
「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
バックナンバーはこちら

はじめに
近年、音声認識や音声合成をはじめとする音声処理技術は、スマートフォンやスマートスピーカー、カーナビゲーションなど、日常生活のあらゆる場面で活用されている。これらの技術は、単に音を録音・再生するだけでなく、音声を数値化し、意味を抽出し、さらには感情や話者の識別まで行う高度な処理を含んでいる。
音声処理の根幹にあるのは、「音を意味に変換する」技術体系である。しかし、AD変換、PCM、FFT、MFCC、音素、音韻、HMM、WaveNetなど、登場する用語は多岐にわたり、それぞれがどのように関係し、どのような役割を果たしているのかを理解することは容易ではない。
本記事では、G検定のシラバスに沿って、音声処理技術を因果関係の観点から整理する。単なる用語の暗記ではなく、技術のつながりと背景にある処理の流れを理解することを目的とする。
音声処理は、「音 → 数値 → 特徴 → 意味 → 応用」という一連の流れで構成されており、それぞれのステップが密接に連携している。音声を機械が理解し、応用可能な情報として活用するまでの過程を体系的に把握することで、G検定対策としても、AI技術の理解としても大きな助けとなるであろう。
動画シリーズ
G検定の究極カンペ関連動画の再生リスト

説明内容
音声処理とは、単に音を録音・再生する技術ではなく、音声を数値化し、意味を抽出し、応用するまでの一連の技術体系である。実際には、非常に多くの技術が関与しており、それらは互いに因果関係を持って連携している。
本記事では、音声処理の技術群を以下の5つのカテゴリに分類し、それぞれの関係性を因果関係図に基づいて整理する。
- 音声信号のデジタル化・符号化
- 音響特徴量の抽出
- 音声の言語的・音韻的特徴
- 音声処理モデル
- 音声処理タスクの種類と応用
これらは、マイクで拾った音が「意味のある情報」として処理され、最終的に「使える技術」として応用されるまでの流れを構成している。たとえば、「こんにちは」という音声が、文字に変換されたり、話者の感情を分析されたり、別の声で再生されたりするまでには、複数の技術が段階的に関与している。
