その他のエッセイはこちら

本記事のG検定向けエッセンシャル版
本記事は以下のシリーズ記事の統合再編版です。
ゆるーい雰囲気でゆっくり読みたい人は以下のシリーズ記事の方がおすすめです。

上記シリーズ記事の統合版シリーズが含まれています。
上記がゆるすぎる場合は、以下シリーズの方が読み易いかもしれません。
(このシリーズ記事から読む方がおすすめです。)

シリーズ記事側はPythonだけでなく、MATLAB,Scilab,Juliaも使用。
- 要約
- 注意
- 射程
- 実務版ロードマップ
- ニューラルネットワーク
- パーセプトロンと決定境界
- 共通コード
- 総当たりで分類位置を特定
- カスタムヘビサイド
- 活性化関数比較
- 決定境界比較
- シグモイド
- シグモイドの導関数導出
- シグモイド統一の副作用
- ロジスティック回帰
- 交差エントロピーとlog
- logが自信満々の誤りを強く罰する理由
- 修正信号が強くなる理由
- 単層学習(NumPy)
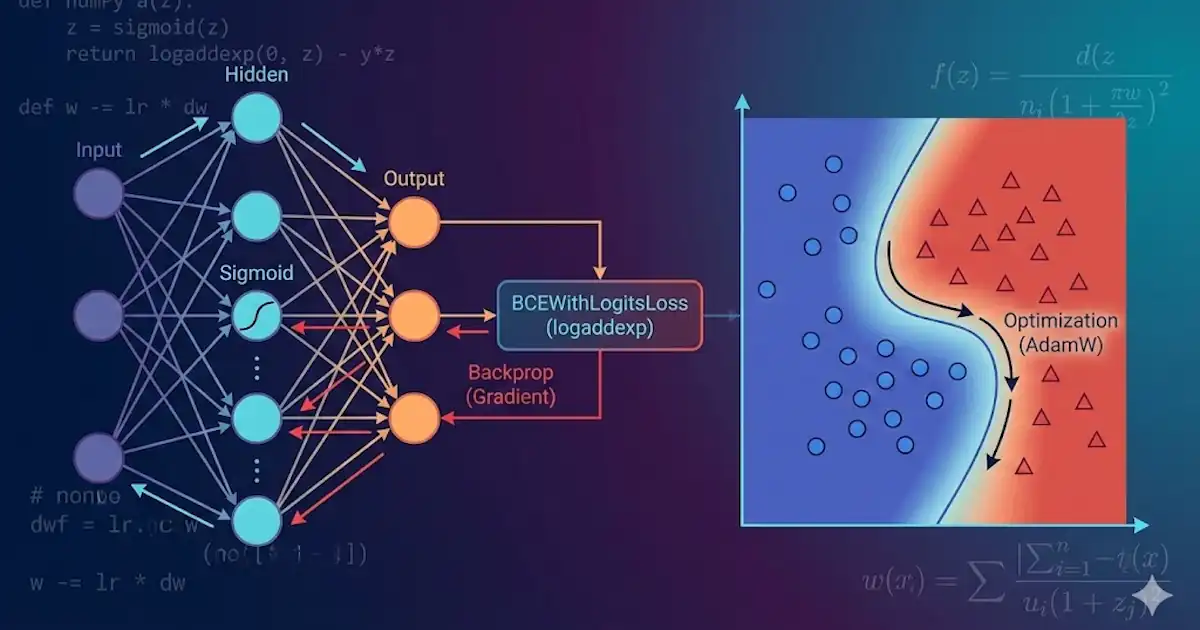
- BCEWithLogitsLoss
- 確率BCEとlogits BCEが同じになる導出
- logaddexp
- BCEWithLogitsLossが安定な理由
- logits可視化
- logits側の損失(自信満々の誤り)
- logits方向の勾配
- クラス不均衡とpos_weight
- 逆伝播と計算グラフ
- 多層ニューラルネットワーク
- XORと決定境界
- 勾配チェック(数値微分)
- 最適化アルゴリズム(分子と分母、1次と2次)
- 最適化アルゴリズムの関係性
- 見取り図(関係性の一枚まとめ)
- 最適化アルゴリズムの更新式
- AdamWとL2正則化の違い
- 等高線で見る最適化
- どれをいつ使うか(失敗パターン別)
- 実務版への最短ブリッジ(NumPyの式→PyTorch API)
- FAQ
- まとめ
- 参考文献
- NumPyで“手で作って腹落ち”する(逆伝播・最適化まで)
- 単層=ロジスティック回帰、BCE、logの意味を“理屈で締める”
- “2026年の実務デフォルト”へ最短で視野を広げる(ReLU系・正則化・最適化)
- 最適化を「1次/2次」「分子/分母」「なまし(平滑化)」で整理したい
- 実務ブリッジ(PyTorch、BCEWithLogits、AdamW、pos_weight への移行)
- 迷ったときの読み順(記事の流れに合わせる)
要約
- ニューラルネットは「線形変換+活性化関数」を重ねた合成関数として整理できます。
- 交差エントロピーのlogは「自信満々の誤り」を強く罰し、修正信号も強くなります。
- 実務へ移るならBCEWithLogitsLoss(logaddexp)とAdamWを軸にすると移行がスムーズです。
注意
数式モデルとPythonコードは補足扱いなので、読み飛ばしても記事として理解できるように書きます。実装はNumPy中心で進め、可視化にはmatplotlibを使います。
射程
このページは、決定境界の可視化→誤差逆伝播→損失(BCE/BCEWithLogitsLoss)→最適化の流れを、シグモイドで統一してつなぐ入門です。
これは2026年の実務デフォルトではないです。入門として導関数と逆伝播の道筋を追いやすくするためにシグモイドで統一し、実務側の定石はロードマップとブリッジで接続します。
シグモイド統一の意図(誤用防止)
- 本文は隠れ層も含めてシグモイドで統一して説明します(導関数が明確で、逆伝播の筋が追いやすいからです)。
- 実務では、隠れ層はReLU系に置き換えるのが普通です(深くするとシグモイドは飽和で勾配が小さくなりやすいからです)。
- 出力層と損失はタスクに合わせ、二値分類なら「logits→BCEWithLogitsLoss」、多クラス分類なら「logits→softmax付き交差エントロピー」へ移行します。
実務版ロードマップ
本文はシグモイドで統一しますが、実務へ移るときは次の構成に置き換えるのが一般的です。
- 隠れ層の活性化関数:ReLU系(ReLU / LeakyReLU / GELUなど)
- 正規化:必要ならBatchNorm(CNNで頻出)またはLayerNorm(Transformerで頻出)
- 最適化:AdamW(decoupled weight decay)
- 学習率:スケジュール込み(cosine / step / OneCycleなど)
- 損失:二値分類ならBCEWithLogitsLoss相当(logitsから数値安定に計算)
- 正則化:weight decay、dropout、データ拡張など
深掘りの導線
- https://cs231n.github.io/neural-networks-1/
- https://cs231n.github.io/neural-networks-2/
- https://cs231n.github.io/neural-networks-3/
ニューラルネットワーク
ニューラルネットは、入力$x$を出力へ写す関数をデータから学習して作る枠組みです。最小部品は次の2つです。
- 線形変換:$z = w^\top x + b$
- 活性化関数:$a = f(z)$
この「線形→非線形」を層として重ねると、直線(線形)だけでは表現できない関係を表せるようになります。
パーセプトロンと決定境界
2次元入力$x=(x_1,x_2)$のとき、$w^\top x + b = 0$は平面上の直線で、これが決定境界です。
ヘビサイド関数(ステップ関数)を活性化関数にすると、出力は0/1に確定します。
$$
H(z)=\begin{cases}
1&(z\ge 0)\\
0&(z<0)
\end{cases}
$$
分かりやすい一方で、境界付近の「確信度」が出力に残りません。まずは決定境界を見てから、連続値の活性化へ移ります。
共通コード
import numpy as np
import matplotlib.pyplot as plt
def heaviside(z):
return (z >= 0).astype(np.float64)
def custom_heaviside(z, eps=1.0):
z = np.asarray(z)
out = np.empty_like(z, dtype=np.float64)
out[z <= -eps] = 0.0
out[z >= eps] = 1.0
mid = (z > -eps) & (z < eps)
out[mid] = (z[mid] + eps) / (2*eps)
return out
def sigmoid(z):
z = np.asarray(z)
pos = z >= 0
neg = ~pos
out = np.empty_like(z, dtype=np.float64)
out[pos] = 1.0 / (1.0 + np.exp(-z[pos]))
ez = np.exp(z[neg])
out[neg] = ez / (1.0 + ez)
return out
def bce_loss_from_prob(a, y, eps=1e-12):
a = np.clip(a, eps, 1 - eps)
return -(y*np.log(a) + (1-y)*np.log(1-a)).mean()
def bce_loss_from_logits(z, y):
# BCEWithLogitsLoss相当:L = logaddexp(0,z) - y*z
return (np.logaddexp(0.0, z) - y*z).mean()
def plot_decision_region_2d(
predict_proba_fn,
X, y,
title="",
padding=0.6,
