
「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
バックナンバーはこちら

はじめに
本稿は、動画シナリオ「G検定対策 究極カンペ#9」を下敷きに、 転移学習 と ファインチューニング を因果関係で解きほぐした説明文書である。キーワードの羅列ではなく、「なぜそうするのか」「それが何をもたらすのか」という 因→果 の線を追うことで、全体像を一気通貫で理解できるように編集した。随所に小さな因果関係図を差し込み、文章と図が相互参照できるよう配慮してある。
動画シリーズ
G検定の究極カンペ関連動画の再生リスト

説明内容
扱う範囲は、基本概念から実装戦略、少数ショット、自己教師あり・半教師あり、代表モデル、適用場面、リスクと対策、そして実務手順の順である。言い換えれば、事前学習 が 汎用表現 をもたらし、それが 転移学習 を可能にし、 ファインチューニング によって ターゲットタスクへの適応 が進む──という長い一本の因果鎖を、必要な分岐(戦略・場面・リスク)と対策で補強していく流れである。
- 基本(転移学習・ファインチューニング・事前学習)
- 戦略(特徴抽出・全体微調整・凍結・層別学習率・ヘッド置換・正則化・早期終了)
- 少数ショット(Few-shot・One-shot)
- 自己教師あり・半教師あり(コントラスト学習・マスク予測・疑似ラベル)
- モデル事例(ResNet・BERT・ViT)
- 適用場面(小規模データ・計算制約・ドメイン近接・シフト)
- リスク・対策(破壊的忘却・過学習・負の転移+EWC・部分凍結)
- 手順(データ準備→評価)
基本(転移学習・ファインチューニング・事前学習)
大規模データで 事前学習 を施すと、モデルはエッジやテクスチャ、語彙や文脈といった 汎用的な表現 を獲得する。この汎用表現が存在するからこそ、別タスクへ 知識の移送 が成立する。すなわち、 事前学習 → 汎用表現の獲得 → 転移学習が可能 という因果が走るわけである。
転移学習の中核手段が ファインチューニング である。出力層のみを学習する特徴抽出型であれば データと計算資源が乏しくても動く。一方、上位層や全層まで更新する微調整型であれば タスク固有の表現に寄る ため、十分なデータがあるほど 適応度が上がる。ここで鍵を握るのが ソースタスクとターゲットタスクの近さ であり、モダリティや分布が近いほど 転移効率は高まる。
