その他の数理的なエッセイはこちら

要約(3行)
- ロジスティック回帰→多層NNを決定境界のグラフで見て、非線形化の意味を腹落ちさせます
- 自己回帰×自己教師あり(スケーリング則まで)で、生成AIが埋めたがる理由(性格)を説明します
- 法律・最新版ガイドライン・契約・倫理を守りのフローにして、境界線を引けるようにします
- 合わせて読むことおすすめの記事
- この文章の立ち位置
- 記事の狙い
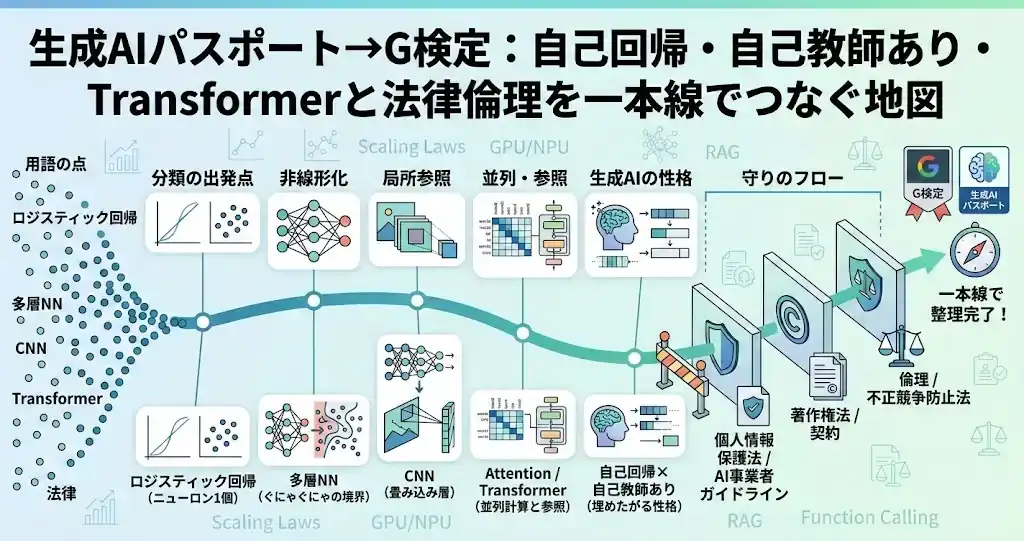
- 一本線の全体像
- 分類の出発点:ロジスティック回帰はニューロン1個分
- 出力を増やす:多クラスとマルチラベル
- 非線形化:層を重ねてぐにゃぐにゃの境界を作る
- 決定境界で理解するロジスティック回帰と多層NN
- CNNの入口:畳み込み層のフィルタ的処理
- 畳み込み層の直感をグラフで見る
- Attentionの要点:要約ではなく参照
- Transformerの位置:Attentionを主役に据えて並列化
- 生成AIの中身:自己回帰×自己教師あり
- スケーリング則:性能が伸び続けた時期の共通言語
- 生成AIの性格:埋めたがる、断言に寄る、根拠が薄いと危ない
- オーケストレーションとツール提示:LLM・オーケストレーター・ツールの分業
- スケール競争と推論最適化:GPUから推論エンジン、NPUへ
- 法律・ガイドラインの一本線:守りたいものがあるときの基本フロー
- 最新版ガイドラインの参照枠:事業者と行政
- G検定・生成AIパスポートで効く頻出ひっかけ3つ
- 生成AIの実務チェックリスト
- FAQ
- 参考文献
- まとめ
- 合わせて読むことおすすめの記事
- 分類の出発点(ロジスティック回帰・評価・特徴量)
- ニューラルネット〜CNN(決定境界→非線形化→畳み込み)
- Attention〜Transformer(仕組みと実装の両輪)
- 自己教師あり・LLM(スケーリング〜評価・生成の勘所)
- オーケストレーション・ツール呼び出し・RAG(使われ方の設計)
- GPU/CUDA・実装基盤(計算資源の感覚をつかむ)
- 守り(法律・ガバナンス・倫理・個人情報)
- 最小セット
合わせて読むことおすすめの記事