grid_step=0.02,
threshold=0.5,
):
fig, ax = plt.subplots(figsize=(6, 4))
x_min, x_max = X[:, 0].min() - padding, X[:, 0].max() + padding
y_min, y_max = X[:, 1].min() - padding, X[:, 1].max() + padding
xs = np.arange(x_min, x_max, grid_step)
ys = np.arange(y_min, y_max, grid_step)
xx, yy = np.meshgrid(xs, ys)
grid = np.c_[xx.ravel(), yy.ravel()]
proba = predict_proba_fn(grid).reshape(-1)
zz = proba.reshape(xx.shape)
cf = ax.contourf(xx, yy, zz, levels=30, alpha=0.35)
ax.contour(xx, yy, zz, levels=[threshold], linewidths=2)
X0 = X[y == 0]
X1 = X[y == 1]
ax.scatter(X0[:, 0], X0[:, 1], s=25, marker="o", label="class 0")
ax.scatter(X1[:, 0], X1[:, 1], s=25, marker="^", label="class 1")
ax.set_title(title)
ax.set_xlim(x_min, x_max)
ax.set_ylim(y_min, y_max)
ax.legend(loc="best")
plt.colorbar(cf, ax=ax, label="model output")
plt.tight_layout()
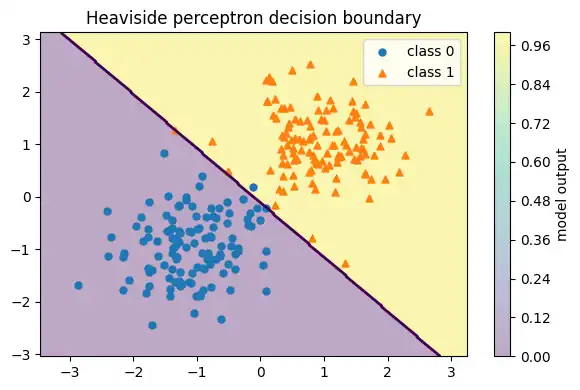
plt.show()総当たりで分類位置を特定
2Dなら「重みの向き」と「バイアス」を走査して、当たりやすい境界を探せます。線形分離の直感を作る目的です。
rng = np.random.default_rng(0)
N = 120
X0 = rng.normal(loc=(-1.0, -1.0), scale=0.6, size=(N, 2))
X1 = rng.normal(loc=(+1.0, +1.0), scale=0.6, size=(N, 2))
X = np.vstack([X0, X1])
y = np.concatenate([np.zeros(N), np.ones(N)])
def perceptron_pred(X, w, b):
return heaviside(X @ w + b)
def acc_for_params(X, y, w, b):
pred = perceptron_pred(X, w, b)
return (pred == y).mean()
thetas = np.linspace(0, 2*np.pi, 720, endpoint=False)
bs = np.linspace(-3.0, 3.0, 601)
best_acc = -1.0
best_w, best_b = None, None
for theta in thetas:
w_dir = np.array([np.cos(theta), np.sin(theta)])
for b in bs:
a = acc_for_params(X, y, w_dir, b)
if a > best_acc:
best_acc = a
best_w, best_b = w_dir.copy(), float(b)
best_acc, best_w, best_b実行結果
(np.float64(0.9958333333333333),
array([0.7193398 , 0.69465837]),
0.08000000000000007)plot_decision_region_2d(
lambda G: perceptron_pred(G, best_w, best_b),
X, y,
title="Heaviside perceptron decision boundary"
)
カスタムヘビサイド
ここで紹介するカスタム・ヘビサイドは学習のためではないです。ヘビサイドの「崖」を斜めにすると中間値が出る、という直感を作るための説明用です。
$$
\tilde{H}(z)=\begin{cases}
0&(z\le -\epsilon)\\
\displaystyle \frac{z+\epsilon}{2\epsilon}&(-\epsilon<z<\epsilon)\\
1&(z\ge \epsilon)
\end{cases}
$$
活性化関数比較
z = np.linspace(-6, 6, 2000)
plt.figure(figsize=(6, 4))
plt.plot(z, heaviside(z), label="Heaviside")
plt.plot(z, custom_heaviside(z, eps=1.0), label="Custom Heaviside")
plt.plot(z, sigmoid(z), label="Sigmoid")
plt.title("Activation functions")
plt.xlabel("z")
plt.ylabel("output")
plt.ylim(-0.1, 1.1)
plt.legend()
plt.tight_layout()
plt.show()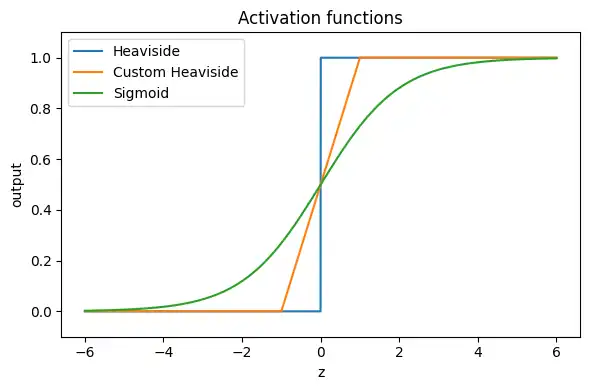
決定境界比較
def plot_decision_region_2d_ax(
ax,
predict_proba_fn,
X, y,
title="",
padding=0.6,
grid_step=0.02,
threshold=0.5,
):
x_min, x_max = X[:, 0].min() - padding, X[:, 0].max() + padding
y_min, y_max = X[:, 1].min() - padding, X[:, 1].max() + padding
xs = np.arange(x_min, x_max, grid_step)
ys = np.arange(y_min, y_max, grid_step)
xx, yy = np.meshgrid(xs, ys)
grid = np.c_[xx.ravel(), yy.ravel()]
proba = predict_proba_fn(grid).reshape(-1)
zz = proba.reshape(xx.shape)
cf = ax.contourf(xx, yy, zz, levels=30, alpha=0.35)
ax.contour(xx, yy, zz, levels=[threshold], linewidths=2)
X0 = X[y == 0]
X1 = X[y == 1]
ax.scatter(X0[:, 0], X0[:, 1], s=25, marker="o", label="class 0")
ax.scatter(X1[:, 0], X1[:, 1], s=25, marker="^", label="class 1")
ax.set_title(title)
ax.set_xlim(x_min, x_max)
ax.set_ylim(y_min, y_max)
plt.colorbar(cf, ax=ax, label="model output")
def heaviside_proba(G):
