
バックナンバーはこちら

はじめに(今回の狙い)
AIプロジェクトは「モデルを作ったら終わり」ではなく、価値 → プロセス → データ → PoC → 社会実装 → 運用 → 価値というループで回る。その全体像を、1枚の因果関係図として頭の中に作るのが本記事のゴールである。
学習目標は次のとおりである。
- AIプロジェクトをどのように進めるか、その全体像と各フェーズで注意すべき点を理解する
- AIプロジェクトを進める際に考えるべき論点や基本概念、国内外の議論、事例への入り口を押さえる
- サービスやプロダクトとしてAIシステムを世に出す局面で、どこに注意が必要かを理解する
- モデルのヘルスモニタリングやライフサイクル管理など、AI運用の基本的な考え方を理解する
- 「PoCで終わらせない」ために、価値回収までの道筋を意識できるようになる
キーワードは次のとおりである。
- AIのビジネス活用、AIプロジェクトの進め方
- BPR、CRISP-DM、CRISP-ML
- アジャイル/ウォーターフォール
- PoC、MLOps、クラウド、Web API、Docker、Jupyter Notebook、Python
- データサイエンティスト、ステークホルダーのニーズ、他企業/他業種連携、産学連携、オープン・イノベーション
本記事のポイントは、用語をバラバラに暗記するのではなく、因果関係図のどこに刺さる概念なのかを意識して読むことである。
動画シリーズ
本記事は、YouTubeで公開している「G検定対策 究極カンペをつくろう」シリーズの第13回「AIプロジェクトの進め方」を文字・図解で整理したものである。
動画では対話形式で解説しているが、この記事では試験直前に見返せるよう、講義ノート+因果関係図の形に圧縮している。

全体構成:AIプロジェクトを1本の因果で見る
AIプロジェクトの流れを1枚にまとめた因果関係図は、概ね次のような構造になっている。
- 左下から ステークホルダーのニーズ が立ち上がる
- それが AIのビジネス活用(価値・KPI) に変換される
- 価値を実現するための AIプロジェクトの進め方(方法論) を選ぶ
- 業務の見直し(BPR)→ データ整備 → PoC → 社会実装 と進む
- 社会実装されたAIは MLOpsによって運用・改善 される
- 運用の結果としてビジネス価値が生まれ、再び「ニーズ」としてループする
この「ニーズ→価値→プロセス→業務/データ→PoC→社会実装→MLOps→価値」が、G検定的にも実務的にも押さえておきたい“究極カンペ”である。
因果関係図(全体)
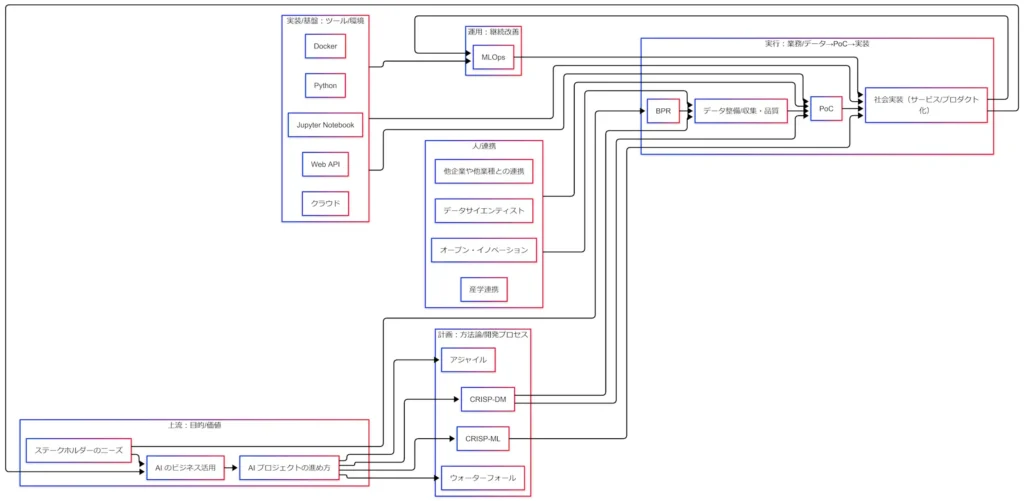
以下では、この図を左から右へ辿る形で各ブロックを解説していく。
上流:目的/価値 ― ステークホルダーのニーズから始める
ステークホルダーのニーズとビジネス価値
AIプロジェクトの起点は「AIを使うこと」ではなく、ステークホルダーのニーズである。
- 誰の(顧客、現場、経営、法務、運用…)
