その他の数理的なエッセイはこちら

- 試作と探索の初速を大きく上げる開発スタイル
- 同じ強みが、理解不足と保証不足も招く
- 本番では、境界設計と人間の責任が欠かせない
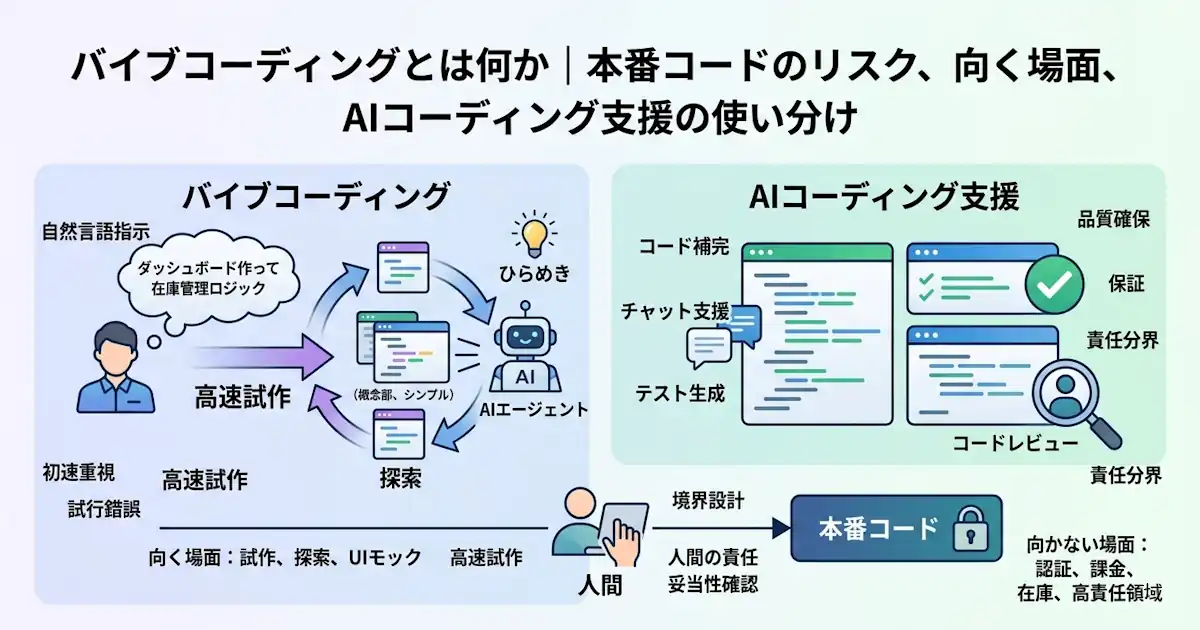
バイブコーディングとは
バイブコーディングとは、生成AIやコーディングエージェントに自然言語で指示しながら、実装、修正、調査、テスト、試行錯誤を高速に回す開発スタイルです。手でコードを書く比率を下げ、意図を言葉で渡し、返ってきた結果を見ながら軌道修正する比率を上げるやり方、と捉えるとわかりやすいです。
GitHub Docs の Vibe Coding チュートリアルでも、コードを自分で細かく書き切るのではなく、自然言語で指示しながらアプリを組み立てる進め方が紹介されています。
https://docs.github.com/ja/copilot/tutorials/vibe-coding
一方で、その適性は概念実証、ドラフトづくり、個人利用アプリに向きやすいとされており、経験豊富な開発者が常にこの進め方を主軸にする前提で書かれているわけではありません。
つまり、バイブコーディングは「すべての開発を置き換える標準手法」というより、「探索や初動を高速化する強力なモード」と理解した方が実態に近いです。
AIコーディング支援との違い
AIコーディング支援は、コード補完、チャット、テスト生成、コードレビュー、エージェントによる pull request 作成まで含めた、道具全体を指す広い言葉です。
一方、バイブコーディングは、その道具を使いながら自然言語主導で高速に作って回す開発スタイルを指します。前者が手段で、後者が使い方の傾向です。
GitHub Docs でも、Copilot は単体テスト生成、テスト失敗の診断、コードレビュー、コーディングエージェントによる pull request 作成まで扱えます。
https://docs.github.com/ja/copilot/tutorials/write-tests
https://docs.github.com/ja/copilot/tutorials/copilot-chat-cookbook/debug-errors/diagnose-test-failures
https://docs.github.com/ja/copilot/concepts/agents/code-review
https://docs.github.com/ja/copilot/how-tos/use-copilot-agents/coding-agent
そのため、AIコーディング支援とバイブコーディングは同義ではありません。AIコーディング支援は道具の総称であり、バイブコーディングはその道具をどう使うかという開発の進め方です。
なぜバイブコーディングが注目されるのか
注目される理由は、試作と探索の速度が目に見えて上がる場面があるからです。従来であれば、要件整理、設計、実装、確認というまとまりで進めていたものを、考える、作る、触る、直す、という細かい往復へ分解できます。
GOV.UK の AI coding assistant trial では、参加者は平均で 1 日あたり 56 分の時間節約を報告しています。特に、情報探索、タスク完了、問題解決の効率化が示されています。
https://www.gov.uk/government/publications/ai-coding-assistant-trial/ai-coding-assistant-trial-uk-public-sector-findings-report
このように、AIコーディング支援は条件が合えば大きな時間短縮につながります。ただし、速く試せることと、業務として正しいことは別問題です。ここを分けて考えないと、探索では強みだったものが、本番では弱点に変わります。
バイブコーディングのメリット
試作と探索の初速が上がる
最大のメリットは、思いついた案をすぐ形にしやすいことです。探索段階では、完成度よりも仮説を早く外せることの方が重要な場合があります。
たとえば簡易ダッシュボードの試作なら、CSV 読み込み、集計、グラフ表示、フィルター追加までを短いサイクルで試しやすくなります。探索段階では、この速さ自体が価値になります。
局所タスクを短時間で形にしやすい
