
「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
バックナンバーはこちら

はじめに(今回の狙い)
学習目標は次の3つである。
- モデルの解釈性が必要な背景について理解する
- 解釈性が必要なユースケースについて理解する
- 解釈性の向上に寄与する代表的手法について理解する
キーワードは、CAM、Grad-CAM、LIME、Permutation Importance、SHAP、説明可能AI(XAI)である。
動画シリーズ
G検定の究極カンペ関連動画の再生リスト

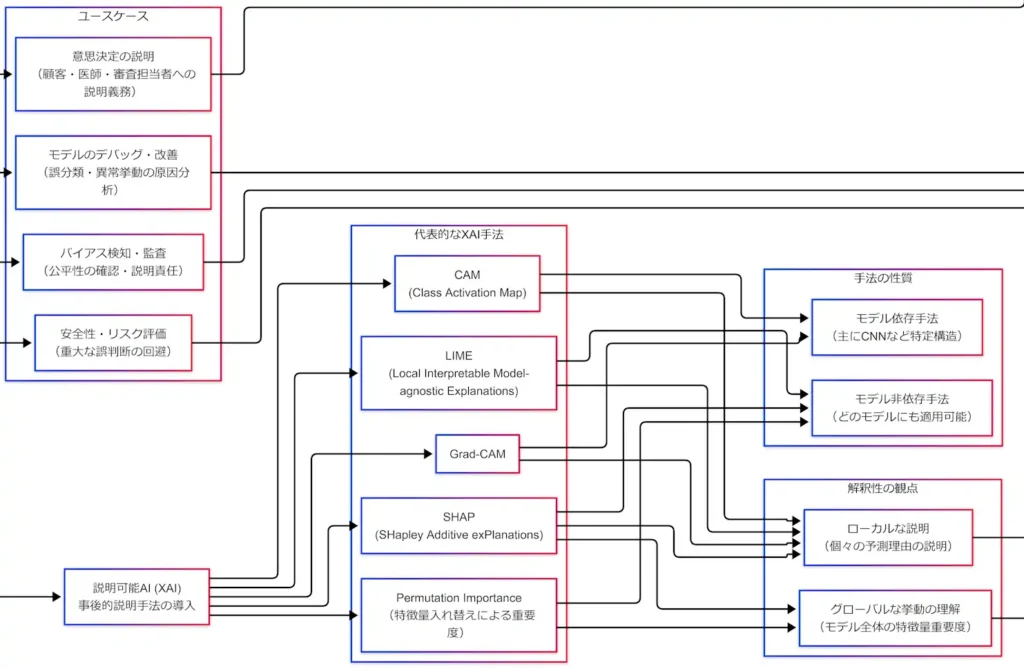
全体構成(背景→ユースケース→分類軸→代表手法)
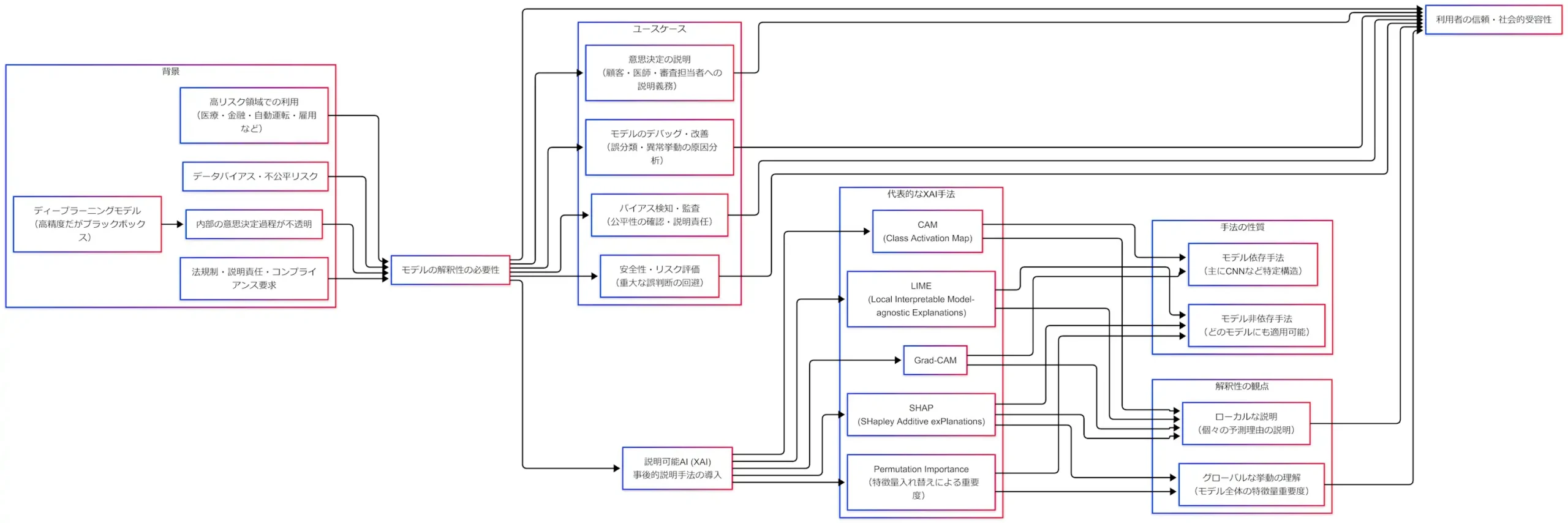
背景:なぜ解釈性が必要か
解釈性が必要になる起点は単純である。ディープラーニングは高精度だが、内部の意思決定過程が不透明になりやすい。ここに「高リスク領域での利用」「説明責任」「バイアス・不公平リスク」が重なると、精度だけでは運用が成立しない。つまり、解釈性は「理解のための贅沢品」ではなく、信頼・監査・安全のためのインフラである。
特に高リスク領域では、次の問いに答えられないことが致命傷になる。
- なぜこの診断になったのか(医療)
- なぜこの審査結果になったのか(金融)
- なぜその操作を選んだのか(自動運転)
- なぜこの応募者を落としたのか(雇用・採用)
この問いに答えられないモデルは、外部説明に失敗するだけでなく、内部改善も遅れる。解釈性の欠如は「説明できない」だけではない。「直せない」「監査に耐えない」「危険を予測できない」へ連鎖するのである。
