
「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
G検定カンペ一覧と各回の概要はこちら(バックナンバー)

究極カンペとは?「カンペに頼らない自分」を作る考え方
結構昔にG検定向けの動画で、
「JDLAジェネラリスト検定(G検定)さっくり対策(究極カンペの作り方)カンペを見なくても問題が解ける自分の作り方。」
というのを公開しているのだが、
これに対しての問い合わせがちょくちょく来ている。
と言っても、問い合わせも出来上がったものが欲しいというより、
作る上でのコツのようなものを聞いてきてる感じのものがほとんど。
(一応、みんな自分で作るつもりはあるっぽい)
尚、究極カンペは「アルティメットカンペ」と発音する。(と私が勝手に呼んでる)
サブタイトルにも記載しているのだが、
実際には、カンペに頼らない自分自身の作り方と捉えた方がよい。
結局はカンペすらも自分自身を鍛えるための材料となる。
よって、自分で作らないと意味がない。
さらに、他人が作ったカンペを使用してもあまり意味がないという理屈になっている。
通常、究極(アルティメット)カンペというのを実在するカンペに命名すると、いわゆる誇大広告になってしまう。(そんな万能感全開のカンペがあるなら皆苦労はしない・・・。)
しかし、ここでは「究極カンペ=カンペ不要な自分自身という状態」という逆説ネーミングとしているので特に誇大広告には該当しない・・・はず?
この記事でわかること(G検定 究極カンペ導入編)
- 「G検定は意味ない」と言われる理由と、その受け止め方
- G検定対策で目指すべき5つの勉強ステージ(語彙力→因果関係→応用力…)
- シラバスを使ったカテゴリ分けの考え方と、究極カンペへの落とし込み方
- 一般物体認識などを例にした、用語どうしの因果関係図のイメージ
- 専門家と効率よく会話するために、G検定レベルで押さえておきたい視点
動画シリーズ
G検定の究極カンペ関連動画の再生リスト

説明内容
今回の説明内容を記載しておく。
- SNS上のG検定の評判
- 勉強のステージ
- カテゴライズの仕方
- カテゴライズの詳細化
- 因果関係
- 専門家とのコミュニケーション例
- 今後の進め方
「SNS上のG検定の評判」だが、
そこを皮切りとして、勉強のステージのイメージを掴んでもらうことを狙っている。
その上で究極カンペの作り方の方針を知ってもらう。
(少々話が込み入る可能性はある・・・。)
このシリーズを見る前提として、G検定の公式テキストを一通り見ていた方が良い。
用語を覚えている必要はなく、
見覚え、聞き覚えがあると認識できる程度で問題無い。
SNS上の「G検定は意味ない」という評判をどう読むか
G検定の評判だけど、ポジティブなものもあれば、ネガティブなものもある。
ここではネガティブなものを中心に確認してみる。
なぜネガティブなものを確認するかというと・・・。
ネガティブな意見は、いわゆる問題提起とも言える。
ただ、その発信の前提条件とかが見えないから鵜呑みにはできないのだが、
そこは、予想される前提条件の仮説を立てることで補完する。
そうすると、結構重要且つ次のアクションにつなげやすい意見に変化する。
この手のネガティブな意見を扱う場合は注意点がある。
- ターゲットを事象にする
- 人ではなく事象に焦点を当てることで、個人攻撃を避け、客観的な分析が可能
- 事象を事実として受け止める
- 事象をまずは単なる事実として受け止め、その事象が起こること自体を普通のこととすることで、偏見や感情的な反応を排除する
- 事象を分解する
- 事象を細かく分解し、各要素を分析することで、問題の真因を特定しやすくする
- 真因を特定する
- 分解した要素をもとに、問題の根本原因を特定し、適切な解決策を見つける
ここらへんを意識しないと水掛け論になって永遠に意見が平行線になる。
主だった意見は、ざっくりまとめると以下が多い印象。
- G検定はひたすら暗記。AIの歴史とかフレーム問題とか、細かい知識を詰め込むだけ
- G検定は実務で使えない。資格取ってもAI開発には関係ない
他にもあるとは思うが、この2点について考えてみる。
両方とも正しいことは言っている気はする。
難しいことを暗記しないといけないし、だからと言って、それがAI開発に使えるわけでもなさそう。
ということはG検定は意味がない!
