その他のエッセイはこちら


要約
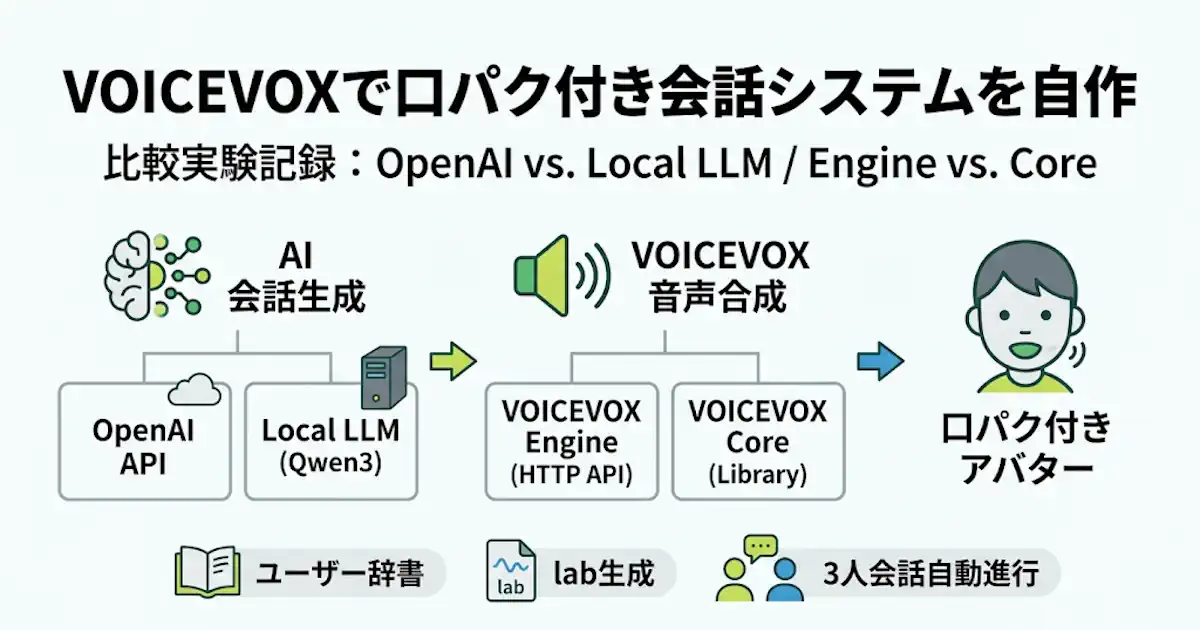
- 私が自作したこのシステムは、VOICEVOX の音声制御と口パク連携を中心に、OpenAI API と Local LLM の会話生成も比較できる実験環境です。
- 3人会話の自動進行機能では OpenAI API 側が優勢で、8B 級の Local LLM 側は反復と待ち時間の大きさが目立ちました。
- 実用面では、発話文中心の構成にユーザー辞書と lab 生成を組み合わせる方法が最も堅実でした。
デモ動画
※ 音声が出ますのでご注意ください
ソースコード
VOICEVOX口パク付き会話システムの概要
今回のシステムは、私が仕様から組み立てた Python / Streamlit ベースの比較実験アプリです。
OpenAI API と Local LLM、VOICEVOX Engine と VOICEVOX Core、発話制御レベル、単発応答 / 履歴あり会話 / 3人会話の自動進行機能を一つのアプリ内で比較できるようにしました。WAV、lab、viseme、metrics などの中間生成物も保存し、どこで差が出たのかを追いやすい構成にしています。
今回の主目的は、LLM の優劣を一言で決めることではありません。
VOICEVOX Engine と VOICEVOX Core の制御に慣れ、ユーザー辞書による読みとアクセント調整、lab ベースの口パク連携を実際に回せる状態へ持っていくことにありました。入力はテキスト方式を前提にし、音声合成、lab 生成、口パク、瞬き、会話ログ保存、比較実行を中心に構成しています。
この記事では独自用語を必要最小限にして、次の意味で使います。
- M1: 発話文のみを使うモード
- M2: 発話文に加えて、速度や抑揚などの話し方パラメータも使うモード
- M3: M2 に加えて、読み補正と強調指定も使うモード
- 3人会話の自動進行機能: 複数キャラクターがテーマに沿って会話を続ける機能
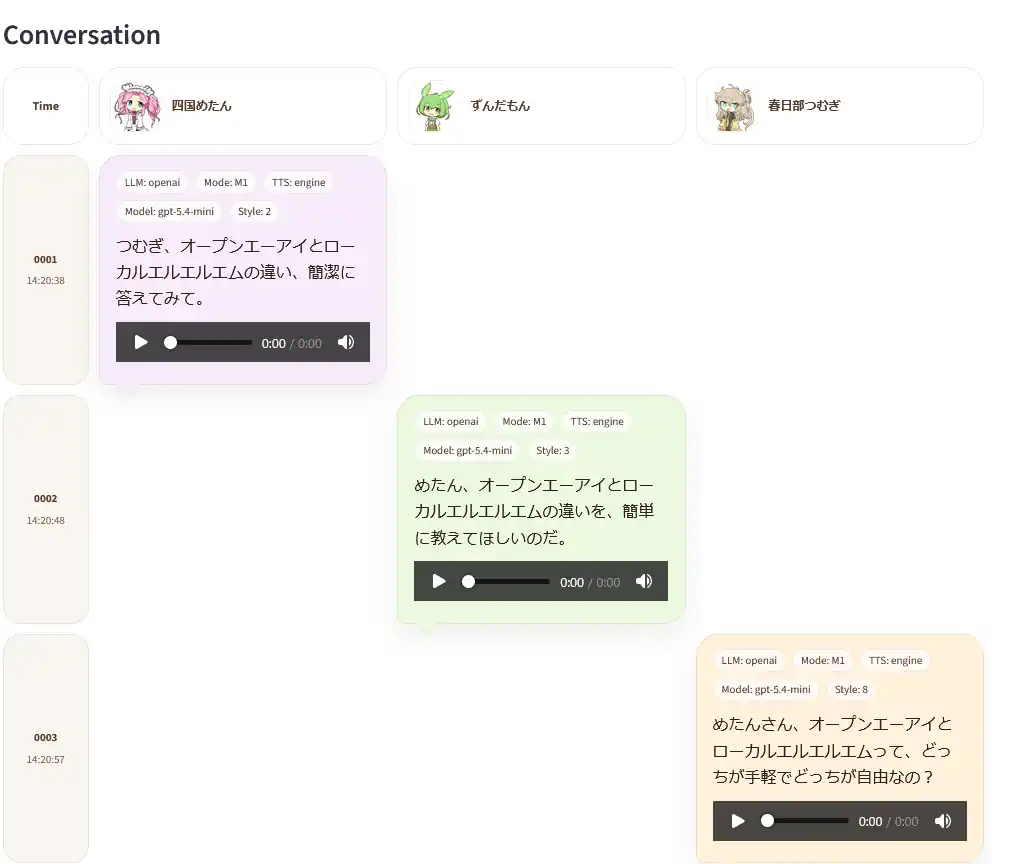
実際の会話画面は次のようになっています。話者ごとの発話内容だけでなく、使用モデルや制御モード、音声再生UIも同時に確認できます。
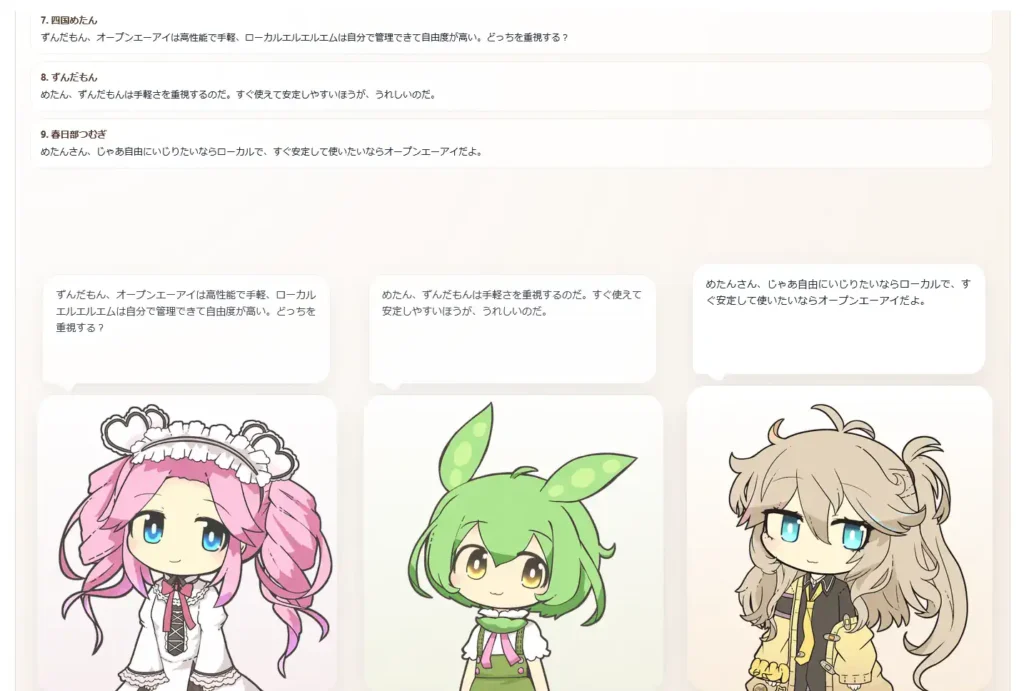
3人会話の自動進行機能では、会話ログだけでなく、立ち絵と吹き出しを並べたステージ表示でも進行を確認できます。
使用したLLMと実験環境
今回のシステムは Windows 11 x64、Python 3.12 系、Python / Streamlit ベースで動かしています。
OpenAI API 側と Local LLM 側の両方を扱え、VOICEVOX Engine / Core の双方で WAV / lab / viseme を保存できる構成です。
実験環境一覧
| 項目 | 内容 |
|---|---|
| アプリ実装 | Python / Streamlit |
| OS | Windows 11 x64 |
| CPU | Intel Core Ultra 7 165U |
| RAM | 32GB |
| Python | 3.12 系 |
| OpenAI API 側モデル | gpt-5.4-mini |
| Local LLM | OpenVINO/Qwen3-8B-int4-ov |
| Local LLM 提供方法 | OVMS 経由の OpenAI 互換 API |
| Local LLM 接続先 | http://127.0.0.1:8010/v3 |
| VOICEVOX Engine 接続先 | http://127.0.0.1:50021 |
| 確認済み Engine 版 | 0.25.1 |
| 確認済み Core 版 | 0.16.4 |