- どんな困りごとを
- どのように良くしたいのか
ここが曖昧なまま「とりあえずAIで何か」を始めると、PoCやモデル開発はできても、価値回収に失敗しやすい。
G検定の文脈では、「AIのビジネス活用」=価値やKPIに落とし込むこととして整理しておくとよい。
- 例:
- 「画像分類精度99%」 → 試験には出るが、ビジネス価値ではない
- 「検査時間が50%短縮」「不良流出が30%減少」 → ビジネス価値としてのKPI
AI導入の目的は、「AIを使うこと」ではなく価値指標(KPI)の改善である。
ここから逆算して、「どのプロセスで何を自動化/高度化するか」が決まる。
拡大図(上流ブロック)
このブロックで押さえるべきこと:
- ニーズがブレると、プロジェクト全体が迷子になる
- 「どのKPIを、どのくらい、いつまでに動かしたいか」を言語化する
- そのうえで、次章の「方法論/開発プロセス」を選択する
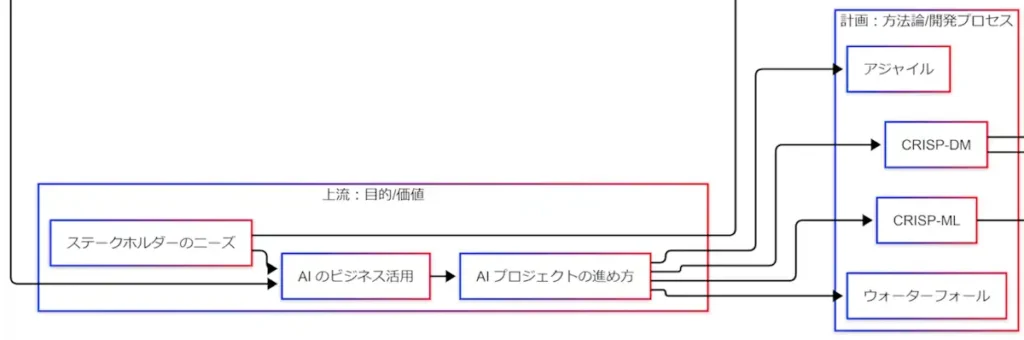
計画:方法論 / 開発プロセス ― CRISP-DM / CRISP-ML / アジャイル / ウォーターフォール
上流で「何を良くしたいか」が決まったら、次にどう進めるかを決める。
因果関係図では「AIプロジェクトの進め方」から、以下の4つに接続されている。
- CRISP-DM
- CRISP-ML
- アジャイル
- ウォーターフォール
CRISP-DM:分析プロジェクトの“定番フレーム”
CRISP-DM(Cross Industry Standard Process for Data Mining)は、データ分析プロジェクトの定番プロセスである。
- ビジネス理解
- データ理解
- データ準備
- モデリング
- 評価
- 展開(Deployment)
の6フェーズを、反復しながら進めることが特徴である。
G検定では、
- 「分析プロジェクトの標準的なプロセスモデル」
- 「ビジネス理解から始まり、展開までを反復的に回す」
この2点を押さえておくとよい。
CRISP-ML:運用まで含めた拡張版
CRISP-ML(やCRISP-ML(Q)など)は、機械学習システムの開発から運用までを意識した拡張フレームとして押さえると理解しやすい。
- 目的設定・ビジネス目標
- データ/モデル開発
- デプロイ
- 運用・監視・改善
といったMLOps的な観点が、最初から組み込まれている点がポイントである。
因果関係図でも、CRISP-MLは社会実装(サービス/プロダクト化)側に刺さる形で描かれている。
アジャイルとウォーターフォール:対立ではなくハイブリッド
- アジャイル
- 短いサイクルで仮説検証を回す
- 不確実性が高い領域(要件や技術がまだ固まっていない)に強い
- PoCや探索フェーズと相性が良い
- ウォーターフォール
- 要件定義→設計→実装→テスト→リリースを段階的に進める
- 安全性・品質・コンプライアンスが重い領域で有効
- 社会実装や本番運用フェーズで求められることが多い
