
「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
G検定の試験概要・勉強法・無料700問問題集は「G検定対策の完全ガイド」にまとめています。

究極カンペとは?このバックナンバー一覧の使い方
G検定の対策でよくいただく質問のひとつが「カンペってどう作ればいいですか?」というものです。
このページでは、G検定向けに公開している「究極カンペをつくろう」シリーズのバックナンバーを一覧できるように整理しました。シラバスの各カテゴリ別の動画+記事へのリンクをまとめています。
「まずはどこから見ればいいか」「自分のカンペにどの回を反映させればいいか」を決めるためのナビゲーションとして使っていただければと思います。
ちなみに究極カンペは「アルティメットカンペ」と読みます。(造語)
究極カンペは実際に存在するカンペを指すのではなく、各個人の中に生まれる知識構造を指すと(勝手に)定義します。
カンペ作成すらも成長の糧にし、カンペに頼らない自分自身の作り方を知りたい人には強くマッチする内容になっています。
通常、究極(アルティメット)カンペというのを実在するカンペに命名すると、いわゆる誇大広告になってしまう。(そんな万能感全開のカンペがあるなら皆苦労はしない・・・。)
しかし、ここでは「究極カンペ=カンペ不要な自分自身という状態」という逆説ネーミングとしているので特に誇大広告には該当しない・・・はず?
※ 一部の記事は、文末に理解確認用の問題を出題。10問中3問をランダムで出題し、選択肢の並びもランダムにしています。ぜひ活用してみてください。(記事及び確認用問題は随時追加中)
この記事でわかること
- G検定向け「究極カンペ」シリーズの構成とテーマ
- 各回(画像認識・自然言語処理・音声処理・強化学習・生成AIなど)で何が学べるか
- 自分用のG検定究極カンペにどの回を反映させると良いかの目安
- シリーズ全体を通して、用語暗記から因果関係ベースの理解に切り替える考え方
G検定カンペ作成の動画シリーズ(YouTube)
G検定の究極カンペ関連動画の再生リスト

究極カンペ×用語カンペ関連記事

G検定カンペ#1:導入編(G検定は意味がない?/勉強ステージ)
- 究極カンペの作り方についての問い合わせが増えている。
- G検定の評判を確認し、ネガティブな意見を問題提起として捉える。
- 勉強のステージを定義し、語彙力と因果関係の把握が重要であることを説明。

機械学習の概要
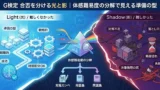
- 理論基盤は マルコフ性 → マルコフ過程 → MRP → MDP → 誘導MRP の階段であり、MDP が中心モデルである。
- 価値は $V,Q,A$ と最適値 $V^*,Q^*$、目的関数は $J_\gamma,J_{\text{avg}}$ で、$\gamma$ は未来重視度のノブである。
- 探索と行動選択は ε-greedy/Softmax/UCB/Thompson/OFU を使い分け、実装は TD→SARSA/Q 学習、REINFORCE、Actor-Critic を軸に据えるべきである。
ディープラーニングの要素技術
- Seq2SeqからTransformerへの進化により、自然言語処理は理解系(BERT)と生成系(GPT)に分岐した。
- AttentionはSelf・Multi-Head・Encoder-Decoder型に分類され、Query・Key・Valueによる計算構造が中核を成す。
- 位置エンコーディングや残差接続などの補助構成要素が、Transformerの性能と安定性を支えている。

ディープラーニングの応用例
- 画像認識の全体像を因果関係図で整理し、AlexNetを起点に各モデルの進化をたどる。
- 一般物体認識から物体検出・セグメンテーション・姿勢推定まで、各カテゴリの代表モデルと技術を解説。
- モデル同士の構造的なつながりや技術的背景を踏まえ、因果関係をもとに体系的に理解を深めていく。

自然言語処理の技術は、単なる用語の暗記ではなく、「何を解決するために生まれた技術か」という視点で理解することが重要である。因果関係を意識することで、技術のつながりが明確になり、より深い理解につながる。

- 音声処理は「AD変換 → PCM → FFT → MFCC → 音素 → モデル → 応用」という因果関係で構成されている。
- 音素を中心に、HMMによる音声認識、WaveNetによる音声合成が展開される。
- MFCCは話者識別や感情分析にも応用され、音声処理の幅広い可能性を支えている。