と、これが答えになると話が全く進まなくなる・・・。
この話は、次の章で説明する、勉強のステージと関連させるともう少し実態が見えてくると思う。
G検定対策の5つの勉強ステージ【語彙力→因果関係→応用力】
まず、勉強のステージというものを書き出す。
私が勝手に定義したものではあるが、一定の納得感はあるとは思う。
- ステージ1:語彙力を付ける
- 専門家とコミュニケーションがそこそこ可能なレベル
- ステージ2:用語の因果関係を把握している
- 専門家とのコミュニケーションにおいて、箇所、範囲を元に効率的なコミュニケーションが可能なレベル
語彙力は用語を知るってこと。
用語を知ったうえで、関係性を把握ってのは普通なことだと思う。
ここで、先ほどの章であった、
「G検定はひたすら暗記。AIの歴史とかフレーム問題とか、細かい知識を詰め込むだけ」
という話を思い出してみる。
ステージ1はひたすら暗記。
ステージ2も暗記な気がするど、ちょっと詰め込むってのとは違う気もする。
この批判は、ステージ1のみでG検定対策をした場合に発生するものということになる。
と言っても、ステージ1のみでG検定対策をすることは普通の話で、
この批判が間違っているという意味では無い。
実際、G検定対策の期間って長い人でも1か月程度。
この期間だと、暗記に頼ったステージ1の範囲の対策になってしまうのは自然なこと。
といわけで、意図的にステージ2を目指した勉強の仕方をすると、暗記による詰め込み感が薄れる。
ちなみに、ステージ2より後ろもある。
G検定の範疇から外れるが、一応簡単に定義している。
- ステージ3:応用力を付ける。
- 学んだ用語や因果関係を実際の問題に応用できるレベル。
- 専門家と高度な議論ができるようになる。
- ステージ4:分析力を付ける
- 複雑なデータや情報を分析し、洞察を得る能力
- 専門家と共に問題解決に向けた戦略を立てることができる。
- ステージ5:創造力を付ける
- 新しいアイデアや解決策を提案し、実行に移す能力を持つ。
- 専門家と共に革新的なプロジェクトを推進する。
G検定の範疇は超えてそうなのは感じとれると思う。
ここでもう一つの批判の、
「G検定は実務で使えない。資格取ってもAI開発には関係ない」
を思い出してみる。
これも、特に間違ったことは言ってないと思っている。
ただ、この批判は、ステージ3以降を想定した批判。
つまり、そもそもG検定の対象範囲外を期待した批判ってことになる。
G検定はAIの開発者というよりも専門家と適切なコミュニケーションが取れる水準で考えるべき検定と言える。
というわけで、ステージ3以降はG検定とは別の話として議論すべき。
それぞれの批判は間違っていないけど、
何に対しての批判なのか、その批判を元にどう対処すべきかってのが少し見えてきたと思う。
まずは語彙力を身に着ける。
そして各用語の因果関係を把握する。
これらを身に着けることで専門家と協力関係が作りやすい。
ここがG検定のゴールってことになる。
そして、これらを身に着けるには上手なカテゴライズというものが必要になる。
G検定シラバスを使ったカンペ用カテゴリ分けのコツ
というわけでカテゴライズの仕方の話になる。
究極カンペの作り方の動画の時は、公式テキストにそってカテゴライズする説明にしている。