return heaviside(G @ best_w + best_b)
def custom_proba(G, eps=0.7):
return custom_heaviside(G @ best_w + best_b, eps=eps)
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
plot_decision_region_2d_ax(axes[0], heaviside_proba, X, y, title="Heaviside decision region")
plot_decision_region_2d_ax(axes[1], lambda G: custom_proba(G, eps=0.7), X, y, title="Custom Heaviside decision region")
for ax in axes:
ax.legend(loc="best")
plt.tight_layout()
plt.show()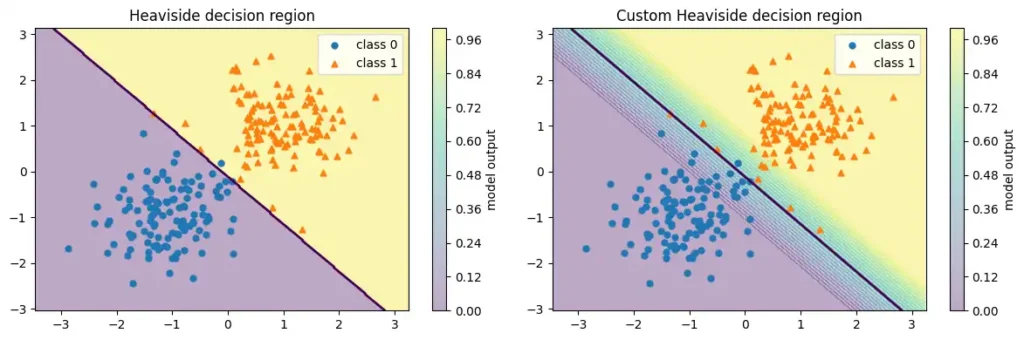
シグモイド
シグモイドは次の関数です。
$$
\sigma(z)=\displaystyle \frac{1}{1+e^{-z}}
$$
出力が0~1の連続値になるため、境界付近の確信度が出力に残ります。ここから学習(逆伝播)へつながります。
シグモイドの導関数導出
$$
\sigma(z)=\displaystyle \frac{1}{1+e^{-z}}
=\displaystyle \frac{e^{z}}{e^{z}+1}
$$
分子$u=e^{z}$、分母$v=e^{z}+1$と置くと$u’=e^{z}$、$v’=e^{z}$なので、商の微分から次になります。
$$
\begin{aligned}
\sigma'(z)
&=\displaystyle \frac{u’v-uv’}{v^2}\\
&=\displaystyle \frac{e^{z}(e^{z}+1)-e^{z}\cdot e^{z}}{(e^{z}+1)^2}\\
&=\displaystyle \frac{e^{z}}{(e^{z}+1)^2}
\end{aligned}
$$
$$
\sigma(z)=\displaystyle \frac{e^{z}}{e^{z}+1},
\quad
1-\sigma(z)=\displaystyle \frac{1}{e^{z}+1}
$$
なので
$$
\sigma(z)\left(1-\sigma(z)\right)
=\displaystyle \frac{e^{z}}{(e^{z}+1)^2}
$$
結論です。
$$
\sigma'(z)=\sigma(z)\left(1-\sigma(z)\right)
$$
シグモイド統一の副作用
シグモイドは$z$が大きく正か負に振れると出力が0か1に近づき、導関数$\sigma'(z)$が小さくなります。逆伝播は局所微分の掛け算なので、深くすると勾配が小さくなりやすいです。
z = np.linspace(-10, 10, 2000)
s = sigmoid(z)
ds = s * (1 - s)
plt.figure(figsize=(7, 4))
plt.plot(z, ds, label="sigmoid'(z) = sigmoid(z)(1 - sigmoid(z))")
plt.axhline(0.25, linestyle="--", label="maximum = 0.25")
plt.title("Sigmoid derivative and saturation")
plt.xlabel("z")
plt.ylabel("sigmoid'(z)")
plt.ylim(-0.01, 0.27)
plt.legend()
plt.tight_layout()
plt.show()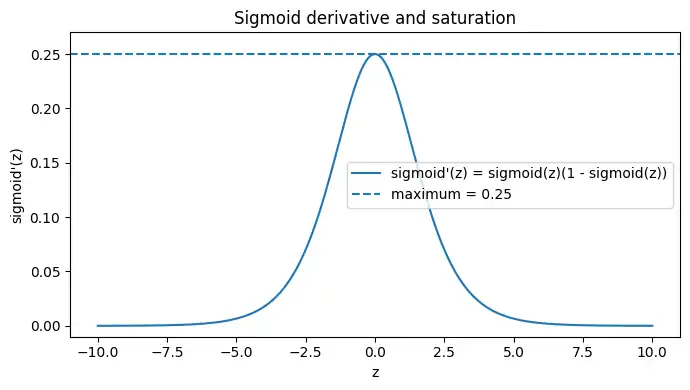
ロジスティック回帰
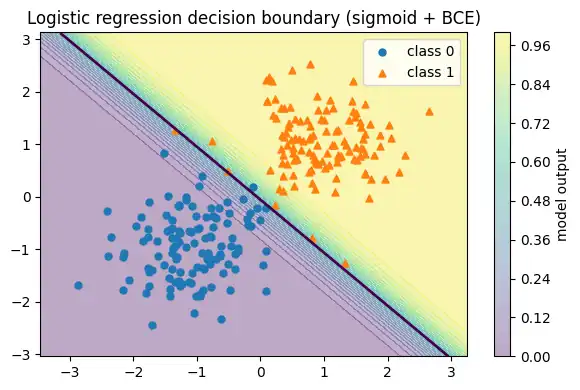
単層(シグモイド1個)でBCEを最小化するモデルは、ロジスティック回帰と同じ位置づけです。決定境界が直線になることと、更新の核が「予測-正解」になることが同時に整理できます。
交差エントロピーとlog
二値分類では、出力$a\in(0,1)$を「$y=1$である確率」と解釈します。このとき1件の尤度はベルヌーイとして次です。
$$
P(y\mid a)=a^{y}(1-a)^{(1-y)}
$$
データが複数になると尤度は掛け算になります。掛け算は数値が極端に小さくなりやすく、式の見通しも悪くなります。対数を取ると掛け算が足し算に変わり、扱いやすくなります。
$$
\log \prod_i P(y_i\mid a_i)=\sum_i \log P(y_i\mid a_i)
$$
確からしさを最大化したいので、負号を付けて最小化にします。これが二値交差エントロピー(BCE)です。
$$
L(a,y)=-(y\log a+(1-y)\log(1-a))
$$
logには「自信満々で外したときに強く罰する」性質もあります。
logが自信満々の誤りを強く罰する理由
a = np.linspace(1e-6, 1 - 1e-6, 2000)
loss_y1 = -np.log(a) # y=1
loss_y0 = -np.log(1 - a) # y=0
plt.figure(figsize=(7, 4))
plt.plot(a, loss_y1, label="y=1: -log(a)")
plt.plot(a, loss_y0, label="y=0: -log(1-a)")
plt.ylim(0, 14)
plt.title("Binary cross-entropy penalty vs confidence")
plt.xlabel("predicted probability a = P(y=1)")
plt.ylabel("loss")
plt.legend()
plt.tight_layout()
plt.show()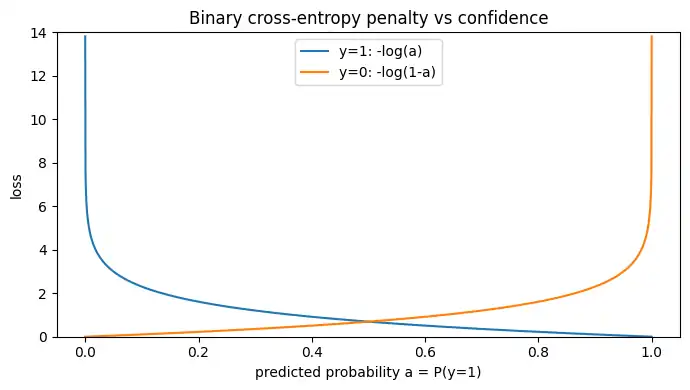
修正信号が強くなる理由
$y=1$のとき$\left|\displaystyle \frac{\partial L}{\partial a}\right|=\displaystyle \frac{1}{a}$、$y=0$のとき$\left|\displaystyle \frac{\partial L}{\partial a}\right|=\displaystyle \frac{1}{1-a}$になり、外した側に確信が寄るほど勾配が大きくなります。
a = np.linspace(1e-6, 1 - 1e-6, 2000)
gradmag_y1 = 1.0 / a
gradmag_y0 = 1.0 / (1 - a)
plt.figure(figsize=(7, 4))
plt.plot(a, gradmag_y1, label="y=1: |dL/da| = 1/a")
plt.plot(a, gradmag_y0, label="y=0: |dL/da| = 1/(1-a)")
plt.yscale("log")
plt.title("Gradient magnitude vs confidence")
plt.xlabel("predicted probability a = P(y=1)")
plt.ylabel("|dL/da| (log scale)")
plt.legend()
plt.tight_layout()
plt.show()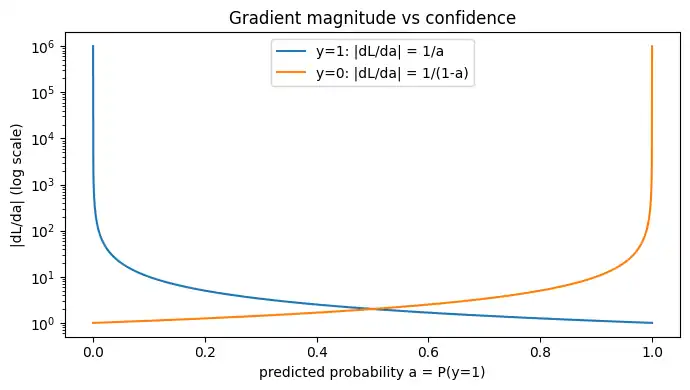
単層学習(NumPy)
