 G検定
G検定 G検定が「難化した」と感じる本当の理由:受験者増×情報過多で起きる“暗記ゴール化”を公式(例題・過去問・シラバス)で較正する勉強法
G検定の「難化体感」は実難化だけでなく、情報過多が“用語暗記=ゴール”に見せる暗記ゴール化で増幅します。公式で較正し、3行復習(用途・つながり・境界)で点学習を判断・説明へ戻す最短手順を解説。生成AIパスポートとの差も整理。
G検定  生成AI
生成AI 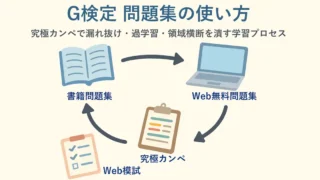 G検定
G検定  生成AI
生成AI  G検定
G検定  生成AI
生成AI 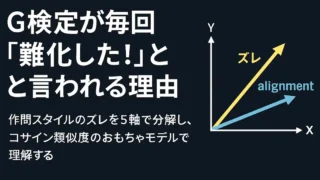 G検定
G検定 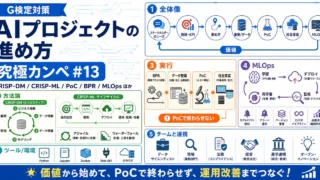 G検定
G検定 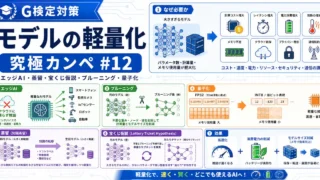 G検定
G検定 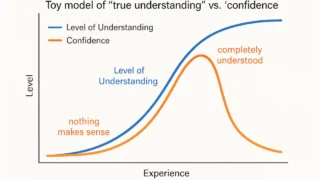 数値計算
数値計算