再利用性や抽象化をいったん後回しにして、その場で必要なものを最短で作れるのも強みです。長寿命のきれいな設計より、まず正しく動く局所解の方が合理的なことがあります。
- 一度きりのデータ変換
- 暫定の移行スクリプト
- 検証用 UI
- 運用現場の一時対応
- 実装案の比較用プロトタイプ
こうした作業では、アーキテクチャを広げるより、用途限定の処理を短時間で作った方が価値が出やすいです。
調査、修正、テストの往復を減らしやすい
依存関係の競合、コンパイルエラー、テスト失敗、ログの読み解きといった反復作業を、ある程度まとめて任せやすいのも利点です。
GitHub Docs でも、Copilot はテスト失敗の診断やテスト生成を支援できるとされています。
https://docs.github.com/ja/copilot/tutorials/copilot-chat-cookbook/debug-errors/diagnose-test-failures
https://docs.github.com/ja/copilot/tutorials/write-tests
初動調査のコストが下がるため、人間は「どの方向で進めるか」を考え、AI は「その方向へ向かう候補と試行」を回す役割を持ちやすくなります。
未知の実装パターンを試しやすい
自分が知らない実装パターンや補助的な数理手法を、たたき台として素早く取り込めるのもメリットです。人間単独では思いつきにくい近道や補助線が入り、探索の射程が広がります。
たとえば、需要予測では、直近の変動を少し先へ延長する補正として、次のような形を試したくなることがあります。
$$
\hat{y}_{t+1} = y_t + \alpha ( y_t – y_{t-1} )
$$
これは、直近の変化量を係数 $\alpha$ 付きで先へ延ばす形です。仮説出しや試作では、有効な出発点になりえます。
バイブコーディングのリスク
失敗の意味が途中で消えやすい
すぐ試せることは、裏を返すと、途中の失敗が持っていた意味を見失いやすいことでもあります。
本来、失敗は「どの前提が外れていたか」を示す重要な信号です。ところが、修正をまとめて任せる運用になると、失敗の履歴が圧縮され、「何が問題だったのか」が手元に残りにくくなります。
たとえば統合テストが落ちたとき、本当の原因は外部 API の二重送信防止キーの扱いミスだったのに、タイムアウト延長、リトライ追加、例外処理変更、期待値の調整まで一気に入り、最終的に CI だけ通ることがあります。このとき消えたのはエラーではなく、エラーが教えていた設計上の違和感です。
局所最適が全体整合を壊しやすい
局所最適を速く作れることは、全体整合を崩しやすいことでもあります。数字や挙動が局所的に合っていても、業務上は意味の違う状態をひとつに潰してしまうと、あとで大きな破綻になります。
在庫管理は典型です。たとえば次の状態は、物としては同じ商品でも、業務上の意味が違います。
- 予約在庫
将来の注文や引当のために事実上空けておく在庫 - 引当済在庫
特定受注に確保済みで、他注文へ回せない在庫 - 出荷確定在庫
出荷対象として確定し、物流処理や売上処理に近い段階へ進んだ在庫 - 返品戻し在庫
返品で戻った在庫。ただし、検品前なら再販可能とは限らない在庫
可用在庫を単純化して考えるなら、少なくとも次のような分離が必要です。
$$
可用在庫_t = 実在庫_t – 引当済在庫_t – 出荷確定在庫_t
$$
ところが、返品戻し在庫を無条件に足すと、
$$
可用在庫_t = 実在庫_t – 引当済在庫_t – 出荷確定在庫_t + 返品戻し在庫_t
$$
という形になり、未検品の返品まで「今すぐ売れる在庫」として扱いかねません。見かけ上は帳尻が合っていても、業務定義は壊れています。
テスト通過と業務上の正しさがずれやすい
調査と試行錯誤を任せやすいことは、症状だけを消して病因を残しやすいことでもあります。バグが見えなくなったからといって、設計上の誤りまで消えたとは限りません。
たとえば「負の在庫が出ないようにして」と依頼し、分岐や補正でテスト上の負数が消えたとしても、本当の原因が在庫状態の概念混同にあるなら、数字合わせだけで根本は治っていません。
GitHub Docs でも、生成されたテストはすべてのシナリオを網羅しない可能性があるため、レビューと追加テストが必要だとされています。