def train_single_neuron_sgd(X, y, lr=0.2, steps=2000, seed=1):
rng = np.random.default_rng(seed)
n, d = X.shape
w = rng.normal(scale=0.1, size=(d,))
b = 0.0
for _ in range(steps):
z = X @ w + b
a = sigmoid(z)
dz = (a - y) / n
dw = X.T @ dz
db = dz.sum()
w -= lr * dw
b -= lr * db
return w, b
w_hat, b_hat = train_single_neuron_sgd(X, y)
w_hat, b_hat実行結果
(array([4.22377473, 4.18478961]), np.float64(0.2416758192421703))plot_decision_region_2d(
lambda G: sigmoid(G @ w_hat + b_hat),
X, y,
title="Logistic regression decision boundary (sigmoid + BCE)"
)
BCEWithLogitsLoss
本文は説明の都合で確率$a$を使いますが、実務ではlogits(シグモイドの手前の値)$z$から直接BCEを計算するのが定石です。$|z|$が大きいと$a=\sigma(z)$が0や1に極端に寄り、$\log(a)$や$\log(1-a)$が数値的に不安定になりやすいからです。
logitsでのBCEは次の形に整理できます。
$$
L(z,y)=\log(1+\exp(z)) – y\cdot z
$$
確率BCEとlogits BCEが同じになる導出
確率で書いたBCEは次です。
$$
L(a,y)=-(y\log a+(1-y)\log(1-a))
$$
$a=\sigma(z)=\displaystyle \frac{1}{1+e^{-z}}$とします。まず $y=1$ と $y=0$ の形を確認します。
$$
-\log \sigma(z)=\log(1+e^{-z})
$$
$$
-\log(1-\sigma(z))=\log(1+e^{z})
$$
したがって一般の$y\in{0,1}$では
$$
L(z,y)=y\log(1+e^{-z})+(1-y)\log(1+e^{z})
$$
ここで次の恒等式を使います。
$$
\log(1+e^{-z})=\log(1+e^{z})-z
$$
これを代入すると
$$
\begin{aligned}
L(z,y)
&=y(\log(1+e^{z})-z)+(1-y)\log(1+e^{z})\\
&=\log(1+e^{z})-y\cdot z
\end{aligned}
$$
結論です。
$$
L(z,y)=\log(1+\exp(z)) – y\cdot z
$$
logaddexp
logaddexp は次を安定に計算するための関数です。
$$
\operatorname{logaddexp}(a,b)=\log(\exp(a)+\exp(b))
$$
特に $a=0$ の場合は次です。
$$
\operatorname{logaddexp}(0,z)=\log(1+\exp(z))
$$
なぜ安定か
次の恒等式で、指数が暴走しにくい形に変形できます。
$$
\log(\exp(a)+\exp(b))
=\max(a,b)+\log\left(1+\exp(-|a-b|)\right)
$$
この右辺では $-|a-b|\le 0$ なので、$\exp(-|a-b|)$ は $0$ から $1$ の範囲に収まり、計算が安定しやすくなります。
BCEWithLogitsLossが安定な理由
Sigmoid + BCELoss は、いったん確率 $a=\sigma(z)$ を作ってから $\log(a)$ や $\log(1-a)$ を計算します。$z$ が大きいと $a$ が0または1に飽和し、数値的に潰れやすくなります。
一方で BCEWithLogitsLoss は、確率を経由せずsoftplus(log-sum-exp系)として計算できるため安定します。
- $y=1$のとき $L=\operatorname{logaddexp}(0,-z)$
- $y=0$のとき $L=\operatorname{logaddexp}(0,z)$
これをまとめると次です。
$$
L(z,y)=(1-y)\operatorname{logaddexp}(0,z)+y\operatorname{logaddexp}(0,-z)
$$
さらに恒等式
$$
\operatorname{logaddexp}(0,-z)=\operatorname{logaddexp}(0,z)-z
$$
を使うと、よく見る一行の形に落ちます。
$$
L(z,y)=\operatorname{logaddexp}(0,z)-y\cdot z
$$
logits可視化
z = np.linspace(-12, 12, 2000)
a = sigmoid(z)
plt.figure(figsize=(7, 4))
plt.plot(z, a, label="a = sigmoid(z)")
plt.title("Logits to probability (sigmoid mapping)")
plt.xlabel("logit z")
plt.ylabel("probability a")
plt.ylim(-0.05, 1.05)
plt.legend()
plt.tight_layout()
plt.show()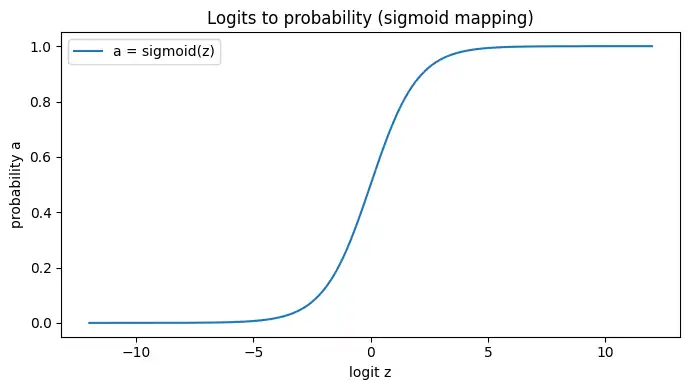
logits側の損失(自信満々の誤り)
z = np.linspace(-12, 12, 2000)
loss_y1 = np.logaddexp(0.0, -z) # y=1
loss_y0 = np.logaddexp(0.0, z) # y=0
plt.figure(figsize=(7, 4))
plt.plot(z, loss_y1, label="y=1: logaddexp(0, -z)")
plt.plot(z, loss_y0, label="y=0: logaddexp(0, z)")
plt.title("BCEWithLogits loss vs logit z")
plt.xlabel("logit z")
plt.ylabel("loss")
plt.ylim(0, 14)
plt.legend()
plt.tight_layout()
plt.show()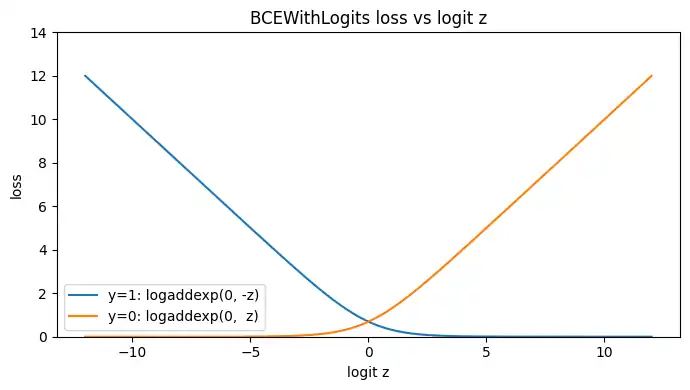
logits方向の勾配
BCEWithLogitsの定番形は、logits $z$ に対する勾配が $a-y$ に整理できる点です。
$$
\frac{\partial L}{\partial z}=\sigma(z)-y
$$
z = np.linspace(-12, 12, 2000)
a = sigmoid(z)
grad_y1 = a - 1.0 # y=1
grad_y0 = a - 0.0 # y=0
plt.figure(figsize=(7, 4))
plt.plot(z, grad_y1, label="y=1: dL/dz = sigmoid(z) - 1")
plt.plot(z, grad_y0, label="y=0: dL/dz = sigmoid(z)")
plt.axhline(0.0, linestyle="--")
plt.title("Gradient wrt logit z (dL/dz)")
plt.xlabel("logit z")
