
「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
G検定究極カンペの一覧と各回の概要はこちら(バックナンバー)

G検定画像認識分野のカンペを作る前に
本稿は「G検定対策 究極カンペをつくろう」シリーズの第2作である。
前回は、専門家とのコミュニケーションの重要性について述べ、SNS上のネガティブな意見を手がかりに現状の課題を抽出した。
学習段階に応じた批判的意見を観察することで、問題提起の対象が明確になる傾向がある。
この記事でわかること(G検定 画像認識カンペ編)
- G検定シラバスに対応した画像認識分野の全体像
- 一般物体認識の代表モデル(AlexNet・VGG・ResNet・DenseNet・EfficientNet・ViTなど)の系譜
- 物体検出モデル(YOLO・R-CNN系列・SSD・Mask R-CNN など)の違いと整理の仕方
- セグメンテーション(FCN・U-Net・PSPNet・DeepLabなど)の位置づけ
- 姿勢推定モデル(OpenPose+PAF)のイメージとG検定レベルで押さえるポイント
- これらのモデルを因果関係図として1枚にまとめるための考え方
G検定究極カンペの動画シリーズ
G検定の究極カンペ関連動画の再生リスト

本記事で扱う画像認識カテゴリと範囲
本稿で扱う主な内容は以下の通りである。
- 各種画像認識処理
- 一般物体認識
- 物体検出
- セグメンテーション
- 姿勢推定
画像認識に関連する技術を体系的に整理し、それぞれのモデルがどのカテゴリに属するかを因果関係に基づいて明確化する。
各用語の詳細については、別途調査することを推奨する。検索エンジンやChatGPTなどを活用するとよい。
なお、用語間の因果関係については、一般的な検索では十分な情報が得られない可能性がある。
画像認識モデル全体の因果関係図(AlexNet起点)
まずは筆者が作成した因果関係図を提示する。
前回は一般物体認識に限定した図であったが、今回はその他の画像認識モデルも含めた構成となっている。
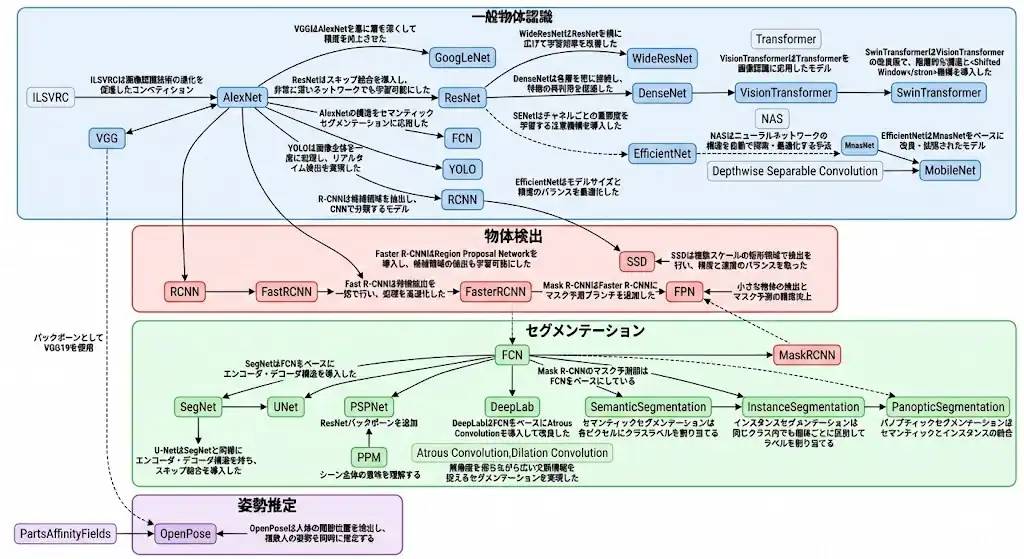

