
「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
※G検定の試験概要・具体的な勉強ステップ・無料700問問題集は、

にまとめています。
その他のエッセイはこちら

2024年版シラバスで追加された項目の詳細は以下の記事参照

合わせて読むことおすすめの記事


この文章でやりたいこと(G検定 勉強法 2026/シラバス攻略のねらい)
これは誰に向けた話か
この文章は、とくに次のような人をイメージして書いています。
- ChatGPT や画像生成AIは日常的に触っている
- そろそろ G検定も取りたいと思っている
- でも 公式テキストを第1章から読み始めて、どこかで挫折した経験がある
あるいは、
- 「AIの歴史」「数理・統計」「機械学習のアルゴリズム説明」あたりで足踏みしてしまい、
応用や法律・倫理までたどり着いていない
という人にも、そのまま当てはまると思います。
検索から来た方へ:「G検定 勉強法 2026」「G検定 勉強法 2025」「G検定 シラバス 改訂 2024」など
「G検定 勉強法 2026」「G検定 勉強法 2025」「G検定 シラバス 改訂 2024」
「G検定 どこから 勉強」「G検定 シラバス 攻略」
といったキーワードで検索して来た方も多いはずです。
この文章は、そうした検索ニーズに対して、
- 「G検定はどこから勉強を始めると挫折しにくいか」
- 「2024のシラバス改訂で“今寄り”になったところはどこか」
- 「生成AI時代に合わせた、現実的な G検定勉強法(2026年版) はどんな形か」
をまとめて整理することを狙っています。
この文章でやりたいこと(G検定シラバス攻略のゴール)
JDLA の G検定にはシラバスがあり、2024年11月実施の「G検定2024 #6」から
改訂版シラバスが適用されています。これに合わせて、公式テキスト第3版も刊行されました。
公式テキスト第3版の目次は、たとえば次のようになっています。
- 第1章:人工知能(AI)とは
- 第2章:人工知能をめぐる動向
- 第3章:機械学習の具体的手法
- 第4章:ディープラーニングの概要
- 第5章:ディープラーニングの要素技術
- 第6章:ディープラーニングの応用例
- 第7章:AIの社会実装に向けて
- 第8章:AIの法律と倫理
- Appendix:事例集 産業への応用
出題範囲としては、ここに 数理・統計の基礎 も加わります。
この並び自体はとてもよくできていますが、
「学ぶ側の頭の動き」として、本当にこの順番が自然か?
というと、少し事情が変わってきます。
この文章は、厳密な「模範的勉強計画」ではなく、
どこから読めば挫折しにくく、結果的に合格に近づけそうか を考える
生成AI時代のG検定勉強法=シラバス攻略エッセイ です。
そして最初にハッキリさせておくと、これは
「何時間で受かるか」「どの問題集を何周すればいいか」といった“合格テクニック大全”ではありません。
ここでは主に 「公式テキストやシラバスを、どの順番で読めば挫折しにくいか」
という「読み方の設計」だけを扱います。
細かい問題演習の話や教材レビューは、別の記事に回す前提です。
具体的には、G検定シラバスを
- 時間軸(昔 → 今)
- 自分事軸(どれくらい「自分の今」と重なるか)
の2軸と、さらに
- 生成AI登場あたりにある“小さな崖(臨界点)”
という観点から眺め直して、
- 「先頭から読む」王道ルート
- 「今から読む」逆向きルート
の 2パターンの勉強法(どこから勉強するか) を整理します。
そのうえで、
- ビジネス職/エンジニア別の 読み順サンプル
- おまけとして 「30日ミニプラン」
も載せておきます。
シラバスの順番は、本当に自分にとって自然か?