重要なのは、アジャイル vs ウォーターフォールという二択ではないという点である。
- PoCや要件探索:アジャイル寄り
- 本番システムの安全性・品質管理:ウォーターフォール寄り
- 実務では、この2つを組み合わせたハイブリッドになりやすい
拡大図(計画ブロック)

G検定対策としては、
- CRISP-DM:分析プロジェクトの標準プロセス
- CRISP-ML:運用・品質まで含めた拡張
- アジャイル:短サイクルの仮説検証
- ウォーターフォール:工程を段階的に管理
という“芯”を押さえておくとよい。
実行:業務/データ→PoC→社会実装
ここからがAIプロジェクトの「体幹」である。
因果関係図では、
ステークホルダーのニーズ → BPR → データ整備/収集→PoC→社会実装(サービス/プロダクト化)→AIのビジネス活用
という太い矢印でつながっている。
BPR:AIの前に「仕事」を作り直す
BPR(Business Process Re-engineering)は、業務そのものを見直すプロセスである。
- どこで意思決定が行われているか
- 誰がその判断をしているか
- 何を根拠に判断しているか
を棚卸しし、AIを入れたときに本当に価値が出るように、仕事の流れを組み替える。
AIプロジェクトでありがちな失敗は、
業務はそのまま → 既存の流れの横に「よくわからないAI」が追加される → 誰も使わない
というパターンである。
「AIを作る前に、仕事を作り直す」という視点がBPRの核心である。
データ整備/収集・品質:地雷原を踏まないために
BPRを通じて「どこにAIを組み込むか」が見えたら、次はデータである。
- 欠損・ノイズ
- ラベル品質(誰がどう付けたか)
- データの偏り(バイアス)
- 個人情報・機微情報の扱い
- 利用許諾や二次利用の範囲
このあたりは、実務では地雷原になりやすい。
CRISP-DMの「データ理解」「データ準備」のフェーズが、ここに刺さっていると考えるとよい。
PoC:ゴールは「動いた」ではなく「価値が出る筋」
PoC(Proof of Concept)は、「できるかどうか」を検証するフェーズである。
ただし、本来のゴールは「モデルが動いた」ではなく「価値が出る筋が見えた」ことである。
- 成果指標(精度、再現率など)がビジネスKPIにどう接続するか
- 本番運用時の負荷・コスト・レイテンシの見通し
- 必要なデータ量・更新頻度
- 法務・セキュリティ・説明責任の論点
これらが「イケそうかどうか」を判断するのがPoCの役割であり、「一発ネタのデモ」で終わらせてはいけない。
社会実装(サービス/プロダクト化)
PoCを越えた先が、社会実装=サービス/プロダクト化である。
この段階で一気に論点が増える。
- UX(どの画面・フローでAIを使うのか)
- エラー時の挙動、フェイルセーフ
- ログと監査対応
- セキュリティ、アクセス制御
- 契約・責任分界(誰がどこまで責任を持つか)
- 説明責任(顧客・監督官庁・社内ステークホルダー)