図の見方としては、AlexNetを起点にその接続線を辿ることで全体像を把握できる。
AlexNetは各種CNNに接続されているほか、物体検出器であるR-CNNやYOLO、VGGを経由して関連するSSDやOpenPoseにもつながっている。
このように、AlexNetは画像認識における最も基礎的なモデルである。
AlexNetは2012年のILSVRC(画像認識コンペティション)において優勝したモデルであり、ディープラーニングの注目を集める契機となった。
CNNを学習する際には、最初に扱う代表的なモデルとして位置づけられている。
歴史的にも重要であり、モデル間の因果関係においても中心的な役割を果たしている。
G検定 画像認識:一般物体認識モデルの系譜(VGG・ResNet・DenseNet・ViTなど)
一般物体認識においても、AlexNetを起点としてモデルの系譜を辿ることが基本となる。

AlexNetの後には、GoogLeNetおよびVGGが登場している。
両者は2014年のILSVRCにおいて発表され、GoogLeNetが優勝、VGGが2位であった。
GoogLeNetはInceptionモジュールを導入しており、異なるサイズの畳み込みを並列に行うことで、画像の特徴を多様なスケールで捉える構造となっている。
一方、VGGはAlexNetを基に層を深くすることで精度を向上させたモデルである。
並列構造のGoogLeNetに対し、VGGは直列構造を採用しているが、内部パラメータを増加させることで性能を向上させるという点では共通している。
特にVGG16(16層)およびVGG19(19層)が広く知られている。
次に登場するのがResNetである。
ResNetはスキップ結合(Skip Connection)を導入したことで知られており、これにより残差学習が可能となり、勾配消失問題への対策が施されている。
残差学習の解釈には諸説あるが、筆者の見解としては、オイラー法のような数値微分的な演算を通じて、データセットに含まれるバイアスを除去し、変化量のみを捉えることで特徴量が際立つ学習が可能になったと考えている。
この解釈はスキップ結合の数式から導かれたものであり、あくまで一つの考察として参考程度に留めておくのが適切である。
ResNetからは、DenseNet、WideResNet、SENetといったモデルが派生している。
DenseNetは各層を密に接続することで特徴の再利用を促進する構造を持つ。

WideResNetはResNetを横方向に拡張することで学習効率を改善したモデルである。

SENetはResNetをベースにAttention機構を導入したモデルであり、SEブロックと呼ばれる構造を利用している。
なお、GoogLeNetにSEブロックを組み込むパターンも存在する。

