合わせて読むことをおすすめな記事



解説動画
本記事の解説動画

究極カンペシリーズ 再生リスト

要約(3行)
- 問題集は「知識を増やす道具」よりも「漏れ抜けを見つける道具」として使うと伸びやすいです。
- 書籍問題集/Web無料問題集/Web模試はクセが違うため、入れる場所(訓練データ/テストデータ)を分けます。
- 分解して学ぶほど本番の絡み合いから離れるパラドックスがあるため、差分統合で“再結合”する工程を明示します。
用語の整理
このページでいう「究極カンペ」は、G検定の知識を「つながり」で復元できるように脳内の知識マップです。暗記表ではなく、背景・因果・境界条件まで含めて理解を保持している状態をさします。(紙やpdfのような実体のあるものではありません。)
しかし、「究極カンペ」という概念に馴染めない方は、まずは「自分専用の理解ノート」と読み替えても問題ありません。
究極カンペの概要(思想・位置づけ)は別ページにまとめています。
https://www.simulationroom999.com/blog/g-kentei-ultimate-kanpe-learning-method/
このページの役割分担は次の通りです。
- 究極カンペ:理解のOS(背景・因果・絡み合い・境界を保持します)
- 用語集カンペ:網羅補正(抜けを面で塞ぎます)
- 問題集:漏れ検出(失点条件・例外・混同をあぶり出します)
- 模試:汎化チェック(初見耐性と過学習を検知します)
前提整理
G検定はシラバスから出題されます。範囲の固定はシラバスが起点になります。
https://www.jdla.org/download-category/syllabus/
例題・過去問題は、出題の雰囲気を掴むための基準点として使えます。
https://www.jdla.org/certificate/general/issues/
このページでいう「カンペ」は学習用ノートの意味です。受験時は試験ルールに従い、不正に該当する行為はしない前提で設計します。
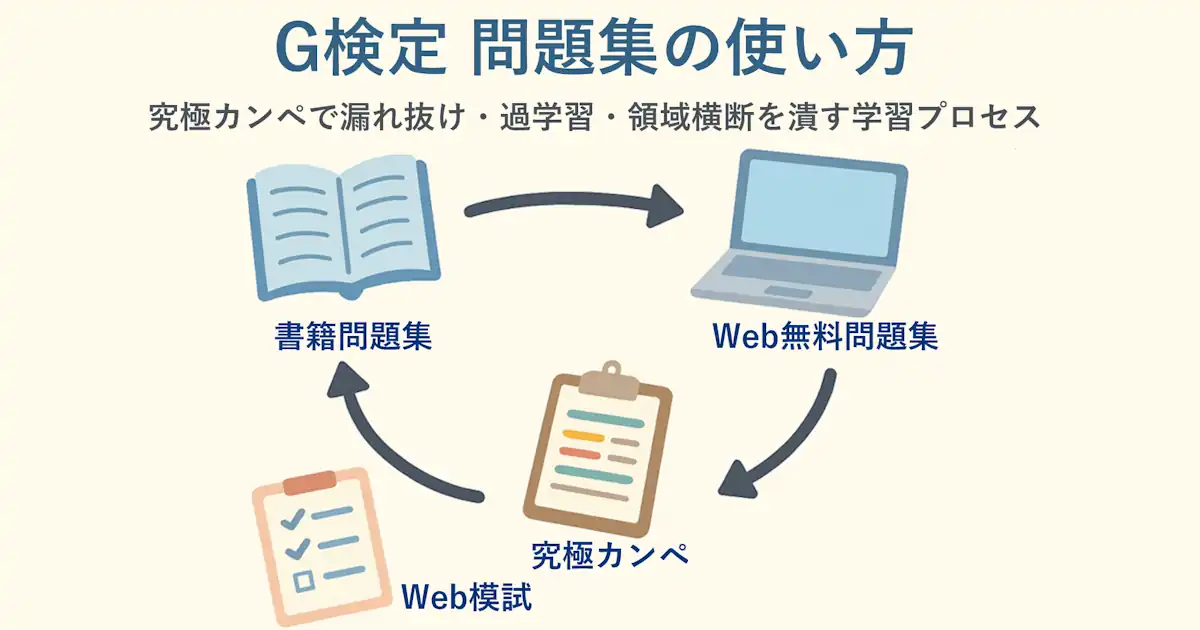
問題集タイプ分け
ここでは、問題集を次の4タイプに分けて扱います。
- 書籍問題集
- Web無料問題集
- Web模試
- その他(公式情報/公的資料など)
具体名を出さない理由
このページでは、問題集や模試の具体的な名称はあえて挙げません。理由は、教材が時期やシラバス更新の影響を強く受けるからです。
- 書籍問題集は、シラバス更新に伴って改版されたり、構成が変わったり、入手性が変わったりします。
- Web無料問題集やWeb模試は、シラバス追従性にばらつきが出たり、コンテンツが増減したり、公開停止や仕様変更が起きたりします。
- 同じ「問題集」でも、用語単体に寄るもの、領域横断に寄るもの、解説が厚いもの薄いものなど、性質の違いが大きいです。
このページの目的は、特定の教材を推すことではなく、書籍/Web無料/Web模試といった大まかな性質の違いを前提に、時期や時代に左右されにくい学習プロセスを提示することです。
具体的な教材の比較やおすすめは、別ページ(おすすめ問題集など)で更新し続けるほうが、情報としても鮮度を保ちやすいです。
(一般的な記事であれば、ここらへんにアフィリエイトリンクを張るのでしょうけど、邪魔にならないように文末に追いやってます。)
書籍問題集
- 得意:編集された順序・難易度・解説の安定感が出やすいです。枠内強化(分野ごとの理解を固める)がしやすいです。
- 苦手:更新が遅れやすく、法律倫理・動向など変化領域の鮮度は落ちやすいです。