このアプリでは、OpenAI API 側のモデルに gpt-5.4-mini、Local LLM 側に OpenVINO/Qwen3-8B-int4-ov を使います。Local LLM 側は OVMS で http://127.0.0.1:8010/v3 を待受にし、VOICEVOX Engine 側は http://127.0.0.1:50021 を使う構成です。実確認では、VOICEVOX Engine 0.25.1、VOICEVOX Core 0.16.4、OVMS + OpenVINO/Qwen3-8B-int4-ov、OpenAI API の動作を確認しています。
比較条件
| 比較軸 | 選択肢 |
|---|---|
| 会話生成 | OpenAI API / Local LLM |
| 音声合成 | VOICEVOX Engine / VOICEVOX Core |
| 発話制御 | M1 / M2 / M3 |
| 会話形式 | Stateless / Chat / 3人会話の自動進行機能 |
| 表示 | 音声のみ / 口パクあり / 口パク + 瞬きあり |
このシステムでは、OpenAI API × VOICEVOX Engine、OpenAI API × VOICEVOX Core、Local LLM × VOICEVOX Engine、Local LLM × VOICEVOX Core を比較できるようにしています。あわせて、M1 / M2 / M3、単発応答 / 履歴あり会話 / 3人会話の自動進行機能、口パク表示、瞬き表示、WAV / lab / viseme / metrics 保存までを対象にしています。
システム構成と口パク連携の流れ
このシステムは、入力テキストを受けて LLM が正規化済み JSON を返し、それを変換層が VOICEVOX Engine または VOICEVOX Core 用の AudioQuery 系データへ反映し、WAV を生成します。その後、同じ情報から lab と viseme タイムラインを生成し、アバター描画へつなげる構成です。3人会話の自動進行機能では、発話者管理、各話者用 LLM 呼び出し、音声生成、口パク / 瞬き表示、ターン保存、停止条件判定という流れで進みます。
アバターは Live2D ではなく、差分画像方式です。
体・髪・顔土台を含むベース画像に対して、目差分で瞬き、口差分で口パクを表現します。口パクは lab ベースで扱い、VOICEVOX Engine / Core から直接 lab を受け取る前提にはせず、AudioQuery 相当の情報からアプリ側で lab と viseme タイムラインを生成する設計です。
比較観点の整理
各結果を読む前に、比較観点を整理しておきます。
| 比較観点 | 見ているポイント |
|---|---|
| OpenAI API と Local LLM | キャラらしさ、会話の前進性、JSON の安定性、待ち時間 |
| Engine と Core | 導入しやすさ、組み込みやすさ、辞書適用、運用のしやすさ |
| M1 / M2 / M3 | 発話文だけで十分か、話し方パラメータや読み補正まで使う価値があるか |
| 口パク | 音声生成と連携した見せ方、lab / viseme の再利用性 |
| 展示会デモ適性 | 見せ方として成立するか、待ち時間や安定性に課題がないか |
具体的な会話例
会話例を見ると、OpenAI API と Local LLM の差がかなり分かりやすくなります。
今回は、3人会話の自動進行機能と単発応答の両方で比較しました。会話例そのものは今回の実験ログに基づくものです。
3人会話の自動進行機能の例
テーマは「OpenAI と Local LLM の違い」です。
ルールは「自分の後にしゃべる人を名指しして質問する。質問された側は質問に答えること」としました。
OpenAI API 側の例
| 話者 | 発話 |
|---|---|
