
音声処理モデル
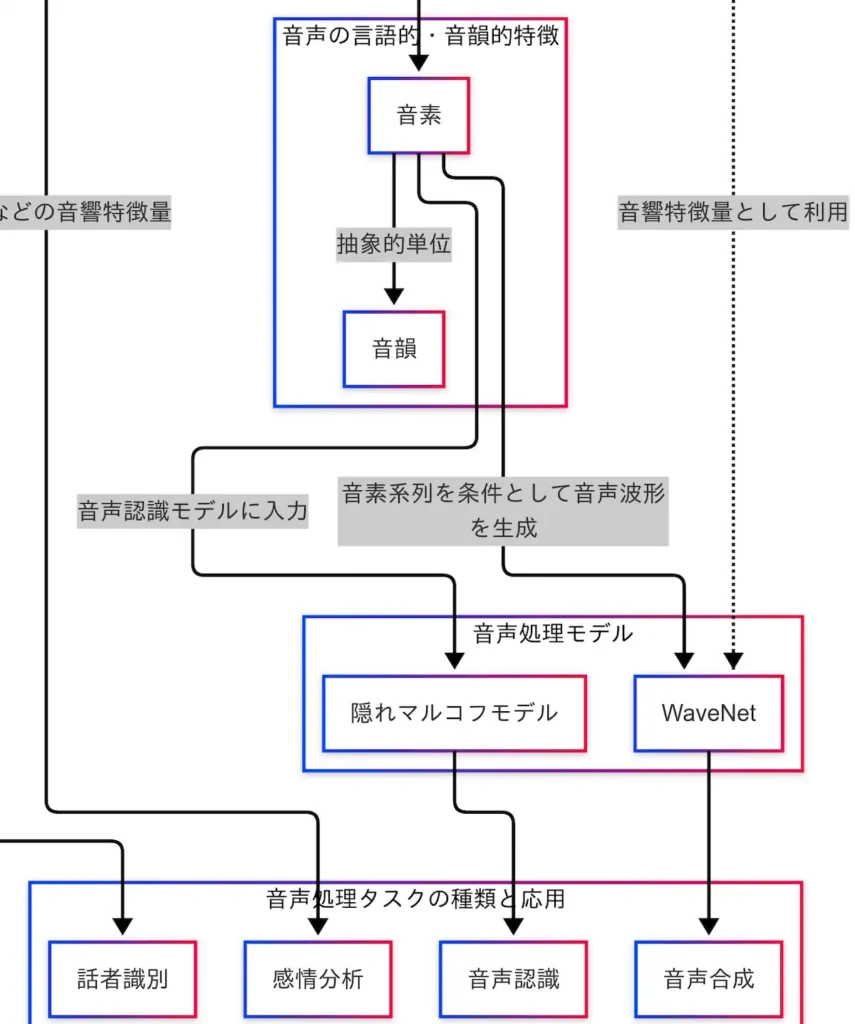
音声処理において、音素は言語的な最小単位であり、音声を意味のある情報へと変換するための中心的な役割を担っている。この音素を入力として、音声を認識したり、逆に音声を生成したりするモデルが存在する。それが音声処理モデルである。
因果関係図では、「音素 → HMM → 音声認識」「音素 → WaveNet → 音声合成」という2つの主要な流れが示されている。
まず、HMM(隠れマルコフモデル) は、古典的な音声認識モデルとして広く知られている。HMMは、音素の系列を時間的にモデル化し、どの音素がどのタイミングで現れるかを確率的に予測する。ここで「隠れ」とは、観測できない内部状態――話し手の意図や文脈など――を仮定し、それを推定するという意味である。音声の表面だけでなく、背後にある意味を推測する構造が、HMMの特徴である。
一方、近年の音声合成技術では、WaveNet が注目されている。WaveNetは、音素の系列を条件として、自然な音声波形を生成する深層学習モデルである。従来の音声合成手法と比較して、より滑らかで人間らしい音声を出力できる点が特徴である。
因果関係図では、「フォルマント周波数 → WaveNet」という破線も示されており、WaveNetが音素だけでなく、フォルマントなどの音響特徴量も活用していることがわかる。これは、音声認識とは逆方向の処理、すなわち「意味 → 音」への変換を実現する技術である。
このように、HMMは「音 → 意味」、WaveNetは「意味 → 音」という方向性を持ち、いずれも音素を中心に構築されている。音素は、音声処理モデルにおけるハブとして機能しており、音声認識・音声合成の両方において不可欠な存在である。
音声処理タスクの種類と応用
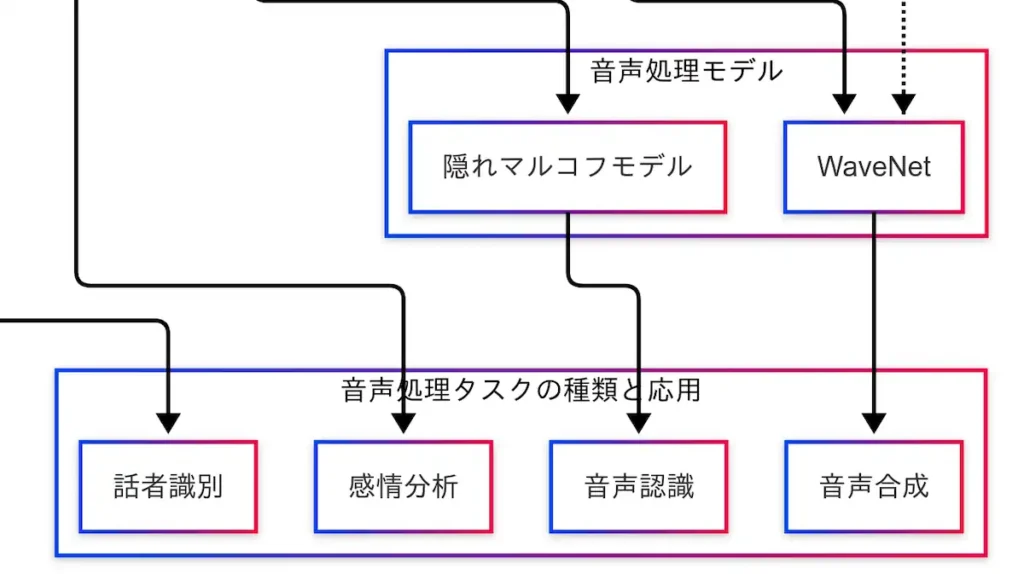
音声処理技術は、単なる信号処理にとどまらず、実世界で多様な応用を持つ。音声を数値化し、特徴を抽出し、モデルで処理することで、さまざまなタスクに展開される。因果関係図では、「HMM → 音声認識」「WaveNet → 音声合成」「MFCC → 話者識別」「MFCC → 感情分析」という4つの代表的な応用が示されている。
音声認識
音声認識とは、話された言葉をテキストに変換する技術である。スマートフォンの音声入力や音声アシスタント(例:Siri)などに広く利用されている。因果関係図では、「音素 → HMM → 音声認識」という流れが示されており、HMMが音素の系列を確率的にモデル化し、発話された単語を推定する役割を担っている。近年では深層学習ベースのモデルが主流となっているが、G検定ではHMMの理解も依然として重要である。
音声合成
音声合成は、テキストから自然な音声を生成する技術である。ナビゲーション音声や読み上げソフトなどに活用されている。因果関係図では、「音素 → WaveNet → 音声合成」という流れが示されており、WaveNetが音素の系列を条件として、滑らかで人間らしい音声波形を生成する。さらに、「フォルマント周波数 → WaveNet」という破線も示されており、音響特徴量を活用することで、よりリアルな音声生成が可能となっている。
話者識別