- 入れどころ:訓練データとして使い、誤答のタグ付けと差分抽出に向きます。
Web無料問題集
- 得意:量と周回性が出しやすく、習慣化に向きます。細切れで回しやすいです。
- 苦手:解説品質や網羅性がばらつきやすいです。用語単体に寄ると、本番の問われ方と乖離しやすいです。
- 入れどころ:訓練データとして量を回しつつ、穴の種類(例外/混同/用語抜け)を検出する用途に向きます。
参考として、サイト内のWeb無料問題集(演習の受け皿)を置いておきます。
https://www.simulationroom999.com/blog/g-test-measures-problem-collection/
Web模試
- 得意:時間制約・出題のまとまりがあり、本番に近い形で弱点が顕在化します。
- 苦手:母数が少ない場合、やり切ると復習化してテストとして機能しにくいです。
- 入れどころ:テストデータとして温存し、初見耐性と過学習の有無を測る用途に向きます。
その他
- 公式シラバス/公式例題・過去問題:範囲と基準点の固定に使えます。
https://www.jdla.org/download-category/syllabus/
https://www.jdla.org/certificate/general/issues/ - 公的資料(法律倫理・ガバナンス):変化領域の差分更新に使えます。本文に溶かすより更新レイヤとして隔離すると運用が軽くなります。
https://www.ppc.go.jp/personalinfo/
https://www.bunka.go.jp/seisaku/chosakuken/aiandcopyright/
問題集に共通する弱点と学習設計のパラドックス
書籍問題集、Web無料問題集、Web模試など形式が違っても、共通して起きやすい弱点があります。
それは、領域横断型の問題を入れ込みにくいことです。
領域横断型とは、例えば「機械学習の手法」だけでなく「評価指標」「運用」「法律倫理」「社会実装の論点」が絡み合う形で問われるタイプです。問題集が用語単体に寄るほど、本番の感覚と乖離しやすくなります。
ただし、これは問題集が悪いから起きるわけではありません。領域横断型は解説も領域横断になり、初学者にとって負荷が高すぎるため、教材はどうしても分解して教える方向へ寄ります。
ここにパラドックスがあります。
学習設計を最適化(分解・整理・順序設計)すればするほど、検定本番の絡み合った問われ方から離れていくという矛盾です。
この矛盾は避けるのではなく、プロセスに組み込んで扱います。分解は必要ですが、再結合も必要です。再結合を担うのが、差分統合(究極カンペへの統合)とテストデータ(初見セット)です。
領域横断型問題の例
実在の過去問は引用せず、問われ方の感覚が伝わるように、例題として示します。
問いがそもそも領域横断
ある画像分類モデルを業務に導入し、誤判定が事故につながる可能性があります。次のうち、優先して見直すべき組み合わせとして最も適切なものはどれですか。
- A:学習率の調整とデータ拡張
- B:評価指標の選び直しと運用時の監視設計
- C:層の数の増加と活性化関数の変更
- D:分散の正則化とバッチサイズの変更
このタイプは、モデルだけでは解けません。評価・運用・リスクが絡みます。暗記や単発の用語理解だけだと、正しい方向へ寄せにくいです。究極カンペ側に「評価→運用→リスク」の接続が必要になります。
問いはシンプルなのに選択肢が領域横断
過学習を抑えるために有効な方法として最も適切なものはどれですか。
- A:学習データを訓練用と評価用に分ける
- B:個人情報を含むデータは法令・ガイドラインに沿って適切に扱う
