
「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
バックナンバーはこちら

はじめに
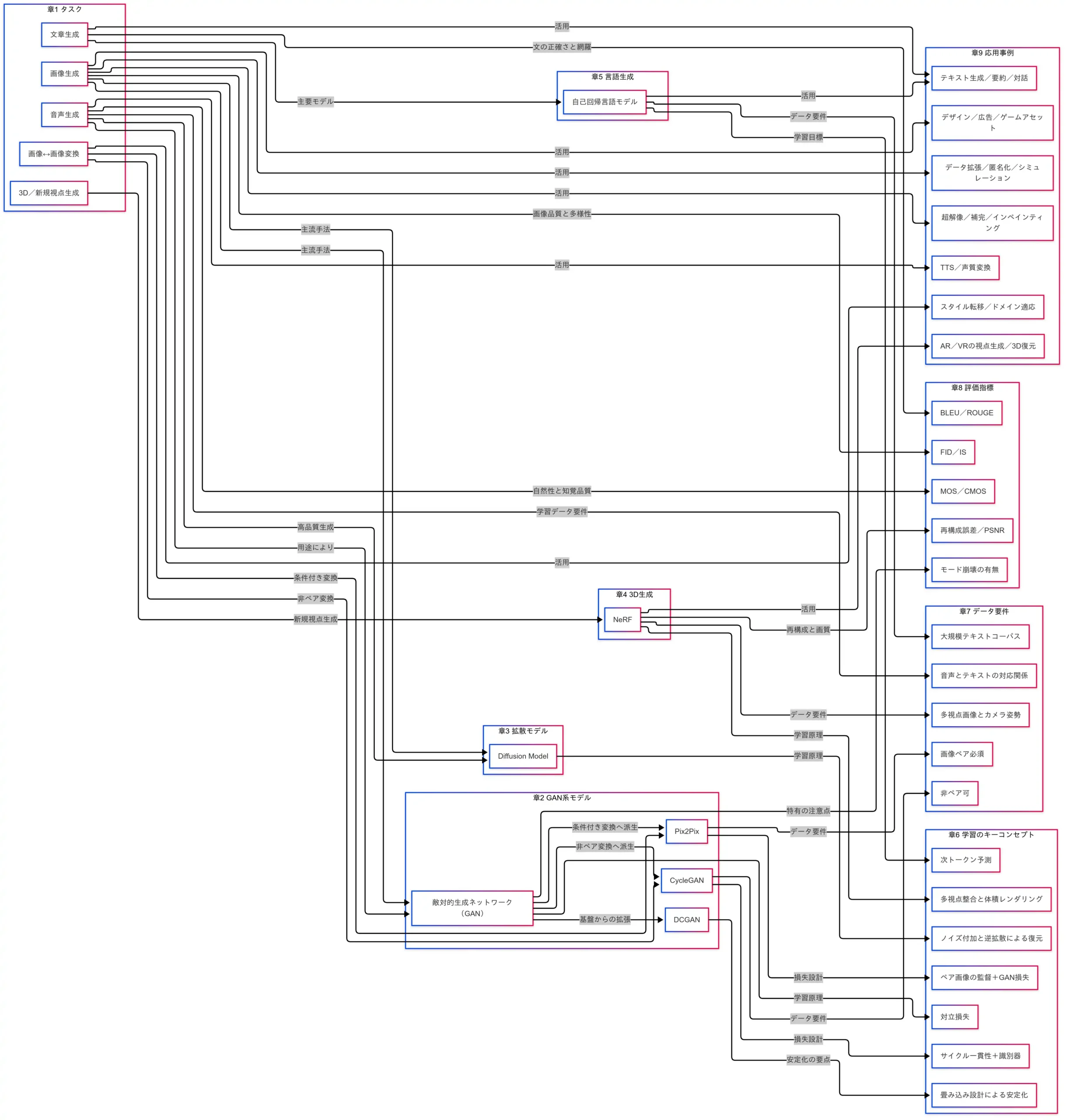
本稿は「G検定対策 究極カンペをつくろう」シリーズ第8回である。前回は強化学習の基本(マルコフ性・価値関数・「状態-行動-報酬」のループ)を図解で整理し、要点を掴んだ。今回は一転して データ生成 を扱う。すなわち、AIが画像・音声・文章を生み出すための主要技術を体系的に整理する回である。
生成系の代表格として GAN と 拡散モデル(Diffusion) がある。名称は広く知られる一方で、「何が違うのか」「どのように動作するのか」が曖昧になりやすい。また、 NeRF による3D/新規視点生成や、 自己回帰言語モデル によるテキスト生成も、G検定の学習範囲として押さえておくべき重要テーマである。
本稿では、用語の暗記ではなく 因果関係で理解すること を重視する。すなわち、
- 何を作るか(タスク)
- どう作るか(モデル)
- なぜその設計なのか(学習のキー概念)
- どんなデータが要るか(データ要件)
- どう良し悪しを測るか(評価指標)
- どこで使われているか(応用事例)
を一連の地図として結び直す。取り上げるキーワードは、 GAN/DCGAN/Pix2Pix/CycleGAN/拡散モデル(DDPM 等)/NeRF/自己回帰言語モデル である。読了後には、「GANはなぜ“敵対的”なのか」「拡散モデルはなぜノイズを入れてから消すのか」「NeRFでカメラ姿勢がなぜ必須なのか」といった 理由 を説明できる状態を目指す。次章「説明内容」では、本記事のスコープと到達目標を明確にする。
動画シリーズ
G検定の究極カンペ関連動画の再生リスト

説明内容
本稿で達成すべき学習目標は以下の三点である。
- データ生成タスクの種類と概要を理解する。
- 代表的なデータ生成モデルを理解する(GAN、拡散モデル、NeRF、自己回帰言語モデル)。
- 生成モデルの実世界での活用法を理解する。
狙いは、用語の暗記ではなく、 タスク → モデル → 学習のキー概念 → データ要件 → 評価指標 → 応用 という因果で全体像を結ぶことである。読了時には、「目的に対してどのモデルを選ぶべきか」を自力で説明できる状態を目標とする。
本稿の範囲
- タスク:画像生成、文章生成、音声生成、画像⇔画像変換、3D/新規視点生成
- 代表的なモデル:GAN系モデル、拡散モデル、NeRF、自己回帰言語モデル
- 学習のキーコンセプトとデータ要件:対立損失、ノイズ付加と逆拡散、多視点整合と体積レンダリング、次トークン予測/ペア・非ペア、カメラ姿勢、コーパス規模、音声テキスト対応
- 評価指標と応用事例:FID/IS、BLEU/ROUGE、MOS、PSNR などの指標と、それに紐づく実務利用
章立て
- はじめに
- 説明内容(本章)
- タスク
- GAN系モデル
- 拡散モデル
- 3D生成(NeRF)
- 言語生成
- 学習のキーコンセプト
- データ要件
- 評価指標
- 応用事例
- まとめ
読み方と導線
- まず タスク で「何を作るか」の地図を掴む。
- 続く GAN系モデル と 拡散モデル で主要手法の設計思想を個別に把握する。章末にミニ比較を置き、総合比較は 学習のキーコンセプト で行う。
- 3D生成(NeRF)と言語生成 で画像以外の重要領域を押さえる。
- データ要件 で実務条件(ペア有無、撮影条件、コーパス品質と量)を整理し、 評価指標 で「良さをどう測るか」を定義する。
- 応用事例 で産業利用へ橋渡しし、まとめ で選定指針を再確認する。
学習方針
- 各章は独立に読めるが、因果関係図 を通して相互に接続される構成である。疑問の所在は次の対応で回収する。
- 「GANと拡散の違い」→ GAN系モデル/拡散モデル/学習のキーコンセプト
- 「NeRFでカメラ姿勢が必要な理由」→ データ要件
- 「品質評価の基準」→ 評価指標
- 実務を意識し、指標の限界(例:BLEU/ROUGEの意味範囲、FIDの解釈)と 人手評価の併用 にも触れる。
