要約
- 用語集カンペは「漏れ抜け防止」、究極カンペは「知識体系化」ですが、その間に初心者が気づきにくい乖離があります。
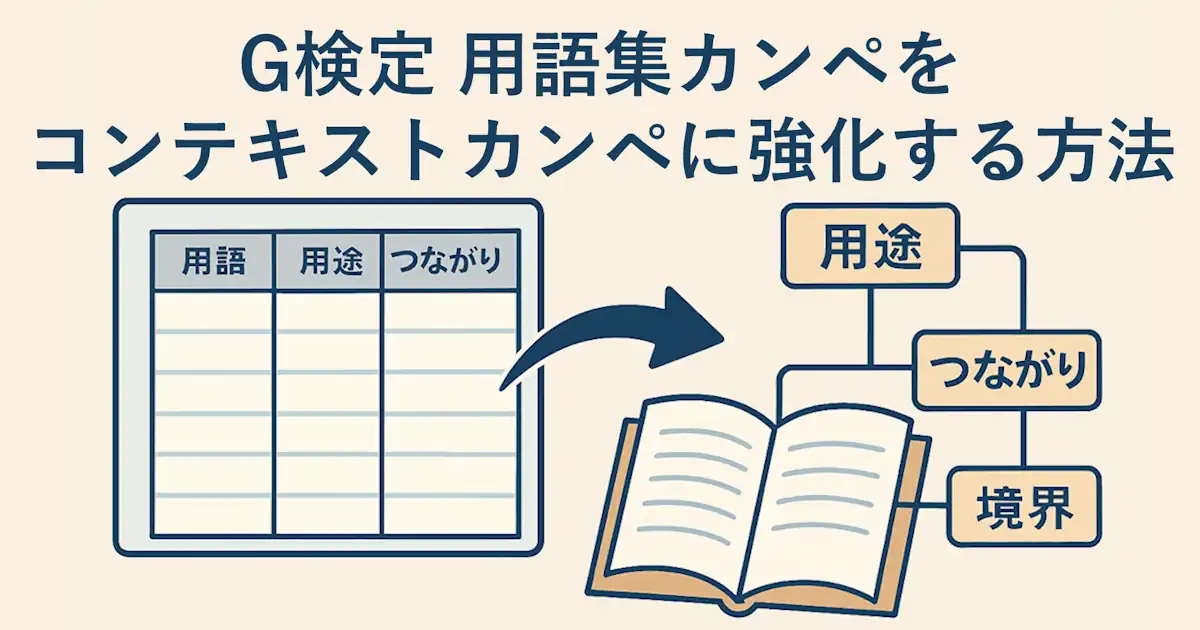
- 乖離は【用途・つながり・境界】で埋まり、用語集カンペを「コンテキストカンペ」に強化すると運用が崩れにくいです。
- 効果の本体は完成品ではなく作成プロセスで、調べる途中の“寄り道”が究極カンペへ至る芽になります。
動画解説