この文章の立ち位置
この文章は「線を通す」ことを優先します。
だから、網羅は目的にしません。
この線の外で、今回は捨てます。
- 決定木、SVM、ベイズ、アンサンブルの詳細
- RNNの詳細(LSTM/GRUの細部、学習安定化の深掘り)
- 生成モデルの詳細(GAN、拡散モデル、VAEなどの作り分け)
- 数式の厳密導出(試験の理解に必要な直感より先の層)
捨てた代わりに、生成AIに直結する主線は濃くします。
分類 → ニューラルネット → 画像 → Attention → Transformer → 生成AI
G検定に対しては「前半が技術寄りで厚め」です。
生成AIパスポートに対しては、ロジスティック回帰〜多層NNは少し詳細ですが、Attention以降と法律・ガイドライン・運用設計はそのまま共通で使えます。
記事の狙い
生成AIパスポートやG検定でつらくなるのは、用語が点に見えるときです。
点を線にすると、暗記が「流れの確認」になりやすいです。
この線のゴールは、プロンプト小技の暗記ではありません。
生成AIの性格を、構造と学習から説明できる状態になることです。
性格が読めると、使い方を自分で設計しやすくなります。
一本線の全体像
この線は、最初は分類で境界線を引く話です。
最後は、生成AIが埋めたがる性格に対して、法律・ガイドライン・契約・倫理で境界線を引く話に戻ってきます。
分類の出発点:ロジスティック回帰はニューロン1個分
最初の願いは「AかBかを当てたい」です。
ここでロジスティック回帰が出てきます。
- 入力を重み付き和でまとめます(線形結合)
- シグモイドで0〜1に潰して確率っぽくします
この形は、ニューラルネットの最小単位(ニューロン1個)とほぼ同型です。
ここがつながると、ニューラルネットの入口が一気に軽くなります。
出力を増やす:多クラスとマルチラベル
二択だけでは現実のタスクが足りません。
ここで「答えの形」を増やします。
- 多クラス分類(どれか1つ)では、クラス数ぶんの出力を並べてsoftmaxで確率分布にします
- マルチラベル分類(複数同時)では、ラベル数ぶんの出力を並べて各出力にsigmoidをかけます
ニューロンを増やすと、答えの形式が増える、と覚えると迷子になりにくいです。
ただし境界はまだ、基本まっすぐ寄りになりがちです。
非線形化:層を重ねてぐにゃぐにゃの境界を作る
世の中の境界はだいたいぐにゃぐにゃしています。
そこで隠れ層と活性化関数(ReLUなど)で非線形性を入れます。
- 隠れ層を入れます
- 活性化関数で非線形性を入れます
- 途中で表現(見方)を作り替えながら最後に分類します
この「途中の見方」が、特徴量・表現学習の感覚です。
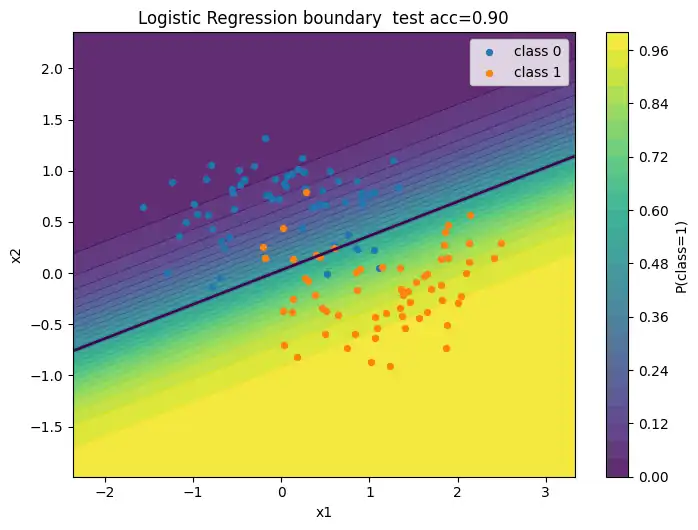
決定境界で理解するロジスティック回帰と多層NN
コードは折りたたみ、グラフだけ見える構成にします。
ロジスティック回帰の決定境界
Pythonコード(ロジスティック回帰の境界)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import LogisticRegression
X, y = make_moons(n_samples=500, noise=0.28, random_state=7)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=7, stratify=y
)
model = make_pipeline(StandardScaler(), LogisticRegression(max_iter=8000))
model.fit(X_train, y_train)
acc = model.score(X_test, y_test)
x_min, x_max = X[:, 0].min() - 0.8, X[:, 0].max() + 0.8
y_min, y_max = X[:, 1].min() - 0.8, X[:, 1].max() + 0.8
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 450), np.linspace(y_min, y_max, 450))
grid = np.c_[xx.ravel(), yy.ravel()]
zz = model.predict_proba(grid)[:, 1].reshape(xx.shape)
plt.figure(figsize=(7.2, 5.4))
cs = plt.contourf(xx, yy, zz, levels=25, alpha=0.85)
plt.colorbar(cs, label="P(class=1)")
plt.contour(xx, yy, zz, levels=[0.5], linewidths=2)
plt.scatter(X_test[y_test == 0, 0], X_test[y_test == 0, 1], s=18, label="class 0")
plt.scatter(X_test[y_test == 1, 0], X_test[y_test == 1, 1], s=18, label="class 1")
plt.legend(loc="upper right")
plt.title(f"Logistic Regression boundary test acc={acc:.2f}")
plt.xlabel("x1")
plt.ylabel("x2")
plt.tight_layout()
plt.show()多層NN(MLP)の決定境界

