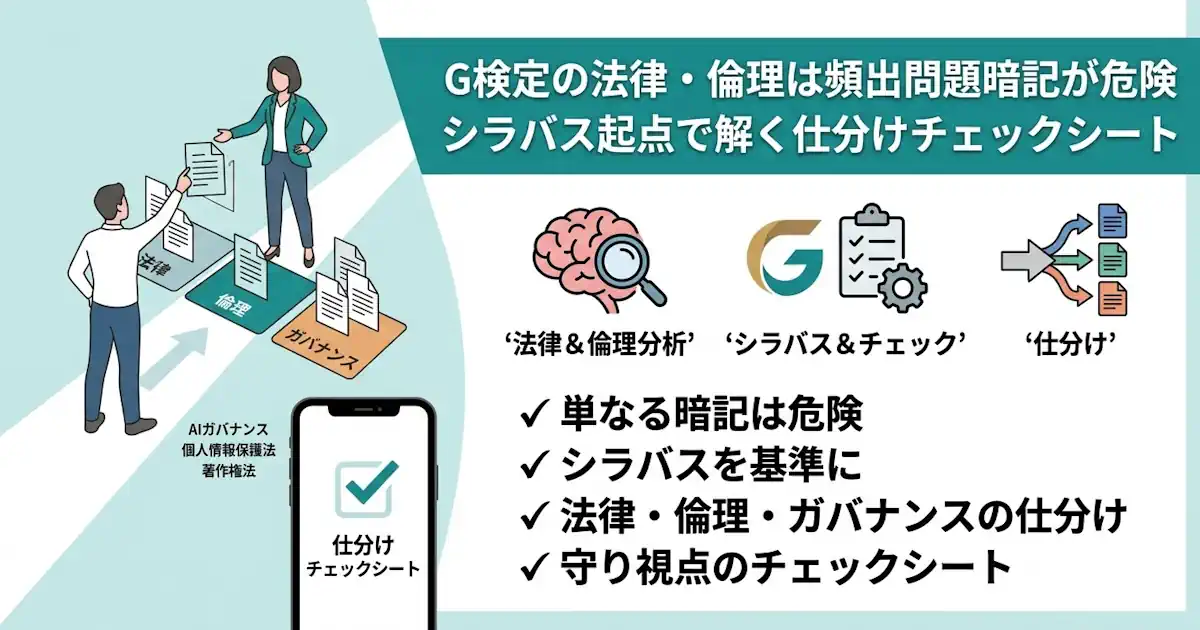
- 頻出問題は、頻出文章ではなく頻出論点として見る
- 法律・倫理・ガバナンスの棚分けが、得点の安定性を左右する
- 抵触回避だけでなく、守りの視点で整理すると初見問題に強くなる
G検定の法律・倫理は、頻出問題を覚えれば点が取れる分野だと思われがちです。ですが実際には、頻出なのは文章ではなく論点です。法律・倫理・ガバナンスが混ざった選択肢を仕分けられないまま、頻出問題の表面だけを追うと、本番で問い方を少し変えられただけで崩れます。この記事では、シラバスを基準に論点を整理し、初見問題にも対応しやすくなる仕分けの考え方とチェックシートをまとめます。
私自身、このテーマを考え始めたきっかけは、受験者の間で共有される「いわゆる頻出問題は、本番では意外とそのまま出ないらしい」という話でした。もちろん、これは公式情報ではありませんし、事実として確認できるものでもありません。ここでは事実認定としてではなく、一つの問題提起として受け止めています。
ただ、この仮説をいったん脇に置いても、学習方針として「頻出問題の表面を覚えるより、シラバスを基準に論点を整理する方が合理的」という結論は変わりません。JDLAはG検定をシラバス準拠で出題しており、公開例題でも「AIに関する法律と契約」と「AI倫理・AIガバナンス」は別カテゴリとして整理されています。つまり公開情報だけを見ても、必要なのは頻出文章の暗記ではなく、法律・倫理・ガバナンスの仕分けです。
合わせて読むことおすすめの記事