音声処理に登場する用語は、AD変換、MFCC、音素、WaveNetなど、初学者にとっては馴染みのないものが多い。しかし、これらを個別に暗記するのではなく、「どの順番で、何のために使われているか」を理解することが、G検定対策としては極めて有効である。
また、音声処理は自然言語処理や画像認識といった他分野とも連携することがあり、AI技術全体の理解を深める上でも重要な橋渡しとなる分野である。
以下に示す因果関係図は、音声処理技術の流れとつながりを視覚的に整理したものである。本記事では、この図をもとに、各技術の役割と関係性を順に解説していく。
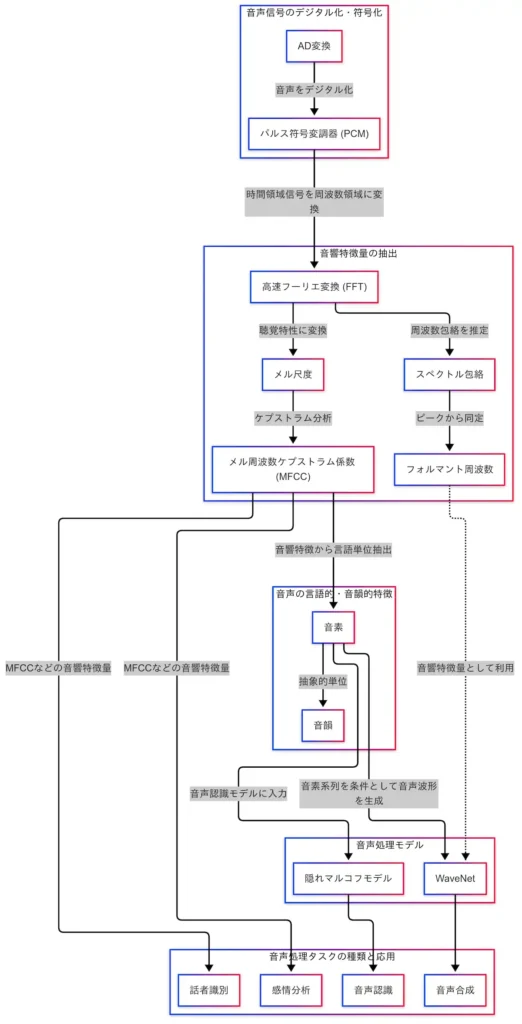
音声信号のデジタル化・符号化
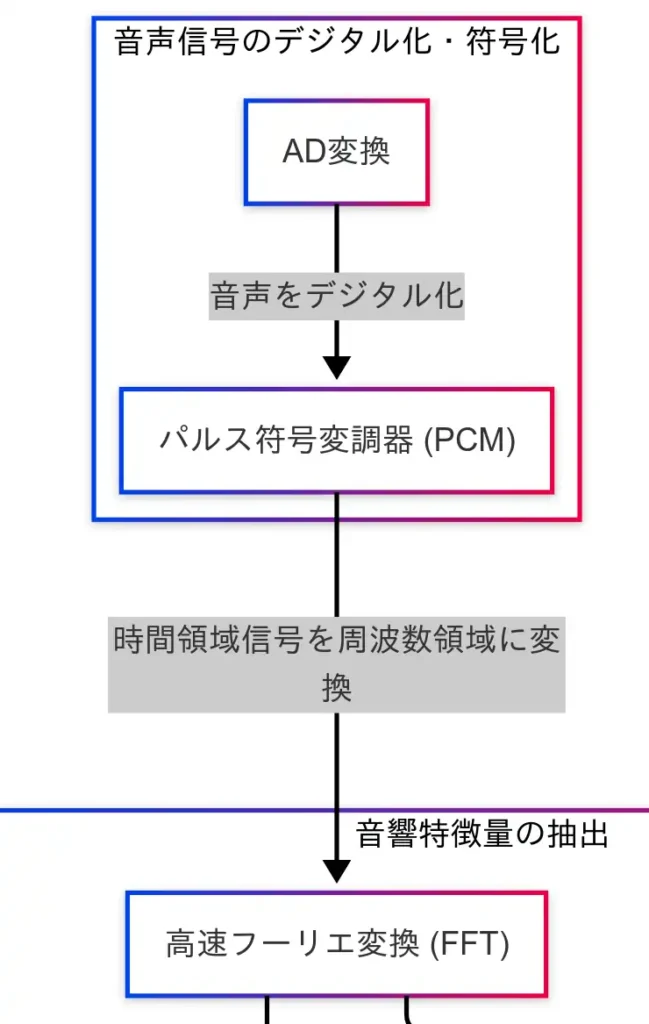
音声処理の出発点は、アナログ音声をデジタル信号へと変換する工程である。音声は空気の振動、すなわちアナログ信号であるため、そのままではコンピュータによる処理が不可能である。そこで必要となるのが AD変換(アナログ・デジタル変換) である。
AD変換では、音声波形を一定間隔でサンプリングし、それぞれの振幅を数値化する。これにより、音声は「数値の列」として表現されるようになる。サンプリング周波数や量子化ビット数は音質に直結し、たとえばCD音質では 44.1kHz・16bit が標準的な設定である。
しかし、AD変換によって得られたデータは、まだ「生の波形」であり、直接的な音声処理には適していない。そこで登場するのが PCM(パルス符号変調) である。PCMは、AD変換された信号を時間領域のデジタル信号として符号化する方式であり、WAVファイルなどにも用いられている。
因果関係図においては、「AD変換 → PCM」という流れが明示されており、この段階が音声処理のすべての基礎となる。PCM形式で保存された音声データは、次の工程である「音響特徴量の抽出」へと接続される。具体的には、PCMから FFT(高速フーリエ変換) を経て、周波数領域での分析が可能となる。
