
https://www.simulationroom999.com/blog/jdla-deep-learning-for-general-2020-1/

はじめに
前回までは、AIの歴史やディープラーニングのブレイクスルー前の話が主だった。
今回からディープラーニングの話に突入。
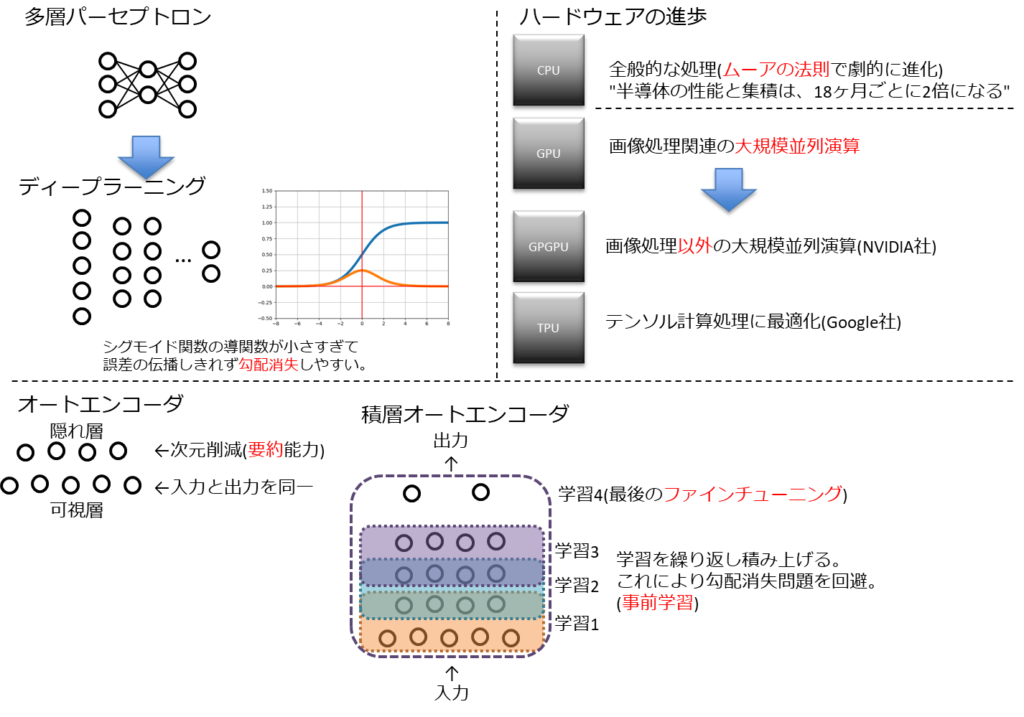
多層パーセプトロン
ディープラーニングの基本構造の由来はニューラルネットワーク。
ニューラルネットワーク自体は隠れ層を持つことで非線形分類ができるようになったもの。
単純パーセプトロンと比べると複雑なことができるとはいえるが、入力と出力の関係性を対応付ける関数という領域は出てはいない。
ディープラーニング
ニューラルネットワークの隠れ層をもっと増やせば、複雑な関数を実現できるはず。
という考えのもと生まれたがのがディープラーニングとなる。
ディープラーニングという単語は手法の名称で、実際のモデルはディープニューラルネットワークと呼ばれる。
ニューラルネットワークの課題
隠れ層を増やすというアイデア自体は過去からあった。
しかし、隠れ層を増やすと誤差逆伝播法による重み更新が正しく反省されなくなるという課題があった。
この課題の影響でモデルの精度が上げられずSVMなどの他の機械学習の方が流行っていたという背景がある。
隠れ層を増やすことで誤差逆伝播が利かなく理由としては以下。
- 活性化関数をシグモイド関数としていた。
- シグモイド関数の導関数は最大値が0.25と小さい 。
- 隠れ層を遡るごとに誤差が小さくなり、その内、誤差を認識できなくなる。(勾配消失)
ニューラルネットワークを深層にする上での大きな課題となった。
事前学習アプローチ
2006年にトロント大学のジェフリー・ヒントンが上記課題を解消する手法を提案。
その手法はオートエンコーダ(自己符号化器)と呼ばれるものであり、ディープラーニングの主要構成要素となった。
オートエンコーダ(auto encoder)
オートエンコーダ自体は可視層と隠れ層の2層からなるネットワーク
※ 可視層は入力層と出力層がセットになったもの
入力層と出力層が同一ということは、隠れ層は高次元のものを圧縮した結果となる。
この次元を圧縮するを感覚的に言うと「要約する」になる。
入力層→隠れ層をエンコード(encode)。
隠れ層→出力層をデコード(decode)と呼ぶ。
積層オートエンコーダ(stacked autoencoder)
オートエンコーダ自体はディープニューラルネットワークではない。
オートエンコーダを積みかなれることでディープオートエンコーダこと、積層オートエンコーダと呼ばれる手法がジェフリー・ヒントンが考えた手法となる。
学習の方法としては、入力層に近い層から順番に学習される逐次的手法になる。
隠れ層が順番に学習していくことになり、これを事前学習(pre-training)と呼ぶ。
ファインチューニング(fine-tuning)
事前学習ではラベル出力はできない。
最終的にはロジスティック回帰層が必要となる。
(シグモイド関数、ソフトマック関数による出力層)
この出力層も学習が必要で、この最後の仕上げをファインチューニングと呼ぶ。