ただ、昨今だとシラバスがかなり整備されてきているため、
シラバスを元にカテゴライズする方がより適切なはず。
公式テキストもシラバスに沿ったものになっているはずなので、どちらを選んでも良いはずだが、
このシリーズとしてはシラバスに沿った分け方をベースとする。
ちなみに、2024年に改定されたシラバスだとこのような感じ。
シラバスの改定としてはおそらく2回目で、かなり洗練されたものと言える。
比較的全体像が分かりやすい検定になってきている。
カテゴライズの詳細化
先ほど、シラバスによるカテゴライズの話をしたが、
実はシラバスのカテゴライズではやや詳細度が不足している面もある。
つまり、シラバスでは一つのカテゴリだけど、もうちょっと分けた方が良い。
具体例を出すと・・・。
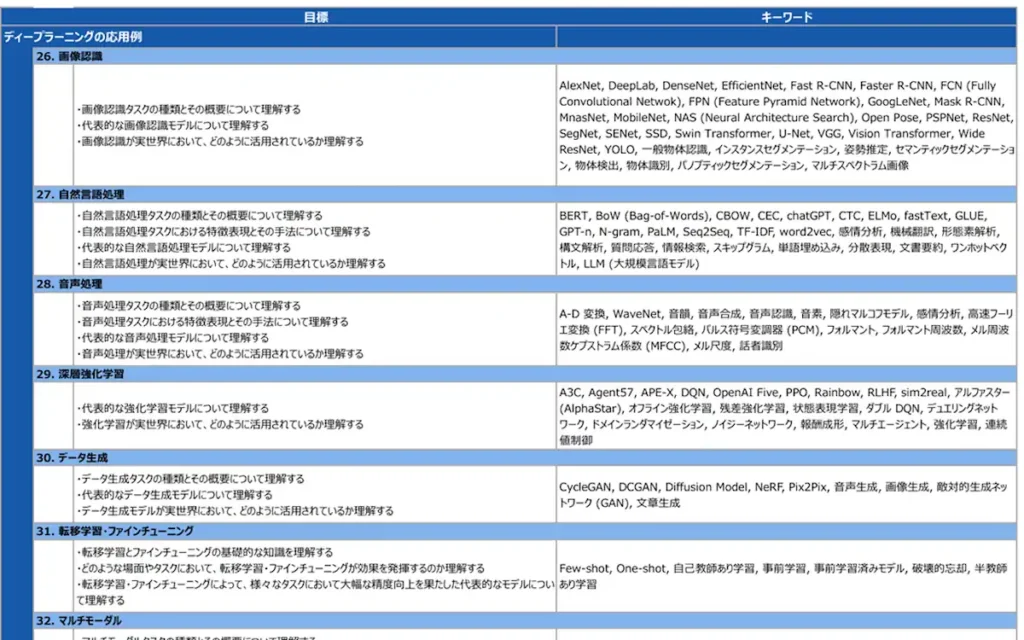
例えば、ディープラーニングの応用例の中の画像認識のカテゴリを見てみる。

キーワードの列に多くの用語が入っているのだが、それぞれ性質が異なるものが多い。
これを私なりに分けるみる。
- 一般物体認識
- AlexNet, VGG, GoogLeNet, ResNet, DenseNet, MobileNet, NAS, SENet, MnasNet, EfficientNet, Vision Transformer, Wide ResNet, Swin Transformer
- 物体検出
- Fast R-CNN, Faster R-CNN, YOLO, SSD
- セマンティックセグメンテーション
- FCN, U-Net, SegNet, DeepLab, PSPNet
- インスタンスセグメンテーション
- Mask R-CNN
- パノプティックセグメンテーション
- FPN
- 姿勢推定
- Open Pose
物体認識、物体検出、セグメンテーション、姿勢推定など、異なる領域がまぜこぜではある。
画像をインプットとするという意味では一緒だが、同一のカテゴリとされるとちょっと辛い。
物体検出やセグメンテーションも、内部的には物体認識の技術要素を入れ込んでいるため、
同一カテゴリであっても妥当とは言えるのだが、
初学者からすると少し厄介なまとめ方ではある。
一般物体認識の因果関係をカンペに落とし込む例
それでは、因果関係の例も示しておく。
先ほどの、一般物体認識ってところが結構用語が多かったので、ここの因果関係を出してみる。
こんな感じの因果関係になる
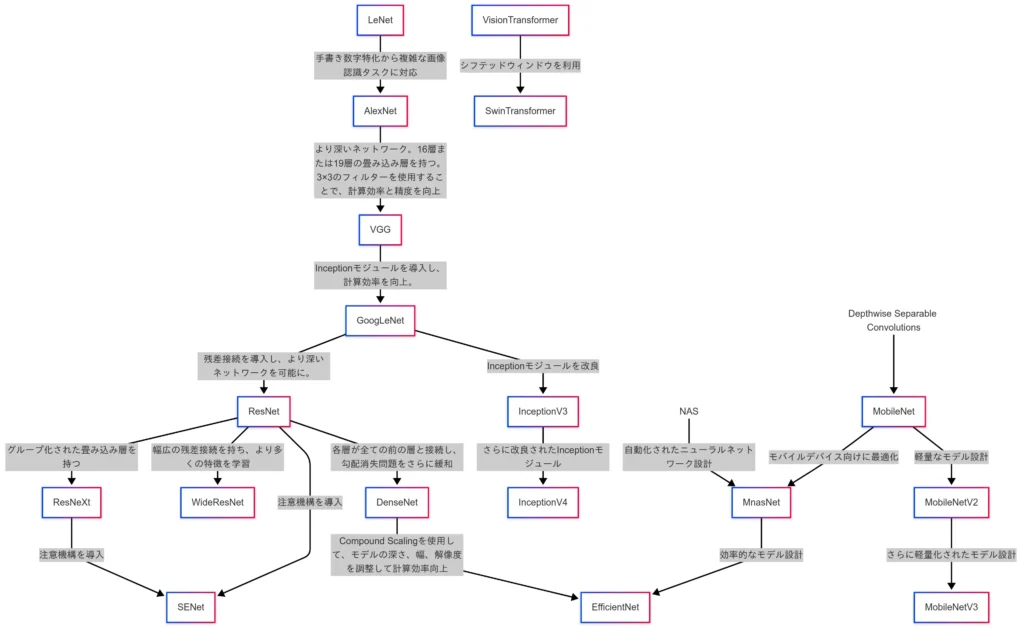
(むっちゃややこしいことになっている・・・。)
これを見ると、確かに用語レベルで暗記しても勉強したことにはならなそうと思った人はそこそこいるではなかろうか?
別にこれを把握していなければならないってことはないから、それほど心配する必要はない。
ただ、これを自分で書けた方がいろいろと話が早いってのはある。
この関係図を簡単に説明すると・・・。
まずは、LeNetやAlexNetを起点とした、層やパラメータ数を増やすことで性能を引き上げていた時代。
そして、ResNetを皮切りとして、残差ブロックを導入することで深層化に成功した時代。
さらにDepthwise Separable Convolutionにより、畳み込み層の計算量を大幅に減らし、