拡大図(背景ブロック)
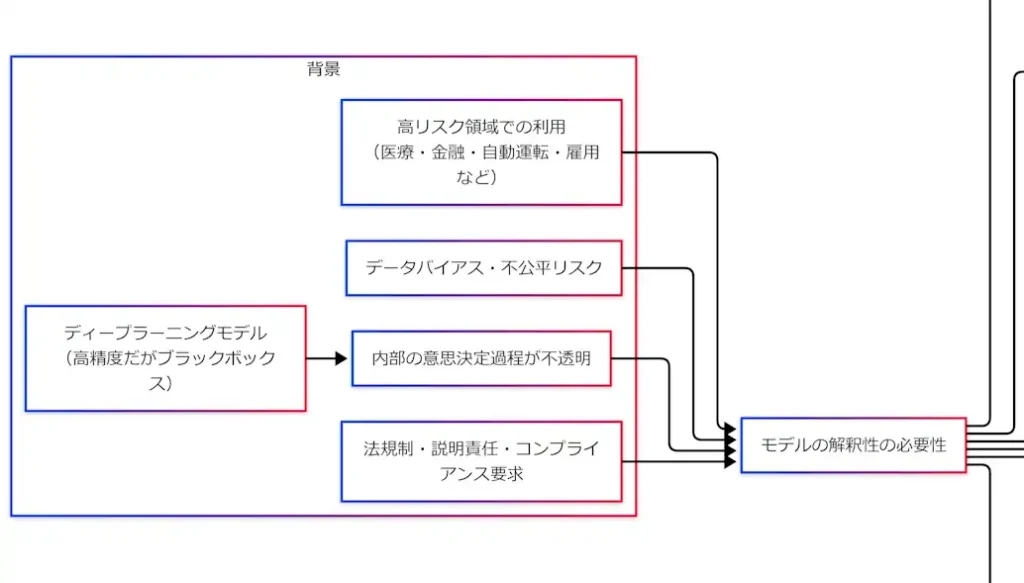
ユースケース:どこで必要か
解釈性が必要になる場面は「外向き」と「内向き」に割れる。外向きは、顧客・医師・審査担当などへの説明である。内向きは、開発・監査・安全担当のための原因究明である。重要なのは、どちらも最終的に信頼と社会的受容性へ接続している点である。
たとえば誤分類が起きたとき、解釈性がなければ「原因不明の不具合」として扱うしかない。逆に解釈性があれば、「実は背景パターンを見ていた」「特定属性に強く引っ張られていた」といった“誤りの形”が見える。これにより、データ収集・前処理・モデル設計・評価軸の見直しまで、改善が一本の線で進む。
拡大図(ユースケースブロック)
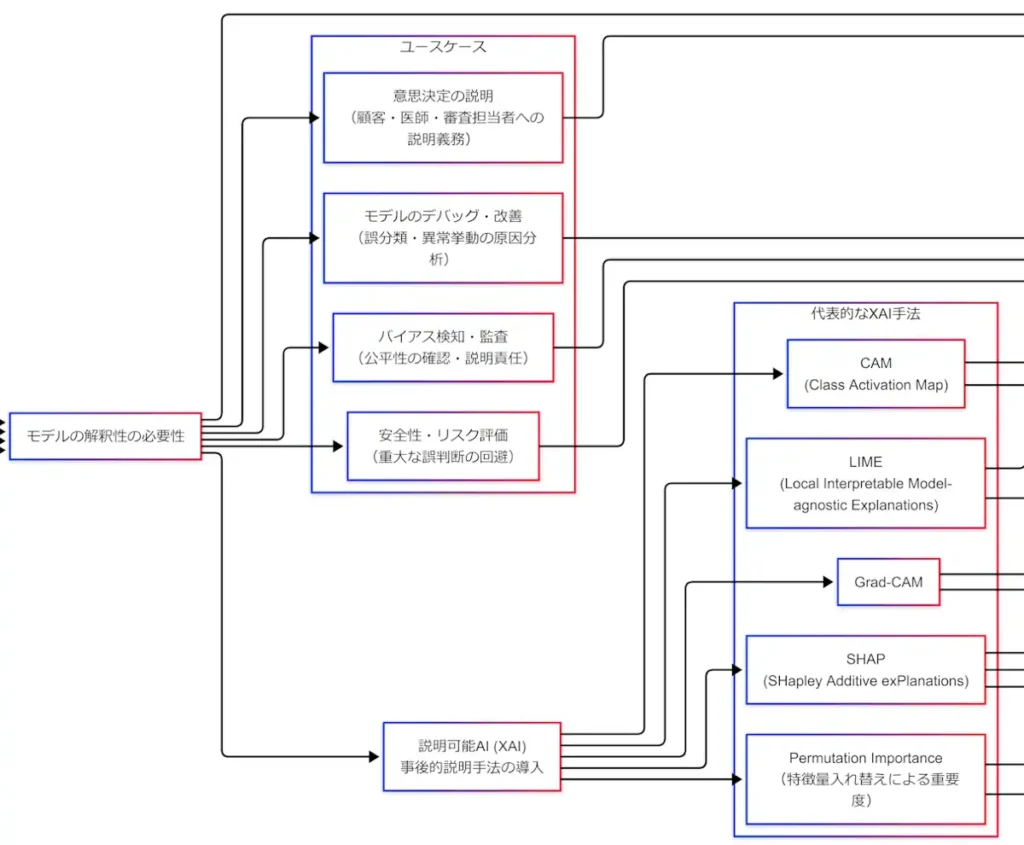
解釈性の観点:グローバル/ローカル
解釈性には「観点」がある。ここを曖昧にすると、手法の暗記がすべて崩れる。観点は2つである。
- グローバル:モデル全体として何を重視しているか
- ローカル:この1件について、なぜこの予測になったか
例として住宅価格予測を考える。グローバルでは「駅距離と面積が重要」「築年数は中程度」など、全体傾向が知りたい。ローカルでは「この家が高いのは駅近+広さが効いた」など、個別の根拠が知りたい。G検定は、この切り分けを前提に用語を問うてくるため、先に軸を立てておくべきである。
拡大図(観点ブロック)
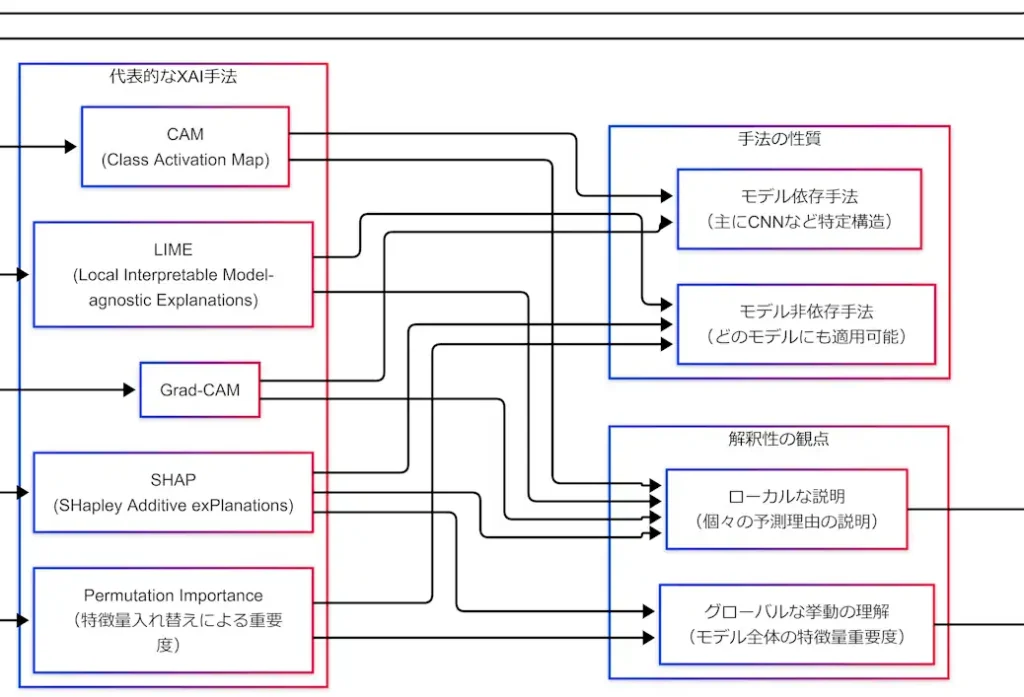
手法の性質:モデル非依存/モデル依存
次の分類軸は「どのモデルに使えるか」である。ここも試験では頻出である。
