
https://www.simulationroom999.com/blog/jdla-deep-learning-for-general-2020-1/

はじめに
前回は、機械学習の各種手法について取り扱った。
実際に学習するに当たって、以下の手法や考え方がある。
- 学習データの扱い方
- 評価指標
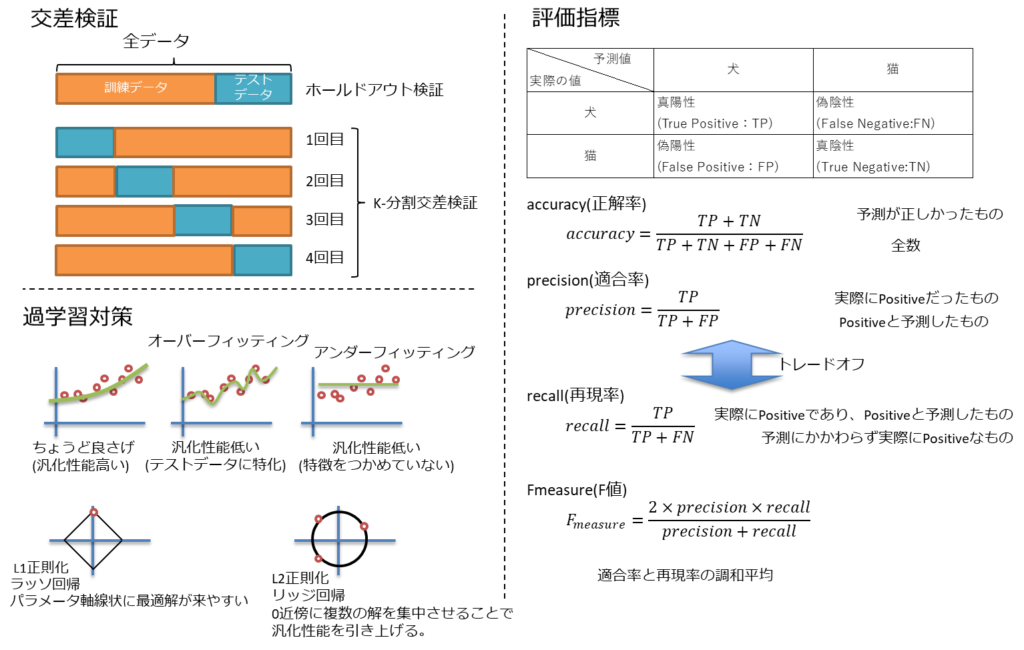
データの扱い方
機械学習にて手元のデータを学習することで、そのデータの分類、回帰ができるようになるが、重要なのは未知のデータに対しての予測能力である。
しかし、機械学習にとっての未知は、人間にとっても未知であるため、疑似的な未知データを作り出す必要がある。
代表的な手法として、手元にあるデータを学習用データと評価用データ分ける方法がある。
これを交差検証と呼ぶ。
学習用データを訓練データ、評価用データをテストデータと呼ぶ。
交差検証
交差検証は大きく2種類ある。
- ホールドアウト検証
- 単純分け
- k-分割交差検証
- 複数回分け方を変える
評価指標
基本的には正解率(Accuracy)が重要となる。
正解率を出すために事前に混同行列という考え方が必要となる。
例えば、犬と猫を分ける場合は以下の混同行列ができる。
| 実際の値\予測値 | 犬 | 猫 |
| 犬 | 真陽性 (True Positive:TP) | 偽陰性 (False Negative:FN) |
| 猫 | 偽陽性 (False Positive:FP) | 真陰性 (True Negative:TN) |
真陽性:True Positive(TP)
Positiveと予測し、実際にPositiveだったもの。
偽陽性:False Positive(FP)
Positiveと予測し、実際はNegativeだったもの。
偽陰性:False Negative(FN)
Negativeと予測し、実際はPositiveだったもの。
真陰性:True Negative(TN)
Negativeと予測し、実際にNegativeだったもの。
accuracy(正解率)
$$accuracy=\frac{TP+TN}{TP+TN+FP+FP}$$
分母は全数を示し、分子が予測が正しかったものを示す。
accuracyは、予測が正しかった割合をみるものとなる。
recall(再現率)
$$recall=\frac{TP}{TP+FN}$$
分子: True Positive (実際にPositiveであり、Positiveと予測したもの)
分母: True Positive + False Negative (予測にかかわらず実際にPositiveなもの)
Recallが高いということは、取りこぼしが少ない。
Recallが低いということは、取りこぼしが多い。
precision(適合率)とはトレードオフになる。
precision (精度 ・ 適合率)
$$precision=\frac{TP}{TP+FP}$$
分子: True Positive (実際にPositiveだったもの)
分母: True Positive + False Positive (Positiveと予測したもの)
Positiveと予測したもののうち、実際にPositiveだったものの割合。
正確性をみることができる。
Recall(再現率)とは、トレードオフになる。
F値(Fmeasure)
$$F_{measure}=\frac{2 \; precision \; recall}{precision+recall}$$
RecallとPrecisionの値を評価するために、F値を用いる。
分子:2 Recall Precision
分母:Recall+Precision
上記を全部使用するというよりも、目的に沿った指標を利用するという考え方が重要になる。
過学習(オーバーフィッティング)
学習を実施しすぎることで、過学習(オーバーフィッティング:overfiting)になることがある。
これを防ぐテクニックも存在しており、その一つが正則化がある。
学習する際の重みの範囲を制限し、重みの強い訓練データに学習結果が引きずられるのを防ぐ効果がある。
しかし、正則化しすぎると汎化性能(予測性能)が低下する問題も発生する。
これをアンダーフィッティング(underfitting)と呼ぶ
良くもちいられる正則化としてL1正則化とL2正則化がある。
- L1正則化
- 一部のパラメータを0にすることで特徴選択可能
- ラッソ回帰
- ElasticNet
- 一部のパラメータを0にすることで特徴選択可能
- L2正則化
- パラメータの大きさに応じて0に近づけることで汎化性能を引き上げる
- リッジ回帰
- ElasticNet
- パラメータの大きさに応じて0に近づけることで汎化性能を引き上げる
まとめ
- 学習する際に学習結果を評価する必要がある。
- 単に正解率が高いが優秀とは限らず、間違い検知率が高いことが重要な場合もある。


コメント