- C:画像の入力解像度を上げる
- D:モデルの推論結果を人間が最終確認する運用にする
問いは単純でも、選択肢が評価設計・法務・運用へ飛びます。問題集が用語単体の正誤に寄るほど、この飛び先に慣れにくく、本番で乖離を感じやすくなります。
例を学習プロセスへ戻す
領域横断型に近づけるために、いきなり難問を増やす必要はありません。誤答の原因がどこで切れたかをタグ付けし、究極カンペへ「つなぎ」を戻します。
- 評価で切れた:評価指標や検証設計の接続を追記します。
- 運用で切れた:監視や再学習、ヒューマンインザループの接続を追記します。
- 法律倫理で切れた:更新レイヤ(個人情報・著作権など)へ接続します。
https://www.ppc.go.jp/personalinfo/
https://www.bunka.go.jp/seisaku/chosakuken/aiandcopyright/
究極カンペ×問題集の学習プロセス
ここからが本題です。問題集は暗記用ではなく漏れ検出器として扱い、差分だけを究極カンペへ統合します。
フェーズ1:枠(スケルトン)
- シラバスと公式テキストの章立てをベースに、究極カンペの器を作ります。
- 空欄が多くてOKです。差分が入る住所を先に作るのが目的です。
https://www.jdla.org/download-category/syllabus/
フェーズ2:訓練データ(書籍問題集/Web無料問題集)
- 書籍問題集またはWeb無料問題集を解きます。
- 誤答は追記せず、まずタグ付けします。
- タグ例:概念未理解/混同/例外条件/用語抜け/評価設計/運用/法律倫理
- 書籍は枠内強化、Web無料は周回と量が得意です。どちらでもよいので回し、タグの偏りを見ます。
フェーズ3:差分統合(再結合)
フェーズ3は、分解して学んだ知識を領域横断に戻す工程でもあります。
- 構造の穴(混同・境界・因果)は究極カンペに統合します。
- 面の穴(用語抜け・網羅不足)は用語集カンペで補正します。
- 追記は用語を増やすより、条件+差分の形に寄せます。
- 何が(対象)→ いつ(条件)→ どうなる(結論)→ どこが落とし穴(例外・境界)
フェーズ4:別のクセを当てる(揺さぶり)
- フェーズ2で使った素材と別タイプを当てます。
- 目的は新規知識の追加よりも、例外・境界条件・問われ方の揺さぶりを拾うことです。
- 公式例題・過去問題を当て、基準点を確認するのも有効です。
https://www.jdla.org/certificate/general/issues/
フェーズ5:テストデータ(Web模試の温存)
- Web模試はできるだけ未使用のセットとして残し、最後に実施します。
- 模試が少ない場合でも、章単位で未実施の領域を作るなど、初見セットを確保します。
- 失点は覚え不足より体系の穴(例外・境界・混同)の可能性が高いので、タグ付け→差分統合→再テストで仕上げます。
タイプ別の入れ込み位置
迷ったときの行動指針です。
- 書籍問題集:フェーズ2(訓練データ)で回し、解説から混同・境界・因果の差分を回収します。
- Web無料問題集:フェーズ2(訓練データ)で量を回し、タグ頻度から重要度配分を調整します。
- Web模試:フェーズ5(テストデータ)で温存し、初見耐性と過学習を測ります。
- その他(公式):フェーズ1とフェーズ4で使い、範囲と基準点を固定します。
https://www.jdla.org/download-category/syllabus/
https://www.jdla.org/certificate/general/issues/