因果関係図では、ここから再び「AIのビジネス活用」に矢印が戻っている。
AIが「使われる」状態になって初めて、上流で定義した価値が回収される。
拡大図(実行ブロック)

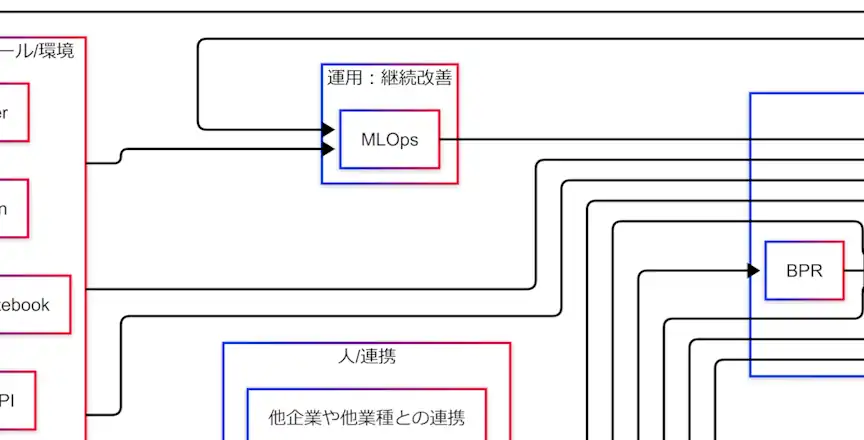
運用:継続改善(MLOps)
社会実装したAIは、そのまま放置すると現実の変化についていけなくなる。
- データ分布の変化(コンセプトドリフト)
- 新しい製品・顧客層の追加
- 法規制や社内ルールの変更
- モデルの劣化・バイアスの顕在化
これらに対応するための考え方が、MLOpsである。
MLOpsで押さえておきたい観点
G検定レベルでは、次のキーワードをひとつの文脈としてつなげて覚えておくとよい。
- モニタリング
- モデル性能(精度、再現率など)
- データドリフト/コンセプトドリフト
- バイアス・公平性
- 再学習と再デプロイ
- 新データでの再学習
- A/Bテストや段階的リリース
- バージョン管理・再現性
- モデル・データ・コード・設定の一貫した管理
- 障害対応
- ロールバック
- フォールバックルール(ルールベースなど)
因果関係図では、社会実装(DEP)→MLOps→社会実装(DEP)というループとして描かれている。
つまり、AIプロジェクトは「リリースして終わり」ではなく、運用で価値を維持・向上させるフェーズが本番なのである。
拡大図(MLOpsブロック)
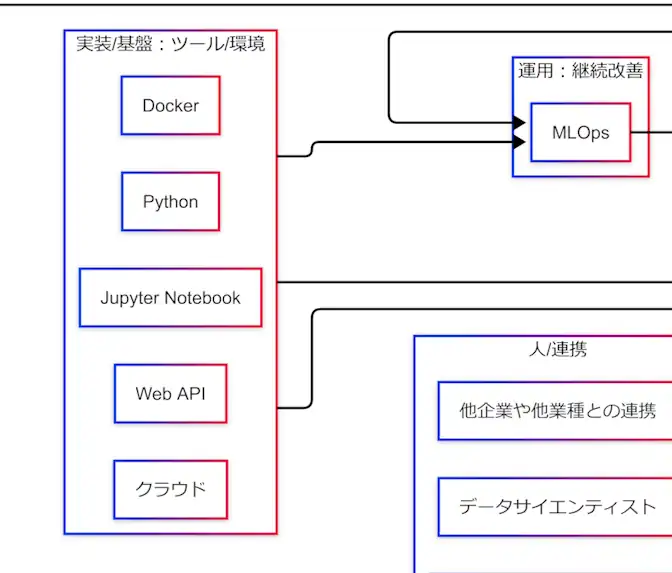
実装/基盤:ツール/環境 ― Python / Jupyter / Docker / Web API / クラウド
因果関係図の下部には、実装や基盤を支えるツール群がまとめて配置されている。
- Python
- Jupyter Notebook
- Docker
- Web API
- クラウド
これらは単なる道具リストではなく、「PoC→社会実装→MLOps」を支える土台として押さえると理解しやすい。
ツールごとの役割
- Python
- 機械学習・データ分析の事実上の標準言語
- ライブラリ(NumPy、pandas、scikit-learn、PyTorch、TensorFlowなど)が豊富
- Jupyter Notebook
- 探索的データ分析やPoCに向いたインタラクティブ環境
- 可視化・メモ・コードを一体として扱える
- Docker
- 環境ごとの差異(ライブラリバージョンなど)による事故を減らす
- 同じコンテナを開発・検証・本番で動かすことで再現性を確保
- Web API
- モデルをサービスとして公開する入口
- バックエンドのMLモデルを、他システムやフロントエンドから利用可能にする
- クラウド
- 計算リソースのスケールアウト
- ストレージ、ジョブ管理、監視、ログ基盤などを含む現実的な運用環境
典型的な流れとしては、
JupyterでPoC → Pythonコードを整理 → Dockerでコンテナ化 → クラウド上でWeb APIとして提供 → MLOps基盤と連携