このように、AD変換とPCMは、音声処理の起点として極めて重要な役割を果たしている。音声を「機械が理解できる形」に変換することで、以降の処理が可能となるのである。
音響特徴量の抽出
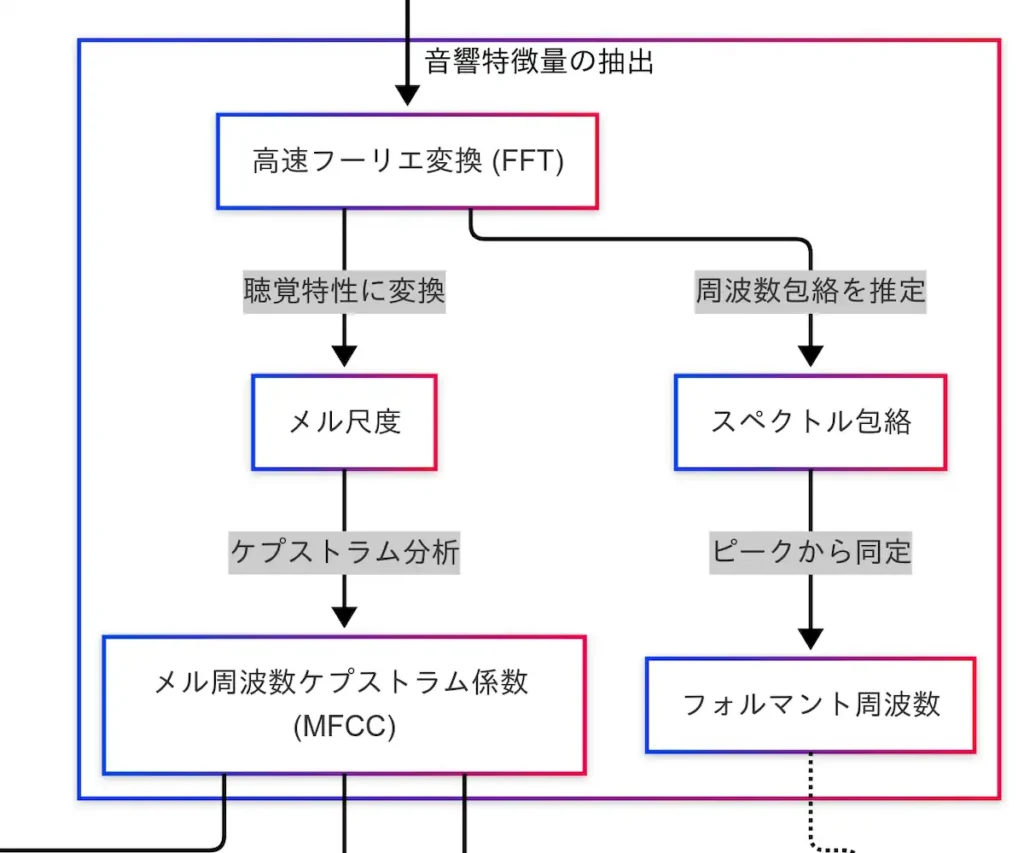
音声信号をデジタル化しただけでは、まだ「音の中身」を理解することはできない。PCM形式で保存された時間領域の波形データから、音声の特徴を抽出する工程が必要となる。この工程が、音響特徴量の抽出である。
まず、PCM信号は FFT(高速フーリエ変換) によって周波数領域に変換される。FFTは、音声信号に含まれる周波数成分を明らかにする手法であり、音の構成要素(低音・高音など)を分析するための基本技術である。
FFTによって得られたスペクトルからは、2つの重要な特徴が導かれる。
1つ目は スペクトル包絡 である。これは、周波数成分の全体的な形状を滑らかに捉えるものであり、音声の共鳴特性、すなわち「声の響き方」を抽出するのに用いられる。スペクトル包絡からは、さらに フォルマント が導かれる。フォルマントは、母音などの識別に重要な共鳴周波数であり、話者の個性や言語的な違いを捉えるために活用される。
2つ目は メル尺度 である。これは、人間の聴覚特性に基づいて周波数を変換するスケールであり、特に低音域の変化に敏感な人間の耳に合わせて設計されている。メル尺度を用いることで、機械による音声認識が人間の感覚に近づく。
このメル尺度に基づいて導出されるのが、MFCC(メル周波数ケプストラム係数) である。MFCCは、音声認識において最も広く用いられる音響特徴量であり、メル尺度で変換されたスペクトルをケプストラム分析することで、音の特徴をコンパクトかつ効果的に数値化する。
因果関係図においては、「PCM → FFT → メル尺度 → MFCC → 音素」という流れが明示されており、MFCCが音素抽出の前段階として機能していることがわかる。また、MFCCは音声認識だけでなく、話者識別 や 感情分析 にも応用されており、「MFCC → 話者識別」「MFCC → 感情分析」という矢印がそれを示している。