(G検定 シラバス攻略の入口)
G検定の改訂シラバスと公式テキスト第3版をざっくりまとめると、次のカテゴリになります。
- 歴史(人工知能とは/人工知能をめぐる動向)
- 機械学習
- ディープラーニング(概要・要素技術・応用)
- 応用(事例集・産業への応用)
- 社会実装(AIプロジェクト・運用・ガバナンス)
- 数理・統計(出題範囲としてカバー)
- 法律・倫理(AIの法律・AI倫理・AIガバナンス)
「歴史 → 基礎 → 応用 → 社会 → 法律・倫理」という、
教科書としてはとても王道な並びです。
一方で、学ぶ側の頭の中は、必ずしもこの順番どおりには動きません。
- 歴史を読んでいても、頭の中はすでに ChatGPT や画像生成のことでいっぱい
- 数学や機械学習の説明で一度止まってしまい、そのまま本を閉じてしまう
- 法律・倫理を「巻末の付録」のように感じて読み飛ばしてしまう
……ということは、かなりよく起きているはずです。
ここで、少し発想を変えてみます。
かなり思い切って言うと、テキストを先頭から読むよりも、
「今の自分に一番近い話」から読んだ方が、筋がいい人もたくさんいるのではないか。
この「今の自分に近い」を、後で 自分事軸 と呼ぶことにします。
時間軸でざっくり眺める
(G検定 シラバス 改訂 2024/2025/2026 を俯瞰)
まずは 時間軸 です。
「これはだいたい、いつ頃の話なのか?」
という視点で、G検定シラバスに出てくる代表的なトピックを
ざっくり並べ直してみると、図1のような感じになります。
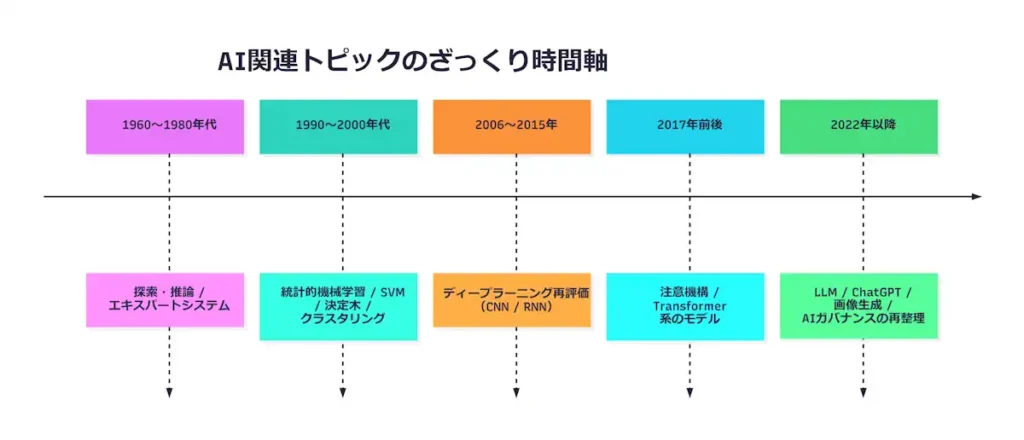
ここで厳密な年号を覚える必要はありません。
- 古典AI(探索・推論・エキスパートシステム)
- 統計的機械学習
- ディープラーニング(CNN/RNN)
- 注意機構・Transformer 系のモデル
- LLM・生成AIと、それに対する法律・倫理の議論
という 流れのイメージ さえ持てれば十分です。
時間軸で見直すと、
- 前半(歴史・古典的な機械学習)は 1960〜2000年代くらいの話が中心
- 中盤(ディープラーニング・応用)は 2000年代後半〜2010年代の話が中心
- 後半(社会実装・法律・倫理)は 2020年代の状況が色濃く反映されるゾーン
という切り分け方もできます。
AIとの距離が一気に縮まった「今」
少し前までは、AI に触れるにはそれなりの専門性が必要でした。
- ライブラリを入れてコードを書く
- 学習データを集める
- 場合によっては GPU を用意して環境を整える
といった準備をしないと、そもそもモデルを動かしてみることすら難しい時期がありました。
ところが今はどうでしょうか。
- ChatGPT のような LLM
- 各種の画像生成モデル
- その他の生成AIサービス
を、ブラウザやスマートフォンから いきなり触れます。
ChatGPT は 2022年11月30日に公開され、そこから一般利用が一気に広がりました。
- 「ちょっと試しに文章を生成してみる」
- 「プロンプトを打ち込んで画像を作ってみる」
といった体験は、もはや技術者だけのものではありません。
同時に、生成AIの 悪用に関するニュース も増えました。
- 著作権やトレーニングデータを巡るトラブル
- 本人になりすました音声・画像・動画(ディープフェイク)
- 差別的なアウトプットや虚偽情報の拡散
こういった話題が、一般向けニュースでも頻繁に取り上げられています。
国際的にも、OECD の AI原則や、UNESCO の「AI倫理に関する勧告」など、
AIの倫理・ガバナンスに関する枠組み作りが進んでいます(詳細は参考文献参照)。
つまり今の私たちは、