Pythonコード(2層MLPの境界)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
from sklearn.neural_network import MLPClassifier
X, y = make_moons(n_samples=500, noise=0.28, random_state=7)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=7, stratify=y
)
model = make_pipeline(
StandardScaler(),
MLPClassifier(
hidden_layer_sizes=(16, 16),
activation="relu",
solver="adam",
alpha=1e-4,
max_iter=6000,
random_state=7,
),
)
model.fit(X_train, y_train)
acc = model.score(X_test, y_test)
x_min, x_max = X[:, 0].min() - 0.8, X[:, 0].max() + 0.8
y_min, y_max = X[:, 1].min() - 0.8, X[:, 1].max() + 0.8
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 450), np.linspace(y_min, y_max, 450))
grid = np.c_[xx.ravel(), yy.ravel()]
zz = model.predict_proba(grid)[:, 1].reshape(xx.shape)
plt.figure(figsize=(7.2, 5.4))
cs = plt.contourf(xx, yy, zz, levels=25, alpha=0.85)
plt.colorbar(cs, label="P(class=1)")
plt.contour(xx, yy, zz, levels=[0.5], linewidths=2)
plt.scatter(X_test[y_test == 0, 0], X_test[y_test == 0, 1], s=18, label="class 0")
plt.scatter(X_test[y_test == 1, 0], X_test[y_test == 1, 1], s=18, label="class 1")
plt.legend(loc="upper right")
plt.title(f"2-layer MLP boundary test acc={acc:.2f}")
plt.xlabel("x1")
plt.ylabel("x2")
plt.tight_layout()
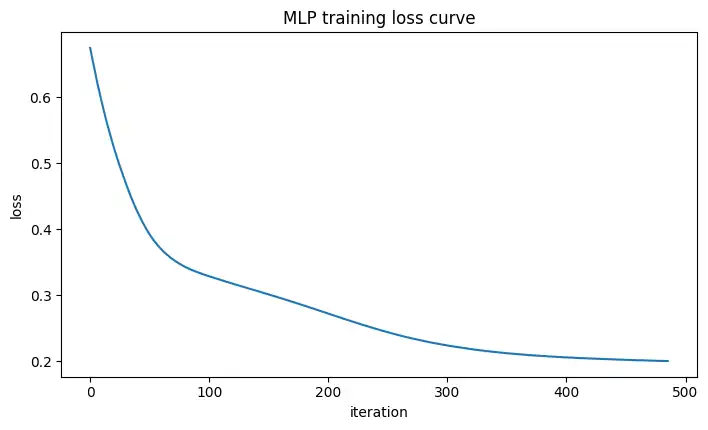
plt.show()学習の進み方(損失曲線)
Pythonコード(MLPの損失曲線)
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
from sklearn.neural_network import MLPClassifier
X, y = make_moons(n_samples=500, noise=0.28, random_state=7)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=7, stratify=y
)
model = make_pipeline(
StandardScaler(),
MLPClassifier(
hidden_layer_sizes=(16, 16),
activation="relu",
solver="adam",
alpha=1e-4,
max_iter=2000,
random_state=7,
),
)
model.fit(X_train, y_train)
mlp = model.named_steps["mlpclassifier"]
plt.figure(figsize=(7.2, 4.4))
plt.plot(mlp.loss_curve_)
plt.title("MLP training loss curve")
plt.xlabel("iteration")
plt.ylabel("loss")
plt.tight_layout()
plt.show()CNNの入口:畳み込み層のフィルタ的処理
画像は情報量が大きく、全結合で扱うと重くなりやすいです。
そこで「局所から見る」構造を入れます。これが畳み込み層です。
畳み込み層は、同じフィルタを画像全体に滑らせます(重み共有)。
初期層では次のようなフィルタ的反応が出やすいです(実際のフィルタは学習で決まります)。
- エッジ検出(方向付き)
- ぼかし(低周波化、ノイズ除去寄り)
- ブロブ検出(点・塊への反応)
- テクスチャ検出(繰り返しパターンへの反応)
- シャープ化(高周波強調、輪郭を立てる)
畳み込み層の直感をグラフで見る
学習済みCNNの重みではなく、畳み込み層がやっている「局所に同じ処理を滑らせる」感覚を古典フィルタで例示します。
エッジ以外(ぼかし・ブロブ・シャープ化)も並べます。
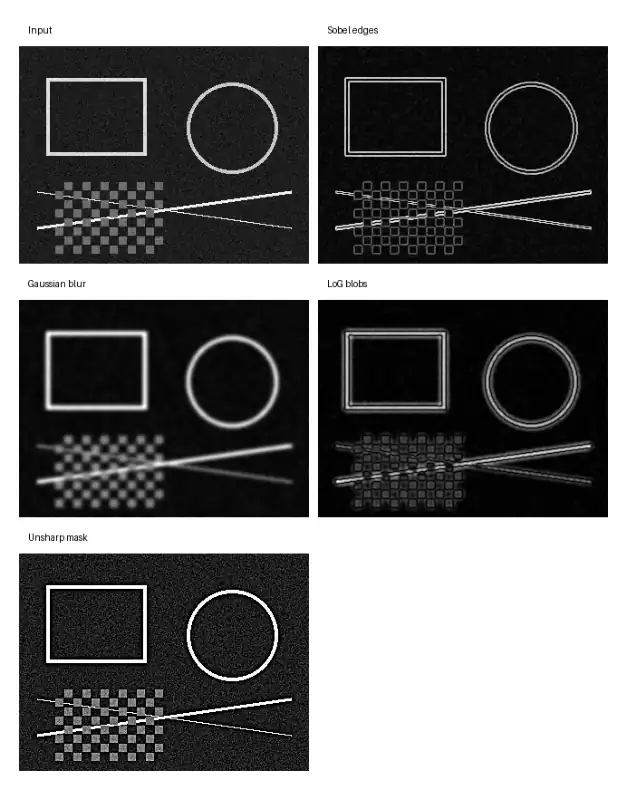
Pythonコード(畳み込みフィルタの可視化)
import numpy as np
from PIL import Image, ImageDraw
from scipy import ndimage
import matplotlib.pyplot as plt
W, H = 320, 240
img = Image.new("L", (W, H), 30)
draw = ImageDraw.Draw(img)
draw.rectangle([30, 35, 140, 120], outline=220, width=4)
draw.ellipse([185, 40, 285, 140], outline=200, width=4)
draw.line([20, 200, 300, 160], fill=240, width=4)
draw.line([20, 160, 300, 200], fill=240, width=2)
for y0 in range(150, 230, 10):
for x0 in range(40, 160, 10):
if ((x0 // 10) + (y0 // 10)) % 2 == 0:
draw.rectangle([x0, y0, x0 + 8, y0 + 8], fill=110)
np_img = np.array(img).astype(np.float32)
rng = np.random.default_rng(7)