つまり、積層オートエンコーダは事前学習とファインチューニングの2工程で完成する。
深層信念ネットワーク(deep belief network)
ジェフリー・ヒントンは積層オートエンコーダ以外に、制限付きボルツマンマシンという手法も提唱している。
事前学習なしアプローチ
事前学習は層ごとに学習していくため、計算コストが高くつくという課題を持っている。
これらの代案として全体を一気に学習できないかの研究もされている。
主に活性化関数を工夫するというテクニックに注目が集まっている。
ディープラーニングを実現するための技術
ディープラーニングのブレイクスルーはハードウェアの進歩も大きな要因となっている。
CPUもゴードン・ムーアの提唱した
半導体の性能と集積は、18ヶ月ごとに2倍になる
に合わせた進化をしてきた。
これが昔の計算コストの課題を解消してしまった背景もある。
CPUとGPU
コンピュータにはCPU(Central Processing Unit)とGPU(Graphics Processing Unit)の2つの演算装置が搭載されている。
CPUはコンピュータ全般の処理をし、GPUは画像処理の演算を担う。
画像処理はCPUでもできるが、大規模な並列演算が必要となるため、GPUの任せる方が効率的となる。
GPGPU
ディープラーニングではテンソル(行列、ベクトル)の計算が主となり、類似の計算処理が大規模に行われることになる。
この性質はGPUと相性が良い。
GPU自体は画像処理に最適化されたもののため、そのままではディープラーニングの計算には適さない。
そこでGPUを画像以外の計算にも使えるように改良されたものとしてGPGPU(General-Purpose computing on GPU)が登場した。
このGPGPUの開発をリードしているのがNVIDIA社で、ディープラーニング実装用ライブラリのほとんどがGPU上での計算をサポートしている。
また、テンソル計算処理に最適化された演算処理装置としてTPU(Tensor Processing Unit)をGoogle社が開発している。
必要なデータ量
ディープニューラルネットワークも学習用のデータが必要となるが、構造が複雑化しているため必要な学習データ量も大きく増えている。
必要なデータ量の目安として「バーニーおじさんのルール」というものがある。
モデルのパラメータ数の10倍のデータ数が必要
画像認識用ニューラルネットワークのAlexNetはモデルパラメータ数が6000万個であるため、6億個のデータ数が必要ということになる。
「バーニーおじさん」とは?
スタンフォード大学教授のバーナード・ウィドロー氏らしい。
https://en.wikipedia.org/wiki/Bernard_Widrow
1987年のIEEEカンファレンスでの講演「ADALINE and MADALINE」の中で「バーニーおじさんのルール(Uncle Bernie’s Rule)」を提唱した。
まとめ
- ニューラルネットワークを元にさらに隠れ層を増やしたディープニューラルネットワークが登場。
- しかし、隠れ層を増やしたことで勾配喪失や計算コストに課題が発生。
- 計算コストはCPUやGPUの発展に助けられた部分はある。


コメント