- 「すごく便利」な側面 と
- 「けっこう危ないかもしれない」側面
の両方を、日常的に目にしながら暮らしているわけです。
自分事軸:どれくらい「今の自分」に刺さるか
ここで、もう一つの軸である 自分事軸 を導入します。
「これは、自分の今の生活・仕事・関心に、どれくらい直結しているか?」
を、0〜1 くらいのスコアでざっくりイメージしてみます。
例として、次のような感覚の人は多いかもしれません。
- LLM・生成AI(ChatGPT など):自分事スコア ≒ 0.9
- 画像生成:0.8
- 画像認識(カメラ検査、顔認証など):0.7
- 統計的機械学習(回帰・分類):0.6
- 古典AIのパズルや探索アルゴリズム:0.3
もちろん人それぞれですが、
「今に近い話ほど自分事として重く感じやすい」 傾向は、
だいたい共有できる感覚ではないでしょうか。
生成AI登場あたりにある「小さな崖」
ここで、時間と自分事の関係を、ざっくり “曲線”としてイメージ してみます。
※ここから先は、数式や Python コードが好きな方向けの「おまけ」です。
雰囲気だけつかめれば十分なので、読み飛ばしていただいても問題ありません。
「AIが自分事に感じられる度合い」を時間 $t$ の関数 $S(t)$ として、
$$
S(t) = \frac{1}{1 + e^{-k(t – t_0)}}
$$
のような ロジスティック関数 の形でイメージしてみます。
- $t_0$:生成AIが一気に一般化したあたりの時間(ざっくり 2022年前後)
- $k$:立ち上がりの急さ(ここ数年の「話題の増え方」の急激さ)
Python で軽く遊んでみると、こんな感じです。
import numpy as np
import matplotlib.pyplot as plt
def selfness(t, k=1.3, t0=2022.0):
"""Year t における『AIが自分事に感じられる度合い』のざっくりモデル"""
return 1 / (1 + np.exp(-k * (t - t0)))
# なめらかな曲線用の年範囲
years = np.linspace(2000, 2030, 300)
values = [selfness(y) for y in years]
# サンプル点(元コードと同じ)
sample_years = [2000, 2010, 2015, 2020, 2022, 2023, 2024]
sample_values = selfness(np.array(sample_years))
plt.figure(figsize=(8, 5))
# 曲線
plt.plot(years, values, label="selfness(t)")
# サンプル点
plt.scatter(sample_years, sample_values)
# サンプル点の上に年を表示(数字のみ)
for x, y in zip(sample_years, sample_values):
plt.text(x, y + 0.03, f"{x}", ha="center", va="bottom", fontsize=8)
# NOTE: タイトル・軸ラベルは英数字だけにしておくと文字化けしにくい
plt.title("AI selfness model")
plt.xlabel("Year")
plt.ylabel("Selfness (conceptual)")
plt.legend()
plt.xlim(2000, 2030)
plt.ylim(-0.05, 1.05)
plt.grid(True)
plt.tight_layout()