np_img = np.clip(np_img + rng.normal(0, 10, size=np_img.shape), 0, 255)
sobel_x = ndimage.sobel(np_img, axis=1)
sobel_y = ndimage.sobel(np_img, axis=0)
edge_mag = np.hypot(sobel_x, sobel_y)
blur = ndimage.gaussian_filter(np_img, sigma=2.0)
log = np.abs(ndimage.gaussian_laplace(np_img, sigma=2.0))
sharp = np.clip(np_img + 1.2 * (np_img - blur), 0, 255)
def to_uint8(a):
a = a - a.min()
if a.max() > 1e-9:
a = a / a.max()
return (a * 255).astype(np.uint8)
tiles = [
("Input", to_uint8(np_img)),
("Sobel edges", to_uint8(edge_mag)),
("Gaussian blur", to_uint8(blur)),
("LoG blobs", to_uint8(log)),
("Unsharp mask", to_uint8(sharp)),
]
tile_w, tile_h, label_h, gap = 320, 240, 30, 10
out_tiles = []
for name, arr in tiles:
base = Image.fromarray(arr).convert("L")
canvas = Image.new("L", (tile_w, tile_h + label_h), 255)
canvas.paste(base, (0, label_h))
d = ImageDraw.Draw(canvas)
d.text((10, 6), name, fill=0)
out_tiles.append(canvas)
cols = 2
rows = int(np.ceil(len(out_tiles) / cols))
mont_w = cols * tile_w + (cols + 1) * gap
mont_h = rows * (tile_h + label_h) + (rows + 1) * gap
mont = Image.new("L", (mont_w, mont_h), 255)
for i, t in enumerate(out_tiles):
r = i // cols
c = i % cols
x = gap + c * (tile_w + gap)
y = gap + r * (tile_h + label_h + gap)
mont.paste(t, (x, y))
# --- ここから matplotlib 表示(mont.show() の代わり) ---
plt.figure(figsize=(12, 8))
plt.imshow(mont, cmap="gray", vmin=0, vmax=255)
plt.axis("off")
plt.tight_layout()
plt.show()Attentionの要点:要約ではなく参照
RNN系は「過去を1本の要約(隠れ状態)に押し込む」設計でした。
長い文脈になるほど、その要約から情報がこぼれやすくなります。
Attentionは発想を変えます。
全部を圧縮して持つのではなく、必要なところをその都度参照します。
ここで重要なのは、畳み込みのように近傍だけを見る作りではなく、内積で「どことどこを結びつけるか」を重みとして作るところです。
- Query(いま知りたい観点)
- Key(各トークンの索引)
- Value(取り出す中身)
QueryとKeyの内積(スコア)を並べ、softmaxで重みにします。
そしてValueを重み付きで混ぜます。
この構造だと、局所性と広域性の両方を受容できます。
- 近くを強く参照すれば局所的になります
- 遠くを強く参照すれば長距離依存になります
- どちらになるかは、学習で重みの付き方が決まります
さらに、Attentionは行列積(内積の集合)として書けます。
この書け方が、並列計算と相性が良い理由になります。
ただし、系列長が伸びるほど参照対象が増えるので、計算量とメモリは増えます。
「よく見える」代わりに「重い」というトレードオフを持ちます。
Transformerの位置:Attentionを主役に据えて並列化
TransformerはAttentionを中心に置き、学習と実装をしやすい形に整えたものです。
ここで説明されがちなのが「RNNと違って並列化できる」という点です。
この説明は正しいのですが、試験で事故りやすい落とし穴があります。
それは「トークンを一気に処理できる=順序を見ていない」と誤解してしまうことです。
Transformerがトークンをまとめて処理できるのは、処理(計算)の並列性の話です。
一方で、トークンの前後関係(系列の位置情報)は、位置エンコーディング(positional encoding / positional embedding)で別途持たせています。
学習(訓練)では全トークンを並列に扱えますが、生成(推論)では自己回帰なので基本は1トークンずつ逐次になります。
つまり、Transformerは次の2つを両立しています。
- 計算としては、トークンをまとめて行列演算できる(並列処理に向きます)
- 意味としては、位置情報を与えることで順序を扱えます
RNNは前の状態を次へ渡す構造なので、計算が逐次になりやすいです。
Transformerは全トークン間の参照を行列演算でまとめて書けるので、計算が並列になりやすいです。
ただし、並列だからといって順序を捨てたわけではなく、順序は位置情報として保持されています。
Attention Is All You Need(arXiv)
https://arxiv.org/abs/1706.03762
生成AIの中身:自己回帰×自己教師あり
生成AIの性格は、構造面(自己回帰)と学習面(自己教師あり)で決まりやすいです。
構造面:確率の自己回帰モデル
言語モデルは「次に来そうな候補」を確率分布として出し、それを繰り返して文章を伸ばします。
確率モデルとしては自己回帰の形になります。
p(x1, x2, ..., xT) = ∏t p(xt | x< t)線形回帰のように連続値を回帰するというより、語彙という巨大な集合に対する確率を逐次的につないでいく形になります。
学習面:自己教師あり学習がスケールを成立させる
教師あり学習は、入力とラベルが対になったデータセットが必要です。
一方で次トークン予測は、正解が文章の中に最初から埋まっています(続きの単語)ので、モデルだけが知らない正解を当てる形で学習が回ります。