| めたん | ずんだもん、オープンエーアイとローカルエルエルエムの違い、どう見る? |
| ずんだもん | めたん、オープンエーアイは高性能で手軽なのだ。ローカルエルエルエムは自分で動かせて安心感があるのだ。 |
| 春日部つむぎ | めたんさん、オープンエーアイとローカルエルエルエムって、使い勝手でどっちが強いと思う? |
| めたん | つむぎ、使い勝手ならオープンエーアイが強いわ。導入が軽くて、すぐ安定して使えるからね。 |
| ずんだもん | つむぎ、ローカルエルエルエムの強みは何だと思うのだ? |
| 春日部つむぎ | ずんだもん先輩、あーしはローカルエルエルエムの強みは自由度の高さだと思うよ。手元で回せるのも安心だしね。 |
この例では、話者の受け渡し、質問と応答の対応、キャラクターらしい言い回し、新しい視点の追加が一応成立しています。
3人会話の自動進行機能では、直前発話の単なる言い換えを避けること、新しい視点・補足・質問・まとめのいずれかを含めること、テーマから大きく外れないことを狙っています。OpenAI API 側は、この条件に比較的沿いやすい挙動でした。
Local LLM 側の例
| 話者 | 発話 |
|---|---|
| めたん | OpenAI と Local LLM の違いについて、質問された人はそれに答える。 |
| ずんだもん | OpenAI と Local LLM の違いについて、質問された人はそれに答える。 |
| 春日部つむぎ | OpenAI と Local LLM の違いについて、質問された人はそれに答える。 |
Local LLM 側では、3人の役割認識が崩れやすく、会話の前進性も弱くなりました。
結果として、ルール文の反復に近い形になり、複数人会話としての自然さはかなり限定的でした。Local LLM 側は OpenAI 互換 endpoint を第一候補にしつつ、JSON 破綻を見込んで再検証する前提で実装しています。今回の体感差は、その設計上の前提とも大きく矛盾しません。
単発応答の例
同じテーマで、単発応答も比べました。
質問は「OpenAI と Local LLM の違いについて可能な限り詳細に教えて」です。
OpenAI API 側の例
| キャラクター | 発話 |
|---|---|
| めたん | 違いは大きく三つ。性能の安定性、運用の手軽さ、そして自由度だよ。OpenAI は高性能で扱いやすい一方、Local LLM は自前で細かく触れるのが強み。 |
| ずんだもん | オープンエーアイとローカルエルエルエムの違いなら、ずんだもんがざっくり言うと、前者は高性能で使いやすい代わりに外部サービスなのだ。後者は自分の手元で動かせて自由度が高いけど、性能や管理は工夫がいるのだ。 |
| 春日部つむぎ | あーし的には、オープンエーアイは高性能で手軽、ローカル LLM は自分の環境で動かせて自由度高めって感じだよ。用途次第で、精度重視なら前者、秘密保持やカスタム重視なら後者が強いかも。 |
Local LLM 側の例
| キャラクター | 発話 |
|---|---|
| めたん | OpenAI と Local LLM の主な違いは、OpenAI は外部サービスとして利用し、Local LLM はローカル環境で実行できる点です。 |
| ずんだもん | OpenAI と Local LLM の主な違いは、OpenAI は外部サービスとして利用し、Local LLM はローカル環境で実行できる点なのだ。 |
| 春日部つむぎ | OpenAI と Local LLM の主な違いは、OpenAI は使いやすさが強みで、Local LLM は手元で動かせる自由度が強みという点だよ。 |
この比較では、OpenAI API 側はキャラクターごとの言い回しや視点の違いが出ています。
一方、Local LLM 側は意味は成立するものの、3キャラクターの返答がかなり似通いやすく、ロールプレイ差は薄くなりました。