EfficientNetはResNetと比較されることが多く、モデルサイズと精度のバランスを最適化した構造を持つ。
EfficientNetに至る系譜としては、MobileNet、MnasNet、EfficientNetという流れがある。
MobileNetはDepthwise Separable Convolutionを採用した軽量CNNであり、モバイルデバイス向けに最適化されている。
この構造は、Depthwise Convolution(チャネルごとの独立畳み込み)とPointwise Convolution(チャネル間の結合)によって構成されており、従来の畳み込み層と同等の性能を維持しつつ、メモリおよび演算リソースの削減を実現している。
MobileNetV2の構造をベースに、NAS(Neural Architecture Search)を適用したものがMnasNetである。
NASはニューラルネットワークの構造を自動で探索・最適化する手法であり、MnasNetの「M」はMobileの頭文字に由来する。
このMnasNetがEfficientNetの基盤となっている。
また、一般物体認識にはTransformerアーキテクチャを応用したモデルも存在する。
Vision Transformer(ViT)は、画像をパッチに分割し、それをトークン列としてTransformerに入力する構造を持つ。
CNNが画像全体を抽象的に捉えるのに対し、ViTはパッチと位置情報をトークンとして系列データとして処理する。
この系列データの関係性を同時に学習することが重要である。
ViTの改良版としてSwin Transformerが存在する。
Swin Transformerは階層的な構造とShifted Window機構を導入しており、局所的なSelf-Attentionを効率的に行いつつ、ウィンドウをずらすことでグローバルな情報伝播も実現している。
Self-Attentionとは、入力ごとに重みを動的に計算することで、重要な情報を選択的に抽出する仕組みである。
通常の全結合層では重みが訓練によって固定されるが、Self-Attentionでは推論時に重みが動的に決定されるため、重要な要素を抽出することが可能となる。
(Attention機構の詳細については、別途解説を予定している。)