自動穴埋め問題生成器が一度できると、あとは文章をひたすら渡すだけで学習用の(入力, 正解)ペアが大量に作られます。
この性質が、モデル規模・データ量・計算量の勝負に入りやすかった理由の一つです。
スケーリング則:性能が伸び続けた時期の共通言語
モデル規模・データ量・計算量を増やすと損失がべき則で改善する、という経験則がスケーリング則(Scaling Laws)として知られています。
Scaling Laws for Neural Language Models(arXiv)
https://arxiv.org/abs/2001.08361
また「計算効率の良い伸ばし方」という観点では、モデルだけでなくデータ(トークン)側の最適も含めて整理した議論もあります(通称Chinchillaの整理として知られます)。
Training Compute-Optimal Large Language Models(arXiv)
https://arxiv.org/abs/2203.15556
生成AIの性格:埋めたがる、断言に寄る、根拠が薄いと危ない
自己回帰×自己教師ありで学んだモデルは、だいたい次の性格を持ちやすいです。
- 空白があると埋めたがります
- それっぽい整合を優先しやすいです
- 参照材料が入力にないと補完に寄りやすいです
この性格が分かると、プロンプトの小技より先に設計が立ちます。
- 前提を固定してから書かせます
- 根拠となる資料や制約を入力として与えます
- 検証ステップまでタスクに含めます
オーケストレーションとツール提示:LLM・オーケストレーター・ツールの分業
生成AIの「使い方」を語るだけだと半分で、実際は「使われ方」まで見ると安定します。
典型的には、次の3つが分業します。
オーケストレーター
ユーザーからの入力を受け取り、全体の取りまとめをします。
- 会話の状態管理(履歴、ユーザー設定、セッション)
- どのツールを使うかの制御(ルーティング、権限、ガードレール)
- 結果の統合(ツール結果を集め、次の一手を回す)
実装上は、アプリ側のサーバ、エージェント実行基盤、ワークフローエンジンがこの役割を持つことが多いです。
LLM
文章把握と意思決定を担います。
- 入力を解釈し、タスクに分解します
- 何を調べ、何を計算し、何を生成すべきかを決めます
- ツール呼び出しのための引数(指示書)を作ります
- ツール結果を読んで、次の指示を更新します
ツール
「実行」を担います。
代表例は次の通りです。
- 画像生成(画像モデル)
- 検索・社内検索(外部検索、RAG、ナレッジベース参照)
- 計算・コード実行(電卓、Python実行、シミュレーション)
- データ取得(DBクエリ、API呼び出し)
- 音声(音声認識、音声合成)
- ファイル生成(PDF、スライド、表、ドキュメント)
Function calling / tool calling(一次情報)
https://developers.openai.com/api/docs/guides/function-calling
この分業が見えると、運用が変わります。
- いきなり実行させず、まずLLMに「実行用の指示書」を作らせます
- 指示書をレビューし、禁止事項の漏れや余計な脚色を潰します
- オーケストレーターがツールを実行し、結果を回収します
- LLMが結果を解釈し、次の一手を決めます
画像生成はこの構造が見えやすい例です。
Image generation(一次情報)
https://developers.openai.com/api/docs/guides/image-generation
GPT Image API(一次情報)
https://help.openai.com/ja-jp/articles/11128753-gpt-image-api
DALL·E 3 API(一次情報、GPT Image APIへの導線あり)
https://help.openai.com/ja-jp/articles/8555480-dalle-3-api
スケール競争と推論最適化:GPUから推論エンジン、NPUへ
スケーリング則が「計算資源の勝負」を分かりやすくし、学習と推論の需要が増えました。
ここ数年で大きかった図式の一つは、CUDAとフレームワークの組み合わせです。
- GPUは並列計算が得意で、深層学習の行列演算と相性が良いです
- CUDAはGPUを汎用計算として使うための土台です
- PyTorchやTensorFlowは、ユーザーがCUDAを強く意識しなくてもGPUを使える体験を作りました
- 結果として、GPUを増やすほど伸びる時期(スケーリング則の時期)に、NVIDIA需要が増えやすい構造ができました
CUDA(一次情報)
https://developer.nvidia.com/cuda
PyTorch CUDA semantics(一次情報)
https://docs.pytorch.org/docs/stable/notes/cuda.html
ここに加えて、最近は「推論を安く・速く・省電力で回す」ことが競争軸として強くなっています。
訓練はしないが推論はする、という利用形態が増えると、推論特化ハード(NPU)が脚光を浴びやすくなります。
その流れに合わせて、もともとエッジAI由来で発展してきた推論エンジンやランタイムが、クラウドやローカル運用にも入ってきます。
- ONNX Runtime
- TensorFlow Lite
- OpenVINO
これらは基本的に「演算ノードの構造(計算グラフ)」を受け取り、推論時の実行の仕方(演算融合、量子化、並列化、カーネル選択など)を、実行環境に合わせて最適化する設計です。
- ONNX(一次情報)
https://onnx.ai/ - ONNX Runtime Execution Providers(一次情報)
https://onnxruntime.ai/docs/execution-providers/ - TensorFlow Lite(一次情報)
https://www.tensorflow.org/lite/guide?hl=ja - OpenVINO NPU Device(一次情報)
https://docs.openvino.ai/2025/openvino-workflow/running-inference/inference-devices-and-modes/npu-device.html
結果として、ローカル環境でも動かしやすくなったり、クラウドでも速度優先の構成で使われたりします。
また、消費電力や冷却などの制約が注目される文脈では、省電力=推論最適化=NPUという語られ方が出やすいです。
法律・ガイドラインの一本線:守りたいものがあるときの基本フロー
生成AIが埋めたがる性格を持つなら、人間側は境界線を引く必要があります。
法律やガイドラインは暗記科目ではなく、境界線の設計図として置くと一本線になります。