次章では、AIが生成しうるデータの種類を俯瞰し、以後のモデル解説の前提地図を整える。
タスク
本章では、生成AIが対象とするタスクの全体像を整理する。大別すると 画像生成/文章生成/音声生成/画像対画像変換(Image-to-Image)/3D視点生成 の五領域である。
画像生成
テキストや潜在ベクトルから新規画像を生成するタスクである。イラストや写真風画像の生成、超解像、インペインティング(欠損補完)などが含まれる。近年は拡散モデルの発展により、高解像・高忠実度の生成が一般化している。
文章生成
自己回帰言語モデルにより、与えられた文脈から自然言語テキストを生成するタスクである。質問応答、要約、翻訳、記事作成、コード補完など応用が広い。長文一貫性や事実整合性は追加の仕組み(RAG 等)で補強するのが実務的である。
音声生成
テキスト読み上げ(TTS)、声質変換、歌声合成など、音声波形を生成・変換するタスクである。自然性や抑揚制御の進展により、人手収録に迫る品質が実現しつつある。評価には主観評価(MOS)と客観指標の併用が一般的である。
画像対画像変換(Image-to-Image)
入力画像を別ドメインの画像へ変換するタスクである。代表例は 白黒→カラー、スケッチ→写真、スタイル転移 など。Pix2Pix は ペア画像必須 の条件付き変換を行い、CycleGAN は 非ペア データでも「A→B→A」に戻す サイクル一貫性 で学習を成立させる。実務ではデータ入手性(ペアの有無)がモデル選択を左右する。
3D視点生成
複数視点画像とカメラ姿勢からシーンの放射輝度場を推定し、未観測の視点画像を合成するタスクである。NeRF が代表的手法であり、AR/VR の没入体験、デジタルツイン、ロボット・自動運転のシミュレーション等に有用である。多視点データと正確なキャリブレーションが前提条件となる。
以上より、生成AIは作る対象(タスク)が多岐にわたり、前提データや評価指標 もタスクごとに異なる。本稿では続けて、これらタスクに対してどのようなモデルが適合するかを、「GAN系モデル」「拡散モデル」で順に検討する。
GAN系モデル
本章では、敵対的生成ネットワーク(GAN)と主要派生(DCGAN/Pix2Pix/CycleGAN)を概観し、タスク適合とデータ要件の観点で整理する。
GANの要点
GANは 生成器(Generator)と識別器(Discriminator)が競合する対立損失 で学習する枠組みである。識別器を欺くほど本物らしいサンプルを生成器が生み出すよう誘導され、学習が進むにつれて生成品質が向上する。画像を中心に、音声・動画など他モダリティにも拡張可能である。一方で、学習不安定や モード崩壊 が課題となりやすい。
DCGAN:畳み込み設計による安定化
DCGAN は畳み込みニューラルネットワーク(CNN)に基づくアーキテクチャ設計(例:全結合の削減、ストライド畳み込み、BatchNorm、活性化関数の統一方針)により、GAN学習の安定性と画像表現力を高めた系統である。自然画像生成の土台として広く参照される。
Pix2Pix:ペア画像必須の条件付き変換
Pix2Pix は入力画像を別ドメインの出力に 条件付きGAN でマッピングする手法であり、ペア画像(入力と正解の対応)が必須 である。スケッチ→写真、白黒→カラー、セマンティックマップ→街景など、対応データが用意できる現場に適する。損失設計はGAN損失に加えL1等の再構成項を併用し、忠実性を担保する。
CycleGAN:非ペアで学べるドメイン変換
CycleGAN は 非ペア データでも学習可能な画像変換である。サイクル一貫性(A→B→Aで元に戻る制約)と識別器を組み合わせ、対応の取れていないコレクション間(例:夏⇔冬、馬⇔シマウマ、写真⇔絵画)のスタイル転移を実現する。ペア収集が困難なケースで有効だが、幾何や細部忠実性の制御には工夫を要する。
使い分けの指針(タスク×データ要件)
- 高品質な新規画像生成:まずは DCGAN系 などの安定化設計を土台に、目的に応じた条件付けや正則化を検討する。