話者識別は、「誰が話しているか」を判定する技術である。電話音声による本人確認や声紋認証などに利用されている。因果関係図では、「MFCC → 話者識別」という流れが示されており、MFCCが話者ごとの声の特徴を数値化することで、識別が可能となる。
感情分析
感情分析は、音声から話者の感情を推定する技術である。コールセンターなどで顧客の感情を把握する目的で活用されている。因果関係図では、「MFCC → 感情分析」という流れが示されており、MFCCが声の抑揚やテンポなどを反映することで、感情の違いを捉えることができる。
音声処理は、「認識」「合成」「識別」「分析」といった多様な方向に応用されており、それぞれのタスクに適したモデルや特徴量が用いられている。因果関係図を通じて、技術のつながりと応用の広がりを体系的に理解することが、G検定対策としても有効である。
まとめ
本記事では、音声処理技術の全体像を因果関係図に基づいて体系的に整理した。音声処理は、単なる録音技術ではなく、「音 → 数値 → 特徴 → 意味 → 応用」という一連の流れによって構成されている。
出発点は AD変換 → PCM による音声のデジタル化である。ここで、アナログ音声がコンピュータで扱える数値信号へと変換される。
次に、FFT → メル尺度 → MFCC によって音響特徴量が抽出される。これにより、音声の中に含まれる周波数成分や聴覚的特徴が数値化され、機械学習モデルが扱える形となる。
その後、MFCC → 音素 → 音韻 という流れを通じて、音声は言語的な意味に近づいていく。音素は音声認識や音声合成の中心的な単位であり、音韻は言語理解の抽象的な基盤を形成する。
音素を入力として、HMM → 音声認識、WaveNet → 音声合成 という2つの代表的なモデルが展開される。HMMは古典的な認識モデルとして、WaveNetは深層学習による高品質な音声生成モデルとして、それぞれ異なる方向性を持つ。
さらに、MFCCは 話者識別 や 感情分析 にも応用されており、音声処理の応用範囲が非常に広いことが因果関係図からも明らかである。
G検定では、こうした技術の「つながり」を理解しているかが問われる。単語の意味を暗記するだけではなく、「何のために使われているか」「どこにつながっているか」を意識することが、より深い理解につながる。
音声処理は、自然言語処理や画像認識とも連携する分野であり、AI技術全体の理解を深める上でも重要な位置づけにある。因果関係図を活用することで、複雑な技術体系を視覚的かつ論理的に把握することが可能となる。
- 音声処理は「AD変換 → PCM → FFT → MFCC → 音素 → モデル → 応用」という因果関係で構成されている。
- 音素を中心に、HMMによる音声認識、WaveNetによる音声合成が展開される。
- MFCCは話者識別や感情分析にも応用され、音声処理の幅広い可能性を支えている。
バックナンバーはこちら

深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト 第3版

徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版 徹底攻略シリーズ

ディープラーニングG検定(ジェネラリスト) 法律・倫理テキスト



コメント