このアプリでは、返答を 1〜2 文程度に収めつつ、四国めたん・ずんだもん・春日部つむぎそれぞれに口調制約を与える設計です。OpenAI API 側はこの制約に比較的沿いやすく、Local LLM 側は簡潔な説明寄りになりやすいという差が出ました。
OpenAI APIとLocal LLMの比較結果
会話例と実験結果をまとめると、OpenAI API と Local LLM の差は次のように整理できます。
会話生成の比較
| 観点 | OpenAI API | Local LLM |
|---|---|---|
| 単発応答 | 安定しやすい | 成立はするが、説明寄りになりやすい |
| キャラ差 | 出やすい | 出にくい |
| 履歴あり会話 | 文脈を保ちやすい | 会話が長くなると崩れやすい |
| 3人会話の自動進行機能 | 話者受け渡しや役割維持が比較的自然 | 反復しやすく、役割維持が難しい |
| JSON の安定性 | 比較的高い | 再検証や再試行が前提 |
| 待ち時間 | 実用寄り | 条件次第でかなり大きい |
このシステムでは、OpenAI API 側は構造化出力を優先し、Local LLM 側は OpenAI 互換 endpoint を前提にしつつ、JSON 破綻を見込んで補正や再試行を行う構成です。品質目安としても、OpenAI API 側の方を高めに見込み、Local LLM 側はより低い水準を前提にしています。
3人会話の自動進行機能に限った比較
| 観点 | OpenAI API | Local LLM |
|---|---|---|
| 話者の受け渡し | 比較的自然 | 乱れやすい |
| 直前発話の言い換え回避 | 比較的できる | 反復が目立ちやすい |
| 新しい視点の追加 | 出しやすい | 同意や言い換えに寄りやすい |
| 役割表現 | 維持しやすい | 3人分を保つのが難しい |
| 展示向け構成との相性 | 良い | 慎重な設計が必要 |
M1・M2・M3の比較結果
制御レベルの比較
| モード | 内容 | 長所 | 課題 | 現時点の評価 |
|---|---|---|---|---|
| M1 | 発話文のみ | 最も安定しやすい | 細かな話し方調整は限定的 | 実用本命 |
| M2 | 発話文 + 話し方パラメータ | 速度や抑揚の傾向を付けやすい | LLM 任せだと再現性に課題 | 実験向け |
| M3 | M2 + 読み補正 + 強調 | 表現力が最も高い | 発音やイントネーションの再現性が安定しにくい | 研究向け |
このシステムでは、M1 は spoken_text のみ、M2 は spoken_text + global prosody、M3 はさらに reading_overrides + emphasis まで扱います。加えて、M2 / M3 の prosody はそのまま使わず、キャラクター既定値寄りに寄せて安全域へ収める方針にしています。
実運用の観点から見た比較
| 観点 | M1 | M2 | M3 |
|---|---|---|---|
| 実装の分かりやすさ | 高い | 中 | 低い |
| 再現性 | 高い | 中 | 低め |
| 発話の自然さ | 十分 | 条件次第 | 条件次第 |
| 読み補正 | 辞書中心 | 一部可 | 可能 |
| 強調表現 | なし | なし | あり |
| 実用適性 | 高い | 中 | 低め |
M3 では速度、音高、抑揚、音量、前後無音長の安定化は行いますが、アクセント核やアクセント句分割の直接補正までは扱っていません。そのため、固有名詞のイントネーションを安定して扱うには、ユーザー辞書の併用が有効です。
ユーザー辞書と読み補正の比較結果
今回の実験で最も手応えがあったのは、ユーザー辞書と lab 生成です。
LLM に毎回読みを期待するよりも、辞書で読みとアクセントを整える方が再現性はかなり高いと感じました。