- 画像対画像変換(対応あり):Pix2Pix が第一候補。ペア品質(位置合わせ・露出差)と再構成損失の重みが成否を分ける。
- 画像対画像変換(対応なし):CycleGAN を検討。サイクル一貫性だけに頼らず、アイデンティティ損失や特徴保持の正則化で破綻を抑える。
実務メモ
- 学習安定化:学習率スケジュール、判別器優位の抑制、ラベルスムージング、データ拡張、正則化(Spectral Norm 等)が有効である。
- 多様性確保:ミニバッチ多様化、潜在コードの可視化、FID/ISによる品質と多様性の併観測が実務上の定番である。
- 倫理・法務:生成物・学習データのライセンス、肖像権・著作権、配布ポリシーの整備が前提となる。
次章では、GANとは発想がまったく異なる 拡散モデル を取り上げ、ノイズ付加と逆拡散という生成原理を整理する。
拡散モデル
拡散モデル(Diffusion Model)は、ノイズ付加と逆拡散による復元 を原理とする生成手法である。GANのように生成器と識別器を競わせるのではなく、確率的なノイズ除去を反復 してデータを生成する点が本質的な違いである。
原理:前向き拡散と逆拡散
- 前向きプロセス(拡散):元データに微小なガウスノイズを段階的に付加し、最終的に 完全なノイズ へと埋没させる過程である。
- 逆拡散プロセス(生成):ノイズ状態から段階的に ノイズを取り除き、元データ分布へと戻す過程を 学習 する。実装上は、各時刻のノイズ量(あるいは速度場/スコア)を予測するネットワークを訓練し、その予測を用いてノイズを除去する反復を行う。
この枠組みにより、モデルは「敵と戦う」のではなく「汚れを落とす」ことで高品質なサンプルを得る。直感的には、“逆再生で写真を現像する”イメージである。
代表的発展
- DDPM/DDIM 系:拡散・逆拡散の時間スケジュールや予測対象(ノイズ、$x_0$、速度)を設計し、高品質化とサンプリング高速化を両立する。
- Latent Diffusion / Stable Diffusion:画像そのものではなく 潜在空間 で拡散を行い、計算量を大幅に削減する。
- 条件付き生成:テキストやクラスラベルによる 条件付け(例:テキストエンコーダ+ガイダンス)で、プロンプト一致度を高める。
GANとの対比
- 学習安定性:識別器との競争がないため、モード崩壊が起きにくく 学習が安定しやすい。
- 計算コスト:多段の反復推論が必要で 計算量が大きい(高速化は活発に研究)。
- 画質と多様性:高解像・高忠実度の生成が得やすい一方、推論時間は長くなりがちである。
タスクへの広がり
- 画像生成:一般画像、超解像、インペインティング、スタイル変換などで高い基準を打ち立てた。
- 音声生成:波形やスペクトログラムに対して ノイズ除去型の生成 を適用し、自然な音質を得る事例が増えている。
- 条件付き画像変換:テキスト条件・画像条件・制御信号(例:エッジ、ポーズ)を用いた 精密制御 が可能である。
実務メモ
- 高速化の鍵:ステップ数削減(例:DDIM風サンプル)、潜在空間化、蒸留・一括予測。
- 制御性:テキスト条件のほか、構造ガイドを併用すると再現性が上がる。
- 評価:画質・多様性は FID/IS 等で把握しつつ、タスクに応じて人手評価を併用する(詳細は「評価指標」章)。
以上の通り、拡散モデルは ノイズを足してから賢く取り除く という発想で高画質と安定性を実現している。次章では、3D/新規視点生成を担う NeRF を取り上げる。
3D生成(NeRF)
本章では、NeRF(Neural Radiance Fields)による 3D/新規視点生成 を概観する。NeRFは、複数視点の観測から 放射輝度場 を推定し、任意視点における画像を 体積レンダリング で合成する手法である。2D画像を直接生成するGANや拡散モデルと異なり、空間そのものを再現 してから任意視点へ投影する点が本質である。
-1024x599.webp)
学習の仕組み:多視点整合と体積レンダリング
- 入力:複数視点から撮影した画像と、それぞれのカメラ姿勢(外部・内部パラメータ)である。