MFCCは、音声を「意味のある単位」に変換するための橋渡しであり、音声処理の中核をなす技術である。音声は単なる波ではなく、構造と意味を持つ情報である。その構造を捉えるために、FFTやMFCCといった技術が不可欠である。
音声の言語的・音韻的特徴
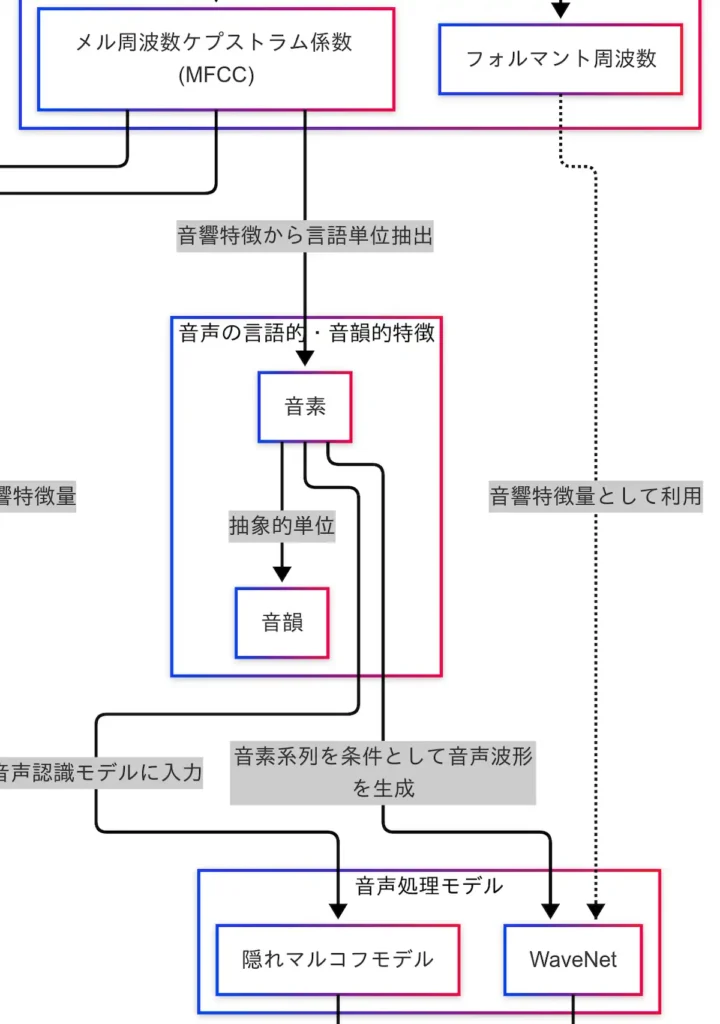
音響特徴量の抽出によって得られたMFCCは、音声信号の数値的な特徴を表すものである。しかし、これだけでは音声の「意味」には到達しない。MFCCをもとに、音声を言語的な単位へと変換する工程が必要となる。この工程が、音声の言語的・音韻的特徴の抽出である。
まず、MFCCから導かれるのが 音素 である。音素とは、言語を構成する最小の音の単位であり、「か」「さ」「た」などのように、それ自体には意味を持たないが、言葉を形成するための基本的なパーツである。音素は、音声認識モデルにとって極めて重要な入力単位であり、因果関係図においても「MFCC → 音素 → HMM」という流れが明示されている。
音素の次に位置づけられるのが 音韻 である。音韻は、音素よりも抽象的な概念であり、意味の違いを生む音のカテゴリを定義する。たとえば「ば」と「ぱ」は、発音上は似ているが、濁音かどうかによって意味が異なる。このような違いを捉えるのが音韻である。
音韻は、音声認識モデルに直接入力されるわけではないが、言語処理の理論的背景として重要な役割を果たす。モデル設計や言語理解の精度向上に寄与するため、音素とともに体系的に理解しておくべき概念である。
因果関係図では、「MFCC → 音素 → 音韻」という流れが示されており、音声が「数値 → 単位 → 意味」へと段階的に変換されていく様子が視覚的に理解できる。音素と音韻は、音声を「言語」として扱うための橋渡しであり、次に登場する音声処理モデル(HMMやWaveNet)にとっても、中心的な役割を担っている。
音声処理モデル
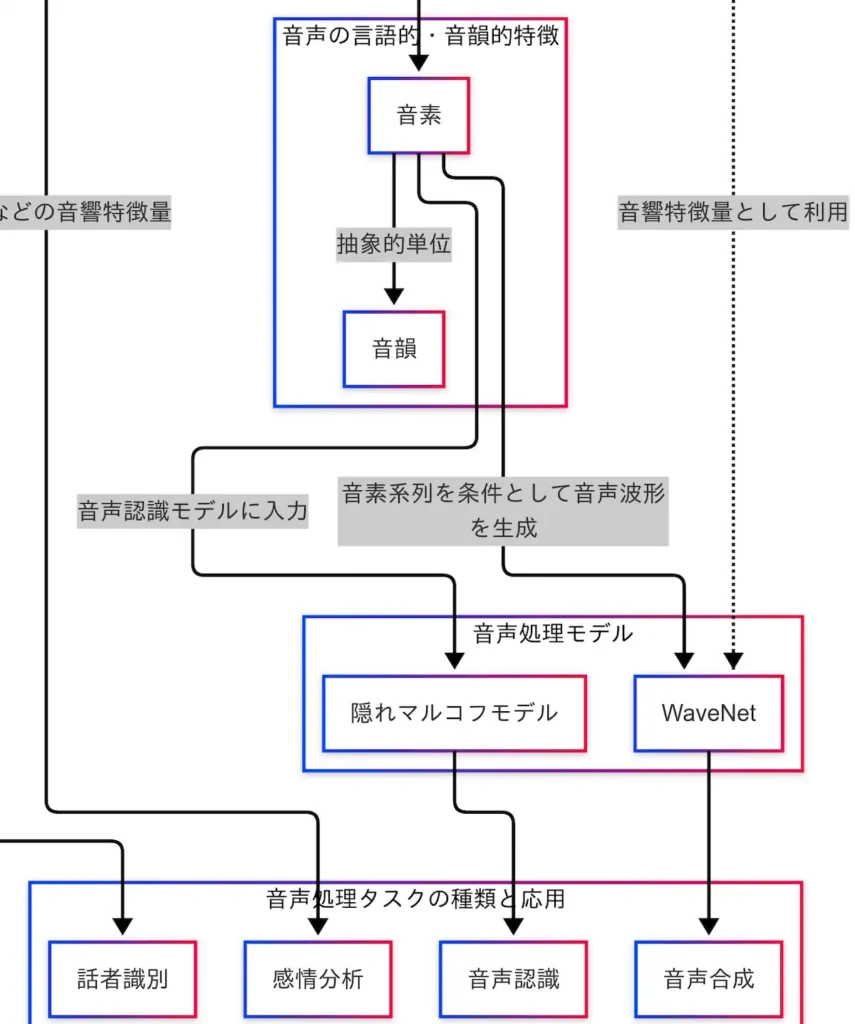
音声処理において、音素は言語的な最小単位であり、音声を意味のある情報へと変換するための中心的な役割を担っている。この音素を入力として、音声を認識したり、逆に音声を生成したりするモデルが存在する。それが音声処理モデルである。