- モデル非依存(Model-agnostic):中身に触れず、入出力と評価で説明する
- モデル依存(Model-specific):構造や勾配など内部情報を使って説明する
モデル非依存は汎用性が高い反面、近似や計算コストの問題が出やすい。モデル依存は適用範囲が狭い反面、画像ヒートマップのように直観に刺さりやすい説明が得られる。実務でも試験でも、このトレードオフを言語化できることが強い。
拡大図(性質ブロック)
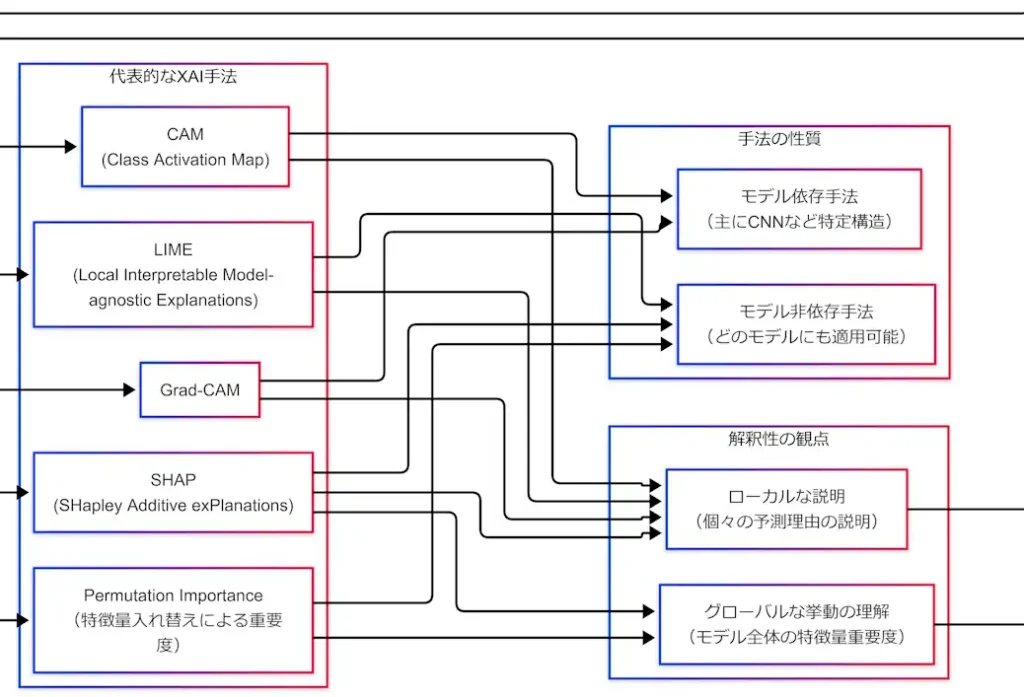
代表的XAI手法:5人を分類軸に刺す
ここまでで「背景→ユースケース→観点→性質」という枠組みが整った。次に、代表手法をこの枠組みに固定する。固定とは、一言定義+(グローバル/ローカル)+(依存/非依存)の3点セットである。
拡大図(XAI→手法ブロック)
CAM(Class Activation Map)
CAMは、CNNが画像分類をするときに「どの領域がそのクラス判断に効いたか」を可視化する手法である。ヒートマップが画像に重なる形で出るため、説明として直観に乗りやすい。ポイントは、“この1枚”に対してどこを見たのかを示すため、ローカル説明であることだ。
- 観点:ローカル
- 性質:モデル依存(主にCNN構造に依存)
Grad-CAM
Grad-CAMは、CAMの考え方を「勾配(Gradient)」で拡張し、より広いCNNに適用しやすくした手法である。ここで覚えるべき芯は、Grad-CAMは「ヒートマップを出す」だけではなく、勾配情報で重み付けして局在化する点である。したがって、CAMと同じくローカル×モデル依存に置く。
- 観点:ローカル