問題集をひたすら解きたい方はこちらへ

解説動画

頻出問題という現象
ネット上で「頻出問題」と呼ばれているものの多くは、厳密には次のどれかです。
- シラバス上の重要論点
- その論点を説明するための例題
- 独自に作られた演習問題
- 過去の問われ方の要約
ここで重要なのは、これらがすべて「標本」にすぎないことです。標本をそのまま暗記しても、母集団である出題範囲全体を理解したことにはなりません。
とくに法律・倫理の分野では、法、倫理、ガバナンス、契約、運用が混ざった選択肢が並びます。その結果、選択肢だけを見ると「どれも正しそう」に見えます。ここで反射的に答えると事故ります。しかも厄介なのは、誤答の多くが「完全に間違っている」わけではないことです。一般論としては正しいのに、その設問に対する正答ではない。それがこの分野の難しさです。
頻出問題暗記が危険な理由
頻出問題の丸暗記が危険なのは、主に次の3点です。
- 頻出なのは文章ではなく論点
- 問い方が変わるだけで正答が変わる
- 一見正しい選択肢が、設問には不正解になりうる
定番の言い回しが流通した時点で、同じ形を繰り返しても差はつきにくくなります。したがって、論点は維持したまま、問い方や切り口を変えるのは試験設計としてかなり自然です。そう考えると、「頻出の問われ方」に張る学習は、見た目ほど安定しません。
さらに重要なのは、たとえ「頻出問題が本番でそのまま出る」試験だったとしても、シラバス起点の整理の方が依然として合理的だという点です。なぜなら、G検定が測ろうとしているのは、文章の再生ではなく、シラバスにある論点の理解だからです。頻出問題の表面を覚えるより、論点の位置関係を理解した方が、出題形式が変わっても崩れにくくなります。
法律・倫理・ガバナンスの混在
法律・倫理で崩れる受験者の多くは、知識が足りないというより、棚が分かれていません。
同じ「正しそうな選択肢」でも、実際にはレイヤーが違います。
- 法律
権利義務、要件、禁止、適法・違法 - 倫理
法違反でなくても望ましいか、不公平でないか、説明できるか - ガバナンス
組織としてどう管理し、どう見直すか - 契約
当事者間で何をどこまで縛るか - 運用
監査、ログ、アクセス制御、持ち出し制限、再現性確保
ここを分けないまま選択肢を読むと、「正しそうだから選ぶ」という反応になりやすくなります。ですが試験で必要なのは、選択肢単体の立派さを評価することではありません。まず設問が何のレイヤーを聞いているのかを見極め、そのレイヤーに対応する選択肢を選ぶことです。
頻出文章ではなく頻出論点
この分野で本当に追うべきなのは、頻出文章ではなく頻出論点です。たとえば次のような論点は、シラバスと公的資料をつなぐと自然に浮かび上がります。
- 個人情報保護法
- 著作権法
- 特許法
- 不正競争防止法
- AI開発・利用契約
- プライバシー
- 公平性
- AI倫理
- AIガバナンス
さらに厄介なのは、法律の中でも仕分けが必要なことです。たとえば著作権法は表現を保護しますが、アイデアそのものは保護しません。一方、特許法は一定の要件を満たした技術的思想を保護対象にします。不正競争防止法は営業秘密や限定提供データの保護が中心です。つまり同じ「何かを守る話」でも、表現の保護なのか、発明の保護なのか、秘密管理や限定共有による保護なのかで制度が変わります。ここを曖昧にしたまま「保護される」「守れる」とだけ覚えると、著作権法と特許法、あるいは特許法と営業秘密の選択肢を取り違えやすくなります。
シラバスを母集団として見る
ここから先の学習方針はシンプルです。
まず、シラバスを母集団とみなします。
次に、ネット上の頻出問題や公開例題を標本とみなします。
そのうえで、標本から出題者が使う仕分け軸を抽出します。