- 表現:3D空間の各位置に対して、密度(不透明度)と放射輝度(色)を返す連続場をニューラルネットで表現する。
- レンダリング:視点ごとに光線を空間へ射出し、線上の密度・色を積分する 体積レンダリング で画像を合成する。
- 最適化:合成画像と観測画像の誤差を最小化することで、多視点整合 を満たす放射輝度場を獲得する。
この過程により、学習後は未観測の視点からでも一貫した見えを生成できる。
データ要件
- 多視点画像:対象物やシーンを覆う十分な視差を持つ画像群が必要である。
- 正確なカメラ姿勢:外部・内部パラメータの信頼度が品質を左右する。推定誤差はゴーストやブレとして顕在化する。
- 被写体条件:大きな動きや非剛体変形が連続的に発生する場合は前処理や拡張手法を要する。
評価指標
- 再構成誤差/PSNR:レンダリング結果と実写の画素差にもとづく画質指標である。一般に PSNRが高いほど良好 であり、視点補間の忠実度を測る。必要に応じてSSIM等の構造指標も併用する。
応用
- AR/VR:任意視点のリアルタイム提示により没入感を向上させる。
- デジタルツイン/文化財保存:現実環境の写実的再現。
- 自動運転・ロボティクスのシミュレーション:環境再現に基づくセンサ模擬や経路検証。
- コンテンツ制作:フォトグラメトリ代替・補完として、背景や小物の再現に活用される。
まとめ
NeRFは「画像を作る」のではなく「空間を再現する」 アプローチであり、多視点画像+カメラ姿勢が学習の前提条件である。品質評価は 再構成誤差/PSNR を基本に据え、用途に応じて指標を追加する。次章では、テキストを生み出す 言語生成(自己回帰モデル) を取り上げる。
言語生成
本章では、自己回帰言語モデル を中心に、言語生成の仕組み・要件・評価と主な応用を概観する。2D画像を直接合成するGANや拡散モデルと異なり、言語生成は 離散トークン列 を対象にし、次トークン予測 を逐次反復して文章を構成する点が核である。
学習原理:自己回帰と次トークン予測
- 目的:文脈 $x_{1:t-1}$ が与えられたときの条件付き確率 $p(x_t|x_1:t-1)$ を推定することである。
- 生成:開始トークンから確率分布に従いトークンを一つずつサンプリング(または貪欲・ビーム探索)し、列を延長していく。
- アーキテクチャ:現在は トランスフォーマ の自己注意機構が主流であり、広い文脈依存を効率的に扱える。
- 調整手法:事前学習後、微調整(教師あり・指示追従)、RLHF(人手フィードバックによる強化学習)等で望ましい振る舞いに近づける。
データ要件
- 大規模テキストコーパス:品質・多様性・ドメイン網羅性が性能を規定する。ノイズ除去や重複排除、毒性コンテンツの管理が重要である。
- タスク適応:専門領域では、追加コーパス や RAG(検索拡張生成) により、最新性・正確性を補強する。RAGは外部知識を参照してから生成するため、事実性 の改善に有効である。
評価指標
- 自動指標:BLEU/ROUGE は参照文との n-gram 類似で可読性・網羅性を近似的に測る。ただし意味理解や一貫性、事実性の完全評価は困難である。
- 人手評価:流暢さ、一貫性、関連性、事実整合性 等を評価軸として併用する。生成文の幻覚(hallucination)対策の観点でも不可欠である。
- 補助指標:タスク次第で METEOR、BERTScore、QAベース評価、毒性・バイアス指標などを用いる。
応用
- テキスト生成:記事作成、メール・レポート草案、クリエイティブライティング。
- 要約:ニュース・議事録の抽出/要約。
- 対話:アシスタント、カスタマーサポート、教育支援。
- 翻訳:ドメイン適応や品質推定と組み合わせた実運用。
- コード支援:補完、リファクタ、テスト生成。
- 情報アクセス:RAG による検索・質問応答の高精度化。
実務メモ
- デコード戦略:温度・トップk/p、ビーム幅の選択が 多様性-正確性 のトレードオフを左右する。
- 安全性:毒性・偏見・機密情報漏洩への対策(プロンプト制御、フィルタ、監査ログ)が必須である。