読み補正手段の比較
| 手段 | 特徴 | 強み | 弱み | 向いている用途 |
|---|---|---|---|---|
| ユーザー辞書 | アプリ側で読みとアクセントを管理 | 再現性が高い | 事前登録が必要 | 実運用、本番寄り |
| M3 の読み補正 | LLM 出力で都度補う | 柔軟 | ばらつきが出やすい | 比較実験 |
| 発話文をカタカナ寄りにする | 最も簡単 | 手軽 | 文として不自然になりやすい | 応急対応 |
英字語や固有名詞の読みが期待と異なる場合、このアプリではユーザー辞書登録を最も確実な方法として扱っています。local のような語も、確実に「ローカル」と読ませたい場合は辞書登録が有効です。
Engine / Core でのユーザー辞書適用の違い
| 観点 | VOICEVOX Engine | VOICEVOX Core |
|---|---|---|
| 適用方法 | /user_dict_word API 経由 | voicevox_core.UserDict を合成時ロード |
| 反映タイミング | 辞書更新後の初回合成時に同期 | 合成ごとに反映 |
| 実装上の印象 | 外部 API 連携として明快 | アプリ内完結で扱いやすい |
アプリ内では、ユーザー辞書データを config/user_dict.json に保存し、Engine 側では API 同期、Core 側では合成時ロードで適用します。単語追加、削除、CSV 入出力、Engine への反映、Core への自動適用まで UI から扱えます。
VOICEVOX EngineとCoreの違い
今回の検証範囲では、VOICEVOX Engine と VOICEVOX Core に目立った性能差があるというより、扱い方の差が前に出ました。
試作段階では Engine が触りやすく、組み込みや配布構成まで見据えるなら Core の理解が重要という整理です。
全体比較表
| 観点 | VOICEVOX Engine | VOICEVOX Core |
|---|---|---|
| 呼び出し方式 | HTTP API | Python ライブラリ |
| 起動形態 | 別プロセス起動が必要 | アプリ内で初期化 |
| 初期導入 | 分かりやすい | 依存準備がやや多い |
| 主な準備 | Engine 本体起動、URL 設定 | wheel、ONNX Runtime、辞書、VVM |
| 音声合成の流れ | audio_query → パラメータ反映 → synthesis | create_audio_query → パラメータ反映 → synthesis |
| 生成物 | WAV、engine_query.json、lab、viseme | WAV、core_query.json、lab、viseme |
| ユーザー辞書 | API 同期 | 合成時ロード |
| style_id 運用 | 設定ファイルから管理 | 設定ファイルから管理 |
| 試作時の扱いやすさ | 高い | 中 |
| アプリ組み込みやすさ | 中 | 高い |
導入と準備の違い
| 観点 | VOICEVOX Engine | VOICEVOX Core |
|---|---|---|
| 入手方法 | Engine release 一式 | downloader と Python wheel |
| 動作確認方法 | /version で確認しやすい | ライブラリ初期化と合成で確認 |
| 必要な設定 | VOICEVOX_ENGINE_URL | VOICEVOX_CORE_VVM_PATH、VOICEVOX_CORE_ONNXRUNTIME_DIR、VOICEVOX_OPENJTALK_DICT_DIR |
| 主な確認ポイント | Engine が起動しているか、URL が正しいか | wheel、辞書、ONNX Runtime、VVM がそろっているか |
