、全体像がより明確になる。
Attentionは単なる「注目」ではなく、Transformerの知性を支える構造的・計算的な仕組みである。その理解は、BERTやGPT、さらにはLLM全体の理解にもつながる重要なステップである。
- Seq2SeqからTransformerへの進化により、自然言語処理は理解系(BERT)と生成系(GPT)に分岐した。
- AttentionはSelf・Multi-Head・Encoder-Decoder型に分類され、Query・Key・Valueによる計算構造が中核を成す。
- 位置エンコーディングや残差接続などの補助構成要素が、Transformerの性能と安定性を支えている。
バックナンバーはこちら

深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト 第3版

徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版 徹底攻略シリーズ

ディープラーニングG検定(ジェネラリスト) 法律・倫理テキスト



コメント