- 外部知識連携:RAG、ツール呼び出し、関数実行により、最新性・正確性・計算能力 を補完できる。
まとめ
自己回帰言語モデルは 次トークン予測 に基づき、大規模コーパス を前提として多様なNLPタスクを横断的に支える。評価は BLEU/ROUGE+人手評価 の併用が基本であり、実務ではRAG等で事実性と再現性を補強するのが定石である。次章では、ここまでに扱った各モデルの 学習のキーコンセプト を横断的に整理する。
学習のキーコンセプト
本章では、各生成手法の 学習原理 を横断的に整理する。因果関係図で示したとおり、GAN、拡散モデル、NeRF、自己回帰言語モデルは、それぞれ異なる発想に基づく。違いを把握することが、モデル選定・評価設計・データ計画の出発点である。
GAN:対立損失(生成器×識別器の競争)
- 核:生成器 $G$ と識別器 $D$ が対立損失で競い合い、$G$ は $D$ を欺く方向に学習する枠組みである。
- 効果:鋭い局所的ディテールを持つサンプルを生成しやすい。
- 注意:学習不安定、モード崩壊のリスクがある。アーキテクチャ(DCGAN 等)や正則化で安定化を図る。
- タスク接続:新規画像生成、条件付き変換(Pix2Pix)、非ペア変換(CycleGAN)。
拡散モデル:ノイズ付加と逆拡散(確率的ノイズ除去の反復)
- 核:データに段階的に ノイズを付加 して完全ノイズ化し、その 逆過程(逆拡散)を学習してノイズを除去 し元分布へ戻す。
- 効果:学習が安定し、高画質・高忠実度 を達成しやすい。
- 注意:多段反復ゆえ 計算コスト が高い。潜在拡散やステップ短縮で高速化する。
- タスク接続:画像生成、超解像・インペインティング、音声波形・スペクトログラム生成、テキスト条件付き生成。
NeRF:多視点整合と体積レンダリング(空間の再現)
- 核:多視点画像と カメラ姿勢 を用いて、3D 空間の 放射輝度場(位置→密度・色)を学習し、体積レンダリング で任意視点画像を合成する。
- 効果:未観測視点でも幾何と見えの一貫性を保つ。
- 注意:多視点データ+正確な姿勢が必須。動的・非剛体には拡張手法が必要。
- タスク接続:3D/新規視点生成、AR/VR、デジタルツイン、シミュレーション。
自己回帰言語モデル:次トークン予測(逐次生成)
- 核:文脈 $x_{1:t-1}$ から 次トークン $x_t$ の条件付き確率を予測し、逐次的に列を延長する。
- 効果:長い文脈の依存を扱い、汎用タスク(要約・対話・翻訳・コード)に適用可能である。
- 注意:大規模コーパス が前提。自動指標では意味・事実性を測り切れないため、人手評価や RAG 併用が実務的である。
- タスク接続:テキスト生成、要約、対話、翻訳、コード支援、検索拡張生成(RAG)基盤。
横断比較:発想の違いを一言で
- GAN=競争 で本物らしさを引き上げる。
- 拡散=ノイズ掃除 を繰り返して高品質化する。
- NeRF=空間を再現 してから任意視点へ投影する。
- 言語=逐次予測 で離散列を組み立てる。
実務で効くチェックリスト
- 安定性が最優先か → 拡散モデルを検討。
- リアルタイム・低遅延が要るか → GAN系や蒸留済み拡散(ステップ短縮)を検討。
- ペア画像は用意できるか → Yes: Pix2Pix、No: CycleGAN。
- 視点変更が主目的か → NeRF。データ撮影計画とキャリブレーションを最初に固める。
- 事実性・最新性が重要か → 言語モデル+RAG、人手評価フローを設計する。
以上で学習原理の地図を共有した。次章では、この原理に対応する データ要件 を具体化し、収集・アノテーション計画の勘所を整理する。
データ要件
本章では、各手法が成立するために必要な データの前提条件 を整理する。因果関係図のとおり、要件はモデル設計と密接に結び付いており、収集・アノテーション計画の可否がモデル選定を左右する。
画像対画像変換(Pix2Pix/CycleGAN)
- Pix2Pix:ペア画像必須