戦略(特徴抽出・全体微調整・凍結・層別学習率・ヘッド置換・正則化・早期終了)
ファインチューニングは「どの層を、どれだけ、どの速さで動かすか」を設計する営みである。ヘッド置換でターゲットの出力構造に適合させ、凍結で低層の汎用表現を保護し、層別学習率で低層の破壊を避けつつ上層の適応を促進する。これらの設定がうまく噛み合うと、安定性と適応力のトレードオフが解け、少ない反復で汎化性能へ到達する。
因果で読み直すと、タスク差が大きい→全体微調整が必要、データが少ない→特徴抽出が安定、旧知識を壊したくない→凍結+小LR、学習が暴走する→正則化と早期終了、という意思決定になる。
少数ショット(Few-shot・One-shot)
Few-shot/One-shotが成立するのは、事前学習済みモデルがすでに豊富な表現を持つ からである。少数例であっても、その例が 既存表現の座標を微修正するだけで済む ため、学習信号が薄くても適応が進む。One-shotはさらに厳しい条件であるが、動く初期解 を得るという目的に対しては理にかなう。ここでも 凍結や小さな学習率 が、表現の崩壊(破壊的忘却)を防ぐ方向に働く。
自己教師あり・半教師あり(コントラスト学習・マスク予測・疑似ラベル)
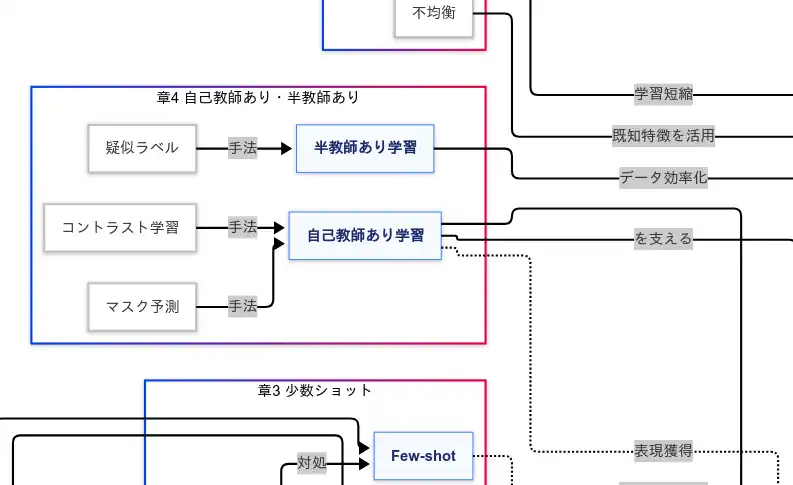
自己教師あり学習 は、ラベルなしデータから 課題そのものを自動生成 して表現を磨く枠組みである。コントラスト学習 は「似を近づけ異を離す」という力学で 距離構造を整える。マスク予測は隠した断片の再構成を迫ることで 文脈的・構成的知識を涵養する。これらが 強力な事前学習 を生み、のちの転移と微調整の 成功確率を底上げ する。
半教師あり学習 は、少量の真ラベルと大量の未ラベルを 疑似ラベル で橋渡しし、データ効率を押し上げる。ただし疑似ラベルの誤りは 学習を汚染 するため、信頼度閾値 や 温度スケーリング 等で誤伝播を抑えるほど、汎化は安定 する。
モデル事例(ResNet・BERT・ViT)
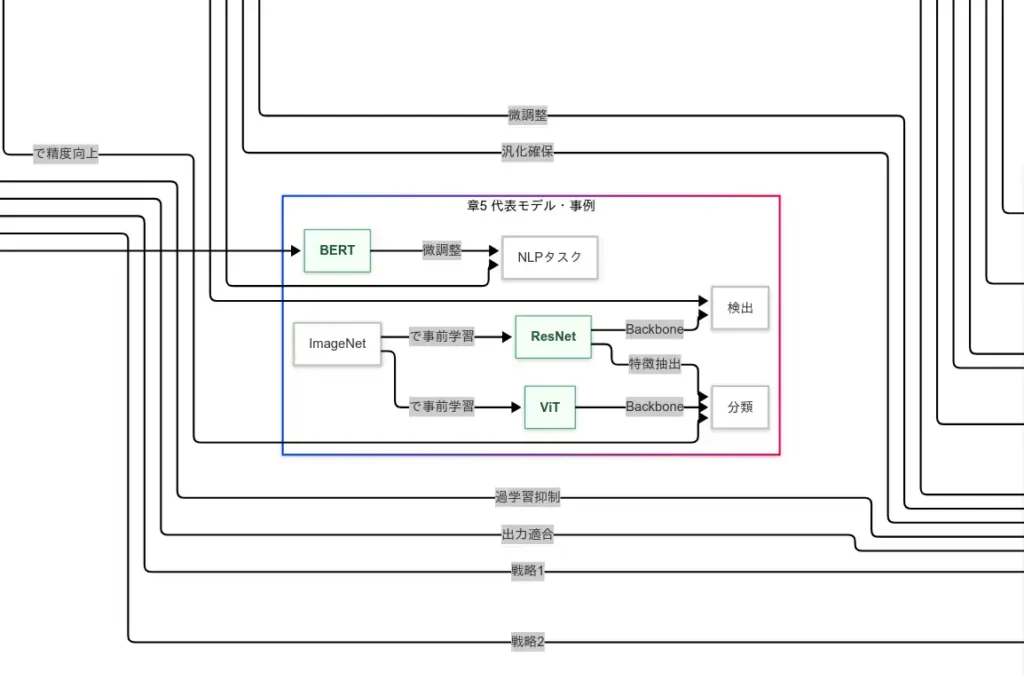
ResNet は残差接続によって深層学習の 勾配劣化を緩和 し、大規模画像事前学習から Backbone として広範に転移される。BERT はマスク言語モデルによる自己教師ありで 言語表現の文脈性 を獲得し、微調整 だけで分類・QA等が 急伸 する。ViT は画像をパッチ化してTransformerに投入する設計により、畳み込みに依存しない視覚表現 を可能にし、ImageNet事前学習→転移 の線が太くなった。