plt.show()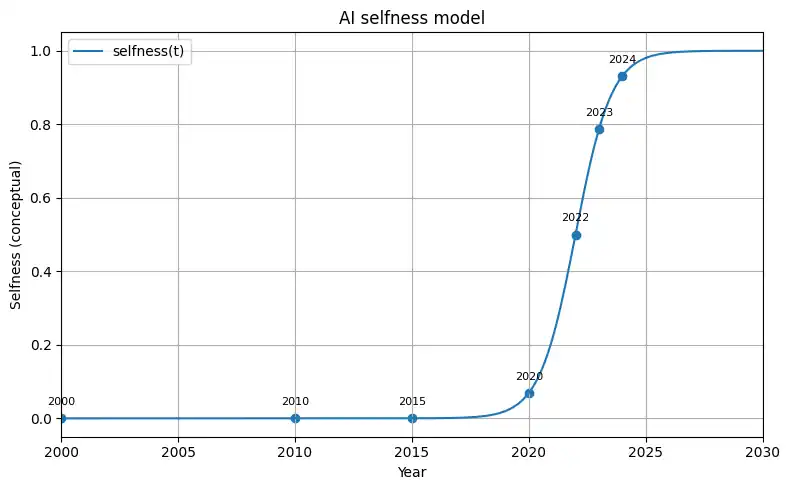
実際のデータではなく、あくまで イメージ図 ですが、
- 2010年くらいまでは、自分事度はじわじわ上がるだけ
- 2020年くらいから傾きが少し大きくなり
- 2022年(ChatGPT が一般公開された頃)あたりで、
一段急に立ち上がる“小さな崖(臨界点)” がある
と考えると、感覚的にはかなりしっくりきます。
この崖の こちら側 にいるのが、今の私たちです。
- 日常的に LLM や画像生成を触れる
- そのリスクや法律・倫理の問題がニュースとして流れてくる
という世界を、すでに「空気」のように吸っている状態です。
その崖を少し分解すると、Transformer が顔を出す
(ミニ“逃げ道”付き)
この「一段急に立ち上がっている部分」を、もう少しだけ分解してみます。
今の生成AI(LLM や画像生成モデル)の根幹技術として、
多くの場合で名前が挙がるのが Transformer です。
2017年の論文 “Attention Is All You Need” で提案されたアーキテクチャで、
現在の多くの LLM の基礎になっています。
Transformer 自体は、
- 線形変換(全結合層)
- 非線形活性化関数
- 正規化
- 残差接続
といった要素の組み合わせなので、
パーツだけを見ると「ニューラルネットワークの一種」にすぎません。
ただし、構造 の部分が従来のモデルとはかなり違います。
- CNN:画像の「近くのピクセルだけ」を見る畳み込みを重ねて、
少しずつ広い範囲の文脈を取り込んでいく - RNN:系列データの「一つ前」だけを見ながら、
時間方向に少しずつ文脈を広げていく - Transformer:最初から すべての位置同士が互いを見合う 自己注意(Self-Attention) を前提にして文脈をつかみに行く
という違いがあります。
ざっくりした構造イメージは、こんな感じです。
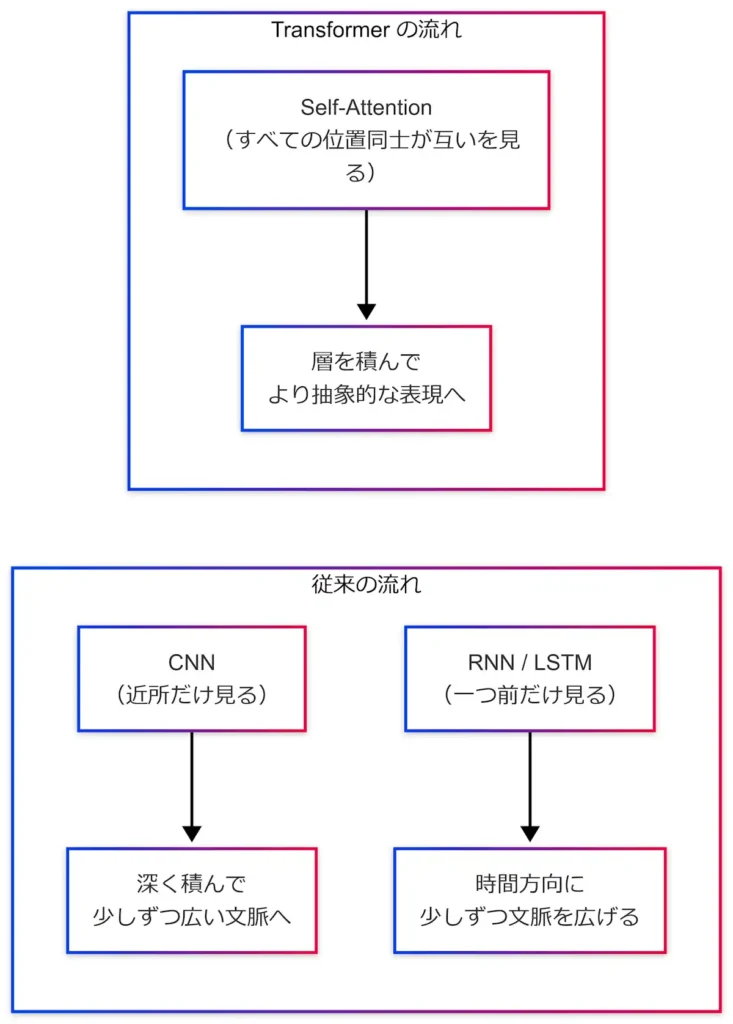
この構造の違いが、
- 長い文章や複雑な依存関係を扱いやすい
- 並列計算と相性が良く、大規模化しやすい
といった性質につながり、現在の LLM ブームの土台になっています。
G検定の新シラバスでも、
- 注意機構(Attention)
- Transformer
- 基盤モデル/大規模言語モデル(LLM)
といったトピックが追加・強化されており、
公式テキスト第3版では、ディープラーニングの要素技術や応用例の章で
これらがまとまって扱われています。
ここは、学習者にとっても小さな「崖」になりやすいポイント です。
- 機械学習・ディープラーニングの基礎までは、
「入力 → 特徴抽出 → 判定」という流れの延長線上としてイメージしやすい - Transformer あたりで、
- クエリ・キー・バリュー
- マルチヘッド注意
- 位置エンコーディング
といった 新しい用語と発想 が一気に出てくる
その結果、
- 「ここだけ急に難しく感じる」
- 「なんとなく乗り越え損ねる」
という意味で、技術的にも学習上も“臨界点”になりやすい のです。
実際にテキストを開いたとき、
- 第5章の中の 「トランスフォーマー関連の節」
- 第6章の 「事前学習モデル(GPT/BERT など)の節」
あたりが、「あ、ここだよね…」と感じる典型的な崖ゾーンだと思います。
ただし、応用レベルでざっくり理解するだけなら、
「文や画像の中で、どの部分同士がどれくらい重要な関係にあるかを、
モデルが柔軟に学習できるしくみ」
くらいのイメージでも、十分に前に進めます。
しかるべきタイミングで戻ってきて、改めてじっくり読む、というスタンスでも問題ありません。