https://docs.github.com/ja/copilot/tutorials/write-tests
妥当性不明な前提が混ざりやすい
未知の手法を取り込めることは、十分に保証されていない理屈まで入り込みやすいことでもあります。とくに危ないのは、数式やそれらしい説明があるために、根拠があるように見えてしまう場合です。
先ほどの補正
$$
\hat{y}_{t+1} = y_t + \alpha ( y_t – y_{t-1} )
$$
は、短期変動に追随しやすい一方で、季節性、販促、欠品、外れ値といった要因を分解していません。要因を理解せずに「最近の傾き」を先へ延ばしているだけなら、手元データではよく見えても、本番では発注量が系統的にずれる可能性があります。
さらに、LLM による実務的なコード生成では、リポジトリ文脈をまたぐ hallucination が起きることも研究で報告されています。実装がそれらしく見えても、存在しない API や不整合な依存関係が混ざることがあるため、動くかどうかだけでなく、前提の妥当性まで確認が必要です。
https://arxiv.org/abs/2409.20550
バイブコーディングが向く場面
バイブコーディングは、やり直しや作り直しが比較的しやすく、仮説を早く回す価値が高い領域で強みを発揮します。
- 試作
- 要件探索
- 一度きりのデータ変換
- UI モック
- エラー初動調査
- 実装案の比較
- 未知領域の入口づくり
この領域では、多少の作り直しコストよりも、仮説を早く外すことの価値が上回りやすいです。GitHub Docs の Vibe Coding チュートリアルも、概念実証、ドラフトアプリ、個人用途との相性を示しています。
https://docs.github.com/ja/copilot/tutorials/vibe-coding
バイブコーディングが向かない場面
速さよりも、説明可能性、妥当性、責任分界、状態定義の厳密さが重要な領域では、バイブコーディングを主軸にしない方が安全です。
- 認証
- 課金
- 会計
- 在庫
- 権限管理
- 数理モデルの本番補正
- 規制や監査の対象となる業務ロジック
NIST の Generative AI Profile でも、生成AI固有のリスクを見極め、用途に応じた管理を行う考え方が示されています。
https://www.nist.gov/publications/artificial-intelligence-risk-management-framework-generative-artificial-intelligence
https://www.nist.gov/itl/ai-risk-management-framework
本番コードに入れる境界
重要なのは、「使うか使わないか」ではありません。どこまでを探索として速く回し、どこからを人間が立ち止まって意味、前提、責任を引き受けるかです。
任せてよい範囲
- たたき台の作成
- UI モック
- 一時的な補助スクリプト
- 調査の初動
- テストケースの草案
- リファクタ候補の洗い出し
- ログやエラーメッセージの整理
この範囲では、スピードのメリットが上回りやすいです。
人が必ず持つべき責任
- 業務状態の定義
- 例外条件の整理
- モデルやロジックの前提確認
- セキュリティ境界の設計
- 権限と監査の要件整理
- 本番投入判断
- 生成物の受け入れ責任
GitHub Docs でも、Copilot が issue を処理して pull request を生成し、その後にユーザーのレビューを求める流れが示されています。
https://docs.github.com/ja/copilot/how-tos/use-copilot-agents/coding-agent
設計レビューで確認する観点
- 状態定義が混ざっていないか
- 例外系が仕様から抜けていないか
- 局所解が全体整合を壊していないか
- 入出力の責務が曖昧になっていないか
- 暗黙の前提が埋め込まれていないか
テストで確認する観点
- 正常系だけでなく境界条件があるか
- 欠損や異常入力を扱っているか
- 値合わせだけでなく意味を検証しているか
- 状態遷移が正しいか
- 失敗時の再現手順が残るか
ログ、監査、再現性で確認する観点