守りたいものがある場合、次の順で考えると整理しやすいです。
- 対象が直撃する法律で保護します
個人情報の保護に関する法律(e-Gov)
https://laws.e-gov.go.jp/law/415AC0000000057
著作権法(e-Gov)
https://laws.e-gov.go.jp/law/345AC0000000048
特許法(e-Gov)
https://laws.e-gov.go.jp/law/334AC0000000121
- それでも難しければ、秘密管理性などを確保して営業秘密として守ります(不正競争防止法の枠)
不正競争防止法(e-Gov)
https://laws.e-gov.go.jp/law/405AC0000000047
営業秘密(経産省)
https://www.meti.go.jp/policy/economy/chizai/chiteki/trade-secret.html
- さらに難しければ、限定提供性などを確保して限定提供データとして守ります
限定提供データ指針(経産省PDF)
https://www.meti.go.jp/policy/economy/chizai/chiteki/guideline/h31pd.pdf
- それでも無理な部分を、契約で保護します(当事者を中心に縛る設計になります)
そして抵触しない側でも、倫理・道徳に気を配る必要があります。
法律に触れていなくても、炎上や信用問題になる領域があるからです。
最新版ガイドラインの参照枠:事業者と行政
ガイドラインは古い版を参照すると陳腐化しやすいですが、最低限、最新版と第1.0版を並べて見ると線が見えます。
AI事業者ガイドライン(資料掲載ページ、各版への導線)
https://www.meti.go.jp/shingikai/mono_info_service/ai_shakai_jisso/20240419_report.html
AI事業者ガイドライン(第1.1版)本編(PDF)
https://www.meti.go.jp/shingikai/mono_info_service/ai_shakai_jisso/pdf/20250328_1.pdf
AI事業者ガイドライン(第1.1版)本編(概要)(PDF)
https://www.meti.go.jp/shingikai/mono_info_service/ai_shakai_jisso/pdf/20250328_2.pdf
AI事業者ガイドライン(第1.0版)本編(PDF)
https://www.meti.go.jp/shingikai/mono_info_service/ai_shakai_jisso/pdf/20240419_1.pdf
行政向けの参照枠としては、デジタル庁の「生成AIの調達・利活用ガイドライン」が強いです。
「行政の進化と革新のための生成AIの調達・利活用に係るガイドライン」を策定しました(デジタル庁)
https://www.digital.go.jp/news/3579c42d-b11c-4756-b66e-3d3e35175623
行政の進化と革新のための生成AIの調達・利活用に係るガイドライン(PDF)
https://www.digital.go.jp/assets/contents/node/basic_page/field_ref_resources/e2a06143-ed29-4f1d-9c31-0f06fca67afc/80419aea/20250527_resources_standard_guidelines_guideline_01.pdf
個人情報保護委員会:生成AIサービスの利用に関する注意喚起等
https://www.ppc.go.jp/news/careful_information/230602_AI_utilize_alert/
文化庁:AIと著作権に関するチェックリスト&ガイダンス(PDF)
https://www.bunka.go.jp/seisaku/bunkashingikai/chosakuken/seisaku/r06_02/pdf/94089701_05.pdf
G検定・生成AIパスポートで効く頻出ひっかけ3つ
この一本線に、即効性のある事故防止を足します。
softmaxとsigmoidの使い分け
多クラス(どれか1つ)ならsoftmaxです。
マルチラベル(複数同時)ならsigmoidです。
「確率っぽいからsoftmax」みたいに覚えると事故ります。
「同時成立できるか」で切るのが安全です。
Transformerは並列でも順序を捨てない
Transformerがトークンをまとめて処理できるのは、計算の並列性の話です。
順序は位置エンコーディングで保持されます。
並列=順序が分からない、は誤りです。
自己教師あり学習の言い換え
自己教師ありは「ラベル不要」ではなく、「ラベルを人手で作らず、データから教師信号を作る」です。
次トークン予測なら、正解は文章の続きとしてデータに埋まっています。
生成AIの実務チェックリスト
- 入力に個人情報・営業秘密・未公開発明・権利物が混ざっていないか、先に分類してから渡します
- 出力には根拠・制約・検証ステップまで含め、断言だけで止めないようにします
- ツール連携がある場合は、外部に送られる情報を前提に入力を最小化します
FAQ
Q1. ロジスティック回帰がニューロン1個分と言える理由は何ですか?
A1. 入力の重み付き和を作り、シグモイドで0〜1に変換して確率として出す形が、単一ニューロン(活性化がシグモイドの場合)とほぼ同型だからです。
Q2. 多層NNで決定境界がぐにゃぐにゃになる理由は何ですか?
A2. 隠れ層と活性化関数で非線形性を入れると、途中で表現を作り替えながら分類できるため、線形分離できないデータでも境界を曲げられるからです。
Q3. 畳み込み層はエッジ検出だけをしているのですか?
A3. エッジは分かりやすい例ですが、ぼかし、ブロブ検出、テクスチャ検出、シャープ化のようなフィルタ的反応も初期層で出やすいです(実際のフィルタは学習で決まります)。
Q4. 自己教師あり学習がスケールを後押しした理由は何ですか?
A4. 次トークン予測のように正解がデータ内に埋まっている学習形式だと、人手ラベル作成がボトルネックになりにくく、生データを増やすほど学習ペアが自動で増えるからです。
Q5. Transformerは並列処理できるなら、単語の順序はどう扱うのですか?
A5. 並列処理できるのは計算の都合で、順序を捨てたという意味ではありません。位置エンコーディングで各トークンの位置情報を持たせ、Self-Attentionで参照するときに順序を反映できるようにしています。
Q6. 画像生成はDALL·E 3だけを覚えれば十分ですか?