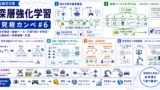
- 強化学習は「状態・行動・報酬・環境・エージェント」の基本構造を中心に、補助技術と連携して進化してきた。
- DQNやPPOを軸に、価値ベース・方策勾配・分散型アルゴリズムが技術的に発展し、応用事例へとつながっている。
- 因果関係図を活用することで、技術のつながりと応用先が体系的に理解でき、G検定対策にも有効である。
- 生成AIは タスク→モデル→学習原理→データ要件→評価→応用 の因果で理解すると全体像が掴めるのである。
- 手法選定は目的(タスク)と制約(データ・計算・権利)から逆算し、GAN/拡散/NeRF/言語モデルを使い分けるべきである。
- 評価は単一指標に依存せず 複数指標+人手評価 を併用し、再現性と法倫理を運用に組み込むべきである。

- 事前学習が汎用表現を供給し、転移学習→ファインチューニングへと因果的に接続してターゲットタスクへ効率適応する構図である
- 戦略(特徴抽出・全体微調整・凍結・層別LR・ヘッド置換・正則化・早期終了)、少数ショット、自己教師あり・半教師あり、そしてResNet・BERT・ViTの役割を位置づけた。
- 適用場面(小規模データ・計算制約・ドメイン近接/シフト)に潜む破壊的忘却・過学習・負の転移をEWC・部分凍結・データ混合・低LRで抑え、データ準備→評価の実務手順を示した。

- 基盤モデルを起点に共有表現→マルチタスク学習→Zero-shotへと汎化が連鎖し、画像×テキストを同一意味空間で扱う枠組みを整理した記事である。
- 主要タスクは画像キャプション・テキスト→画像生成・視覚質問応答であり、共有表現を背骨に検索・生成・説明・応答へ橋渡しする。
- 代表モデルはCLIP(検索)、DALL·E(生成)、Flamingo(少数例対応)、Unified-IO(統合処理)であり、活用は検索/クリエイティブ/アクセシビリティ/ロボティクス/EC/医療に及ぶ。

- 解釈性は「高リスク×説明責任×バイアス」で必須になる。
- 手法はまず「グローバル/ローカル」と「非依存/依存」の軸で置く。
- CAM/Grad-CAM=画像局所、LIME=局所近似、PI=全体重要度、SHAP=寄与分解で両対応。

- 高性能化は巨大化を招きやすく、計算資源・遅延・電力/発熱・通信依存・プライバシ/オフライン要件が重なって、軽量化が必要になりやすい
- 軽量化の目的地はエッジAIになり、スマホ/ウェアラブル、監視カメラ、産業IoT、車載/ロボットなどの現場に落ちやすい
- 代表手法はモデル圧縮としてプルーニング・量子化・蒸留が軸になり、宝くじ仮説は「当たりサブネット」という見方として押さえると混ざりにくい
- 効果は速度・電力・サイズに集約される一方、精度低下リスクが残るため、評価・再学習・チューニングまで含めて初めて“使える軽量化”となりやすい

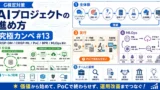
AIの社会実装に向けて
- AIプロジェクトは「ニーズ→価値→プロセス→業務/データ→PoC→社会実装→MLOps→価値」のループで回る。
- CRISP-DM/CRISP-ML/アジャイル/ウォーターフォールは、このループのどこをどう支えるかで整理する。
- PoCで終わらせず、「誰がどう使い、どう運用し、どの価値指標で判断するか」までをセットで設計する。
- 分割は最初、統計はtrain基準
- EDAはtrain中心、testは最後に一度
- 共同開発はアクセス制御・版管理・メタデータで事故を止める
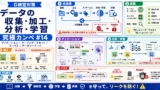
AIに必要な数理・統計知識
- 記述統計は、平均・中央値・分散・標準偏差・外れ値からデータ理解へ接続
- 確率分布と推定・検定は、不確実性と統計的判断の土台
- 相関・距離・類似度は、特徴理解とモデル解釈の重要ポイント

AIに関する法律と契約
- 個人情報か、要配慮か、利用目的は明確か
- 外部利用、加工、GDPR、安全管理まで一連で確認
- 条件を満たせば活用可、足りなければ再検討

- AI利用の著作権確認は、利用対象、学習、入力、生成、公開の順序で整理
- 第30条の4は、情報解析・機械学習の目的と権利者利益への影響が中心
- AI生成物の公開・商用利用は、人間の創作的寄与、類似性、依拠性、規約確認が重要