音声合成処理の違い
| 観点 | VOICEVOX Engine | VOICEVOX Core |
|---|---|---|
| クエリ生成 | audio_query | create_audio_query(text, style_id) |
| パラメータ名 | speedScale など | speed_scale など |
| 強調反映先 | accent_phrases | accent_phrases[].moras[] |
| クエリ保存 | engine_query.json | core_query.json |
| lab / viseme | アプリ側で生成 | アプリ側で生成 |
このシステムでは、lab は Engine / Core から直接受け取る前提にはしていません。
どちらも AudioQuery 相当のモーラ情報からアプリ側で生成するため、口パクまわりの実装を Engine / Core で大きく分けずに扱いやすくしています。
Core 特有のポイント
| 項目 | 内容 |
|---|---|
| VVM の指定 | キャラクターごとに VVM パスを持てる |
| style_id に対応する VVM | 該当 style_id がない場合は別 VVM を選ぶ仕組みがある |
| 既定スタイル運用 | 話者ごとに既定 style を持てる |
| 商品化を見たときの印象 | ライブラリ方式のため構成整理を進めやすい |
このアプリでは、Core 側で指定した VVM に対象 style_id がない場合、同じ vvms/ 配下から一致する style_id を持つ別 VVM を選ぶ仕組みを入れています。実確認でも、style_id=22 での VVM 自動選択を確認しています。
口パク・瞬き・録画時の見え方
このシステムでは、口パクは lab ベースで扱い、口形は A / I / U / E / O / CLOSE の 6 種を使っています。
音素列から viseme タイムラインを生成し、それをアバター描画へ渡します。さらに、表示タイミングを微調整するための lip_sync_offset_ms も用意しています。アプリ上ではこの値を変更でき、調整後の viseme タイムラインも保存します。
リアルタイムで LLM に会話を作らせ、VOICEVOX で音声を生成し、音声再生と口パクを同時に行った画面を録画したところ、録画映像では同期差がやや大きく見える場面がありました。
ただし、実際の再生ではそこまで極端ではなく、録画時の負荷による見え方の影響が大きいと考えています。見え方の追い込みには lip_sync_offset_ms が有効でした。
立ち絵素材について
3人の立ち絵には、akihiyo さんの公開素材を使用しており、本システムにも同梱します。
クレジット表記は README に記載しています。利用時は、素材利用条件と各キャラクターの利用規約を確認してください。
このシステムで投げているプロンプトの考え方
このシステムでは、LLM に単なる返答文だけを求めるのではなく、spoken_text、prosody、reading_overrides、emphasis などを含む構造化データを返させる設計です。返答は原則 1〜2 文程度に収め、キャラクターらしさを出しつつ、内容崩壊するほどの誇張は避けるようにしています。英字語や略語は、原則として spoken_text 側でカタカナ寄りにし、必要なら読み補正情報を持たせる方針です。
単発応答の想定 system prompt 例
あなたはキャラクター音声応答システムの応答生成器です。
出力は JSON のみとします。
説明文、前置き、コードブロックは出力しません。
必須項目:
- spoken_text
- persona
- prosody
- delivery_notes