A6. DALL·E 3は重要ですが、現在はGPT Image APIなども含めた画像生成APIとして整理されているので、系譜として理解すると陳腐化しにくいです。一次情報としては https://developers.openai.com/api/docs/guides/image-generation と https://help.openai.com/ja-jp/articles/11128753-gpt-image-api を参照します。
Q7. AI事業者ガイドラインはどの版を参照すべきですか?
A7. 原則は最新版(第1.1版など)を参照し、差分理解のために第1.0版も並べて置くのが安全です。資料掲載ページは https://www.meti.go.jp/shingikai/mono_info_service/ai_shakai_jisso/20240419_report.html です。
Q8. この内容は生成AIパスポートにも効きますか?
A8. 効きます。生成AIパスポートでは前半(ロジスティック回帰〜多層NN)がやや詳細ですが、Attention以降の考え方、生成AIの性格、法律・ガイドライン・運用設計は共通の射程に入ります。
参考文献
Attention Is All You Need(arXiv)
https://arxiv.org/abs/1706.03762
Scaling Laws for Neural Language Models(arXiv)
https://arxiv.org/abs/2001.08361
Training Compute-Optimal Large Language Models(arXiv)
https://arxiv.org/abs/2203.15556
OpenAI Function calling / tool calling(一次情報)
https://developers.openai.com/api/docs/guides/function-calling
OpenAI Image generation(一次情報)
https://developers.openai.com/api/docs/guides/image-generation
OpenAI GPT Image API(一次情報)
https://help.openai.com/ja-jp/articles/11128753-gpt-image-api
OpenAI DALL·E 3 API(一次情報)
https://help.openai.com/ja-jp/articles/8555480-dalle-3-api
NVIDIA CUDA(一次情報)
https://developer.nvidia.com/cuda
PyTorch CUDA semantics(一次情報)
https://docs.pytorch.org/docs/stable/notes/cuda.html
ONNX(一次情報)
https://onnx.ai/
ONNX Runtime Execution Providers(一次情報)
https://onnxruntime.ai/docs/execution-providers/
TensorFlow Lite(一次情報)
https://www.tensorflow.org/lite/guide?hl=ja
OpenVINO NPU Device(一次情報)
https://docs.openvino.ai/2025/openvino-workflow/running-inference/inference-devices-and-modes/npu-device.html
AI事業者ガイドライン(資料掲載ページ)
https://www.meti.go.jp/shingikai/mono_info_service/ai_shakai_jisso/20240419_report.html
AI事業者ガイドライン(第1.1版)本編(PDF)
https://www.meti.go.jp/shingikai/mono_info_service/ai_shakai_jisso/pdf/20250328_1.pdf
AI事業者ガイドライン(第1.0版)本編(PDF)
https://www.meti.go.jp/shingikai/mono_info_service/ai_shakai_jisso/pdf/20240419_1.pdf
デジタル庁:「行政の進化と革新のための生成AIの調達・利活用に係るガイドライン」を策定しました
https://www.digital.go.jp/news/3579c42d-b11c-4756-b66e-3d3e35175623
行政の進化と革新のための生成AIの調達・利活用に係るガイドライン(PDF)
https://www.digital.go.jp/assets/contents/node/basic_page/field_ref_resources/e2a06143-ed29-4f1d-9c31-0f06fca67afc/80419aea/20250527_resources_standard_guidelines_guideline_01.pdf
個人情報の保護に関する法律(e-Gov)
https://laws.e-gov.go.jp/law/415AC0000000057
著作権法(e-Gov)
https://laws.e-gov.go.jp/law/345AC0000000048
特許法(e-Gov)
https://laws.e-gov.go.jp/law/334AC0000000121
不正競争防止法(e-Gov)
https://laws.e-gov.go.jp/law/405AC0000000047
個人情報保護委員会:生成AIサービスの利用に関する注意喚起等
https://www.ppc.go.jp/news/careful_information/230602_AI_utilize_alert/
文化庁:AIと著作権に関するチェックリスト&ガイダンス(PDF)
https://www.bunka.go.jp/seisaku/bunkashingikai/chosakuken/seisaku/r06_02/pdf/94089701_05.pdf
まとめ
この線は、最初の分類(境界線を引く)から、最後の法律・ガイドライン・契約・倫理(守る境界線を引く)へ戻ってきます。
用語を点で暗記するのではなく、課題→設計→トレードオフの因果でつなぐと、生成AIの性格も扱いやすくなります。
まとめのまとめ(3行)
- ロジスティック回帰→多層NNを決定境界で見ると、非線形化の意味が一発で分かります
- スケーリング則まで含めて自己回帰×自己教師ありを押さえると、生成AIの性格が読めます
- 最新版ガイドラインまで含めて守りのフローを置くと、生成AIが埋めたがる性格に対して境界線を引けます
合わせて読むことおすすめの記事
その他の数理的なエッセイはこちら
分類の出発点(ロジスティック回帰・評価・特徴量)
Pythonではじめる機械学習(オライリー・ジャパン)