この順番にすると、頻出問題の位置づけが変わります。
- 暗記対象としての頻出問題
- 母集団推定材料としての頻出問題
有効なのは後者です。
ただ、ここで大げさに構える必要はありません。最初からシラバス全体を完璧に整理しようとすると、かえって手が止まります。まずは「法律・倫理・ガバナンス・契約・運用という5つのレイヤーがある」とだけ意識して、例題や過去問風の問題を見てみるだけでも十分です。最初の一歩として大事なのは、全部を網羅することではなく、「この選択肢は何の話か」を意識することです。
抵触だけでなく守りの視点
法律・倫理を「違反しないための分野」とだけ見ると、整理しにくくなります。そこで効くのが、守りの視点です。
何かを守るとき、考える順番はおおむねこうです。
- 法で守る
個人情報保護法、著作権法、特許法 - 不正競争防止法で守る
営業秘密、限定提供データ - 契約で守る
利用範囲、再提供禁止、学習利用、成果物帰属、秘密保持 - 運用で支える
アクセス制御、ログ、監査、持ち出し制限
この整理があると、法律・倫理の各論点がバラバラな暗記項目ではなくなります。単に「何をしてはいけないか」を覚えるのではなく、「何をどう守るか」という設計の話として並び直せます。その結果、著作権法と営業秘密、個人情報保護法とプライバシー、法的義務とガバナンスの違いが見えやすくなります。
守り視点のチェックシート
設問や選択肢を見たら、次の順で確認します。
- 何のレイヤーの話か
法律 / 倫理 / ガバナンス / 契約 / 運用 - 何をしている話か
他人を侵害しない / 自分の価値を守る - 法律なら何の法律か
個人情報保護法 / 著作権法 / 特許法 / 不正競争防止法 - 守る話なら何で守るか
法 / 営業秘密 / 限定提供データ / 契約 / 運用 - その選択肢は一般論として正しいのか、この設問に対して正しいのか
この5段階を挟むだけで、選択肢の見え方がかなり変わります。大事なのは、選択肢の評価を始める前に、設問が何を聞いているかを先に固定することです。
例題1 頻出問題っぽく見えるが、仕分けないと危険な問題
以下はシラバスに基づく自作例です。
問い
顔認識システムの導入に関する記述として、個人情報保護法上、最も直接に求められる対応を一つ選んでください。
選択肢
A. 取得したデータについて利用目的を特定し、必要な通知・公表を行う
B. 利用者に過度な監視と受け取られないよう、説明や掲示を充実させる
C. 性別や肌の色による精度差がないか継続的に検証する
D. 導入部門、法務、監査の責任分担と見直し手順を定める
正答
A
思考プロセス
まず、設問は「個人情報保護法上」と限定しています。したがって、最優先は法律レイヤーです。
- A
法律レイヤー、個人情報保護法の中心論点 - B
プライバシー配慮、社会的受容、倫理寄り - C
公平性、バイアス、倫理・品質寄り - D
AIガバナンス、組織統制
B、C、Dはいずれも重要です。ですが、この設問に対する正答ではありません。ここで「どれも大事だからBも正しそう」と考え始めると崩れます。
例題2 選択肢は同じ、問い方だけで正答が変わる問題
以下もシラバスに基づく自作例です。選択肢はまったく同じです。
このタイプは特に「頻出問題が本番でそのまま出る」感覚があるともったいない失点につながりやすいです。
共通選択肢
A. 取得したデータについて利用目的を特定し、必要な通知・公表を行う
B. 法令違反でなくても、利用者に過度な監視と受け取られないよう、説明や掲示を充実させる
C. 性別や肌の色などによる精度差がないか、継続的に検証する
D. 導入部門・法務・監査の責任分担と見直し手順を定める
問いA
個人情報保護法上、最も直接に求められる対応を一つ選んでください。
正答
A
問いB