- 性質:モデル依存
LIME(Local Interpretable Model-agnostic Explanations)
LIMEは名前の通り「ローカル」かつ「モデル非依存」である。やっていることは、対象サンプルの近傍で入力を少しずつ揺らし、その近傍だけを単純な代理モデル(線形モデルなど)で近似して説明する、という発想である。
重要なのは、LIMEの説明は「モデルの真の内部」を開いているわけではない点である。あくまで局所近傍での近似である。したがって、サンプリングや近傍の定義により説明が揺れることがある。この性質まで含めて「LIMEらしさ」である。
- 観点:ローカル
- 性質:モデル非依存
Permutation Importance(特徴量入れ替え重要度)
Permutation Importanceは、特徴量をシャッフル(入れ替え)したときに性能がどれだけ落ちるかで重要度を測る手法である。直観は「その特徴を壊したらどれだけ困るか」である。個別予測の理由というより、モデル全体での重要度を測るため、グローバル説明に置く。
注意点として、特徴量同士が強く相関している場合、入れ替えの影響が単純に読めないことがある。重要度が分散したり、解釈が歪む可能性がある。とはいえ概念は単純で、試験でも実務でも入口として強い。
- 観点:グローバル
- 性質:モデル非依存
SHAP(SHapley Additive exPlanations)
SHAPは、ゲーム理論のShapley値に基づき、予測に対する各特徴量の寄与を加法的に分解して説明する枠組みである。1サンプルに対して「この特徴がプラス寄与」「この特徴がマイナス寄与」という形で出せるためローカル説明になる。さらにそれを集計すれば、モデル全体としての傾向(グローバル)も見えてくる。よって、SHAPはローカル&グローバルにまたがる。