因果関係図では、「音素 → HMM → 音声認識」「音素 → WaveNet → 音声合成」という2つの主要な流れが示されている。
まず、HMM(隠れマルコフモデル) は、古典的な音声認識モデルとして広く知られている。HMMは、音素の系列を時間的にモデル化し、どの音素がどのタイミングで現れるかを確率的に予測する。ここで「隠れ」とは、観測できない内部状態――話し手の意図や文脈など――を仮定し、それを推定するという意味である。音声の表面だけでなく、背後にある意味を推測する構造が、HMMの特徴である。
一方、近年の音声合成技術では、WaveNet が注目されている。WaveNetは、音素の系列を条件として、自然な音声波形を生成する深層学習モデルである。従来の音声合成手法と比較して、より滑らかで人間らしい音声を出力できる点が特徴である。
因果関係図では、「フォルマント周波数 → WaveNet」という破線も示されており、WaveNetが音素だけでなく、フォルマントなどの音響特徴量も活用していることがわかる。これは、音声認識とは逆方向の処理、すなわち「意味 → 音」への変換を実現する技術である。
このように、HMMは「音 → 意味」、WaveNetは「意味 → 音」という方向性を持ち、いずれも音素を中心に構築されている。音素は、音声処理モデルにおけるハブとして機能しており、音声認識・音声合成の両方において不可欠な存在である。
音声処理タスクの種類と応用
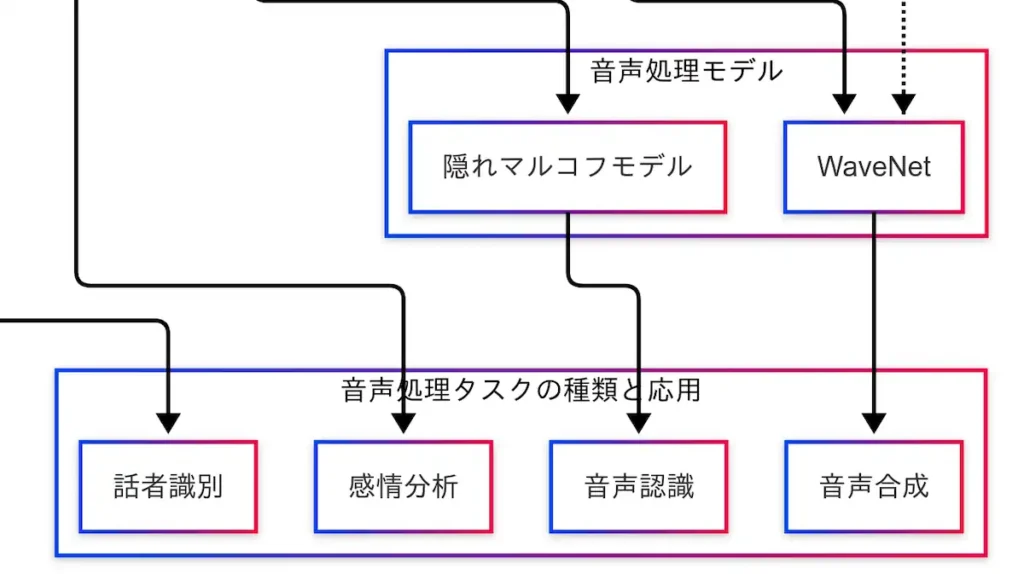
音声処理技術は、単なる信号処理にとどまらず、実世界で多様な応用を持つ。音声を数値化し、特徴を抽出し、モデルで処理することで、さまざまなタスクに展開される。因果関係図では、「HMM → 音声認識」「WaveNet → 音声合成」「MFCC → 話者識別」「MFCC → 感情分析」という4つの代表的な応用が示されている。
音声認識