- なぜその変更が入ったか追えるか
- 生成プロンプトや判断理由が残るか
- 同じ条件で再実行できるか
- 失敗の履歴が圧縮されすぎていないか
AIコーディング支援を業務で使い分ける基準
実務では、「使うか使わないか」ではなく、「どこまで任せるか」を設計することが重要です。判断の軸としては、次の4点を置くと整理しやすいです。
1. 失敗してもやり直しやすいか
やり直しが容易で、局所的な失敗が全体へ波及しにくいなら、バイブコーディングは向きやすいです。逆に、失敗が顧客影響や金銭影響へ直結するなら、向きにくいです。
2. 正しさを後から明確に検証できるか
UI モックや補助ツールは、見た目や挙動である程度評価できます。一方、会計、在庫、予測補正のように、正しさが業務定義や統計前提に依存するものは、テスト通過だけでは足りません。
GitHub Docs でも、生成されたテストはすべてのシナリオを網羅しない可能性があるため、レビューと追補が必要だとされています。
https://docs.github.com/ja/copilot/tutorials/write-tests
3. ドメイン知識がコードより重要か
業務ロジックや数理モデルは、コードの巧拙より前に、定義と前提の正しさが重要です。この比率が高い領域ほど、AI に一気に作らせる運用は危険です。
4. 生成物の責任者が明確か
エージェントが pull request を起票できる時代でも、受け入れる責任は人間に残ります。レビュー責任と承認責任を曖昧にしたまま使うと、速さだけが前に出て、事故時の説明ができなくなります。
生産性は本当に上がるのか
生産性が上がる場面は確かにあります。ただし、常に、誰でも、どのタスクでも速くなるわけではありません。
GOV.UK の試験では平均 56 分/日の時間節約が報告されています。
https://www.gov.uk/government/publications/ai-coding-assistant-trial/ai-coding-assistant-trial-uk-public-sector-findings-report
一方で、企業内での導入研究では、利用者ごとの期待、責任感、受け止め方の違いが便益に影響することが示されています。さらに、経験豊富な OSS 開発者を対象にした 2025 年の RCT では、AI 利用時に平均 19% 遅くなったと報告されています。
https://arxiv.org/abs/2412.06603
https://arxiv.org/abs/2507.09089
つまり、AIコーディング支援は「自動で高速化してくれる魔法」ではありません。条件が合えば大きく効く道具であり、条件が合わなければ、レビュー負荷や理解コストで相殺されることもあります。
バイブコーディングのメリット・リスク比較表
| 観点 | 強み | 注意点 |
|---|---|---|
| 試行速度 | 仮説を短いサイクルで試しやすい | 失敗の意味や原因を見失いやすい |
| 実装の初速 | 局所タスクを短時間で形にしやすい | 局所最適が全体整合を壊しやすい |
| 調査と修正 | エラー調査や試行錯誤をまとめて進めやすい | 症状だけ消して根本原因を残しやすい |
| テスト支援 | テストの草案や失敗の切り分けを進めやすい | テスト通過と業務上の正しさは一致しない |
| 未知の手法の導入 | 新しい実装パターンや補助線を試しやすい | 妥当性不明な前提や理屈が混ざりやすい |
| 本番適用 | 補助実装や周辺作業では効きやすい | 高責任領域では人間の設計判断が不可欠 |
この表からわかる通り、バイブコーディングの強みとリスクは別々のものではありません。同じ性質が、探索では利点として働き、本番では弱点として現れます。重要なのは、速く回すこと自体ではなく、どこまでを探索として扱い、どこからを保証の対象として人間が引き受けるかです。
まとめ
バイブコーディングは、試作と探索の速度を大きく上げる開発スタイルです。とくに、初動調査、たたき台作成、実装案の比較、用途限定のツールづくりでは高い価値があります。
一方で、その強みは同時に、失敗履歴の圧縮、局所解の固定化、設計理解の希薄化、妥当性不明な理屈の混入にもつながります。コードが動くことと、業務として正しいことは同じではありません。
