
自己注目と多視点処理
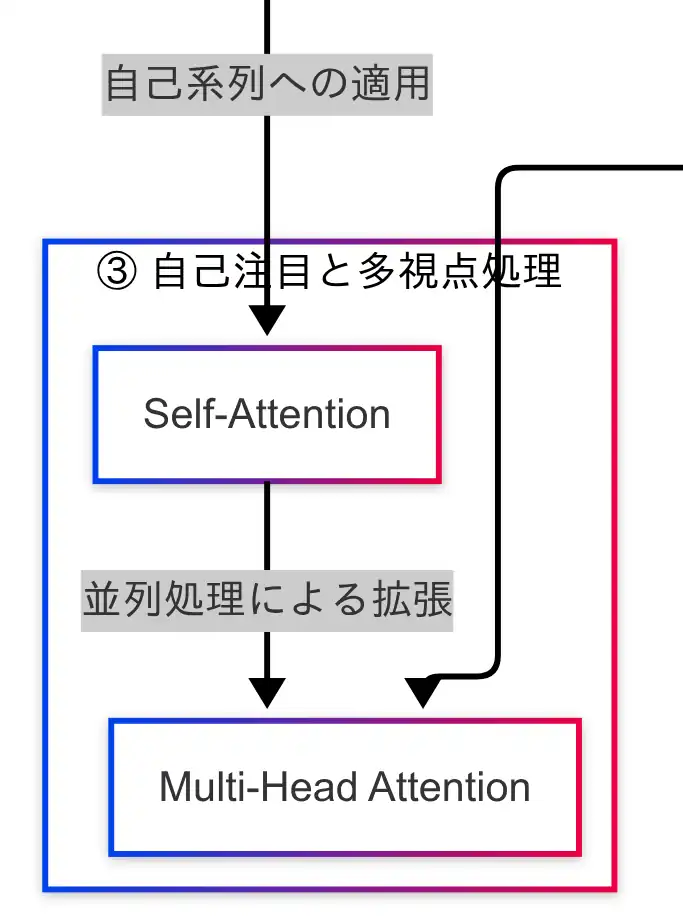
Transformerにおける文脈理解の中核を担うのが、Self-Attention(自己注目)である。これは、入力系列内の各単語が他のすべての単語に対して「どれだけ重要か」をスコア化し、文全体の意味を把握するための仕組みである。
たとえば、「彼は銀行で働いている」という文において、「銀行」と「働く」が意味的に関連していると判断されるように、Self-Attentionは文中の語同士の関係性を数値的に評価する。これにより、文脈の全体像を捉えることが可能となる。
Self-Attentionの計算は、すべての単語に対して全単語との関係を評価するため、計算量が多くなる。入力系列の長さに対して計算量は二乗で増加するが、それでも採用されるのは、得られる文脈情報が非常に価値あるものであるためである。
このSelf-Attentionをさらに拡張したのが、Multi-Head Attention(多視点処理)である。Multi-Head Attentionでは、Self-Attentionを複数の「ヘッド」で並列に計算し、それぞれ異なる視点から文脈を抽出する。たとえば、あるヘッドでは「主語と動詞の関係」に注目し、別のヘッドでは「形容詞と名詞の関係」に注目する、といった具合である。
この多視点処理により、Transformerは文の意味を多面的に捉えることが可能となる。モデルによってヘッド数は異なり、BERTでは12ヘッド、GPT-3では96ヘッドなど、規模に応じて視点の数も増加する。
因果関係図においては、Self-AttentionからMulti-Head Attentionへの矢印が示されており、Transformerが自己系列に対して多次元的な注目を行っている構造が明示されている。また、Transformer本体からもMulti-Head Attentionに矢印が伸びており、この機構がTransformerの「理解力」を支える重要な要素であることが視覚的に理解できる。
次章では、これらのAttention機構がどのように計算されているか、Query・Key・Valueというベクトル構造を用いた計算手順について解説する。
Attentionの計算構造
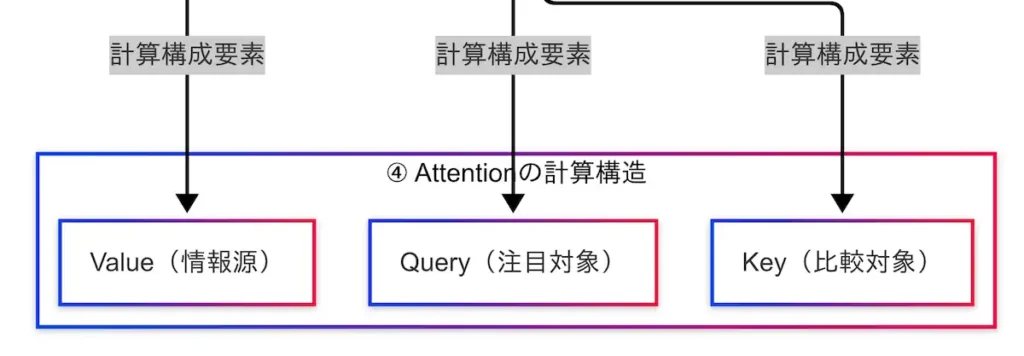
TransformerにおけるAttentionは、単なる「注目」ではなく、数式に基づいた厳密な計算によって実現されている。その中核を成すのが、Query(注目対象)、Key(比較対象)、Value(情報源)という3つのベクトルである。
この構造は、データベース検索に例えると理解しやすい。Queryは検索語、Keyはインデックス、Valueは検索結果に相当する。Transformerでは、QueryとKeyの類似度を計算し、そのスコアに基づいてValueを重み付きで合成することで、文脈に応じた情報抽出を行っている。
たとえば、「彼は銀行で働いている」という文において、「働いている」という単語をQueryとした場合、「銀行」という単語のKeyとの類似度が高ければ、そのValue(文脈情報)が強く反映される。このようにして、Attentionは「どこに注目すべきか」を数値的に判断している。
類似度の計算には、通常、QueryとKeyの内積(ドット積)が用いられる。得られたスコアはSoftmax関数によって正規化され、すべての単語に対する注目度の合計が1になるように調整される。これにより、Attentionは確率的な重み付けを実現している。
Attentionの計算式は以下の通りである:
$$
\text{Attention}(Q,K,V)=\text{softmax}\bigg(\frac{QK^\top}{\sqrt{d_k}}\bigg)
$$
ここで、$\sqrt{d_k}$はスケーリング係数であり、内積の値が大きくなりすぎるのを防ぐために導入されている。これにより、Softmaxの出力が極端な値にならず、学習が安定する。
この計算は、Transformer内部で全単語に対して同時に行われる。さらに、前章で述べたように、これを複数の視点(ヘッド)で並列に処理するのがMulti-Head Attentionである。つまり、Attentionの計算構造は、Transformerの「知性の核」とも言える存在である。
因果関係図においては、AttentionからQuery・Key・Valueへの矢印が明示されており、これら3要素が計算構造の中心であることが視覚的に理解できる。また、Transformer本体からMulti-Head Attentionへの接続も示されており、これらの計算がモデル全体の性能に直結していることがわかる。
次章では、Transformerの性能と安定性を支える「補助構成要素」について解説する。


コメント