法令遵守に加えて、利用者の不安や受容性への配慮として最も適切な対応を一つ選んでください。
正答
B
問いC
AIガバナンスの観点から、継続運用のために最も重要な対応を一つ選んでください。
正答
D
この例が示すこと
選択肢の中身は変わっていません。変わったのは、設問が要求するレイヤーだけです。
つまり、法律・倫理で落ちる人は、選択肢を評価しています。
受かる人は、先に設問のレイヤーを判定しています。
この差は大きいです。選択肢だけ見て反射で答える人は、BもCもDも全部よく見えるので崩れます。
例題3 守り視点で解く問題
以下もシラバスに基づく自作例です。
問い
自社が長年蓄積した高品質な学習用データを外部パートナーに共有しつつ、無断拡散を防ぎたい。このときの考え方として最も適切なものを一つ選んでください。
選択肢
A. すべて特許で保護する
B. 秘密として厳格管理できるなら営業秘密を検討し、共有前提なら限定提供データや契約条件も検討する
C. データであれば自動的に著作権で保護される
D. 法律上の保護は難しいため、何もできない
正答
B
思考プロセス
この設問は「侵害しない話」ではなく「守る話」です。したがって、守りの順番で考えます。
- 法で守れるか
- 不正競争防止法で守れるか
- 契約で縛るか
- 運用で支えるか
ここでAは過剰一般化です。すべてが特許になるわけではありません。Cも誤りです。データであること自体から一律に著作権が成立するわけではありません。Dも極端です。営業秘密、限定提供データ、契約、運用の組み合わせが現実的です。
この問題のポイントは、守り方を一つの制度に押し込めないことです。法で守れる部分、不正競争防止法で守る部分、契約で補う部分、運用で支える部分を重ねる発想が必要です。
このタイプは「頻出問題が本番でそのまま出る」感覚がある程度効きやすいように見えますが、選択肢側の組み合わせがかなり多く、「問題と対になる答えがあるはず」という覚え方が危険な部類になります。
例題では、営業秘密を起点にした選択肢がたまたま正解ですが、順序さえ合っていれば、特許法や著作権を起点した文言でも成立します。
さらに、例題ではわかりやすく他の選択肢をシンプルしていますが、特許法、著作権起点の選択肢と、営業秘密を起点が並んでいる場合は、特許法、著作権起点の選択肢の方が「より正しい」場合はあります。
学習の実務的な進め方
法律・倫理で点を安定させたいなら、順番はこうなります。
- シラバス確認
- 論点洗い出し
- 仕分け軸の作成
- 頻出問題の再解釈
- 自作例題で初見対応の訓練
ここでいう再解釈とは、「この文章が頻出」ではなく、「この問題はどの論点を、どの混線で問っているか」を抽出することです。
ただ、最初からこれを完璧にやろうとしなくて大丈夫です。最初は、問題を見たときに「これは法律の話か、倫理の話か、ガバナンスの話か」だけを意識するところからで十分です。その感覚がついてから、契約や運用、不正競争防止法のような保護手段の違いまで広げていく方が、無理なく進められます。
公的資料の参照先を固定しておくと、整理しやすくなります。
- 個人情報
個人情報保護委員会 - 著作権
文化庁 - 特許
特許庁 - AIガバナンス、契約、限定提供データ
経済産業省
この形にすると、試験対策と実務感覚がきれいにつながります。
まとめ
G検定の法律・倫理は、頻出問題の暗記ゲームではありません。シラバスを母集団として見て、公開されている問題や解説を標本として扱い、そこから仕分け軸を抽出する分野です。
そのときに効くのが、法律・倫理・ガバナンス・契約・運用の棚分けです。さらに、抵触回避だけでなく、何をどの手段で守るのかという守りの視点を入れると、論点の位置がきれいに定まります。