Transformer 崖ゾーンの“ミニ逃げ道”
「いや、それでも Transformer まわりで止まりそう…」という場合は、
ひとまず次の 「最低限ライン」 だけ押さえるつもりで読んでしまっても大丈夫です。
- 第4章(DL概要)では
- 「ニューラルネットワークの基本構造」と
- 「畳み込み(CNN)」「再帰(RNN)」の役割イメージ
の説明と図だけは押さえる
- 第5章(要素技術)では
- Attention/Transformer の節の 最初の概念説明と構造図 だけ眺める
- クエリ・キー・バリューの式は「そういう値を計算しているのね」くらいで流す
- 第6章(応用例)では
- 「事前学習モデル」「BERT」「GPT」あたりの
“事前学習 → ファインチューニング”の流れの図 を押さえる
- 「事前学習モデル」「BERT」「GPT」あたりの
細かい式や派生モデルの名前まで覚えるよりも、
「Attention/Transformer の章に
“崖の入り口がある”とだけ分かっていて、
あとから戻って来られる状態にしておく」
ことの方が、合格に対してはずっと重要です。
機械学習・強化学習の章で「足踏み」しないために
(G検定 勉強法の落とし穴と“逃げ道”)
ここで、もう一つの「足踏みポイント」についても触れておきます。
実際のところ、
- 機械学習の章(第3章)
- 強化学習(第3章・第6章の一部)
は、仕組み寄りの内容 が多く、どうしても情報量が増えがちです。
- アルゴリズムのステップ(勾配降下法、Q学習など)
- 損失関数や評価指標の式
- 行動価値関数・方策・割引率…といった用語の洪水
こうした内容はとても重要ですが、
これをすべて理解していないと、
ディープラーニングや生成AIの応用例がまったく分からないかというと、
そうでもありません。
むしろ現実には、
- 機械学習の章で立ち止まってしまう
- 強化学習の数式で「一度心が折れる」
- その結果、応用や法律・倫理までたどり着く前に疲れてしまう
というパターンの方が多いかもしれません。
ここで、一つ割り切り方の提案です。
「応用例をざっくり理解するだけなら、
機械学習・強化学習のメカニズムは“あとで戻ってくればいい”」
たとえばディープラーニングの画像認識であれば、
- 「画像 → 特徴抽出 → クラス判定」という大まかな流れ
- 誤分類すると困る場面や、精度をどう測るか
がイメージできれば、
「現場で何が起きているか」を理解するには十分です。
そのうえで、
- 「なぜその特徴抽出がうまくいくのか」
- 「なぜその最適化が収束すると期待できるのか」
が気になってきたときに、
あらためて機械学習や強化学習の章に戻ってくる、という読み方でも構いません。
機械学習・強化学習ゾーンの“ミニ逃げ道”
こちらも、最低限これだけ押さえて先に進めばOK、という 逃げ道ライン を書いておきます。
- 第3章(機械学習)では
- 「教師あり学習/教師なし学習/強化学習」の違いの説明
- 線形回帰・ロジスティック回帰・決定木あたりの 例としてのイメージ
- 評価指標(正解率・再現率・F値 など)の グラフや図
だけは押さえる(式は追いきれなくてもよい)
- 強化学習の節では
- 「エージェント」「環境」「報酬」という3つの言葉
- 「試行錯誤しながら報酬が最大になるように行動を学ぶ」
というストーリー部分 - 図に描かれた矢印(エージェント⇔環境⇔報酬)の流れ
を確認して、細かいアルゴリズムの擬似コードは一旦飛ばす
このくらいでも、実務やニュースで出てくる
「教師あり学習」「強化学習」「報酬設計」といった言葉の意味は十分つかめます。
G検定はどこから勉強するか?