ただし強力であるぶん、計算が重くなりやすい。現実の運用では近似や高速化の工夫とセットで語られることが多い。試験ではまず「寄与分解」「両対応」「非依存」を芯として押さえるべきである。
- 観点:ローカル&グローバル
- 性質:モデル非依存(思想として)
まとめ:究極カンペ(1枚)に圧縮する
ここまでの要点は、手法を“丸暗記”することではない。背景→ユースケース→分類軸→手法の順で、頭の中に棚を作り、そこへ用語を配置することである。棚ができると、用語が増えても破綻しない。これが「究極カンペ=知識体系」という裏テーマの意味である。
- 背景:高精度なブラックボックスが、高リスク領域に入ってきたため、説明責任や公平性の要請が強まった
- ユースケース:説明・デバッグ・監査・安全のすべてが信頼と社会的受容性に接続する
- 分類軸:グローバル/ローカル、非依存/依存の2軸で代表手法が整理できる
- 配置:
- CAM/Grad-CAM=ローカル×モデル依存
- LIME=ローカル×モデル非依存
- Permutation Importance=グローバル×モデル非依存
- SHAP=ローカル&グローバル×モデル非依存
最後に、試験直前に見るべき3行だけ残す。
- 解釈性は「高リスク×説明責任×バイアス」で必須になる。
- 手法はまず「グローバル/ローカル」と「非依存/依存」の軸で置く。
- CAM/Grad-CAM=画像局所、LIME=局所近似、PI=全体重要度、SHAP=寄与分解で両対応。
FAQ
Q1. 「解釈性」と「説明可能AI(XAI)」は同じであるか?