重要なのは、使うか使わないかではありません。どこまでを探索として速く回し、どこからを人間が立ち止まって意味、前提、責任を引き受けるか、その境界を設計できるかです。
領域
まとめのまとめ
- 探索には強い
- 保証には弱い
- 境界設計が肝心
その他の数理的なエッセイはこちら
FAQ
バイブコーディングとは何ですか
バイブコーディングとは、生成AIやコーディングエージェントに自然言語で指示しながら、実装、修正、調査、テストを高速に回す開発スタイルです。AIコーディング支援という道具の使い方の一種であり、道具そのものと同義ではありません。
AIコーディング支援とバイブコーディングの違いは何ですか
AIコーディング支援は、コード補完、チャット、テスト生成、コードレビュー、エージェントによる実装支援まで含めた広い概念です。バイブコーディングは、その道具を自然言語主導で高速に回す使い方の傾向です。
バイブコーディングは本番コードでも使えますか
使えます。ただし、使い方を限定する必要があります。試作、補助実装、初動調査、たたき台作成には向いていますが、認証、課金、会計、在庫、権限のような高責任領域では、人間による設計理解とレビューを厚くする前提が必要です。
バイブコーディングが向いている場面は何ですか
試作、要件探索、UI モック、一度きりのデータ変換、エラー初動調査、実装案の比較などです。やり直しや作り直しがしやすく、仮説を早く回す価値が高い場面と相性がよいです。
バイブコーディングではテストまで任せてよいですか
テスト生成やテスト失敗の診断までは有効です。ただし、テストが通ることと、業務ロジックや数理的前提が正しいことは同義ではありません。テストは通過条件であって、妥当性の最終保証ではないと考えるのが安全です。
バイブコーディングは必ず生産性を上げますか
必ずではありません。効果が出やすい場面はありますが、タスクの性質、既存コードベースへの習熟度、レビュー負荷、品質要求によっては、かえって遅くなることもあります。万能な高速化手段としてではなく、条件付きで効く道具として扱うのが現実的です。
参考文献
GitHub Docs, GitHub Copilot を使用した Vibe コーディング
https://docs.github.com/ja/copilot/tutorials/vibe-coding
GitHub Docs, GitHub Copilot を使ってテストを記述する
https://docs.github.com/ja/copilot/tutorials/write-tests
GitHub Docs, テストエラーの診断
https://docs.github.com/ja/copilot/tutorials/copilot-chat-cookbook/debug-errors/diagnose-test-failures
GitHub Docs, GitHub Copilot コード レビューについて
https://docs.github.com/ja/copilot/concepts/agents/code-review
GitHub Docs, GitHub Copilot コーディングエージェント
https://docs.github.com/ja/copilot/how-tos/use-copilot-agents/coding-agent
GOV.UK, AI coding assistant trial: UK public sector findings report
https://www.gov.uk/government/publications/ai-coding-assistant-trial/ai-coding-assistant-trial-uk-public-sector-findings-report
NIST, AI Risk Management Framework
https://www.nist.gov/itl/ai-risk-management-framework
NIST, Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile
https://www.nist.gov/publications/artificial-intelligence-risk-management-framework-generative-artificial-intelligence