plt.ylabel("dL/dz")
plt.legend()
plt.tight_layout()
plt.show()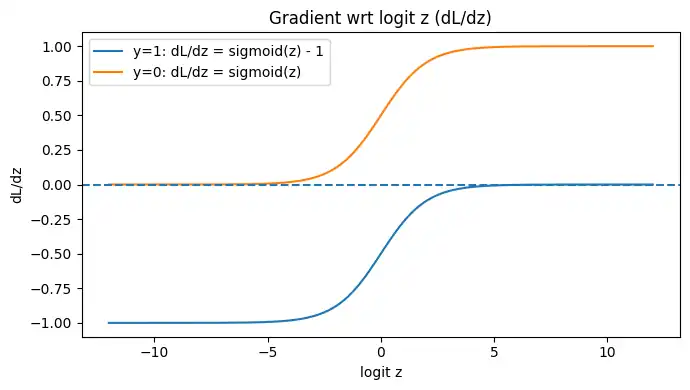
クラス不均衡とpos_weight
二値分類の現場では、正例が希少(不均衡)なケースがよく出ます。損失側で正例に重みを付けて学習信号を強める方法がよく使われます。
PyTorchのBCEWithLogitsLossはpos_weightを持ち、正例に重み$p$を掛けられます。
https://docs.pytorch.org/docs/stable/generated/torch.nn.BCEWithLogitsLoss.html
softplus(logaddexp)で書くと次になります。
$$
L(z,y)= (1-y)\operatorname{logaddexp}(0,z) + p,y\operatorname{logaddexp}(0,-z)
$$
NumPy側の対応式です。
def bce_with_logits_pos_weight(z, y, p):
return ((1-y)*np.logaddexp(0.0, z) + p*y*np.logaddexp(0.0, -z)).mean()逆伝播と計算グラフ
誤差逆伝播は、計算グラフ上で局所微分をつなぐ手続きです。
- 前向き:各ノードの出力を計算して保存します($z$や$a$など)
- 逆向き:出力側から勾配を流し、各ノードで「受け取った勾配×局所微分」を前へ渡します
活性化関数は導関数が分かるほど扱いやすいです。一方で実務の代表格ReLUは0で微分不能ですが、ほぼ至る所で微分可能で、実装ではサブグラディエント(慣例的な局所微分の割り当て)を使って計算グラフを回します。
連鎖律(合成関数の微分)の証明
$y=f(u)$、$u=g(x)$、$y=f(g(x))$とします。
$$
\frac{dy}{dx}
=\lim_{h\to 0}\frac{f(g(x+h))-f(g(x))}{h}
$$
$\Delta u=g(x+h)-g(x)$と置きます。
$$
\frac{f(g(x+h))-f(g(x))}{h}
\left(\frac{f(g(x+h))-f(g(x))}{\Delta u}\right)
\left(\frac{\Delta u}{h}\right)
$$
$h\to 0$で$\Delta u\to 0$なので
$$
\lim_{h\to 0}\left(\frac{f(g(x+h))-f(g(x))}{\Delta u}\right)=f'(g(x)),
\quad
\lim_{h\to 0}\left(\frac{\Delta u}{h}\right)=g'(x)
$$
より
$$
\frac{dy}{dx}=f'(g(x))\cdot g'(x)
$$
多層ニューラルネットワーク
単層モデルは直線境界に限られます。多層化すると非線形の合成になり、曲がった境界や複数領域を表現できるようになります。
$$
z^{(l)} = W^{(l)}a^{(l-1)} + b^{(l)}
$$
$$
a^{(l)} = f\left(z^{(l)}\right)
$$
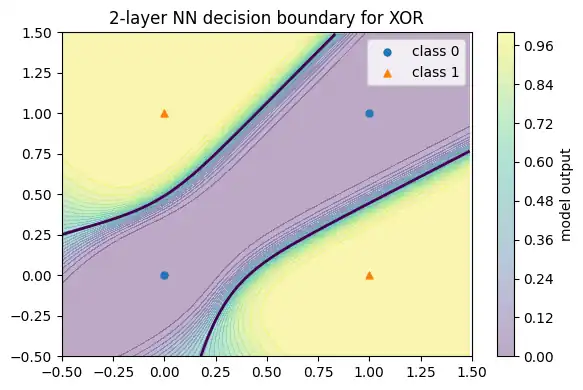
XORと決定境界
XORは直線で分離できないので単層では解けません。2層にすると解けるようになります。目的関数は二値交差エントロピー(BCE)で、出力層はシグモイドとします。
def init_params(d_in, d_hid, d_out, seed=0):
rng = np.random.default_rng(seed)
W1 = rng.normal(scale=0.5, size=(d_in, d_hid))
b1 = np.zeros((d_hid,))
W2 = rng.normal(scale=0.5, size=(d_hid, d_out))
b2 = np.zeros((d_out,))
return {"W1":W1, "b1":b1, "W2":W2, "b2":b2}
def forward_2layer(X, p):
z1 = X @ p["W1"] + p["b1"]
a1 = sigmoid(z1)
z2 = a1 @ p["W2"] + p["b2"]
a2 = sigmoid(z2)
cache = {"X":X, "a1":a1, "a2":a2}
return a2, cache
def backward_2layer(y, cache, p):
X, a1, a2 = cache["X"], cache["a1"], cache["a2"]
n = X.shape[0]
dz2 = (a2 - y) / n
dW2 = a1.T @ dz2
db2 = dz2.sum(axis=0)
da1 = dz2 @ p["W2"].T
dz1 = da1 * (a1 * (1 - a1))
dW1 = X.T @ dz1
db1 = dz1.sum(axis=0)
return {"W1":dW1, "b1":db1, "W2":dW2, "b2":db2}
X_xor = np.array([[0,0],[0,1],[1,0],[1,1]], dtype=np.float64)
y_xor = np.array([[0],[1],[1],[0]], dtype=np.float64)
p = init_params(2, 4, 1, seed=1)
lr = 1.0
for _ in range(5000):
a2, cache = forward_2layer(X_xor, p)
grads = backward_2layer(y_xor, cache, p)
for k in p:
p[k] -= lr * grads[k]plot_decision_region_2d(
lambda G: forward_2layer(G, p)[0].reshape(-1),
X_xor, y_xor.reshape(-1),
title="2-layer NN decision boundary for XOR",
padding=0.5,
grid_step=0.01
)
勾配チェック(数値微分)
NumPy実装では、逆伝播が合っているかを数値微分で一度だけ確認すると安心感が増します。ここでは出力層をlogitsとして扱い、BCEWithLogitsLoss相当でチェックします。
def forward_2layer_logits(X, p):
z1 = X @ p["W1"] + p["b1"]
a1 = sigmoid(z1)
z2 = a1 @ p["W2"] + p["b2"] # logits
a2 = sigmoid(z2)
cache = {"X": X, "a1": a1, "z2": z2, "a2": a2}
return z2, a2, cache
def loss_2layer_bcewithlogits(X, y, p):
z2, _, _ = forward_2layer_logits(X, p)
return bce_loss_from_logits(z2, y)
def backward_2layer_logits(y, cache, p):
X, a1, a2 = cache["X"], cache["a1"], cache["a2"]
n = X.shape[0]
dz2 = (a2 - y) / n
dW2 = a1.T @ dz2
db2 = dz2.sum(axis=0)
da1 = dz2 @ p["W2"].T
dz1 = da1 * (a1 * (1 - a1))
dW1 = X.T @ dz1
db1 = dz1.sum(axis=0)