冒頭で触れた「頻出問題は本番では意外とそのまま出ないらしい」という話は、あくまで問題提起のきっかけです。この記事の主張は、その話の真偽には依存していません。公開されているシラバスと例題を見るだけでも、G検定の法律・倫理で必要なのが、表面の文章暗記ではなく、論点の仕分けであることは十分にわかります。
試験本番で強いのは、選択肢を見て反射する人ではありません。設問が何のレイヤーを問うているかを先に判定できる人です。
- 頻出文章の暗記ではなく、頻出論点の把握
- 正しそうな選択肢の評価ではなく、設問レイヤーの判定
- 抵触回避だけでなく、守りの運用を含めた整理
FAQ
Q1. G検定の法律・倫理は頻出問題だけ覚えれば十分ですか?
十分ではありません。G検定はシラバス準拠で出題されるため、頻出問題の文章暗記よりも、シラバス上の論点と、法律・倫理・ガバナンスの仕分け軸を理解する方が本番対応力につながります。
Q2. G検定の法律・倫理で点が取れない最大の理由は何ですか?
選択肢の内容だけを見て反射的に選ぶことです。法律の問いに倫理の一般論、個人情報保護法の問いにガバナンス論、特許の問いに営業秘密の選択肢が混ざると、一見正しそうでも設問に対する正答ではないことがあります。
Q3. G検定の法律・倫理はどう整理して学べばよいですか?
まずシラバスを基準に出題範囲を確認し、次に法律・倫理・ガバナンス・契約・運用のレイヤーを分けて整理します。そのうえで、侵害しない視点と守る視点の両方から各論点を見直すと、初見の問いにも対応しやすくなります。
Q4. 守り視点とは何ですか?
抵触しないかだけでなく、何をどの手段で守るかを考える視点です。個人情報保護法、著作権法、特許法、不正競争防止法、契約、運用統制のどれで守るのかを整理すると、試験でも実務でも判断しやすくなります。
参考文献
- 一般社団法人日本ディープラーニング協会「G検定(ジェネラリスト検定)シラバス改訂および公式テキスト第3版刊行のお知らせ
https://www.jdla.org/news/20240514001/ - 一般社団法人日本ディープラーニング協会「G検定の例題・過去問」
https://www.jdla.org/certificate/general/issues/ - 一般社団法人日本ディープラーニング協会「シラバス」
https://www.jdla.org/download-category/syllabus/ - 個人情報保護委員会「法令・ガイドライン等」
https://www.ppc.go.jp/personalinfo/legal/ - 文化庁「AIと著作権について」
https://www.bunka.go.jp/seisaku/chosakuken/aiandcopyright.html - 特許庁「AI関連技術に関する特許審査の事例について」
https://www.jpo.go.jp/system/laws/rule/guideline/patent/ai_jirei.html - 経済産業省「AIガバナンス」
https://www.meti.go.jp/policy/it_policy/ai-governance/index.html - 経済産業省「『AIの利用・開発に関する契約チェックリスト』を取りまとめました」
https://www.meti.go.jp/press/2024/02/20250218003/20250218003.html - 経済産業省「限定提供データに関する指針」
https://www.meti.go.jp/policy/economy/chizai/chiteki/guideline/h31pd.pdf
まず1冊ならこれ
深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト

最初の土台。新シラバス準拠で、第8章に「AIの法律と倫理」が入り、法律・倫理を試験範囲全体の中でどこに置くかをつかみやすい。試験対策の起点として最優先。
記事の主張に近い本
AIと法 実務大全

「法律・契約・個人情報・不正競争防止法・社内導入」をまとめて俯瞰したいなら、かなり相性がいい。開発者・提供者・利用者それぞれの視点で、知財、個人情報、機密情報、不正競争防止法、ライセンス契約、利用契約、社内導入ポイントまで射程に入っているので、「抵触しない」だけでなく「どう守るか」で整理しやすい。 ([日本加除出版][2])
倫理・ガバナンスを固める本
AIの倫理 人間との信頼関係を創れるか

倫理・責任・説明・偽情報・法的人格・持続可能性など、AIを社会に置いたときの論点が広く入っている。G検定の法律・倫理で混ざりやすい「法」と「倫理」の境目を意識するのに向いている。新しめの本なので、生成AI以後の論点感覚をつかみやすい。 ([KADOKAWAオフィシャルサイト][3])
高リスク分野のための機械学習 責任あるAI構築のための実践アプローチ

説明責任・公平性・プライバシーを、実務のフレームワークとして見たいならこれ。試験対策専用というより、「ガバナンス」「守り視点」を実装寄りに深める本。翻訳書だが日本語版が2025年に出ている。 ([オーム社][4])
AIの倫理学

倫理の全体像を、技術・哲学・実践をまたいで整理したいときに向く。「選択肢が一般論として正しいのか、設問に対して正しいのか」を考える下地として使いやすい。翻訳書だが、日本語版が丸善出版から出ている。 ([丸善ジュンク堂書店ネットストア][5])
契約・データ利活用を固める本
ガイドブック AI・データビジネスの契約実務〔第2版〕

「守り視点」に最も直結する本。経済産業省のAI・データ契約ガイドライン策定に関与した著者陣が、データ利用許諾契約、ソフトウェア開発・保守契約、ライセンス契約、クラウド利用契約、プライバシーポリシーなどを扱っている。G検定で契約が薄く感じる人の補強にちょうどいい。 ([商事ホーム][6])
個人情報・プライバシーを固める本
個人情報保護法

条文、ガイドライン、実務論点までかなり厚く押さえた本。G検定対策だけならオーバースペックだが、「個人情報保護法っぽい選択肢」と「ガバナンス・プライバシーっぽい選択肢」を切り分ける精度は上がる。2024年刊で、AIやカメラ、メタバース、プライバシーガバナンスまで章立てに入っているのが強い。 ([商事ホーム][7])
プライバシーと氏名・肖像の法的保護

個人情報保護法そのものではなく、プライバシー、氏名、肖像の保護を公法・私法の両面から考える本。「個人情報保護法とプライバシーは同じではない」をもう一段深く理解したいときに向く。
個人情報保護法の逐条解説 第6版

逐条で当たりたいときの定番。試験直前向けというより、法律の厳密な定義を見に行くための辞書として使う本。
著作権・知財を固める本
生成AIと著作権の論点

「著作権法の問いに倫理っぽい選択肢が混ざる」「契約や肖像・声の論点も近くに来る」を整理するのに向く。開発・学習段階、生成・利用段階、AI生成物の著作物性、契約との関係、肖像と声の無許諾利用まで扱っている。生成AI時代の著作権を直球で押さえるなら最有力。
著作権法 第4版

「アイデアは保護されず、表現が保護される」という基本線をきちんと押さえたいならこれ。G検定向けには少し硬めだが、著作権法そのものの骨格を理解するには強い。
年報知的財産法 2024-2025

AIと著作権法が特集テーマに入っている。体系書というより、近年の論点整理や動向把握に向く。試験専用ではないが、生成AIまわりの知財論点を広めに見たいなら有用。
どう買うか迷ったらこの順
- 深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト
- ガイドブック AI・データビジネスの契約実務〔第2版〕
- AIの倫理 人間との信頼関係を創れるか
かなり実用的な組み合わせ
- バランス型
- 公式テキスト 第3版
- AI・データビジネスの契約実務
- AIの倫理 人間との信頼関係を創れるか
- 法務寄り
- 公式テキスト 第3版
- AIと法 実務大全
- 生成AIと著作権の論点
- 個人情報・ガバナンス寄り
- 公式テキスト 第3版
- 個人情報保護法
- 高リスク分野のための機械学習
コメント