失速パターン別の調整
点が伸びない(頭打ち)
量を増やす前に、タグの偏りを見ます。例外条件や混同が多いなら、究極カンペ側の境界の追記が足りていません。用語を増やすより「見分ける条件」を追記します。
点が乱高下する
訓練データとテストデータが混ざっている可能性があります。未使用セットを作り、同じ条件で定点観測します。
法律倫理・動向で落ちる
本文に溶かし込むより更新レイヤとして隔離し、差分更新できる形にします。起点は公的情報に置きます。
https://www.ppc.go.jp/personalinfo/
https://www.bunka.go.jp/seisaku/chosakuken/aiandcopyright/
まとめ
究極カンペは体系化に強い一方、例外・境界条件の漏れ抜けが残りやすいです。問題集・模試を漏れ検出器として工程に組み込み、差分だけを究極カンペへ統合すると、厚みを増やさずに精度だけ上げられます。
また、問題集は構造上、領域横断型を入れ込みにくいという弱点があります。分解だけで終わらせず、差分統合とテストデータで再結合することで、本番の問われ方へ戻しやすくなります。
- 問題集は暗記用ではなく漏れ検出器として扱います。
- 書籍/Web無料/Web模試のクセに合わせ、訓練データとテストデータを分けます。
- 領域横断は差分統合で再結合し、テストデータで初見耐性を測ります。
合わせて読むことをおすすめな記事
補足:漏れ抜けを定量化する簡易モデル(読み飛ばしOK)
数式モデルは補足です。読まなくても記事は成立します。
カバー率を $C$(0~1)として、1周回の学習で増える分と忘却で減る分を置くと、次の形でイメージできます。
$C_{k+1}=C_k+\alpha(1-C_k)-\beta C_k$
$\alpha$ は差分統合の効率、$\beta$ は忘却・混同の強さです。式の正しさよりも、差分統合の効率が伸び方を決め、テストデータでズレを検出して調整するという構造を掴むのが目的です。
補足:Pythonで伸び方を可視化(読み飛ばしOK)
Pythonコードは補足です。読まなくても記事は成立します。グラフも見え方の例です。
グラフは表示のみで、ファイル保存はしない前提のコードです。
import matplotlib.pyplot as plt
# 簡易モデル:C_{k+1}=C_k+alpha*(1-C_k)-beta*C_k
alpha = 0.25 # 差分統合の効率
beta = 0.06 # 忘却・混同の強さ
K = 20
C = [0.10]
for _ in range(K):
c = C[-1]
C.append(c + alpha * (1 - c) - beta * c)
plt.figure()
plt.plot(range(K + 1), C, marker="o")
plt.ylim(0, 1.0)
plt.xlabel("cycle")
plt.ylabel("coverage C")
plt.title("Coverage growth (toy model)")
plt.grid(True)
plt.show()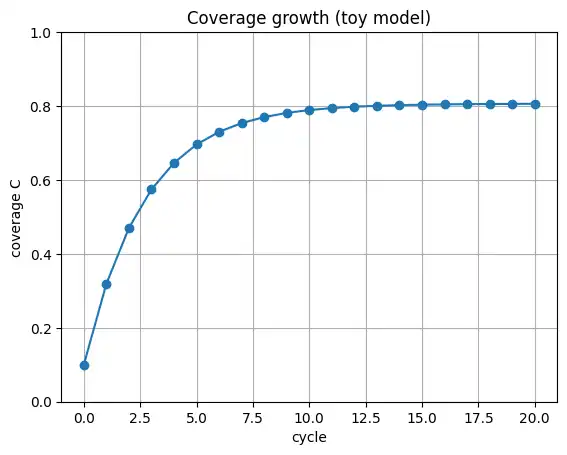
FAQ
問題集の具体名を出していない理由
教材はシラバス更新や運営都合で改版・増減・公開停止が起きやすく、時期によって最適解が変わりやすいです。このページでは具体名に依存せず、書籍/Web無料/Web模試といった性質の違いを前提に、時代に左右されにくい学習プロセスを提示しています。
「究極カンペ」とは結局なにか