同一ではない。解釈性は「理解できる状態」全般を指す概念である。XAIは、特にブラックボックスモデルに対して事後的に説明を与える技術群として語られることが多い。
Q2. グローバル説明とローカル説明はどう違うのであるか?
グローバルはモデル全体の傾向であり、ローカルは特定入力に対する予測理由である。G検定では、手法がどちら寄りかを即答できると強い。
Q3. CAMとGrad-CAMの違いは何であるか?
どちらも画像の「見ていた領域」を示すが、Grad-CAMは勾配情報を使ってより汎用的に適用しやすい点が核である。
Q4. LIMEとSHAPの違いは何であるか?
LIMEは局所近傍で代理モデルを当てて説明する。SHAPはShapley値に基づき寄与を加法的に分解し、ローカル説明とグローバル傾向の両方に接続しやすい。
Q5. Permutation Importanceの落とし穴は何であるか?
特徴量間の相関が強いと、入れ替えによる性能低下の解釈が単純でなくなる場合がある。
「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
参考文献(個人ブログ、企業ブログは除外/URL併記)
- Bolei Zhou et al., “Learning Deep Features for Discriminative Localization” (CAMの源流), arXiv:1512.04150
https://arxiv.org/abs/1512.04150 - Ramprasaath R. Selvaraju et al., “Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization”, arXiv:1610.02391
https://arxiv.org/abs/1610.02391 - Marco Tulio Ribeiro, Sameer Singh, Carlos Guestrin, “Why Should I Trust You?: Explaining the Predictions of Any Classifier” (LIME), arXiv:1602.04938
https://arxiv.org/abs/1602.04938 - ACL Anthology: NAACL 2016 Demonstrations “Why Should I Trust You?”
https://aclanthology.org/N16-3020/ - Scott Lundberg, Su-In Lee, “A Unified Approach to Interpreting Model Predictions” (SHAP), NeurIPS 2017 Proceedings
https://proceedings.neurips.cc/paper/2017/hash/8a20a8621978632d76c43dfd28b67767-Abstract.html - Leo Breiman, “Random Forests”, Machine Learning (2001)
https://link.springer.com/article/10.1023/A:1010933404324
(フリーPDFの一例)
https://www.stat.berkeley.edu/~breiman/randomforest2001.pdf - Aaron Fisher, Cynthia Rudin, Francesca Dominici, “All Models are Wrong, but Many are Useful…” (Permutation系重要度の整理), JMLR (2019)
https://jmlr.csail.mit.edu/beta/papers/v20/18-760.html - NIST, “Artificial Intelligence Risk Management Framework (AI RMF 1.0)”
https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.100-1.pdf - Regulation (EU) 2024/1689 (EU AI Act), EUR-Lex
https://eur-lex.europa.eu/eli/reg/2024/1689/oj/eng - Regulation (EU) 2016/679 (GDPR), EUR-Lex
https://eur-lex.europa.eu/eli/reg/2016/679/oj/eng - European Data Protection Board (EDPB), “Guidelines on Automated individual decision-making and Profiling”
https://www.edpb.europa.eu/our-work-tools/our-documents/guidelines/automated-decision-making-and-profiling_en
バックナンバーはこちら
深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト 第3版

徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版 徹底攻略シリーズ

ディープラーニングG検定(ジェネラリスト) 法律・倫理テキスト



コメント