合わせて読むことおすすめの記事



二刀流の全体像
この記事では「カンペ」という言葉を使いますが、受験時に参照してズルするためのものではありません。学習用コンテンツとして、理解を育てるために使います。
G検定の学習を破綻させないために、ここでは次の二刀流を前提にします。
- 究極カンペ:実在するノートではなく、頭の中で育つ「知識体系(概念の地図)」です。
https://www.simulationroom999.com/blog/g-kentei-ultimate-kanpe-learning-method/ - 用語集カンペ(Excel):シラバスの用語を並べ、抜け漏れチェックと外部記憶として使う台帳です。
https://www.simulationroom999.com/blog/g-kentei-syllabus-2024-excel-glossary-cheatsheet/
二刀流の狙いは、「忘れないための台帳」と「つながるための地図」を分けて持つことです。これだけで学習の迷子が減ります。
初学者に見えない乖離
二刀流が機能しにくくなるポイントは、両者の“間”にあるギャップです。
- 用語集カンペは「名称 → 一言説明」の対応表になりやすいです。
- 究極カンペは「概念 → 判断(使い分け)→ 推論(つながり)」のネットワークです。
初学者はこの差を認識しにくく、次の状態に陥ります。
- 一言説明は覚えたのに、選択肢で切れません。
- 似た用語が並ぶと、境界が曖昧で落とします。
- 「分かった気」だけが増えます(説明できる気がするのに解けません)。
この「分かった気」は、説明知識に特有の錯覚として研究でも知られています。
https://doi.org/10.1207/S15516709COG2605_1
コンテキストカンペ
乖離の正体は、文脈リンク不足です。そこで、用語集カンペに「文脈」を追加して橋をかけます。
文脈は、次の3点に圧縮できます。
- 【用途】何を解決する?どんな場面で使う?
- 【つながり】前提は?関連概念・手法・指標は?どこに位置づく?
- 【境界】何と混同しやすい?いつ使えない?例外・限界・条件は?
この3点が揃うと、「定義」から「判断」へ移りやすくなります。
この強化版を、ここでは コンテキストカンペ と呼びます(実体は「用語集カンペの列追加」でOKです)。
用語集カンペをコンテキストカンペ化する手順
やることはシンプルです。
追加する列
用語集カンペ(Excel)の右側に、次の3列を追加します。
- 用途
- つながり
- 境界
入力ルール
ここを外すと燃え尽きます。
- 全部の用語を埋めません。
- 対象は次だけに絞ります。
- 理解度が低い(C/D)
- 過去問で間違えた/迷った
- 口頭で説明できない
- 1用語につき、各列は 1行(長文化禁止) にします。
- 境界は「混同語+見分けポイント1つ」を基本にします。
こうすると「網羅の台帳」は保ったまま、「弱点だけ文脈化」できます。
記入例(AlexNet・移動平均・GDPR)
以下3つは、用語集カンペからそれぞれ1行ずつ抜粋した行をベースに、コンテキスト(用途・つながり・境界)を追加した例です。
ここでは「正解を書き切る」より「書き方の型」を優先します。
| 章 | 用語(見出し/用語) | 用語集カンペの1行説明(既存) | 【用途】 | 【つながり】 | 【境界】 |
|---|---|---|---|---|---|
| ディープラーニングの応用例 | 画像認識 / AlexNet | ILSVRC2012で従来手法を大きく上回る精度を出しディープラーニングブームのきっかけとなった畳み込みニューラルネットワーク | 画像タスクで「CNNが何を変えたか」を掴み、以降のモデル理解(転移学習など)の起点にします。 | CNN、畳み込み/プーリング、ReLU、ドロップアウト、GPU学習、ImageNetとつながります。 | 「CNN一般」と混同しやすいです。AlexNetは“歴史的転換点の具体例”で、VGG/ResNetなどは発展形です。 |
| AI に必要な数理・統計知識 | 移動平均 | 一定期間のデータの平均を順番に計算して並べることで短期的な変動をならし傾向を見やすくする方法 | ノイズの多い時系列の傾向を見やすくし、比較や変化検知の前段に使います。 | 時系列、平滑化、窓幅(期間)、トレンド/季節性、指数平滑と関連します。 | 窓幅が大きいほど遅れて見え、急変を潰します。急な異常検知や即時性が重要な場面では使いにくいです。 |
| AIに関する法律と契約 | 個人情報保護法 / GDPR | EU域内の個人データ保護を包括的に定めた一般データ保護規則で日本の個人情報保護法にも影響を与えている規制 | 個人データの取扱い設計(同意・目的・越境移転など)を考えるための基準にします。 | 個人データ、匿名化/仮名化、データ主体の権利、処理の法的根拠、越境移転、DPIAとつながります。 | 「日本の個人情報保護法と同じ」とは限りません。域外適用や権利・義務の粒度など、適用範囲と要件を切り分けます。 |
参考として一次情報も貼っておきます。
- AlexNet(原典):https://papers.nips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
- 移動平均(定義例・NIST):https://www.itl.nist.gov/div898/handbook/pmc/section4/pmc421.htm
- GDPR(原文・EUR-Lex):https://eur-lex.europa.eu/eli/reg/2016/679/oj/eng
究極カンペへの道筋
コンテキストカンペは、究極カンペ(知識体系)への中継地点になります。ただし、重要なのは成果物そのものではなく、作る過程です。
他人のコンテキストが刺さりにくい理由
他人が作ったコンテキストは、あなたの脳内フックになりにくいです。これは精神論ではなく、学習の性質として自然です。
- 自分で生成した情報のほうが記憶に残りやすい(生成効果)
https://doi.org/10.1037/0278-7393.4.6.592 - 思い出す練習(検索)が理解と定着を押し上げます(テスト効果)