モバイルデバイスに対応した時代。
ほぼ同時期にはなるけど、NASによりアーキテクチャを自動設計した時代。
Transformerを自然言語タスクからビジョンタスクにも転用した時代。
という分け方が代表的。
これを究極カンペに反映できればさらに究極化されるってことになる。
情報量としてはそれほど多くないから、暗記って感じもしないでしょう。(たぶん?)
G検定レベルで専門家と会話するためのコミュニケーション例
ここまで、専門家とのコミュニケーションに対して重要という話をしてきたわけだが、、
おそらく具体的にどういうシーンの話をしているかが伝わりにくいと思う。
というわけで、コミュニケーション例。
車両移動上の物体検出をリアルタイムで行いたい。
振動が激しい環境のため、PCなどを使用した計測は困難であることからエッジデバイス利用が妥当。
リアルタイム且つエッジデバイスということから精度が落ちるのは避けられないが、可能な限りの精度維持が望ましい。
使用するモデルは演算リソースの都合、MobileNetが候補に挙がるが、
YOLOv8が使用可能かの検討も同時に進めたい。
先ほどのリソース都合でモデル圧縮は必須になる。
知らない人からしたら、
「日本語のようで日本語じゃねぇ!」
になるとは思うが・・・。
まず、ステージ1の語彙力が身に付いた状態だと、
エッジデバイス、MobileNet、YOLO、モデル圧縮はわかると思う。
このレベルでも十分コミュニケーションを取れていると言えるのだが、
ここに対してステージ2の因果関係も含めた知識を入れ込むと、こういう解釈が暗黙的に行われる。
- リアルタイムであることからYOLOのような1段検出器が望ましく、Faster R-CNNやMask R-CNNのような多段検出器は相性が悪い。
- MobileNetは物体検出器では無く画像分類器。ここでは暗黙的に物体検出器であるMobileNet-SSDなどを指している。
- MobileNetはDepthwise Separable Convolutionにより、畳み込み層の大幅なメモリリソース削減と演算効率向上を実現している。
- エッジデバイス利用より、YOLOv8は暗黙的にSmall、Nanoなどの軽量モデルを想定している。
- モデル圧縮は量子化、プルーニング、蒸留を指している。
- モデル圧縮手法の全てをいきなり実施するというより、一つずつ試して適正な度合の目途を付ける必要がある。
行間を読むとかそういうレベルは超えている・・・・。
このように、語彙力と因果関係を組み合わせたコミュニケーションは相当な情報圧縮が可能で、
その分、コミュニケーション効率が高いと言える。
MobileNet-SSDについてはG検定の範疇を超えている話ではあるが、
YOLOv8とMobileNetを対比していることからの違和感は拾える。
尚、Depthwise Separable Convolutionは用語として長い名称ことで有名である反面、実態がよくわからない用語でもある。
実際に会話で直接使われることはほぼ無いのだが、
MobileNetというキーワードを聞くと、その場にいる人全員の脳内で自動で流れるワードではある。
ステージ2をクリアしている人同士だったら数秒で終わる会話が、