という形が、因果関係図の「T→PoC/T→DEP/T→MLOps」に対応している。
拡大図(ツール/環境ブロック)
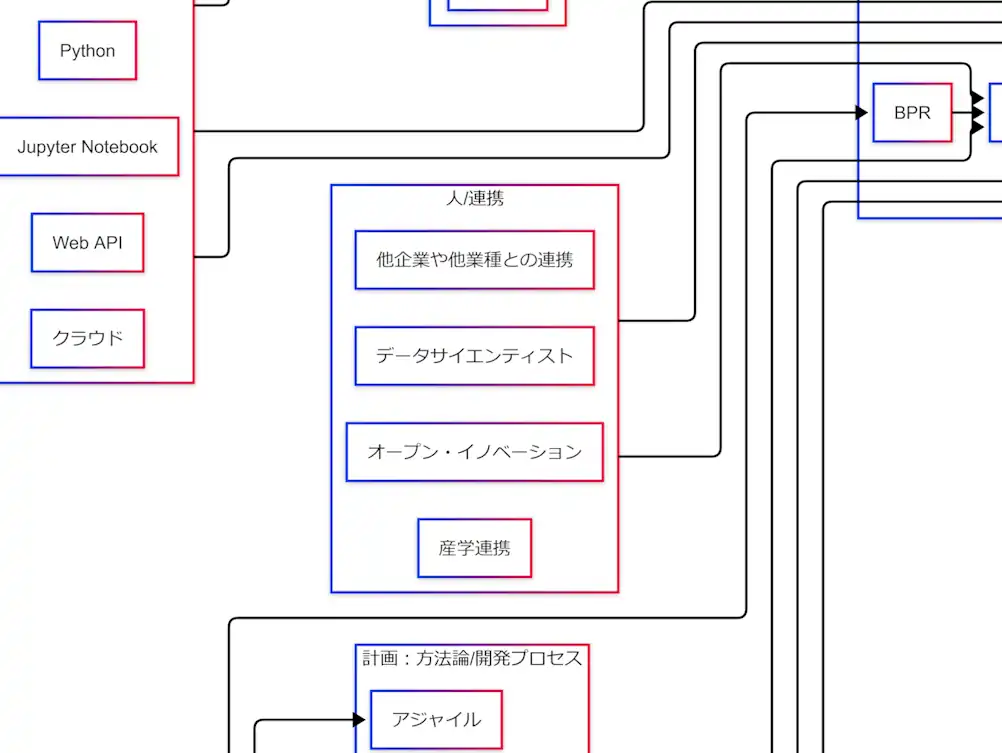
人/連携:チームと外部連携
最後に、因果関係図の右下には人と連携のブロックが配置されている。
- データサイエンティスト
- オープン・イノベーション
- 他企業や他業種との連携
- 産学連携
職種横断のチームで進める
AIプロジェクトは、データサイエンティストが1人で完結する仕事ではない。
- 企画・ビジネスサイド
- 現場担当
- データサイエンティスト
- ソフトウェア/インフラエンジニア
- セキュリティ・法務・コンプライアンス
- 運用チーム
これらが一体となって初めて、BPR→データ整備→PoC→社会実装→MLOpsの矢印が前に進む。
外部連携(オープン・イノベーション / 産学連携 など)
外部連携が必要になる典型的な理由は次のとおりである。
- 自社だけでは十分なデータが集まらない
- 特定ドメインの知見が不足している
- 自前開発よりもスピードが重要
- 標準規格や業界全体の取り組みとして進める必要がある
G検定では、「AIの社会実装には技術だけでなく、プライバシー・説明責任・リスク分類・ガバナンスなどの社会的論点が絡む」ことが問われやすい。
人と連携のブロックは、これらの議論への入り口としても意識しておくとよい。
拡大図(人/連携ブロック)
まとめ:究極カンペ(1枚)に圧縮する
最後に、因果関係図を左から右へ一本の線として思い出せるように整理する。
- 上流:
- ステークホルダーのニーズから出発する
- 「AIのビジネス活用」=価値やKPIに落とし込む
- ここがブレると、すべてが迷子になる
- 計画:
- CRISP-DM:分析プロジェクトの標準プロセス
- CRISP-ML:実装・運用まで意識した拡張
- アジャイル/ウォーターフォールは対立ではなく、状況に応じたハイブリッド
- 実行:
- BPR→データ整備→PoC→社会実装 が幹
- PoCで満足せず、「使われるAI」になるまで進めて初めて価値が出る
- 運用:
- MLOpsでモニタリングとライフサイクル管理を行う
- モデル・データ・コードのバージョン管理と再現性が重要
- 実装/基盤:
- Python・Jupyter・Docker・Web API・クラウドは、PoC・実装・運用を支える土台
- 人/連携:
- 職種横断チーム+外部連携が、データとPoCを前に進める推進力になる
試験直前に見るべき3行
- AIプロジェクトは「ニーズ→価値→プロセス→業務/データ→PoC→社会実装→MLOps→価値」のループで回る。
- CRISP-DM/CRISP-ML/アジャイル/ウォーターフォールは、このループのどこをどう支えるかで整理する。
- PoCで終わらせず、「誰がどう使い、どう運用し、どの価値指標で判断するか」までをセットで設計する。
FAQ
Q1. CRISP-DMとCRISP-MLの違いは何か?