適用場面(小規模データ・計算制約・ドメイン近接・シフト)
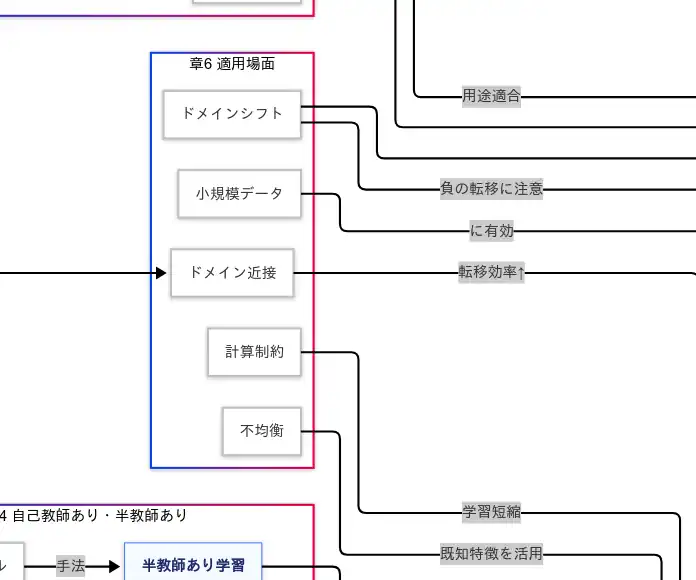
データが少ない ほど、ゼロ初期化の学習は 高リスク になるため、転移が 最短距離 となる。計算資源が限られる ほど、事前学習の再利用は 時間と電力の節約 を誘発する。ドメインが近い ほど、既存表現の再利用率が高まり 学習効率が上がる。逆に ドメインシフト が大きいと、近道が遠回りに化ける 負の転移 が起きるため、データの再サンプリングやスタイル正規化、低学習率 などで 慎重に橋渡し する必要がある。クラス 不均衡 への対処では、事前表現が 希少クラスの特徴抽出を補助 するため、重み付け損失 や 再サンプリング と併用すると総合的な汎化が改善する。
リスク・対策(破壊的忘却・過学習・負の転移+EWC・部分凍結)
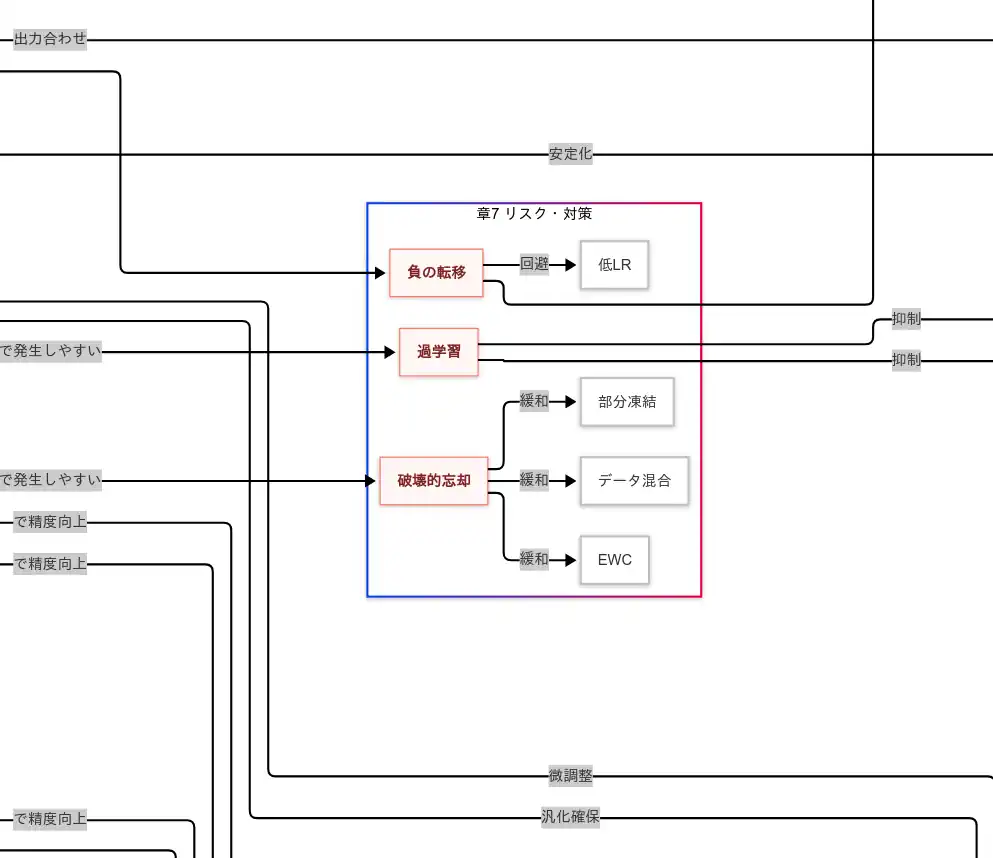
ファインチューニングの自由度が高いほど旧知識が壊れやすい ため、破壊的忘却 が現れる。これに対して、EWC は重要重みに 罰則を課す ことで 保持圧力 を生み、部分凍結は低層表現を 物理的に固定 し、データ混合 は旧分布の 想起を促進 する。過学習 は モデル容量×データ量の不均衡 が原因であるため、正則化(L2/Weight Decay, Dropout)と 早期終了 が 汎化誤差の膨張 を抑える。負の転移 は 分布差や課題差 が引き金であるから、ドメイン近接の確保 と 低学習率による慎重更新 が 悪化の連鎖 を断つ。
手順(データ準備→評価)
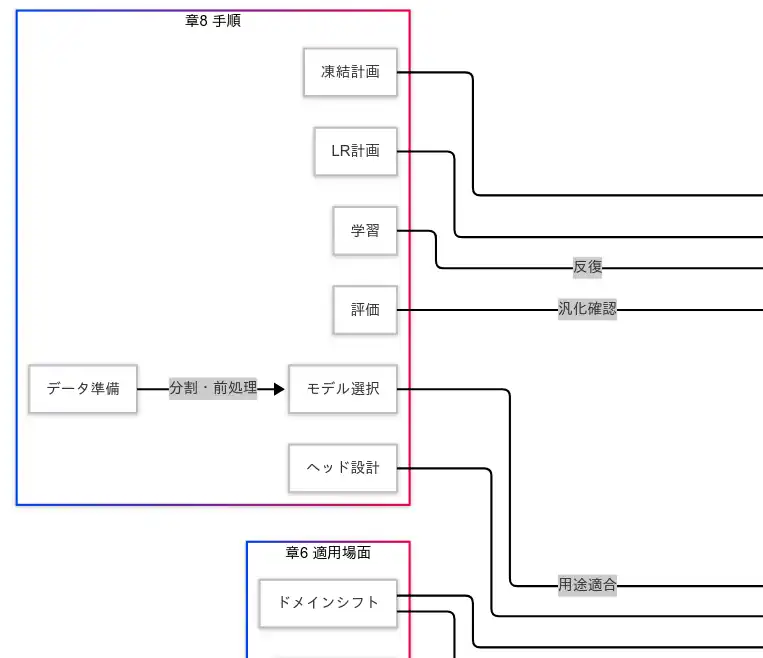
実務の流れは、入力の整備が出力の信頼性を決める という因果を前提に設計する。まず データ準備 で前処理と分割を徹底すると、検証指標の歪みが減り、以降の意思決定が 再現可能 になる。次に モデル選択 でタスク適合の高い事前学習済みモデルを選ぶと、初期性能が高く 学習が 短縮 される。ヘッド設計 で出力次元と損失を合わせると、勾配が素直 になり 収束が安定 する。凍結計画 と LR計画 で安定と適応のバランスを決め、学習 では正則化と早期終了を組み込み、評価 で汎化を確認する。評価で異常が出れば、因果の上流(データ・凍結・LR・正則化)へ戻り、最小変更で因果の断点を修復 する。