── 先頭から読むか、それとも「あえて今から」読むか
ここまでを整理すると、次のようになります。
- 時間軸 で見ると、G検定シラバスは昔→今へと整然と並んでいる
- 自分事軸 で見ると、生成AI登場(LLM・画像生成)あたりに小さな「崖」があり、
そこから先(応用・社会実装・法律・倫理)の自分事度が一気に上がっている - 機械学習・強化学習、そして Transformer 付近は、
内容的にも学習上の臨界点になりがち
これを踏まえると、「G検定はどこから勉強するか?」 という問いに対して、
読み方の選択肢は少し増やせます。
王道ルート(前から順に読む)
- 歴史
- 機械学習
- ディープラーニング
- 応用
- 社会実装
- 数理・統計
- 法律・倫理
と、シラバスどおりに前から読むルートです。
- 全体像を体系的に押さえやすい
- 「どこに何が書いてあるか」を覚えやすい
といったメリットがあります。
今からルート(巻末側から入って前に戻る)
もうひとつのルートは、今の自分に一番近いところから入る 方法です。
- まず、生成AI・応用・社会実装・法律・倫理といった
「いま自分がニュースや業務で見ているゾーン」 をざっと眺める - 「なぜこうなっているのか?」が気になったタイミングで、
ディープラーニング → 機械学習 → 数理・統計 → 歴史と、前提側に遡る
という読み方です。
今の私たちはすでに生成AIの“崖”のこちら側に立っているので、
- 「今の体験」(生成AIやそのリスク)を入口にする
- そこから G検定シラバスを過去へと遡る
という読み方は、以前よりずっと自然なルート になっていると言えます。
おすすめ読み順サンプル
(生成AI時代のG検定勉強法)
最後に、もう一歩だけ具体的な「読み順サンプル」を置いておきます。
あくまで一例ですが、迷ったときのスタート地点として使えると思います。
生成AI時代のG検定勉強法:ビジネス職向け(非エンジニア)
| ステップ | 読む章・カテゴリ | ねらい |
|---|---|---|
| 1 | 第6章 応用例+Appendix 事例集 | 自分の業界や仕事との接点をまずつかむ |
| 2 | 第7章 AIの社会実装に向けて | プロジェクトの進め方・役割分担の感覚を持つ |
| 3 | 第8章 AIの法律と倫理 | リスクと責任の輪郭を押さえる(自分事化しやすい) |
| 4 | 第4章 ディープラーニング概要 | 「中で何をしていそうか」をざっくり知る |
| 5 | 第3章 機械学習(代表的な手法だけ) | 用語と雰囲気だけでもつかんでおく |
| 6 | 数理・統計(別資料や問題集で補う) | 評価指標やグラフの読み方に必要な最低限を押さえる |
| 7 | 第1〜2章 歴史・動向 | 余裕が出てきたら、全体の文脈を振り返る |
生成AI時代のG検定勉強法:エンジニア/技術寄り向け
| ステップ | 読む章・カテゴリ | ねらい |
|---|---|---|
| 1 | 第4章 ディープラーニング概要 | CNN/RNN/Attention/Transformer の輪郭を先に知る |
| 2 | 第5章 ディープラーニングの要素技術 | 特に「トランスフォーマー関連の節」をざっくり読む |
| 3 | 第6章 応用例(事前学習モデルなど) | BERT/GPT など生成AI寄りの話を押さえる |
| 4 | 第3章 機械学習 | 回帰・分類・評価指標など、DL以前の土台を補強 |
| 5 | 数理・統計 | 必要に応じて戻りながら、最低限の数理を固める |
| 6 | 第7章 社会実装 | 実務のプロジェクトの流れ・役割をイメージ |
| 7 | 第8章 法律と倫理 | 技術者として関わるときの注意点を押さえる |
どちらのルートでも、
- 最初の2〜3ステップは「読みやすくて自分事度の高いところ」だけに絞る
- 「必要になったとき」「気になったとき」に、数理や歴史側へ戻る
くらいの軽さでシラバスを使ってみると、挫折しにくくなると思います。
30日ミニプラン(ビジネス職向けサンプル)
最後に、「とりあえず1か月で一周してみたい」という方向けに、
上の読み順をざっくりカレンダーに落とした 30日ミニプラン を置いておきます。
※平日は 30〜60分/日、週末は 2〜3時間取れるイメージです。
すべてを完璧に理解する前提ではなく、「一周して全体像をつかむ」ためのプランです。
1週目:今側をざっと眺める(自分事ゾーン)
- 第6章 応用例+Appendix 事例集