- CRISP-DM:
- データ分析プロジェクトの標準プロセスモデル
- ビジネス理解→データ理解→準備→モデリング→評価→展開 を反復する
- CRISP-ML:
- 機械学習システムの実装・運用・品質管理まで含めて強化した枠組み
- MLOpsやリスク管理の観点が組み込まれている
→ 覚え方:
「CRISP-DM=分析プロセスの定番」「CRISP-ML=運用まで伸ばした拡張版」。
Q2. アジャイルとウォーターフォール、結局どっちが正解か?
どちらか一方が常に正解、ということはない。
- 不確実性が高い部分(要件不明・技術検証):アジャイル寄り
- 安全性・品質・法規制が重い部分(本番運用・インフラ):ウォーターフォール寄り
現実のプロジェクトでは、「アジャイルで探索→ウォーターフォール寄りに固めていく」といったハイブリッドが多い。
G検定では、「長所・短所と向いているフェーズ」を言語化できると強い。
Q3. PoCで終わって“お蔵入り”しないためには?
PoCの時点で、次の3点をセットで設計しておくことが重要である。
- 誰が、どの業務の中で、そのAIを使うのか(ユーザーと業務フロー)
- どのように運用し、誰が監視するのか(MLOpsの責任分界)
- どの価値指標(KPI)で、Go/No-Goを判断するのか
「動いたからOK」ではなく、「価値・運用・責任」まで見通してPoCを設計することで、実装フェーズへの橋がかかる。
Q4. さらに理解を深めるには?
より実務寄りに理解を広げたい場合は、次のキーワードを入り口にすると良い。
- モデル/データのガバナンス
- データ・モデルドリフト検知
- A/Bテスト、オンライン実験
- モデルレジストリ、特徴量管理
- 監査ログ、インシデント対応
- モデルカード/データカード
- 責任分界(RACIなど)
これらはすべて、因果関係図の「社会実装⇔MLOps⇔人/連携」の周辺にぶら下がる論点である。
以上で、「AIプロジェクトの進め方」の究極カンペは完成である。
この1枚の因果関係図を軸に、用語や事例を“上から吊るしていく”イメージで学習を進めてほしい。
参考文献(個人ブログ・企業ブログ・書籍を除外)
個人ブログ・企業ブログ・書籍を除き、百科事典・コミュニティサイト・学術寄りの情報源から選定しています。
- Cross-industry standard process for data mining(CRISP-DM)
Wikipedia
https://en.wikipedia.org/wiki/Cross-industry_standard_process_for_data_mining - CRISP-ML(Q) – A systematic process model for machine learning software development
ml-ops.org
https://ml-ops.org/content/crisp-ml - MLOps(日本語版)
ウィキペディア
https://ja.wikipedia.org/wiki/MLOps - Business process re-engineering
Wikipedia
https://en.wikipedia.org/wiki/Business_process_re-engineering - アジャイルソフトウェア開発
ウィキペディア日本語版
https://ja.wikipedia.org/wiki/%E3%82%A2%E3%82%B8%E3%83%A3%E3%82%A4%E3%83%AB%E3%82%BD%E3%83%95%E3%83%88%E3%82%A6%E3%82%A7%E3%82%A2%E9%96%8B%E7%99%BA
バックナンバーはこちら
深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト 第3版

徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版 徹底攻略シリーズ

ディープラーニングG検定(ジェネラリスト) 法律・倫理テキスト



コメント