https://doi.org/10.1111/j.1467-9280.2006.01693.x - 検索練習は、精緻化学習より強い場合があります(概念マップ比較)
https://doi.org/10.1126/science.1199327
“寄り道”が芽になる
自分で調べていると、ターゲット用語以外の情報(前提概念、反例、関連指標、似た概念)が目に止まる瞬間があります。
この偶然の引っ掛かりこそが、究極カンペへ至るための芽になります。
つまり、次の関係です。
- コンテキストカンペ自体が究極カンペへ連れていくのではありません。
- コンテキストカンペを作成する過程そのものが、究極カンペへ至る道筋になります。
この道筋を捨てないようにしてください。
サンプル公開
用語集カンペ(Excel)はすでに公開しています。
https://www.simulationroom999.com/blog/g-kentei-syllabus-2024-excel-glossary-cheatsheet/
今回はこの用語集カンペをベースに、サンプルとして一部だけ「コンテキストカンペ化(用途・つながり・境界の追記)」したものを用意しました。
- 各章の先頭の用語だけ、用途・つながり・境界を埋めた「書き方見本」として加筆しています。
- 目的は「完成品の配布」ではなく、書き方の見本です。
- それ以外は、読者が自分で調べて埋める前提にします(効果の本体がそこにあります)。
ありがちな失敗と回避策
- 全用語をコンテキスト化して燃え尽きます。
→ C/D・誤答だけに絞ります。上限を「1日10語」などに固定すると続きます。 - 長文化して見返せないノートになります。
→ 各列1行にします。境界は「混同語+見分け1点」だけで十分です。 - 他人の完成品をコピペして満足します。
→ “寄り道”が起きないので究極カンペへ繋がりにくいです。見本は型の確認に使い、自分で調べて埋めます。
FAQ
コンテキストカンペは別ファイルにする必要があるか
必須ではありません。用語集カンペを母艦にして列追加し、フィルタで「埋めた行だけ」を表示する運用が一番破綻しにくいです。
3列(用途・つながり・境界)は全用語に書くべきか
書きません。理解度C/Dや誤答した用語だけに絞るほうが継続しやすく、成果も出やすいです。
境界には何を書けばよいか
混同しやすい用語名を1つ挙げて、「見分けポイントを1つ」書くのが最も効果的です。
サンプルを使えば、そのまま合格できるか
サンプルは書き方見本として有効です。ただし、究極カンペ(知識体系)につながるのは“自分で調べて埋める過程”なので、丸写しだけだと効果が薄くなりやすいです。
究極カンペと用語集カンペの考え方はどこで確認できるか
究極カンペと用語集カンペの考え方は、以下で整理しています。
https://www.simulationroom999.com/blog/g-kentei-ultimate-kanpe-learning-method/
https://www.simulationroom999.com/blog/g-kentei-syllabus-2024-excel-glossary-cheatsheet/
まとめ
用語集カンペをコンテキストカンペに強化する狙いは、「台帳(網羅)を守ったまま、文脈リンクを追加する」ことです。
究極カンペへ近づく本体は、完成品ではなく、調べて・迷って・つながりを拾う作成プロセスにあります。
試験対策としての効率と、その後の成長(知識体系化)を両立させるなら、この設計が一番崩れにくいです。
- まとめのまとめ
- 乖離は「定義」から「判断」へ移るための文脈不足です。
- 用語集カンペに【用途・つながり・境界】を弱点だけ追加すると埋まります。
- 効果の本体は完成品ではなく、作る過程(寄り道で芽が出る)です。
合わせて読むことおすすめの記事
参考文献
- Rozenblit, L., & Keil, F. (2002). The misunderstood limits of folk science: an illusion of explanatory depth. https://doi.org/10.1207/S15516709COG2605_1
- Slamecka, N. J., & Graf, P. (1978). The generation effect: Delineation of a phenomenon. https://doi.org/10.1037/0278-7393.4.6.592
- Roediger, H. L., & Karpicke, J. D. (2006). Test-enhanced learning: Taking memory tests improves long-term retention. https://doi.org/10.1111/j.1467-9280.2006.01693.x
- Karpicke, J. D., & Blunt, J. R. (2011). Retrieval practice produces more learning than elaborative studying with concept mapping. https://doi.org/10.1126/science.1199327
- Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet classification with deep convolutional neural networks(AlexNet原典PDF) https://papers.nips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
- NIST Engineering Statistics Handbook. Single moving average. https://www.itl.nist.gov/div898/handbook/pmc/section4/pmc421.htm
- EUR-Lex. Regulation (EU) 2016/679 (GDPR). https://eur-lex.europa.eu/eli/reg/2016/679/oj/eng
試験範囲の母艦
『深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト』