まとめ
転移学習は 事前学習で得た汎用表現を別タスクに再利用する 構造であり、ファインチューニングはその 適応のレバー である。タスク差・データ量・資源制約 という条件が、特徴抽出か全体微調整か という選択を規定し、凍結・層別学習率・ヘッド置換 が 安定性と適応力 の配分を決める。少数ショットが成立するのは 豊かな初期表現 があるからであり、自己教師ありや半教師ありはその 初期表現の質とデータ効率 を底上げする。対して、破壊的忘却・過学習・負の転移 はこの仕組みの裏腹であるため、EWC・部分凍結・データ混合・正則化・早期終了・低LR といった介入で 因果の逆流 を止めるべきである。最終的には、データ準備→設計→学習→評価 の各段で因果を点検し続けることが、短時間で信頼できる汎化性能に到達する最短路である。
補遺として、LoRAやAdapterに代表される軽量微調整、ドメイン適応、PEFT系の手法は、凍結を活かしつつ追加パラメータで適応度を稼ぐ という因果設計をさらに推し進める選択肢である。制約の厳しい現場ほど、これらの手法が 性能/費用の曲線を押し上げるといえる。
- 事前学習が汎用表現を供給し、転移学習→ファインチューニングへと因果的に接続してターゲットタスクへ効率適応する構図である
- 戦略(特徴抽出・全体微調整・凍結・層別LR・ヘッド置換・正則化・早期終了)、少数ショット、自己教師あり・半教師あり、そしてResNet・BERT・ViTの役割を位置づけた。
- 適用場面(小規模データ・計算制約・ドメイン近接/シフト)に潜む破壊的忘却・過学習・負の転移をEWC・部分凍結・データ混合・低LRで抑え、データ準備→評価の実務手順を示した。
「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
バックナンバーはこちら
深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト 第3版

徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版 徹底攻略シリーズ

ディープラーニングG検定(ジェネラリスト) 法律・倫理テキスト



コメント