- 特許法は、AI・技術アイデアを「発明」「要件」「帰属」「守り方」「活用リスク」の順で整理
- 特許権は技術的発明、著作権は表現、営業秘密は非公開情報の管理が中心
- 出願、営業秘密、他の知財、利用方法の再検討、権利侵害リスク確認を事業判断に接続

FAQ
Q1. このページは何をまとめていますか?
A. G検定向けに公開されている「究極カンペをつくろう」シリーズについて、各回(動画+記事)へのリンクをテーマ別に一覧化した“道しるべ”ページです。(シミュレーションルーム999)
Q2. 「究極カンペ」とは何ですか?
A. 実在するチートシートそのものではなく、「自分の中に知識構造(因果関係のつながり)を作る」ための学習コンセプトとして定義されています。(シミュレーションルーム999)
Q3. まずどこから見ればいいですか?
A. 迷ったら「導入編 → 機械学習の概要 → 要素技術 → 応用例」と進み、時間がない場合は自分の弱点領域(例:画像認識/NLP/音声/強化学習/生成AI)から拾うのがおすすめです。(シミュレーションルーム999)
Q4. このシリーズはどこまで公開されていますか?
A. このページでは、現時点で公開されている「究極カンペをつくろう」シリーズのバックナンバーをまとめています。シリーズは今後も継続して追加される予定のため、新しい回が公開され次第、随時アップデートします。
Q5. 「用語集カンペ」との違いは何ですか?
A. 用語集カンペは“語彙の穴埋め(暗記・確認)”に強く、究極カンペは“因果関係で全体像をつなぐ理解”に強い、という役割分担です(併用を前提に設計されています)。(シミュレーションルーム999)
Q6. 自分用カンペに落とし込むコツは?
A. 公式シラバスで必要範囲を押さえたうえで、各回の内容を「原因→仕組み→派生→代表モデル→評価→応用」のように“つながり”で圧縮し、最後に自分の弱点だけ追記していくと崩れにくいです。(シミュレーションルーム999)
Q7. 最新シラバスに合わせるには?
A. JDLAが公開している最新のG検定シラバス(例:G2024#6〜)を基準に、足りない章だけをこの一覧から逆引きして埋めていくのが確実です。(一般社団法人日本ディープラーニング協会〖公式〗)
「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
参考文献(個人ブログ・企業ブログ・書籍以外/URL併記)
■ 試験・公式情報
- JDLA「G検定とは」 https://www.jdla.org/certificate/general/
- JDLA「G検定のよくある質問」 https://www.jdla.org/g-qa/
- JDLA「G検定の試験出題範囲(シラバス)G2024#6〜」 https://www.jdla.org/download/g%E6%A4%9C%E5%AE%9A%E3%81%AE%E8%A9%A6%E9%A8%93%E5%87%BA%E9%A1%8C%E7%AF%84%E5%9B%B2-%EF%BC%88%E3%82%B7%E3%83%A9%E3%83%90%E3%82%B9%EF%BC%89g20246%EF%BD%9Ev1-3/
■ 記事内の主要トピック(一次ソース:論文)
- Vaswani et al., “Attention Is All You Need” (2017) https://arxiv.org/abs/1706.03762
- Devlin et al., “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” (2018) https://arxiv.org/abs/1810.04805
- van den Oord et al., “WaveNet: A Generative Model for Raw Audio” (2016) https://arxiv.org/abs/1609.03499
- Mnih et al., “Playing Atari with Deep Reinforcement Learning” (2013) https://arxiv.org/abs/1312.5602
- Schulman et al., “Proximal Policy Optimization Algorithms” (2017) https://arxiv.org/abs/1707.06347
- Ho et al., “Denoising Diffusion Probabilistic Models” (2020) https://arxiv.org/abs/2006.11239
- Radford et al., “Learning Transferable Visual Models From Natural Language Supervision (CLIP)” (2021) https://arxiv.org/abs/2103.00020
- He et al., “Deep Residual Learning for Image Recognition (ResNet)” (2015) https://arxiv.org/abs/1512.03385
G検定の試験概要・勉強法・無料700問問題集は「G検定対策の完全ガイド」にまとめています。
深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト 第3版

徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版 徹底攻略シリーズ

ディープラーニングG検定(ジェネラリスト) 法律・倫理テキスト



コメント