入力と正解の 1対1対応(例:スケッチ⇔対応写真、白黒⇔同一構図のカラー)が必要である。位置合わせや露出差が大きいと損失が不安定化するため、厳密なアライメント と 十分な枚数 が前提である。 - CycleGAN:非ペア可
ドメインA・Bそれぞれの 非対応コレクション で学習できる。データ収集は容易になるが、幾何や色の アイデンティティ保持 が崩れやすいため、被写体分布や前処理(色統一、クロップ一貫化)を計画するべきである。
画像生成(GAN/拡散モデル)
- 量と多様性
クラスバランス、構図・照明・背景の偏りを抑えた 大規模・多様データ が望ましい。偏りは モード崩壊 や汎化不足の温床となる。 - 前処理
解像度統一、標準化、軽微なデータ拡張の設計が安定化に寄与する。拡散モデルでは キャプション品質(テキスト条件付けの場合)が生成忠実度を左右する。
3D/新規視点生成(NeRF)
- 多視点画像+カメラ姿勢(必須)
視差を十分に含む 多視点画像群 と 正確な外部・内部パラメータ が必要である。姿勢誤差はゴーストやブレとして顕在化する。 - 撮影計画
覆い(カバレッジ)とベースライン(カメラ間距離)の設計、露出・ホワイトバランスの一貫化、反射・透過物体の扱いが品質を左右する。動的シーンは静止化または拡張手法の導入が前提である。
言語生成(自己回帰言語モデル)
- 大規模テキストコーパス
品質(正確性・文体多様性)とスケールが性能の上限を規定する。重複排除、毒性・機密情報の除去などクレンジングが前提である。 - ドメイン適応
専門分野では追加コーパスや RAG で外部知識を参照し、最新性・事実性を補う設計が必要である。
音声生成(TTS/声質変換/歌声)
- 音声-テキスト対応
音素・単語レベルでの アライメント が重要である。録音品質(無反響・SNR)、話者バリエーション、発話スタイルの網羅が自然性に直結する。 - メタデータ
話者ID、話速・感情ラベルなどの リッチな付帯情報 は制御性向上に有効である。
実務チェックリスト
ペアを用意できるか → 可能:Pix2Pix/不可:CycleGAN。
視点変更が主目的か → NeRF、撮影計画とキャリブレーションを先に固める。
大規模・多様データを確保できるか → GAN/拡散の品質・多様性のボトルネックとなる。
機密・権利・個人情報 → 収集時のライセンス確認、匿名化・合成データ併用の方針策定が必須である。
以上より、「使いたいモデル」ではなく「用意できるデータ」から逆算 して手法を選ぶのが合理的である。次章「評価指標」では、これらの前提の上に 生成品質をどう測るか を定義する。
評価指標
本章では、生成タスクごとに用いられる主要指標を整理する。何を良しとするか はタスクで異なるため、画質/多様性/自然さ/忠実度 を軸に指標を選定し、必要に応じて 人手評価 を併用するのが実務的である。
画像生成:FID/IS と多様性
- FID(Fréchet Inception Distance)
生成画像群と実画像群を特徴空間でガウス近似し、その分布距離を測る指標である。小さいほど良い。品質と多様性を同時に反映しやすい利点がある。 - IS(Inception Score)
生成画像のクラス確信度と多様性を測る。クラスバイアスの影響を受けやすく、FIDとの併用が通例である。 - 補助観点:モード崩壊の有無(特定パターンに偏る現象)や再現性、テキスト条件一致度(条件付き生成)を個別に点検する。
文章生成:BLEU/ROUGE と人手評価
- BLEU
参照文との n-gram 一致度に基づく精密度指標である。 - ROUGE
n-gram の再現率(召喚率)に重きを置く指標である。
両者は 表層一致 の近似であり、意味的妥当性・一貫性・事実性 は測り切れない。したがって、人手評価(流暢さ、関連性、事実整合性等)や、場合により BERTScore/QAベース評価 を併用する。
音声生成:MOS/CMOS
- MOS(Mean Opinion Score)
複数評価者が主観的自然さをスコア化する。収録条件や評価設計の厳密さが信頼性を左右する。 - CMOS(Comparison MOS)
参照と生成の相対比較により差分を評価する。