return {"W1": dW1, "b1": db1, "W2": dW2, "b2": db2}
def grad_check_one_param(X, y, p, param_name="W1", idx=(0,0), eps=1e-5):
_, _, cache = forward_2layer_logits(X, p)
grads = backward_2layer_logits(y, cache, p)
g_analytic = grads[param_name][idx]
orig = p[param_name][idx]
p[param_name][idx] = orig + eps
L_pos = loss_2layer_bcewithlogits(X, y, p)
p[param_name][idx] = orig - eps
L_neg = loss_2layer_bcewithlogits(X, y, p)
p[param_name][idx] = orig
g_numeric = (L_pos - L_neg) / (2 * eps)
denom = max(1.0, abs(g_analytic), abs(g_numeric))
rel_err = abs(g_analytic - g_numeric) / denom
print("gradient check")
print("param:", param_name, "index:", idx)
print("analytic:", float(g_analytic))
print("numeric :", float(g_numeric))
print("rel_err :", float(rel_err))
grad_check_one_param(X_xor, y_xor, p, param_name="W1", idx=(0,0), eps=1e-5)実行結果
gradient check
param: W1 index: (0, 0)
analytic: 0.00011131067912407451
numeric : 0.00011131067549890321
rel_err : 3.6251713030109947e-12最適化アルゴリズム(分子と分母、1次と2次)
更新はだいたい次の形で整理できます。
$$
\theta \leftarrow \theta – \eta\cdot \frac{\text{方向(1次)}}{\text{歩幅調整(2次っぽい量)}}
$$
- 方向(1次):いまの勾配だけを見るか、過去も混ぜて平滑化するか
- 歩幅調整(2次っぽい量):座標ごとのスケール差を、勾配二乗で割って均すか
ここでいう「2次」は、ヘッセ行列そのものではなく、勾配二乗やその移動平均でスケールを推定するという意味です。
最適化アルゴリズムの関係性
SGDを基準形として、何を足したかで位置づけると把握しやすいです。
- SGD:勾配に学習率を掛けて引くだけ
- モーメンタム:方向に平滑化(慣性)を入れて安定化
- AdaGrad:座標ごとのスケール差を意識(累積勾配二乗で割る)
- RMSProp:AdaGradを平滑化して“忘れる”ように拡張
- AdaDelta:RMSProp系の発展(更新量のスケールも調整して単位感をそろえる)
- Adam:モーメンタム(1次の平滑化)+RMSProp(2次の平滑化)+バイアス補正
- AdamW:Adamのweight decayを勾配から分離(decoupled weight decay)
見取り図(関係性の一枚まとめ)
SGD
├─ 方向(1次)を平滑化 → Momentum
└─ 歩幅(2次っぽい)を座標ごとに調整
└─ 累積二乗 → AdaGrad
└─ 平滑化して“忘れる” → RMSProp
└─ 更新量のスケールも調整 → AdaDelta
Momentum(1次の平滑化) + RMSProp(2次の平滑化) + バイアス補正 → Adam
Adam + decoupled weight decay → AdamW最適化アルゴリズムの更新式
SGD
$$
\theta_{t+1}=\theta_t-\eta g_t
$$
モーメンタム
$$
m_t=\beta m_{t-1}+(1-\beta)g_t
$$
$$
\theta_{t+1}=\theta_t-\eta m_t
$$
AdaGrad
$$
r_t=r_{t-1}+g_t^2
$$
$$
\theta_{t+1}=\theta_t-\eta\cdot \displaystyle \frac{g_t}{\sqrt{r_t}+\epsilon}
$$
RMSProp
$$
v_t=\rho v_{t-1}+(1-\rho)g_t^2
$$
$$
\theta_{t+1}=\theta_t-\eta\cdot \displaystyle \frac{g_t}{\sqrt{v_t}+\epsilon}
$$
AdaDelta
$$
E[g^2]_t=\rho E[g^2]_{t-1}+(1-\rho)g_t^2
$$
$$
E[\Delta\theta^2]_t=\rho E[\Delta\theta^2]_{t-1}+(1-\rho)(\Delta\theta_t)^2
$$
$$
RMS[g]_t=\sqrt{E[g^2]_t+\epsilon},
\quad
RMS[\Delta\theta]_t=\sqrt{E[\Delta\theta^2]_t+\epsilon}
$$
$$
\Delta\theta_t=- \displaystyle \frac{RMS[\Delta\theta]_{t-1}}{RMS[g]_t}\cdot g_t
$$
$$
\theta_{t+1}=\theta_t+\Delta\theta_t
$$
Adam
$$
m_t=\beta_1 m_{t-1}+(1-\beta_1)g_t
$$
$$
v_t=\beta_2 v_{t-1}+(1-\beta_2)g_t^2
$$
$$
\hat{m}_t=\displaystyle \frac{m_t}{1-\beta_1^t},
\quad
\hat{v}_t=\displaystyle \frac{v_t}{1-\beta_2^t}
$$
$$
\theta_{t+1}=\theta_t-\eta\cdot \displaystyle \frac{\hat{m}_t}{\sqrt{\hat{v}_t}+\epsilon}
$$
AdamWとL2正則化の違い
AdamWはweight decayを「勾配に混ぜる」のではなく、「更新として分離」して適用します。実装に落とすとき迷いが減るように、一行の表記に統一します。
$$
\theta_{t+1}
=\theta_t-\eta\left(\displaystyle \frac{\hat{m}_t}{\sqrt{\hat{v}_t}+\epsilon}+\lambda\theta_t\right)
$$
注意点として、損失にL2正則化項 $\lambda|\theta|^2$ を足したときの「勾配としてのL2」と、AdamWの「更新としてのweight decay」は、Adam系の適応的スケーリングが入ると一致しない場面があります。そこでdecoupled weight decayとして分離する設計が使われます。
https://arxiv.org/abs/1711.05101
実務メモ
- weight decayは通常、重み(weight)にだけ適用し、バイアス(bias)や正規化のパラメータ(BatchNorm/LayerNormのscale/shiftなど)には適用しない運用が多いです。
- 実装では「decayグループ」と「no_decayグループ」に分けるのが定番です。
等高線で見る最適化