- reading_overrides
- emphasis
共通ルール:
- spoken_text は 1〜2 文
- 内容は簡潔
- 英単語や略語は、可能なら spoken_text をカタカナ寄りにする
- 英字表記を残す場合は reading_overrides に読みを入れる
キャラクター制約:
- 四国めたん: 少し知的で自然体
- ずんだもん: 一人称は「ずんだもん」、語尾は「なのだ」寄り
- 春日部つむぎ: 一人称は「あーし」、軽快でフランク3人会話の自動進行機能の想定 prompt 例
speaker: shikoku_metan
theme: OpenAI と Local LLM の違い
recent_history:
- zundamon: オープンエーアイは手軽なのだ
- kasukabe_tsumugi: ローカルは自由度が高いと思うよ
rules:
- 1〜2文
- 直前発話の単なる言い換え禁止
- 新しい補足、質問、まとめのいずれかを含める
- テーマから大きく離れない
- spoken_text はそのまま音声合成に使える自然な文にするLocal LLM 向けの短い prompt 例
Local LLM 側では、長い指示を重ねるより、短く要点を渡す方が安定しやすい場面があります。
そのため、単発応答では次のような短い形式も考えられます。
JSON only
character=zundamon
fields=spoken_text,spoken_kana
rules:
- 1〜2文
- 一人称は「ずんだもん」
- 語尾は「なのだ」寄り
- 自然な回答
question:
OpenAI と Local LLM の違い展示会デモへの応用可能性
今回の主目的は、VOICEVOX Engine と VOICEVOX Core の制御に慣れることでした。
ただし、構成としては展示会デモのような用途にも十分につながります。音声認識で得た質問文を LLM に渡し、その応答を VOICEVOX で音声化し、口パク付きで返す流れは自然に組めます。現時点では STT 自体は対象外ですが、下流の音声生成、lab 生成、口パク表示、保存の流れはすでに成立しています。
一方で、展示会向けとして完成度を左右するのは、単に音声が出るかどうかではありません。
重要なのは、会話制御の安定性、待ち時間、読み補正の再現性、録画や描画時の負荷です。
そのため、今の時点で現実的なのは、OpenAI API を使った単発応答または短い履歴あり会話に、VOICEVOX、ユーザー辞書、lab ベースの口パクを組み合わせる構成だと考えています。
FAQ
Q1. このシステムは何を目的に作ったのですか?
主目的は、VOICEVOX Engine と VOICEVOX Core の制御に慣れることです。特に、ユーザー辞書による読みとアクセントの調整、lab 生成による口パク連携の確認を重視しました。
Q2. OpenAI API と Local LLM の差はどこに出ましたか?
最も差が大きかったのは、3人会話の自動進行機能でのロールプレイ能力です。OpenAI API 側は会話の前進性と役割維持が比較的自然でしたが、8B 級の Local LLM 側は反復と待ち時間の大きさが目立ちました。会話例でもその差が見えやすかったです。
Q3. VOICEVOX Engine と Core に性能差はありますか?
今回の検証範囲では、性能差よりも扱い方の差が大きいという結論でした。Engine は HTTP API として扱いやすく、Core はライブラリとして組み込みやすい点が特徴です。
Q4. 実用面で有力だった構成は何ですか?
現時点では、発話文を中心に扱う M1 を使い、必要な読みとアクセントをユーザー辞書で整える構成が最も扱いやすいです。M2 と M3 は研究や比較用途としては面白い一方、毎回の再現性にはまだ課題があります。
Q5. 立ち絵素材は何を使っていますか?
