
方策勾配アルゴリズム
価値ベースアルゴリズムが「どの行動が得か」を推定する手法であるのに対し、方策勾配アルゴリズムは「どう行動するか」を直接学習する手法である。因果関係図においては、REINFORCEを起点として、TRPO、PPOへと進化する流れが描かれている。
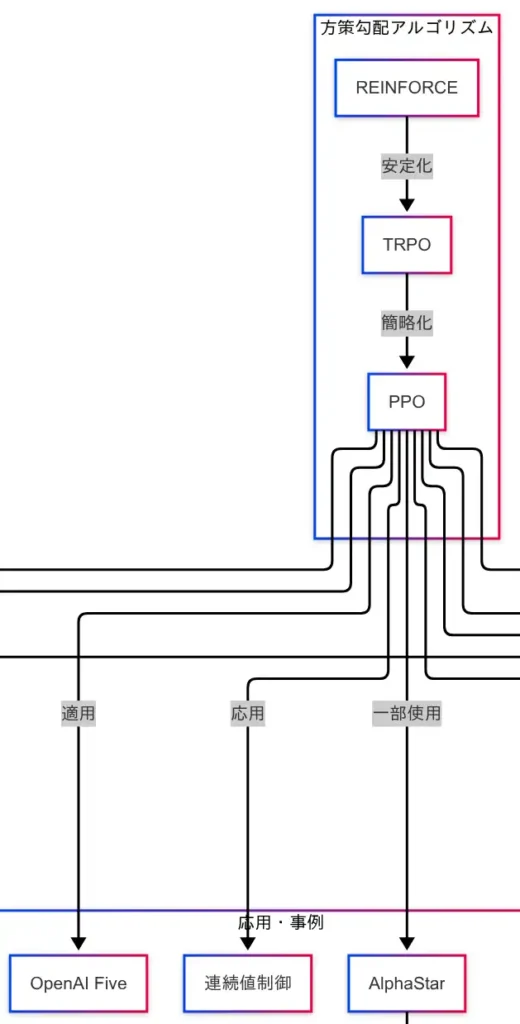
まず、REINFORCEは方策勾配法の基本形であり、確率的な方策に基づいて行動を選択し、その方策を報酬に応じて更新する。価値の推定を介さず、方策そのものを最適化する点が特徴である。
次に、TRPO(Trust Region Policy Optimization)は、REINFORCEの課題である学習の不安定性を克服するために導入された。方策の更新を「信頼できる範囲(Trust Region)」に制限することで、性能の急落を防ぎ、安定した学習を実現する。ただし、TRPOは計算コストが高く、実装が複雑である。
この課題を解決するために登場したのが、PPO(Proximal Policy Optimization)である。PPOはTRPOの安定性を維持しつつ、より簡便な手法で方策の更新を行う。現在では、強化学習の実装において最も広く使われているアルゴリズムの一つである。
因果関係図では、PPOが複数の応用事例に接続されていることが確認できる。
- OpenAI Five:Dota2という複雑なゲーム環境において、PPOを用いてプロチームに勝利したAIである。
- AlphaStar:StarCraft IIにおけるAIであり、マルチエージェント環境での学習にPPOが活用されている。
- 連続値制御:ロボットの関節動作や自動運転のハンドル操作など、滑らかな制御が求められる場面において、PPOは高い適応力を示している。
このように、方策勾配アルゴリズムは、現実世界への応用に強みを持つ技術群である。因果関係図を参照することで、REINFORCEからPPOへの技術的進化と、それに伴う応用展開が明確に理解できる。G検定対策においても、方策勾配の流れを押さえておくことは重要である。
分散・統合型アルゴリズム
強化学習の実用化に向けて、学習効率とスケーラビリティを高めるために登場したのが「分散・統合型アルゴリズム」である。因果関係図では、A3CからAPE-Xへの技術的進化が一本の流れとして描かれている。
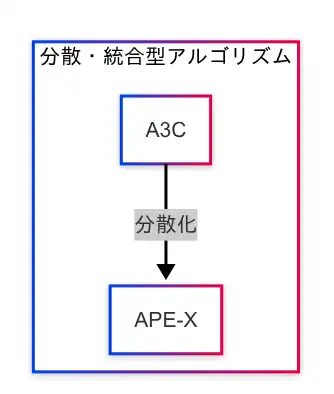
まず、A3C(Asynchronous Advantage Actor-Critic)は、複数のエージェントが非同期に並列学習を行うことで、探索の多様性と学習の安定性を両立させる手法である。各エージェントが独立して環境と相互作用し、得られた経験を共有することで、効率的な学習が可能となる。
この分散学習の考え方をさらに発展させたのが、APE-Xである。APE-Xは、経験の蓄積(リプレイバッファ)と分散処理(複数のワーカー)を組み合わせることで、大規模なデータを高速に処理し、スケーラブルな強化学習を実現する。クラウド環境やGPUを活用することで、従来の手法では困難だった大規模環境への対応が可能となる。