- 第7章 AIの社会実装に向けて
- 第8章 AIの法律と倫理
→ 「自分の業務との接点」「ガバナンス・リスク」「最近ニュースになっている論点」を
ざっくりつかむ週です。
2週目:ディープラーニングと Transformer 崖ゾーンの入口
- 第4章 ディープラーニング概要
- 第5章 ディープラーニングの要素技術のうち
- 畳み込み/RNN の概要
- Attention/Transformer の冒頭と図(前述の“ミニ逃げ道”ライン)
→ 「中で何をしていそうか」と「崖ゾーンの位置」を把握する週です。
詳しい式は読み飛ばしてもかまいません。
3週目:機械学習・数理の最低限を固める
- 第3章 機械学習の代表的な手法・評価指標のイメージ
- 数理・統計(平均・分散・確率分布・回帰のごく基本)を
別資料や問題集で補う
→ 「なぜこんな評価指標を使うのか」「精度グラフの意味」など、
応用を理解するのに必要な最低限を押さえる週です。
4週目:アウトプットと復習
- 市販の問題集や公式問題(もし手元にあれば)で
1日数十問ペースで解いてみる - 間違えた問題だけ、該当する章へ ピンポイントで戻る
- 例:Transformer で落とした → 第5章の図をもう一度眺める
- 法律・倫理で落とした → 第8章の該当節だけ読み直す
→ 「理解 → アウトプット → 戻る」のサイクルを
軽く一周回す週です。
この30日ミニプランは、あくまで “とっかかり”用のたたき台 です。
仕事の忙しさやバックグラウンドに合わせて、
- 6週間に伸ばしてゆっくり回す
- 逆に2〜3週間で一周してから、2周目に細部を詰める
といったアレンジをしていただいてかまいません。
2024/2025/2026 シラバス改訂で「今側」が厚くなったところ
(G検定 シラバス攻略の要点)
ここは公式発表や解説記事をベースに、「今寄り」になったポイントだけをピックアップして整理しています。
JDLA の発表によると、今回の改訂では、
- 基盤モデル・言語モデルなど、生成AIに必要な技術の追加・強化
- AI倫理・AIガバナンスを含む社会実装・運用面の強化
- 歴史・機械学習・ディープラーニングの体系の見直し
が行われています。
公式テキスト第3版ベースで、「今側」が厚くなった例を挙げると:
- ディープラーニング関連の章で、
- 注意機構(Attention)
- Transformer
- 事前学習モデル(BERT や GPT などの LLM を含む)
が、まとまった形で解説されている
- 応用例の章では、
- 画像認識・自然言語処理に加え、
- データ生成(生成モデル) など、最近のトピックが明確に押さえられている
- 社会実装・法律・倫理の章では、
- モデルのライフサイクル管理、ヘルスモニタリング
- 国内外の AI ガイドラインや原則(OECD AI 原則や国際的な倫理勧告など)
に対応する形で、ガバナンス面の解説が強化されている。
これらはまさに、
- ニュースでよく見る話題
- 職場で今後関わる可能性が高い話題
と直結している「自分事度の高いゾーン」です。
逆にいうと、
「どこから読めば合格に近づきやすいか?」という観点では、これら“今寄り”のトピックから入るのは十分アリ
ということでもあります。
まとめ:自分の「今」からシラバスを組み替えてみる
(2026年向けG検定勉強法の結論)
最後に、ポイントだけ改めてまとめます。
- G検定シラバスは、「歴史〜法律・倫理」までをきれいに並べてくれている
- しかし、学ぶ側の頭は
- 時間軸(昔→今)
- 自分事軸(どれくらい今の自分に刺さるか)
によって、少し違った順番で動く
- 生成AI登場あたりに 小さな「崖(臨界点)」 があり、
その崖の中身を分解すると Transformer や LLM が顔を出す - 機械学習・強化学習・Transformer 付近は、内容的にも学習上の臨界点になりがちなので、
応用や法律・倫理を先にざっくり押さえてから戻ってくる、という戦略も十分アリ - 入口としては、
- シラバスどおり前から読む「王道ルート」
- 今の自分に近い章から読んで前提へ遡る「今からルート」
の2パターンを、状況に応じて使い分けるのが現実的
- 改訂シラバスでは、Attention・Transformer・LLM・AIガバナンスなど、
“今側”のトピックがはっきり厚くなっている
G検定シラバスの並びを否定するのではなく、
「自分の今」から見て、どこから入ると歩きやすいか?