客観指標(信号歪み、スペクトル差)を補助的に使うが、知覚品質 は最終的に主観評価が要となる。
3D/新規視点生成(NeRF):再構成誤差/PSNR
- 再構成誤差
合成画像と実観測の画素差で忠実度を評価する。 - PSNR
画質指標であり、値が高いほど良い。必要に応じて SSIM などの構造類似度も併用する。
視点一般化性能(未観測視点での劣化)や幾何整合性も個別に確認する。
横断的注意点
- 指標の限界を前提化:BLEU/ROUGE は意味理解を、FID は知覚的妥当性の全てを保証しない。人手評価やタスク固有指標を補助 に使うべきである。
- 分布ずれ:評価用データの分布が実運用と乖離していないかを確認する。
- 再現性:シード固定、データ分割、前処理の明示により、比較の公平性を担保する。
以上のとおり、評価は 単一指標依存を避け、複数指標+人手評価 で多面的に行うのが原則である。次章では、これらの指標を前提として、生成技術の 応用事例 を横断的に整理する。
応用事例
本章では、生成モデルの 実運用シナリオ を横断整理する。エンタメから産業領域まで、活用は 創作支援/変換・補完/検索・要約/シミュレーション の四系統に大別できる。
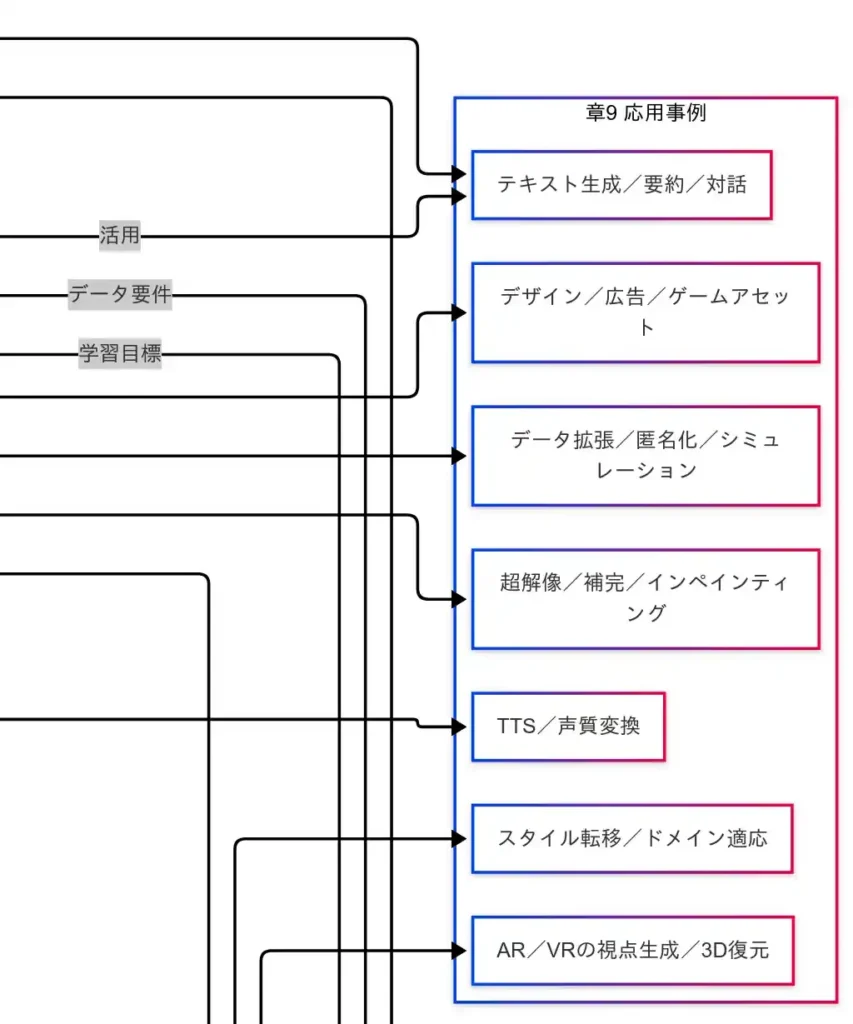
クリエイティブ制作(デザイン/広告/ゲームアセット)
- 画像生成(拡散/GAN):コンセプトアート、背景、テクスチャ、バリエーション生成に用いる。拡散モデルは高忠実度、GANは低遅延プレビューに利点がある。
- 画像対画像変換(Pix2Pix/CycleGAN):白黒→カラー、スケッチ→写真、スタイル転移などの 条件付き変換 で反復制作を高速化する。
- ワークフロー統合:プロンプトテンプレート化、リファレンス画像併用、制御信号(エッジ・ポーズ)投入により再現性を高める。
文書業務の効率化(テキスト生成/要約/対話)
- 自己回帰言語モデル:要約、ドラフト作成、QA、翻訳、議事録生成、コード補完に活用する。
- 検索拡張生成(RAG):社内文書やナレッジベースを参照し 事実性 を担保する。FAQ自動化や問い合わせ一次対応で効果が大きい。
メディア補完(超解像/インペインティング/修復)
- 拡散モデル:低解像度画像の精細化、欠損領域の自然な補完、ノイズ除去を実現する。映像ポストプロダクションや写真修復で需要が高い。
- GAN系:リアルタイム性を要求する場面でのアップスケーリングやスタイル適用に適する。
ドメイン適応/スタイル転移
- CycleGAN:非ペアでの 外観変換(夏⇔冬、昼⇔夜、絵画⇔写真)により、データ拡張やシミュレーション—実画像間のギャップ縮小に寄与する。
- Pix2Pix:ペアが確保できる場合、正確なマッピングでUIスキン差し替え、マップ→街景の生成などに用いる。
音声生成(TTS/声質変換/歌声)
- 拡散型TTS/GANボコーダ:読み上げ、キャラクターボイス、案内放送、ポストプロダクションの 自然性向上 に利用する。
- パーソナライズ:話者IDや感情ラベルを条件付けし、ブランド音声や多言語ガイドを生成する。
3D/視点生成(AR/VR/デジタルツイン)
- NeRF:現実空間を 写真的忠実度 で再現し、任意視点を生成する。VR展示、文化財保存、屋内外スキャン、映像制作のプリビズに有効である。
- シミュレーション:自動運転・ロボットのセンサ模擬や経路検証に活用し、実験コスト・リスクを低減する。
産業活用の勘所
- 品質管理:画像=FID/IS、言語=BLEU/ROUGE+人手評価、音声=MOS、3D=PSNR 等を 運用KPI として実装する。
- データと権利:ライセンス、個人情報、著作権・肖像権への配慮は必須である。必要に応じて 合成データ や匿名化を併用する。
- 統制と再現性:プロンプト・シード・前処理・モデルバージョンを記録し、再現生成 を可能にする。
- リアルタイム要件:対話UIやゲームでは 低遅延 が鍵であり、GAN系や蒸留拡散、軽量化(量子化・最適化)を検討する。
まとめ:モデル選定の指針
- 高忠実度の静的生成:拡散モデル