G検定 画像認識:物体検出モデル(YOLO・R-CNN・SSD・Mask R-CNN)
本節では、物体検出に関する代表的なモデルとその系譜について解説する。
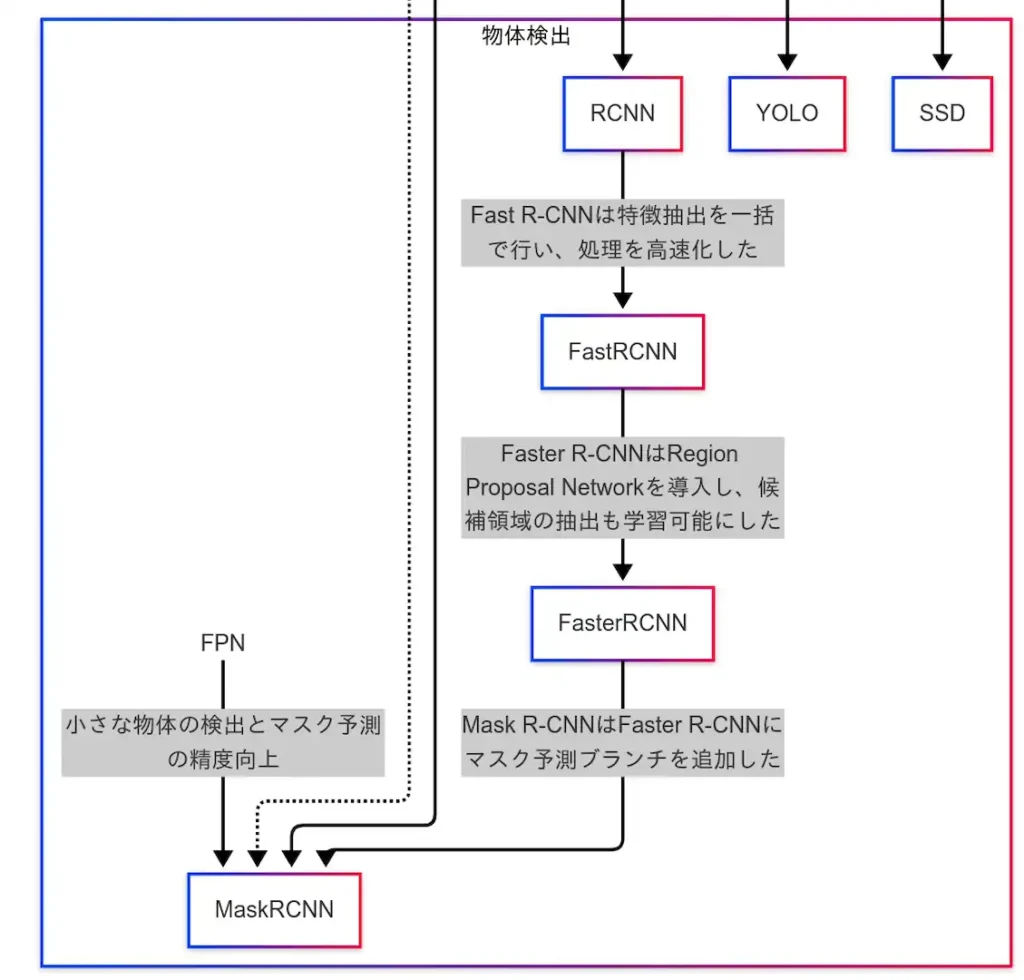
物体検出に関するモデルは、一般物体認識と比較すると要素数は少ないが、技術的には重要な位置を占めている。
まず、YOLO(You Only Look Once)は、リアルタイム処理に優れた物体検出モデルとして広く知られている。
YOLOは画像全体を一度に処理することで高速な推論を実現しており、リアルタイム検出が可能である。
バージョンも多数存在し、YOLOv8以降では物体検出に加え、姿勢推定やセグメンテーションにも対応している。
次に、R-CNN系列のモデル群が存在する。
R-CNN、Fast R-CNN、Faster R-CNNの順に、処理速度と精度の両面で改良が加えられてきた。
これらのモデルは多段検出器として分類され、高精度な検出を実現している。
さらに、Faster R-CNNを基盤とし、FCN(Fully Convolutional Network)によるセグメンテーションマスクを統合したモデルがMask R-CNNである。
Mask R-CNNは、物体検出とセグメンテーションを組み合わせたインスタンスセグメンテーションを実現する。
また、FPN(Feature Pyramid Network)を用いることで、小さな物体の検出精度やマスク予測の精度が向上している点も特徴である。
加えて、SSD(Single Shot MultiBox Detector)も重要なモデルである。
SSDはVGG-16をバックボーンとして採用し、YOLOと同様に1段検出器として設計されている。
リアルタイムでの高速処理と高精度な検出を両立しており、YOLOよりも高精度、Faster R-CNNよりも高速というバランスの取れた性能を有している。
以上をまとめると、R-CNN系列は多段検出器として高精度を実現し、YOLOおよびSSDは1段検出器として高速処理を実現している。
また、Mask R-CNNのように、物体検出とセグメンテーションを統合したモデルも存在する。
G検定 画像認識:セグメンテーション(FCN・U-Net・PSPNet・DeepLab)