3人の立ち絵には akihiyo さんの公開素材を使用しており、本システムにも同梱します。クレジット表記は README に記載しています。利用時は、素材利用条件と各キャラクターの利用規約を確認してください。
まとめ
今回の自作システムで確認できたのは、会話生成の巧拙と音声制御の巧拙は別の層にある、ということです。3人会話の自動進行機能では OpenAI API 側が明らかに有利でしたが、読みとアクセント、音声化、口パク連携の再現性は LLM の賢さだけでは決まりません。むしろ、ユーザー辞書、lab 生成、表示タイミング調整の方が、実装者としての手応えは大きい部分でした。
現時点で最も扱いやすい構成は、M1 を中心に、必要な読みだけをユーザー辞書で整え、VOICEVOX で安定して音声化する流れです。そのうえで、3人会話の自動進行機能や M2 / M3 のような高度な制御を研究対象として重ねていくのが、今の段階では最も筋の良い進め方だと考えています。
- OpenAI API 側は 3人会話の自動進行機能で優勢でした
- 実用面では M1 とユーザー辞書、lab 生成の組み合わせが有力でした
- Engine と Core は性能差より、導入と運用の違いが大きいと感じました
参考文献
- VOICEVOX Engine Releases
https://github.com/VOICEVOX/voicevox_engine/releases - VOICEVOX Engine Repository
https://github.com/VOICEVOX/voicevox_engine - VOICEVOX Core Releases
https://github.com/VOICEVOX/voicevox_core/releases - VOICEVOX 公式サイト
https://voicevox.hiroshiba.jp/ - OpenVINO Model Server bare metal deployment documentation(OpenVINO 2026 系ドキュメント)
https://docs.openvino.ai/2026/model-server/ovms_docs_deploying_server_baremetal.html - OpenVINO Model Server Releases
https://github.com/openvinotoolkit/model_server/releases - OpenVINO/Qwen3-8B-int4-ov model card
https://huggingface.co/OpenVINO/Qwen3-8B-int4-ov - Qwen/Qwen3-8B model card
https://huggingface.co/Qwen/Qwen3-8B - 四国めたん / ずんだもん 利用規約
https://zunko.jp/con_ongen_kiyaku.html - 春日部つむぎ 利用規約
https://tsukushinyoki10.wixsite.com/ktsumugiofficial/利用規約
書籍
LLMの全体像をつかむ本
『直感 LLM』

LLM を視覚的に理解しながら、Jupyter Notebook やクラウド上で実際に動かして学ぶ構成です。まず全体像をつかみたいときに合います。
『大規模言語モデル入門』

LLM の理論と実装の両方を扱う入門書です。文埋め込み、類似文検索、質問応答、OpenAI API を使った実装や評価にも触れているので、今回の記事にある「会話生成」「検索との組み合わせ」「実装寄りの比較」と相性がよいです。
LLMアプリ開発を進める本
『実践 LLMアプリケーション開発』

モデルの構造や限界、活用手法、応用パターンを体系的に紹介する本です。
単なる API 利用ではなく、LLM を使ったアプリ設計を一段深く考えたいときに向いています。
『生成AIアプリ開発大全』

Dify ベースの本ですが、「生成 AI をどうアプリとして組み立てるか」という観点で参考になります。
ノーコード寄りの構成を知りたいなら候補に入ります。
自然言語処理の基礎を固める本
『自然言語処理の教科書』

新しめの技術だけに寄らず、自然言語処理システム開発で必要な普遍的な知識を中心に扱う本です。
会話システムを「モデル比較」だけでなく「設計」「評価」「開発全体」で見たいときに相性がよいです。
『BERT実践入門 PyTorch + Google Colaboratoryで学ぶ自然言語処理』

Transformer を土台に、BERT の仕組みや実装を学ぶ本です。
LLM そのものではありませんが、埋め込みや Transformer 系モデルの理解を補強したいなら役立ちます。
音声処理・音声合成まわりを理解する本
『電子情報通信レクチャーシリーズ C-8 音声・言語処理』

音声合成、音声認識、音声生成、音声分析、自然言語処理の概略まで含めて、基盤技術を平易に学べる本です。
「音声生成」「口パク連携」「音声処理の前提知識」を押さえるのに向いています。
『音響テクノロジーシリーズ 22 音声分析合成』

音声をパラメータとして表現し、そこから音声波形を生成する音声分析合成の知識をまとめた本です。
VOICEVOX を直接解説する本ではありませんが、lab や韻律、合成処理の理解を一段深めたいならかなり相性がよいです。
PythonでUI化・デモ化する本
『作ってわかる[入門]Streamlit』

Streamlit を使って、テキスト分析、AI 連携チャットボット、画像処理、音声データからのテキスト起こし、可視化などを実装する本です。
今回の記事のような「比較実験アプリを形にする」流れにかなり近いです。
コメント