まずはここを母艦にすると、用語集カンペの「章・粒度」が安定します(=漏れ抜けチェックの精度が上がります)。シラバス改訂と第3版刊行の位置づけも公式に押さえられます。
ディープラーニングのコア(つながり列が太くなる)
『深層学習(Deep Learning)』(Ian Goodfellowほか/KADOKAWA)

「CNN/RNN/最適化/正則化」などが体系で繋がるので、つながり列を“丸ごと地図化”できます。
『深層学習』(岡谷貴之/講談社サイエンティフィク)

比較的日本語で追いやすく、近年の話題(トランスフォーマー等)も含めて整理しやすいです。
機械学習の基礎理論(境界列が強くなる)
『パターン認識と機械学習(上)(下)ベイズ理論による統計的予測』(C.M. Bishop/日本語版)

「なぜその手法か」「何と何が似ていて何が違うか」を理詰めで分けられるので、境界列の説得力が一段上がります。
講談社サイエンティフィク『機械学習プロフェッショナルシリーズ』

トピック別に薄めで刺さるので、用語ごとに「この1冊でつながりを補う」がやりやすいです。シリーズ全体の棚として便利です。
確率・統計(移動平均など“数理の用途/限界”を埋める)
『統計学入門』(東京大学教養学部統計学教室 編/東京大学出版会)

統計を「道具として何をするか」に寄せて学べるので、用途列と「いつ使えないか(限界)」の言語化がしやすいです。
『機械学習のための確率と統計』(杉山将/講談社)

機械学習に必要な確率統計に絞っているので、G検定寄りの「最短でつながりを作る」用途に向きます。
社会実装・運用(用途列が“実務の言葉”になる)
『機械学習システムデザイン ―実運用レベルのアプリケーションを実現する継続的反復プロセス』(Chip Huyen/O’Reilly Japan)

「精度を上げる」ではなく「何の価値を出すか」「監視/再学習/データ品質」まで含めて書けるようになり、用途列が一気に実戦的になります。
法律・倫理・ガバナンス(境界列の“条件・例外”が書ける)
『AIガバナンス入門 ―リスクマネジメントから社会設計まで―』(羽深宏樹/早川書房)

「AI倫理を実務の枠組みに落とす」入口に良く、用途(なぜ必要か)とつながり(ガバナンス全体像)が作れます。
『AIの倫理リスクをどうとらえるか――実装のための考え方』(リード・ブラックマン/白揚社)

倫理を“スローガン”で終わらせず、運用に落とす観点が得られるので、境界(法令順守≠倫理OK)の言語化が強くなります。
『AIと法 実務大全』(日本加除出版)

開発者/提供者/利用者の論点で整理されており、境界列(何がアウトで、どこがグレーか)に実務の根拠を入れたいときのリファレンスになります。
『生成AIの法律実務』(弘文堂)

生成AI周りの論点を実務目線でまとめた系統の本として、G検定の近年トピック(生成AI・契約・知財)に寄せて補強しやすいです

コメント