セグメンテーションとは、画像内の各ピクセルに対してクラスラベルを割り当てる技術である。
この技術は、画像認識の中でも特に詳細な領域分割を必要とする場面で活用される。
セグメンテーションには主に以下の3種類が存在する。
- セマンティックセグメンテーション:画像内のピクセルをクラスごとに分類するが、同一クラス内の個体識別は行わない。
- インスタンスセグメンテーション:同一クラス内でも個体ごとにピクセル単位で識別を行う。
- パノプティックセグメンテーション:セマンティックとインスタンスの両方を統合した手法であり、背景も含めて包括的に分類を行う。
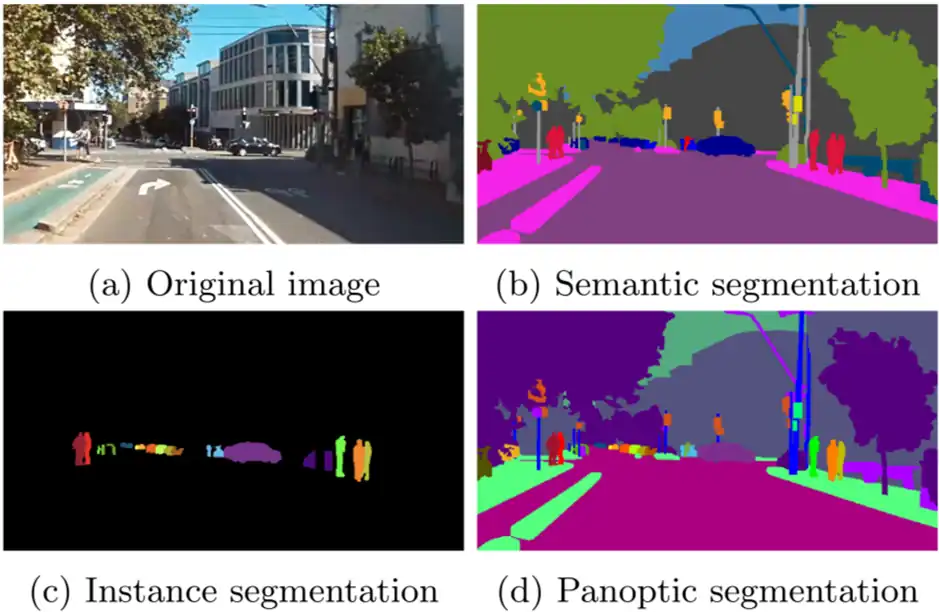
これらの手法は、ピクセル分類、個体識別、背景の扱いという観点から以下のように整理される。
| 手法 | ピクセル分類 | 個体識別 | 背景の扱い |
| セマンティック | ✓ | ❌ | ✓ |
| インスタンス | ✓ | ✓ | ❌(主に物体のみ) |
| パノプティック | ✓ | ✓ | ✓(両方統合) |
パノプティックセグメンテーションは最も包括的な手法であるが、その分モデルの規模が大きくなる傾向がある。
G検定においては、主にセマンティックセグメンテーションが対象となっており、一部においてMask R-CNNがインスタンスセグメンテーションとして登場する。
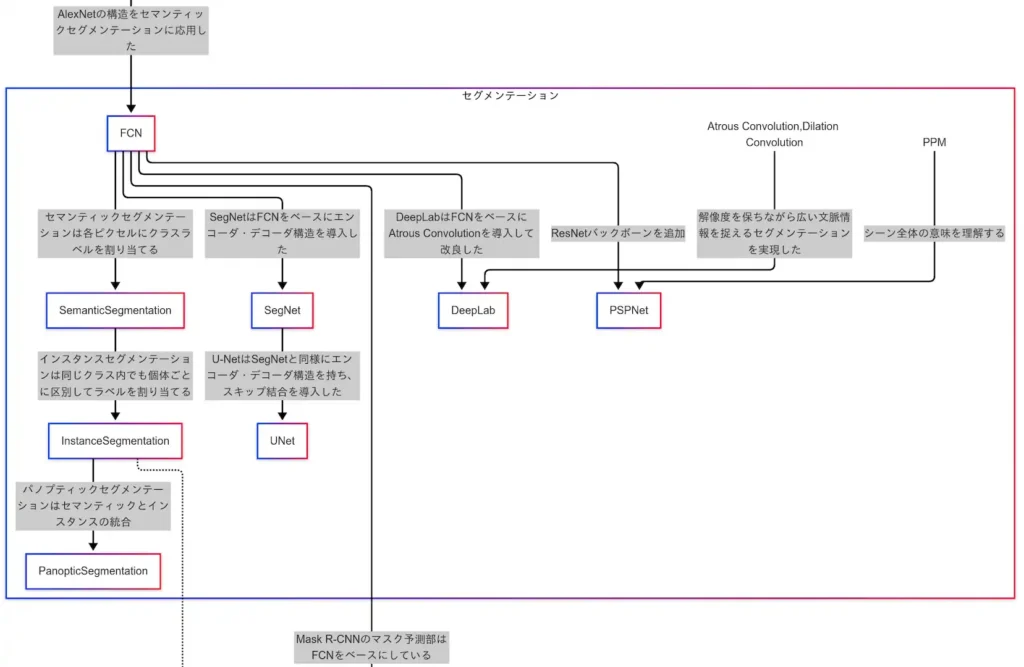
モデルの因果関係に着目すると、FCN(Fully Convolutional Network)を起点として、SegNet、U-Netへと発展している。
SegNetはFCNを基にエンコーダ・デコーダ構造を導入したモデルであり、U-NetはSegNetにスキップ結合を加えることで性能を向上させた構造となっている。
また、PSPNetもFCNから派生したモデルである。
PSPNetはPyramid Pooling Module(PPM)を導入することで、マルチスケールな文脈理解、グローバル情報の補完、複雑なシーンへの対応力を向上させている。
PPMは異なるサイズの畳み込み層を並列に配置することで、画像の多様なスケールに対応する構造を持つ。
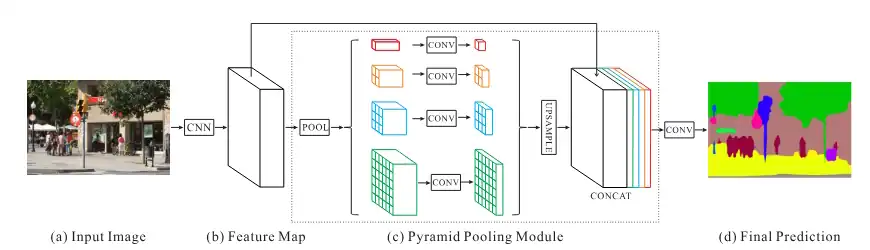

