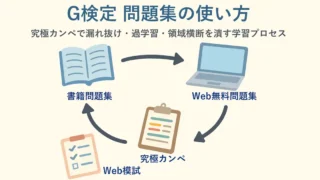
G検定 G検定 勉強方法、問題集の使い方|究極カンペで漏れ抜け・過学習・領域横断を潰す学習プロセス G検定の問題集は暗記用ではなく「漏れ検出器」として使うと強いです。書籍問題集/Web無料問題集/Web模試のクセを分け、究極カンペ(脳内の知識マップ)へ差分統合して、漏れ抜け・過学習・領域横断の弱点を潰す学習プロセスを解説します。 2026.02.17 G検定
生成AI ChatGPTとGeminiの違いは「性能差」より“検索・根拠・提案”の初期設定:体感 → 仮説 → パラメータ分解 → おもちゃモデル ChatGPTとGeminiの体感差(個人の推測)を先に具体化し、その体感を「根拠・概略・提案・リスク」に分解。期待値の式で整理したうえで、Pythonのおもちゃモデルで用途により優位が逆転する構造を可視化します。 2026.02.08 生成AI
G検定 G検定のカンペは禁止?「G検定 カンペ禁止」で検索する人向けに、受験規約・利用規約から読み解くNG行為(Google検索・ChatGPTは?) 「G検定 カンペ禁止」で不安な人向け。受験規約(同意画面)のカンニングNG、利用規約の漏えい禁止から安全な対応を整理。Google検索・ChatGPTの注意点も。 2026.01.22 G検定
生成AI 生成AIパスポートの禁止事項は「性格の問題」じゃない|“カンニング不安”を設計で消す方法 生成AIパスポートの禁止事項・失格条件を「いつもの癖(習慣)」として再設計。デュアル環境や“即ChatGPT”、終了ボタンの事故を、学習段階から潰す具体策を解説。 2026.01.16 生成AI
G検定 G検定が毎回「難化した!」と言われる理由:作問スタイルのズレを5軸で分解し、コサイン類似度のおもちゃモデルで理解する G検定で毎回「難化した!」と言われる理由を、作問スタイルのズレとして5軸で分解。シラバス→公式例題→ズレ耐性の最短対策も解説。 2026.01.16 G検定
G検定 G検定対策 究極カンペをつくろう#13|AIプロジェクトの進め方(CRISP-DM / CRISP-ML / PoC / BPR / MLOps ほか) G検定「AIの社会実装に向けて」対策。CRISP-DM/CRISP-ML、アジャイルとウォーターフォール、BPR・PoC・MLOpsまで、AIプロジェクトの進め方を因果関係図で整理し、PoC止まりを防いで価値創出につなげるポイントを解説します。 2026.01.10 G検定
G検定 G検定対策 究極カンペをつくろう#12|モデルの軽量化(エッジAI・蒸留・宝くじ仮説・プルーニング・量子化) DLモデルの巨大化が招く現実制約(計算資源・遅延・電力・通信・プライバシ)から、モデル圧縮(プルーニング/量子化/蒸留/宝くじ仮説)と効果・注意点、そしてエッジAIのユースケースまでを因果で一本化して整理する。 2026.01.07 G検定
G検定 【2026年版】生成AI時代のG検定勉強法・2024シラバス攻略── 時間軸と自分事軸、それから小さな「崖」の話 ChatGPTは触っているけれどG検定テキスト第1章で挫折した人へ。G検定 シラバス 改訂 2024 に対応した2025年、2026年向けのG検定 勉強法として、「G検定 どこから 勉強するか?」に答えるシラバス攻略エッセイです。生成AI時代のG検定勉強法のコツと、おすすめの読み順サンプル・30日ミニプランを解説します。 2026.01.02 G検定
G検定 【2026年度最新】G検定最新2024シラバス対応:究極カンペ×用語集カンペで合格力を高める学習法 G検定最新シラバス対応の勉強法として、「究極カンペ」と用語集カンペExcelを組み合わせた学習プロセスを具体的に解説します。 2025.12.24 G検定
G検定 【2026年対応】G検定チートシート|用語集カンペExcel無料DL(究極カンペ×二刀流) JDLA G検定最新シラバス対応の用語集カンペExcelを無料公開します。公式シラバス準拠の補助資料として「究極カンペ理論」を支えるサブノート的カンペの位置づけを解説します。 2025.12.20 G検定
 G検定 G検定
G検定 G検定  生成AI
生成AI  G検定
G検定  生成AI
生成AI 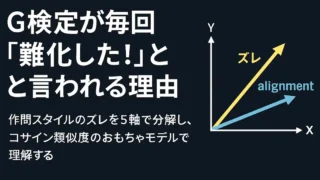 G検定
G検定 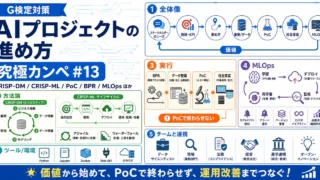 G検定
G検定 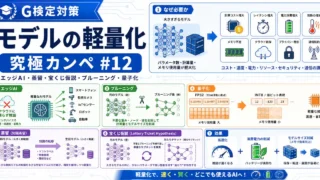 G検定
G検定  G検定
G検定  G検定
G検定  G検定
G検定