このサイトでの呼び名で、G検定対策の知識をつながりで復元できるようにまとめた脳内マップです。暗記表ではなく、背景・因果・境界条件まで含めて理解を保持する状態が特徴です。概要は https://www.simulationroom999.com/blog/g-kentei-ultimate-kanpe-learning-method/ にまとめています。
書籍問題集とWeb無料問題集はどちらを優先すべきか
習慣化と量を優先するならWeb無料問題集が向きやすく、解説の安定感と枠内強化を優先するなら書籍問題集が向きやすいです。どちらでも構いませんが、誤答をタグ付けして差分だけを統合する運用にすると効果が出やすいです。
Web模試はいつ受けるべきか
最後に受けるのがおすすめです。模試はテストデータとして温存し、初見耐性と過学習の有無を測ります。模試が少ない場合は、章単位で未実施を残すなど、初見セットを確保します。
領域横断型に強くなるにはどうすればよいか
問題の難易度を上げるより、誤答の原因がどこで切れたか(評価・運用・法律倫理など)をタグ付けし、究極カンペへ接続を戻すほうが効率的です。分解して学んだ内容を差分統合で再結合し、最後に初見セットで確認します。
法律倫理・動向の扱いはどうすればよいか
変化が速い領域なので、本文に溶かすより更新レイヤとして隔離し、差分更新できる形にします。起点は公的情報に置きます。
https://www.ppc.go.jp/personalinfo/
https://www.bunka.go.jp/seisaku/chosakuken/aiandcopyright/
参考文献
- JDLA シラバス:https://www.jdla.org/download-category/syllabus/
- JDLA G検定 例題・過去問題:https://www.jdla.org/certificate/general/issues/
- 個人情報保護委員会(個人情報保護法・ガイドライン等):https://www.ppc.go.jp/personalinfo/
- 文化庁(AIと著作権):https://www.bunka.go.jp/seisaku/chosakuken/aiandcopyright/
目的別おすすめ書籍(カテゴリ別)
ここは「学習設計図」の補助として、骨格づくりに相性が良い書籍をカテゴリで紹介します。版や追従状況は更新されるため、購入時は最新版・対応シラバスを確認してください。
公式テキスト(骨格の基準点)
深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト

→ 骨格づくりの「基準点」。用語の定義や範囲の境界を揃える用途に向きます。
書籍問題集(枠内強化)
徹底攻略ディープラーニングG検定ジェネラリスト問題集

→ 反復の主力。間違いを「骨格のどこに追記するか」で扱うと伸びが安定します。
生成AI・LLM(新しめの論点の理解)
大規模言語モデル入門

→ Transformer周辺を「用語」ではなく「流れ」で理解したい人向けです。
法律(生成AIの実務リスクの地図)
ゼロからわかる生成AI法律入門

→ 直前に詰め込みにくい領域を、更新レイヤとして整理する用途に向きます。
ガバナンス
AIガバナンス入門: リスクマネジメントから社会設計まで

数学
ディープラーニングがわかる数学入門

→ 数式を暗記せず、意味が追える状態にするための補助線として使えます。
実装で腹落ち(余裕がある人向け)
ゼロから作るDeep Learning

→ 「理解はしたが、結局なにが起きている?」を実装で回収したい人向けです。


コメント