因果関係図における「A3C → APE-X」という接続は、分散化による性能向上の流れを示しており、強化学習の実用化に向けた重要なステップであることがわかる。
このような分散・統合型のアプローチは、単一エージェントによる学習では限界のある複雑な環境において、探索の効率化と学習の高速化を同時に達成するための鍵となる。特に、現代の強化学習では、複数のエージェントが協調して学習するマルチエージェント環境や、大量のシミュレーションを必要とするロボット制御などにおいて、分散処理の重要性が高まっている。
因果関係図を参照することで、A3CからAPE-Xへの技術的進化が明確に理解でき、分散・統合型アルゴリズムが強化学習のスケーラビリティを支える基盤技術であることが把握できる。
補助・拡張技術
強化学習の性能を引き上げるためには、アルゴリズムそのものだけでなく、それを支える補助・拡張技術の理解が不可欠である。因果関係図では、「報酬成形」「残差強化学習」「状態表現学習」「RLHF」が並列に配置されており、複数のアルゴリズムに対して適用可能な技術として示されている。
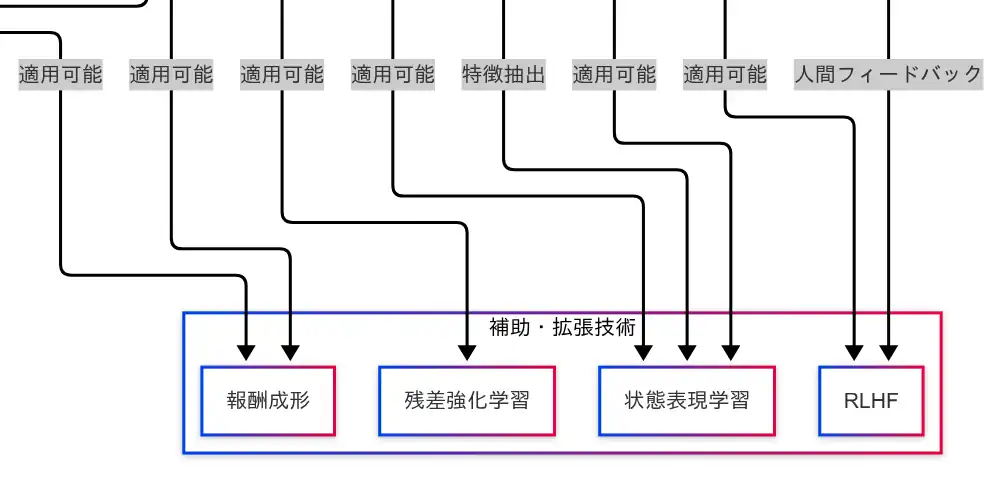
報酬成形(Reward Shaping)
報酬成形は、エージェントが学習しやすくなるように報酬の設計を工夫する技術である。たとえば、ゴールに到達したときだけ報酬を与えるのではなく、途中の行動にも段階的な報酬を与えることで、学習の安定性と効率を高めることができる。因果関係図では、DQNおよびPPOの両方に適用可能な技術として接続されており、アルゴリズムを問わず活用できる汎用性の高い補助技術である。
残差強化学習(Residual Reinforcement Learning)
残差強化学習は、既存の方策に対して差分(残差)を加えることで性能を改善する手法である。これは、すでにある程度機能する方策に対して微調整を加えることで、より高性能な方策を得ることを目的としている。因果関係図では、PPOに対して適用可能な技術として接続されている。
状態表現学習(State Representation Learning)
状態表現学習は、環境から得られる状態をそのまま使用するのではなく、特徴抽出を行い、学習に適した形式へと変換する技術である。画像データにはCNN、時系列データにはRNNやTransformerなどが用いられる。因果関係図では、DQNおよびPPOの両方に接続されており、広範なアルゴリズムにおいて活用されている。
RLHF(Reinforcement Learning with Human Feedback)
RLHFは、人間のフィードバックを活用してエージェントの方策を改善する手法である。人間が「この行動は良かった」と評価することで、エージェントはより望ましい行動を学習する。因果関係図では、エージェントから直接RLHFへと接続されており、さらにPPOとの相性が良いことも示されている。ChatGPTなどの大規模言語モデルの学習にも応用されている技術である。
これらの補助・拡張技術は、強化学習の基盤技術に対して横断的に適用可能であり、性能向上や学習安定化に寄与する。因果関係図を参照することで、各技術がどのアルゴリズムに接続されているかを視覚的に把握でき、応用の幅を理解するうえで有効である。


コメント