- 低遅延・条件付き変換:GAN/Pix2Pix
- 非ペア変換・ドメイン適応:CycleGAN
- 視点変更・空間再現:NeRF
- 文章・対話・要約:自己回帰言語モデル(必要に応じRAG)
以上により、生成AIは 創作支援から業務自動化、シミュレーション まで幅広く適用可能である。次章では、本記事全体を振り返る まとめ に入る。
まとめ
本稿では、生成AIの学習範囲を タスク → モデル → 学習原理 → データ要件 → 評価指標 → 応用事例 の因果で再編し、全体像を一枚の地図として把握できるように整理した。あらためて俯瞰すると、 画像・文章・音声・画像変換・3D視点生成 というタスク群に対し、GAN系/拡散モデル/NeRF/自己回帰言語モデル がそれぞれ異なる設計思想で応えていることが分かる。用語を暗記するのではなく、なぜその仕組みかという理由とあわせて理解することが、G検定対策にも実務応用にも効くのである。
覚え方のフックはシンプルでよい。GAN=バトル系/拡散=コツコツお掃除/NeRF=職人の空間再現/言語=おしゃべりの逐次予測*。この“性格付け”は軽妙だが、学習原理の本質を外していない。最終的には、目的(タスク)と制約(データ・計算・権利)から逆算して手法を選ぶ ことが重要である。
一覧表(要点の再掲)
| 項目 | GAN系 | 拡散モデル | NeRF | 言語モデル |
|---|---|---|---|---|
| 学習原理 | 生成器×識別器の競争(対立損失) | ノイズ付加→逆拡散 | 多視点整合+体積レンダリング | 次トークン予測(自己回帰) |
| 代表モデル | GAN, DCGAN, Pix2Pix, CycleGAN | Stable Diffusion, DDPM 等 | NeRF, Instant-NGP | GPT, LLaMA 等 |
| 得意タスク | 画像生成・画像変換・スタイル転移 | 高品質画像生成・インペインティング・音声 | 3D/新規視点生成 | テキスト生成・要約・対話・翻訳 |
| データ要件 | ペア必須(Pix2Pix)/非ペア可(CycleGAN) | 大量画像(条件付けなら良質キャプション) | 多視点画像+正確なカメラ姿勢 | 大規模テキストコーパス |
| 評価指標 | FID/IS、モード崩壊の有無 | FID/IS(人手評価併用) | PSNR、再構成誤差(+SSIM) | BLEU/ROUGE(人手評価併用) |
| 強み | 低遅延、条件付き変換に強い | 高画質・安定、多様性に強い | 高忠実な空間再現 | 文脈保持・汎用性 |
| 弱み | 学習不安定・崩壊リスク | 計算コスト・推論時間 | 撮影・姿勢取得の手間 | 事実性・最新性の確保が課題 |
次のアクション
- 自分のユースケースをタスク言語で定義し、上表から候補モデルを引くべし。
- データ要件と評価指標を初期段階で決め、収集計画とKPIを同時に設計すべし。
- 実務では、人手評価と権利配慮(ライセンス・個人情報)をワークフローに組み込むべし。
以上で、生成AI「データ生成」の全体像を締めくくる。以降は必要に応じ、各章の詳細や実装ノート、チェックリストを参照されたい。
- 生成AIは タスク→モデル→学習原理→データ要件→評価→応用 の因果で理解すると全体像が掴めるのである。
- 手法選定は目的(タスク)と制約(データ・計算・権利)から逆算し、GAN/拡散/NeRF/言語モデルを使い分けるべきである。
- 評価は単一指標に依存せず 複数指標+人手評価 を併用し、再現性と法倫理を運用に組み込むべきである。
「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
バックナンバーはこちら
深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト 第3版

徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版 徹底攻略シリーズ

ディープラーニングG検定(ジェネラリスト) 法律・倫理テキスト



コメント