という観点で、時間軸と自分事軸、そして小さな崖を意識して眺めてみると、
同じ目次でも、少し違った景色が見えてくるはずです。
それがそのまま、自分なりの勉強順=G検定勉強法=シラバス攻略法 につながっていきます。
FAQ
Q1. G検定シラバスはどんなカテゴリで構成されていますか?
A1. 現行の G検定シラバス(2024年11月以降)および公式テキスト第3版では、技術分野として「人工知能とは」「人工知能をめぐる動向(歴史・動向)」「機械学習の具体的手法」「ディープラーニングの概要・要素技術・応用例」「AIの社会実装に向けて」などがあり、法律・倫理分野として「AIの法律と倫理」「AIガバナンス」に相当する内容がまとめられています。出題範囲としては数理・統計の基礎も含まれます。
Q2. なぜ生成AIの登場が「自分事度の臨界点」になるのですか?
A2. 生成AIの登場前は、AIに触れるには専用の開発環境や知識が必要でしたが、ChatGPT のようなサービスが登場したことで、ブラウザやスマホから誰でも強力なモデルに触れられるようになりました。 その結果、「AIは専門家のもの」から「自分の生活や仕事のすぐそばにあるもの」へと認識が一気に変わり、自分事度がロジスティック関数のように急激に立ち上がった、とイメージすると分かりやすくなります。
Q3. Transformer は G検定の学習においてなぜ“崖”になりやすいのですか?
A3. Transformer は構成要素としてはニューラルネットワークの一種ですが、「すべての位置同士が互いを見合う自己注意」を前提にした構造であり、従来の CNN や RNN とは発想が大きく異なります。 G検定シラバスでも Attention/Transformer/LLM 周辺のキーワードが追加・強化されており、公式テキスト第3版ではディープラーニングの要素技術や応用例の中で、これらがまとまって登場します。そのため新しい用語や概念が一気に増え、学習者にとって内容的な「崖」になりやすいポイントです。
Q4. 機械学習や強化学習の章でつまずいた場合、どうしたらよいですか?
A4. 機械学習や強化学習の章はアルゴリズムや数式など仕組み寄りの説明が多く、最初の読み下しで完璧に理解しようとすると足踏みしがちです。応用例や生成AI、法律・倫理の章を先にざっくり読んで「何が問題になっているのか」「どんな場面で使われているのか」を掴んでから、必要に応じて基礎側に戻ってくるという読み方も十分にありです。大事なのは「止まらないこと」であって、「最初からすべてを理解し切ること」ではありません。
Q5. 結局、G検定のシラバスはどこから読むのがおすすめですか?
A5. 一つのおすすめは、「今の自分が一番気になっているところ」を入口にすることです。生成AIや法律・倫理に関心が強ければ巻末側から、ディープラーニングの仕組みに興味があればそのあたりから入ってもよく、そこから「なぜそうなっているのか?」をたどる形で機械学習・数理・歴史へ戻っていくルートも自然です。もちろん、王道としてシラバスどおりに頭から読むルートも有効なので、自分のモチベーションが続きやすい順番を選ぶのがよいでしょう。
「引用は出典リンク必須・必要最小限」「FAQ全文転載・図表転載は禁止」「社内資料/研修利用は要連絡」
参考文献(公式情報・一次情報を優先)
- 一般社団法人日本ディープラーニング協会(JDLA)
「『G検定(ジェネラリスト検定)』シラバス改訂および公式テキスト第3版刊行のお知らせ」
https://www.jdla.org/news/20240514001/ - 翔泳社/SEshop
「深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト 第3版」書誌情報・目次
https://www.seshop.com/product/detail/26217 - Ashish Vaswani et al.
“Attention Is All You Need”, NeurIPS 2017(arXiv)
https://arxiv.org/abs/1706.03762 - OECD
“AI principles | OECD”
https://oecd.ai/en/ai-principles - UNESCO
“Recommendation on the Ethics of Artificial Intelligence”
https://www.unesco.org/en/articles/recommendation-ethics-artificial-intelligence - OpenAI
“Introducing ChatGPT”(OpenAI公式ブログ、2022年11月30日)
https://openai.com/index/chatgpt/
もっと具体的な試験概要や勉強ステップ、無料700問問題集までまとめた
もあります。あわせてどうぞ。
その他のエッセイはこちら
G検定

G検定 問題集

AI白書

G検定 法律


コメント