さらに、DeepLabはAtrous Convolution(またはDilation Convolution)を用いたモデルである。
Atrous Convolutionは畳み込みの受容野を広げる手法であり、カーネルの間に空間的な隙間を設けることで広範囲の情報を取得可能にする。
なお、Atrous ConvolutionとDilation Convolutionは同一の技術であるが、論文上では前者、フレームワーク上では後者の名称が用いられることが多い。
このように、同一技術に対して異なる名称が存在する点には注意が必要である。
G検定 画像認識:姿勢推定(OpenPoseとPAFのイメージ)
最後に、姿勢推定について述べる。
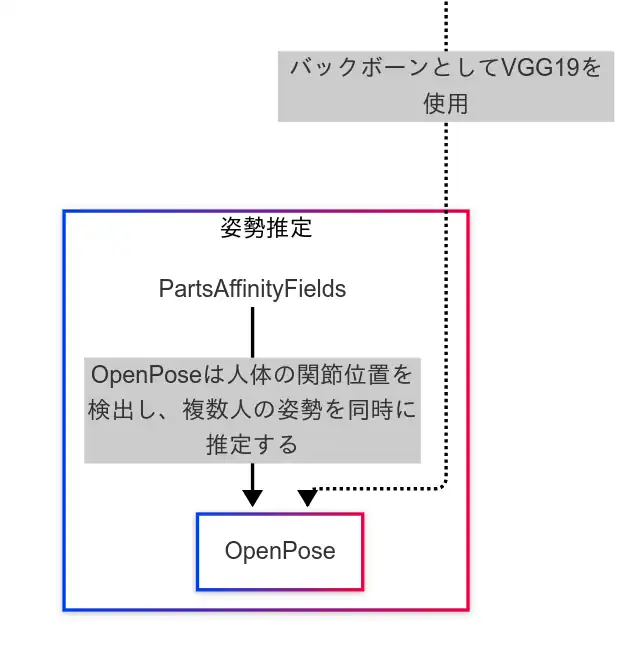
姿勢推定に関するモデルは比較的構造が単純であり、主にVGGとの関連性と、Parts Affinity Fields(PAF)との接続に注目すれば十分である。
PAFとは、人体の各部位間のつながりをベクトル場として表現し、それを学習・推定する技術である。
この技術により、複数人の姿勢推定が可能となり、遮蔽物(オクルージョン)によって一部の部位が視認できない場合でも、関節位置の補完が可能となる。
PAFの導入により、より柔軟かつ精度の高い姿勢推定が実現されている。
姿勢推定モデルは、以下の3つのステージで構成されている。
- ステージ1:粗い姿勢の推定を行う。
- ステージ2:より精密なパーツ親和性(部位間の関係性)を推定する。
- ステージ3以降:関節位置の詳細な推定を行う。
このように、推定の精度を段階的に高めながら、身体各部のつながりを推定し、最終的に関節の位置を特定する構造となっている。
参考文献:

まとめ:G検定の画像認識分野を因果関係からカンペに落とし込む
- 画像認識の全体像を因果関係図で整理し、AlexNetを起点に各モデルの進化をたどる。
- 一般物体認識から物体検出・セグメンテーション・姿勢推定まで、各カテゴリの代表モデルと技術を解説。
- モデル同士の構造的なつながりや技術的背景を踏まえ、因果関係をもとに体系的に理解を深めていく。
「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
確認用(過去問ふぅ対策道場)
10問中ランダムで3問、選択肢配置もランダム。

対策道場本体は以下のリンクから

画像認識以外の自然言語処理・音声処理・強化学習・生成AI・転移学習・マルチモーダルなどの究極カンペは、G検定究極カンペのバックナンバー一覧から辿れます。
深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト 第3版

徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版 徹底攻略シリーズ

ディープラーニングG検定(ジェネラリスト) 法律・倫理テキスト



コメント