このデモは直感を作る用途で、深層学習の現実(ミニバッチ由来の勾配ノイズ、非凸な損失地形)は表現しません。ここでは「方向の平滑化」「歩幅のスケール調整」が歩き方にどう効くかだけを見ます。
a_coef, b_coef = 1.0, 23.0
def grad(theta):
x, y = theta
return np.array([a_coef*x, b_coef*y], dtype=np.float64)
def run_sgd(lr=0.08, steps=80, theta0=np.array([2.0, 2.0])):
th = theta0.astype(np.float64).copy()
path = [th.copy()]
for _ in range(steps):
g = grad(th)
th -= lr * g
path.append(th.copy())
return np.array(path)
def run_momentum(lr=0.08, beta=0.9, steps=80, theta0=np.array([2.0, 2.0])):
th = theta0.astype(np.float64).copy()
m = np.zeros_like(th)
path = [th.copy()]
for _ in range(steps):
g = grad(th)
m = beta*m + (1-beta)*g
th -= lr * m
path.append(th.copy())
return np.array(path)
def run_adam(lr=0.2, beta1=0.9, beta2=0.999, eps=1e-8, steps=80, theta0=np.array([2.0, 2.0])):
th = theta0.astype(np.float64).copy()
m = np.zeros_like(th)
v = np.zeros_like(th)
path = [th.copy()]
for t in range(1, steps+1):
g = grad(th)
m = beta1*m + (1-beta1)*g
v = beta2*v + (1-beta2)*(g*g)
mhat = m / (1 - beta1**t)
vhat = v / (1 - beta2**t)
th -= lr * mhat / (np.sqrt(vhat) + eps)
path.append(th.copy())
return np.array(path)
xs = np.linspace(-2.2, 2.2, 400)
ys = np.linspace(-2.2, 2.2, 400)
xx, yy = np.meshgrid(xs, ys)
zz = 0.5*(a_coef*xx*xx + b_coef*yy*yy)
path_sgd = run_sgd()
path_mom = run_momentum()
path_adam = run_adam()
plt.figure(figsize=(6, 5))
plt.contour(xx, yy, zz, levels=30, alpha=0.6)
plt.plot(path_sgd[:, 0], path_sgd[:, 1], marker="o", markersize=2, label="SGD")
plt.plot(path_mom[:, 0], path_mom[:, 1], marker="o", markersize=2, label="Momentum")
plt.plot(path_adam[:, 0], path_adam[:, 1], marker="o", markersize=2, label="Adam")
plt.title("Optimizer trajectories on contours")
plt.xlim(xs.min(), xs.max())
plt.ylim(ys.min(), ys.max())
plt.gca().set_aspect("equal", adjustable="box")
plt.legend()
plt.tight_layout()
plt.show()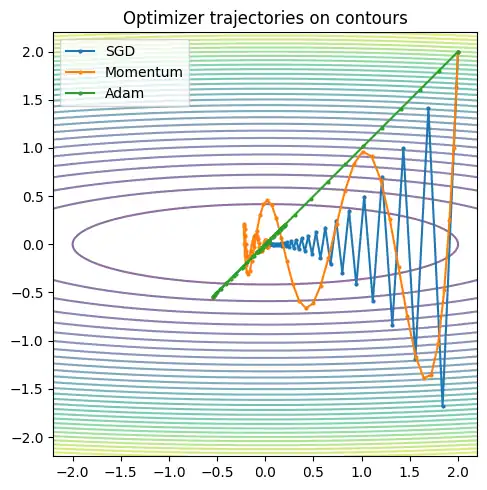
どれをいつ使うか(失敗パターン別)
発散(lossが増える、NaN、激しい振動)
- 学習率を下げます
- 入力の標準化、バッチサイズ、学習率スケジュールを確認します
停滞(lossが下がらない)
- 学習率の見直し(上げる、ウォームアップ)とスケジュール導入を検討します
- 隠れ層の活性化関数をReLU系へ移行し、必要なら正規化も入れます
過学習(学習は進むが検証が悪化)
- weight decay、データ拡張、早期終了を入れます
- モデル容量、分割やラベル品質を確認します
学習は進むが精度が伸びない(lossは下がるが指標が改善しない)
- 評価設計(閾値、不均衡、リーク)を確認します
- データ分布のズレ、ラベルノイズ、目的関数(重み付けなど)を見直します
実務版への最短ブリッジ(NumPyの式→PyTorch API)
実務移行では「モデルはlogitsを出す」「損失はlogitsを直接食べる」を固定すると迷いが減ります。
対応の最小表
- NumPyのシグモイド:
sigmoid(z)
PyTorch:torch.sigmoid(logits) - 確率BCE(入力が確率):
-(y*log(a)+(1-y)*log(1-a))
PyTorch:torch.nn.functional.binary_cross_entropy(prob, target) - logits BCE(BCEWithLogitsLoss相当):
np.logaddexp(0,z) - y*z
PyTorch:torch.nn.functional.binary_cross_entropy_with_logits(logits, target)またはtorch.nn.BCEWithLogitsLoss()
PyTorch公式ドキュメント(BCEWithLogitsLoss)
https://docs.pytorch.org/docs/stable/generated/torch.nn.BCEWithLogitsLoss.html
FAQ
logaddexpとは
$\operatorname{logaddexp}(a,b)=\log(\exp(a)+\exp(b))$ を数値安定に計算するための関数です。$\max(a,b)$でくくるlog-sum-exp系の変形により、指数が暴走しにくくなります。
BCEWithLogitsとは
確率$a$を作ってからBCEを計算する代わりに、logits $z$から直接損失を計算する定石です。$L(z,y)=\operatorname{logaddexp}(0,z)-y\cdot z$ に整理できます。
BCEWithLogitsLossとSigmoid+BCELossの違い
確率を経由すると$\sigma(z)$の飽和で$\log$が不安定になりやすい一方、logitsからsoftplus(log-sum-exp系)で直接計算できるため安定します。
https://docs.pytorch.org/docs/stable/generated/torch.nn.BCEWithLogitsLoss.html
pos_weightとは
クラス不均衡で正例を拾う学習信号を強めるための重みです。BCEWithLogitsLossのpos_weightとして使えます。
https://docs.pytorch.org/docs/stable/generated/torch.nn.BCEWithLogitsLoss.html
AdamWとL2正則化の違い