伝統的MLの基本(分類・評価・特徴量)をscikit-learnで押さえる土台向き。
機械学習のエッセンス(SBクリエイティブ)

いくつかの代表アルゴリズムを「自分で実装する」寄りで、ブラックボックス感を消す用途に合う。
機械学習教本(森北出版)

数式を抑えめにしつつ回帰〜ディープラーニングまで俯瞰しやすい。
パターン認識と機械学習〈上〉(Bishop、邦訳)

線形識別モデル〜ニューラルネットワークまで、理屈側を重く読みたい人向け。
ニューラルネット〜CNN(決定境界→非線形化→畳み込み)
ゼロから作るDeep Learning(斎藤康毅、オライリー・ジャパン)

逆伝播やCNNまで「作って分かる」系。記事の決定境界〜CNNの流れと相性がいい。
深層学習(Goodfellow/Bengio/Courville、邦訳)

体系的な教科書。理論を通しで確認したいときの参照先。
ゼロから作るDeep Learning ❸ フレームワーク編(オライリー・ジャパン)

自動微分やフレームワークの“腹落ち”に寄せられる。
Attention〜Transformer(仕組みと実装の両輪)
Transformerによる自然言語処理(朝倉書店)

仕組みの説明+Pythonコードで、Transformer中心に学べる。
機械学習エンジニアのためのTransformers(オライリー・ジャパン、邦訳)

Hugging Face Transformersで実務に寄せた本。蒸留・量子化・枝刈り・ONNX Runtimeなど「推論を軽くする話」まで射程に入る。
ゼロから作るDeep Learning ❷ 自然言語処理編(オライリー・ジャパン)

NLPやAttention/RNN系を実装で辿れる。記事の「点→線」づくりの補強にちょうどいい。
自己教師あり・LLM(スケーリング〜評価・生成の勘所)
大規模言語モデル入門(技術評論社)

理論と実装を両方扱う入門。
大規模言語モデル入門Ⅱ(技術評論社)

入門の続編で、評価や生成LLM周りを厚めにする方向。
オーケストレーション・ツール呼び出し・RAG(使われ方の設計)
LangChainとLangGraphによるRAG・AIエージェント[実践]入門(技術評論社)

OpenAI API、RAG、評価、LangGraphでのエージェントまでを実装で繋ぐ。記事の「オーケストレーター/LLM/ツール分業」パートに直結。
LangChainによるAIエージェント開発講座(翔泳社)

LangChainでのエージェント設計〜応用までを講座形式で。
GPU/CUDA・実装基盤(計算資源の感覚をつかむ)
GPUプログラミング入門-CUDA5による実装(講談社)

CUDAでの並列計算の基本発想を掴む用途に向く(内容はCUDA5前提なので“概念の本”として扱うのが安全)。
PyTorchで作る!深層学習モデル・AIアプリ開発入門(翔泳社)

PyTorchでモデル構築〜アプリ実装までを通す。記事の「PyTorch/CUDAで回る」感覚の補助に使える。
(推論最適化そのものは、上で挙げた「機械学習エンジニアのためのTransformers」にONNX Runtime等の高速化がまとまっているので、あわせ読みが効く)
守り(法律・ガバナンス・倫理・個人情報)
生成AIの法律実務(弘文堂)

生成AIをめぐる実務論点を網羅的に扱うタイプ。
AIと法 実務大全(日本加除出版)

知財・個人情報・営業秘密・OSS・契約・社内導入まで、現場の論点を「大全」として厚く押さえる用途。
AIガバナンス入門(ハヤカワ新書)

リスクマネジメント〜社会設計の見取り図を先に作りたいときに合う。
AIの倫理リスクをどうとらえるか:実装のための考え方(白揚社、邦訳)

倫理を“実装”に落とすためのフレームワーク寄り。記事の「法律に触れなくても炎上する」領域の補強に効く。
個人情報保護法(商事法務)

個情法を条文+運用+実務で厚く参照する辞書枠(生成AIの入力・学習・ログ設計で迷うときの背骨)。
最小セット
- ゼロから作るDeep Learning(NN〜CNNまで)
- 機械学習エンジニアのためのTransformers(Transformer〜推論最適化)
- AIと法 実務大全(守りのフローを実務で固める)

コメント