ステージ1にも至ってない人が入ることで数時間とかに膨れ上がりそうというのも認識できたと思う。
会話しながらだと、ググったりChatGPTに質問している余裕もない。
音声入力でリアルタイムでLLMに解説してもらうという手法もあると言えばあるが、
それでも、語彙力と因果関係を身に着けた人たちのスループットに追いつけるものではない。
このスループットが目に見える差として現れる以上、これが今後の人間にとっての重要な付加価値になり得ると言える。
究極カンペシリーズの今後の進め方と扱うカテゴリ
一応、シリーズ化する予定ではあるのだが、
扱うカテゴリの優先順位を決めておく。
普通はシラバスの先頭からやるのだろう。
しかし、シラバスの先頭の方は、それほど因果関係がややこしくはない。
因果関係がややこしくなるのは後半以降。
G検定のテキストも最初の方はサクサク読めるが、途中から何を言っているのかわかりにくくなるのを感じている人も多い事でしょう・・・。
わかりにくいのに加えて、そもそも情報量が多くなる・・・。
これが、因果関係がややこしいって状態になる。
というわけで、この順番で解説していくことになると思う。
- ディープラーニングの応用例
- AIの社会実装に向けて
- AIに必要な数理・統計知識
- AIに関する法律と契約
- AI倫理・AIガバナンス
これら以外にもディープラーニングの概要や要素技術のカテゴリもあるのだが、
ここらへんはたぶん、個々人で普通に対応できるものとして、まずは対象外としておく。
ディープラーニングの要素技術に関しては、そもそも単体で覚えるというよりも、
ディープラーニングの応用例と紐づける形で覚える方が効率的。
この点も示していければと思っている。
まぁ、G検定のシラバスの最初の方は、他のサイトや他のYoutube動画でも扱ってること多いから、
あまり扱いきれてないところからやった方が良いと思う。
だいたい最初の方だけ情報が厚くて、後ろになるほど薄くなる傾向がある・・・。
これは、途中で力尽きたか、多忙とかで更新が難しくなったとかいろいろあるのだと思う。
後ろに行くほど単純な用語説明より因果関係の方が重要になってくるから、
説明しにくい、よってどうしても情報が薄くなる。
というのはあるかもしれない。
(用語単位で説明してもあまり説明にならないし・・・)
まとめ:G検定は「意味ない」のではなくゴール設定が違うだけ
- 究極カンペの作り方についての問い合わせが増えている。
- G検定の評判を確認し、ネガティブな意見を問題提起として捉える。
- 勉強のステージを定義し、語彙力と因果関係の把握が重要であることを説明。
「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
この続きの#2以降(画像認識・自然言語処理・強化学習・生成AIなど)の究極カンペは、G検定カンペバックナンバー一覧から辿れます。
深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト 第3版

徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版 徹底攻略シリーズ

ディープラーニングG検定(ジェネラリスト) 法律・倫理テキスト



コメント