AdamWはweight decayを勾配から分離して更新として適用します。Adam系の適応的スケーリングがあると、損失にL2項を足した場合と一致しない場面があり、分離する設計が使われます。
https://arxiv.org/abs/1711.05101
勾配チェックとは
数値微分(有限差分)で計算した勾配と、逆伝播で計算した勾配が一致するかを確認する方法です。NumPy実装の検証として有効です。
まとめ
ニューラルネットは「線形変換+活性化関数」を重ねた合成関数として整理でき、決定境界の可視化から直感を作れます。交差エントロピーのlogは自信満々の誤りを強く罰し、修正信号を強くします。実務へ移るときは、確率BCEではなくlogitsからBCEWithLogitsLoss(logaddexp)で安定に計算し、クラス不均衡ならpos_weight、最適化はAdamWと学習率スケジュールを軸にするとつながりが良いです。
まとめのまとめ
- logits→BCEWithLogitsLoss(logaddexp)は数値安定と実務APIに直結します。
- クラス不均衡はpos_weightで正例の学習信号を強める設計がよく使われます。
- シグモイド統一は入門用で、隠れ層はReLU系へ置き換えるのが普通です。
その他のエッセイはこちら
本記事のG検定向けエッセンシャル版
本記事は以下のシリーズ記事の統合再編版です。
ゆるーい雰囲気でゆっくり読みたい人は以下のシリーズ記事の方がおすすめです。
上記シリーズ記事の統合版シリーズが含まれています。
上記がゆるすぎる場合は、以下シリーズの方が読み易いかもしれません。
(このシリーズ記事から読む方がおすすめです。)
シリーズ記事側はPythonだけでなく、MATLAB,Scilab,Juliaも使用。
参考文献
- Rosenblatt, F. (1958). The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain. Psychological Review.
https://psycnet.apa.org/record/1959-09865-001 - Rumelhart, D. E., Hinton, G. E., Williams, R. J. (1986). Learning representations by back-propagating errors. Nature.
https://www.nature.com/articles/323533a0 - Duchi, J., Hazan, E., Singer, Y. (2011). Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. JMLR.
https://jmlr.org/papers/v12/duchi11a.html - Zeiler, M. D. (2012). ADADELTA: An Adaptive Learning Rate Method. arXiv.
https://arxiv.org/abs/1212.5701 - Kingma, D. P., Ba, J. (2014). Adam: A Method for Stochastic Optimization. arXiv.
https://arxiv.org/abs/1412.6980 - Loshchilov, I., Hutter, F. (2019). Decoupled Weight Decay Regularization. arXiv.
https://arxiv.org/abs/1711.05101 - PyTorch Documentation: BCEWithLogitsLoss
https://docs.pytorch.org/docs/stable/generated/torch.nn.BCEWithLogitsLoss.html - Stanford CS231n: Convolutional Neural Networks for Visual Recognition
https://cs231n.github.io/
NumPyで“手で作って腹落ち”する(逆伝播・最適化まで)
ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装(斎藤 康毅)

外部ライブラリに頼らずに実装しながら、パーセプトロン~誤差逆伝播~学習の要点までを一気につなげられます。今回の記事の「NumPyでやり切る」方針と最も相性がいいです。
ゼロから作るDeep Learning ③ ―フレームワーク編(斎藤 康毅)

自動微分・計算グラフ(連鎖律の見方)が「自作フレームワーク」で腑に落ちます。記事内で“逆伝播が合ってる”の信頼を上げたい(勾配チェックも入れる)流れとも噛み合います。
(発展として)ゼロから作るDeep Learning ②(NLP/時系列) / ④(強化学習)

単層=ロジスティック回帰、BCE、logの意味を“理屈で締める”
パターン認識と機械学習(Bishop)

ロジスティック回帰、識別、確率、情報理論まわりが体系的です。「単層シグモイド+BCE=ロジスティック回帰」と位置づける章に厚みが出ます。
情報理論―基礎と広がり(Cover & Thomas、邦訳)

交差エントロピーや対数尤度の見方を、情報理論の言葉できれいに整理できます。「logは外したときに強く罰する」直観を、数式の背景まで含めて納得させたいときに強いです。
“2026年の実務デフォルト”へ最短で視野を広げる(ReLU系・正則化・最適化)
深層学習(Goodfellow / Bengio / Courville、邦訳)

記事がシグモイド統一で進むぶん、実務で頻出の論点(ReLU系、正則化、最適化、勾配問題など)を「次に何を学ぶべきか」まで含めて補完できます。ロードマップ枠の根拠付けにも使いやすいです。
統計的学習の基礎(Hastie / Tibshirani / Friedman、全訳)

ロジスティック回帰・正則化・汎化など、「NNだけを学ぶと抜けがちな地盤」を固める用途に向きます。記事の“誤用防止”にも効きます。
最適化を「1次/2次」「分子/分母」「なまし(平滑化)」で整理したい
最適化アルゴリズム(Kochenderfer / Wheeler、邦訳)

勾配・数値微分(勾配チェックの文脈に直結)から始まり、1次法(Momentum / AdaGrad / RMSProp / AdaDelta / Adam)と2次法までまとまっています。今回の記事の「歴史的・機能的因果関係」を、書籍側で裏取りしやすい構成です。
スタンフォード ベクトル・行列からはじめる最適化数学(Boyd / Vandenberghe、翻訳)

ベクトル・行列、最小二乗、スケーリング感、近似(テイラー)など、最適化の直観を育てるのに強いです。「勾配に学習率を掛けるだけのSGD」から一段上の理解(なぜスケールが効くか)に繋げやすいです。
実務ブリッジ(PyTorch、BCEWithLogits、AdamW、pos_weight への移行)
PyTorch実践入門 ディープラーニングの基礎から実装へ(Stevens / Antiga / Viehmann、邦訳)

NumPyで理解した学習ループを、PyTorchのテンソル・自動微分・実プロジェクトへ自然に移せます。記事内の「NumPyのこの式がPyTorchのこのAPIに一致する」ブリッジ枠を置く流れとも相性がいいです。
迷ったときの読み順(記事の流れに合わせる)
- ゼロから作るDeep Learning(まず記事の設計と同型で走る)
- パターン認識と機械学習(単層=ロジスティック回帰/BCEの理屈を締める)
- 最適化アルゴリズム(最適化の“関係性”を数式で整理する)
- 深層学習(実務デフォルト側の論点を一気に俯瞰する)
- PyTorch実践入門(実装を現場側へ寄せる)
コメント