音声認識とは、話された言葉をテキストに変換する技術である。スマートフォンの音声入力や音声アシスタント(例:Siri)などに広く利用されている。因果関係図では、「音素 → HMM → 音声認識」という流れが示されており、HMMが音素の系列を確率的にモデル化し、発話された単語を推定する役割を担っている。近年では深層学習ベースのモデルが主流となっているが、G検定ではHMMの理解も依然として重要である。
音声合成
音声合成は、テキストから自然な音声を生成する技術である。ナビゲーション音声や読み上げソフトなどに活用されている。因果関係図では、「音素 → WaveNet → 音声合成」という流れが示されており、WaveNetが音素の系列を条件として、滑らかで人間らしい音声波形を生成する。さらに、「フォルマント周波数 → WaveNet」という破線も示されており、音響特徴量を活用することで、よりリアルな音声生成が可能となっている。
話者識別
話者識別は、「誰が話しているか」を判定する技術である。電話音声による本人確認や声紋認証などに利用されている。因果関係図では、「MFCC → 話者識別」という流れが示されており、MFCCが話者ごとの声の特徴を数値化することで、識別が可能となる。
感情分析
感情分析は、音声から話者の感情を推定する技術である。コールセンターなどで顧客の感情を把握する目的で活用されている。因果関係図では、「MFCC → 感情分析」という流れが示されており、MFCCが声の抑揚やテンポなどを反映することで、感情の違いを捉えることができる。
音声処理は、「認識」「合成」「識別」「分析」といった多様な方向に応用されており、それぞれのタスクに適したモデルや特徴量が用いられている。因果関係図を通じて、技術のつながりと応用の広がりを体系的に理解することが、G検定対策としても有効である。
まとめ
本記事では、音声処理技術の全体像を因果関係図に基づいて体系的に整理した。音声処理は、単なる録音技術ではなく、「音 → 数値 → 特徴 → 意味 → 応用」という一連の流れによって構成されている。
出発点は AD変換 → PCM による音声のデジタル化である。ここで、アナログ音声がコンピュータで扱える数値信号へと変換される。
次に、FFT → メル尺度 → MFCC によって音響特徴量が抽出される。これにより、音声の中に含まれる周波数成分や聴覚的特徴が数値化され、機械学習モデルが扱える形となる。
その後、MFCC → 音素 → 音韻 という流れを通じて、音声は言語的な意味に近づいていく。音素は音声認識や音声合成の中心的な単位であり、音韻は言語理解の抽象的な基盤を形成する。
音素を入力として、HMM → 音声認識、WaveNet → 音声合成 という2つの代表的なモデルが展開される。HMMは古典的な認識モデルとして、WaveNetは深層学習による高品質な音声生成モデルとして、それぞれ異なる方向性を持つ。
さらに、MFCCは 話者識別 や 感情分析 にも応用されており、音声処理の応用範囲が非常に広いことが因果関係図からも明らかである。
G検定では、こうした技術の「つながり」を理解しているかが問われる。単語の意味を暗記するだけではなく、「何のために使われているか」「どこにつながっているか」を意識することが、より深い理解につながる。
音声処理は、自然言語処理や画像認識とも連携する分野であり、AI技術全体の理解を深める上でも重要な位置づけにある。因果関係図を活用することで、複雑な技術体系を視覚的かつ論理的に把握することが可能となる。
- 音声処理は「AD変換 → PCM → FFT → MFCC → 音素 → モデル → 応用」という因果関係で構成されている。
- 音素を中心に、HMMによる音声認識、WaveNetによる音声合成が展開される。
- MFCCは話者識別や感情分析にも応用され、音声処理の幅広い可能性を支えている。
知識確認問題(過去問ふぅ対策道場)
10問中3問をランダムに出題。選択肢の並びもランダム。

対策道場本体はこちら

「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
バックナンバーはこちら
深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト 第3版

徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版 徹底攻略シリーズ

ディープラーニングG検定(ジェネラリスト) 法律・倫理テキスト



コメント