Weisz, J. D. et al., Examining the Use and Impact of an AI Code Assistant on Developer Productivity and Experience in the Enterprise
https://arxiv.org/abs/2412.06603
Becker, J. et al., Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity
https://arxiv.org/abs/2507.09089
Zhang, Z. et al., LLM Hallucinations in Practical Code Generation: Phenomena, Mechanism, and Mitigation
https://arxiv.org/abs/2409.20550
まず読む本
この記事の核は、「速く作れること」と「正しく運用できること」は別だ、という点にある。そこにいちばん素直につながるのは、まず可読性と変更容易性の本だ。 ([オライリージャパン][1])
リーダブルコード

AI が書いたコードでも人が読む以上、名前、コメント、制御フロー、ロジック、再構成の基本が弱いと本番ではつらい。
この本は、コードを理解しやすくする原則を、命名、コメント、制御フロー、変数、ループ、テストまで含めて整理している。
「動く」と「理解できる」を分けて考える感覚をつくるのに向いている。
改訂新版 良いコード/悪いコードで学ぶ設計入門

変更しにくいコードがなぜ生まれるのか、どうすれば成長しやすい設計に変えられるのかを実践寄りに学べる本。
「局所最適が全体整合を壊す」という論点と相性がいい。
本番コードの境界を考える本
「どこから先は探索ではなく設計なのか」を判断する視点。
その軸をくれるのがアーキテクチャ本。
ソフトウェアアーキテクチャの基礎 第2版

アーキテクチャの定義、アーキテクトの役割、モジュールや結合、アーキテクチャスタイル、チームとの協働までを体系的に整理している。
第2版では、クラウド、データ、チームトポロジー、統制、イベント駆動、マイクロサービス、モジュラーモノリス、さらに LLM を含む新しい技術潮流まで加筆されていて、AI コーディング支援をどこに組み込むか考える土台としてかなり合う。
Clean Architecture 達人に学ぶソフトウェアの構造と設計

構成要素をどう組み立てるか、詳細に依存しすぎない設計をどう保つかを学ぶ本。
「速く作れた差分」ではなく、「何に依存しているか」「責任境界がどう分かれているか」を見たい人に向く。
業務ロジックを壊さないための本
在庫や会計のような業務定義は、単にコードが動けばよいわけではないという話。
そこに直結するのがドメイン駆動設計まわり。
[入門]ドメイン駆動設計

ドメイン駆動設計の基礎だけでなく、ユビキタス言語、イベントストーミング、イベントソーシング、分散アーキテクチャとの関係、クリーンアーキテクチャまで扱っている。
「状態の意味を潰さない」「業務知識をコードへ正しく写す」という観点とかなり相性がいい。
テストと保証を厚くする本
「AI にテストまで任せてよいか」という論点も持っているので、ここは外せない。
特に「テストが通る」と「業務として正しい」は違う、という感覚を補強する本を選ぶとよい。
単体テストの考え方/使い方

単体テストと統合テストの定義を整理し、価値のあるテストとは何か、どのテストを残し、どのテストを直し、あるいは削除するかまで踏み込む本。
「テスト通過と業務上の正しさはずれうる」という章を厚く理解したい人にいちばん合う。
Web API設計実践入門

API 仕様ファースト開発とテスト駆動開発を「車の両輪」として扱っていて、E2E テストや API 仕様がないことで生まれる技術負債にも触れている。
「本番コードに入れる境界」「ログ、監査、再現性」を、Web サービス文脈で具体化したい人に向く。
AIコーディング支援そのものを理解する本
探索の速さと、現場での導入・使い分けをどう考えるかに寄っている。
コード×AI ーソフトウェア開発者のための生成AI実践入門

GitHub Copilot や ChatGPT などの生成 AI によるコード生成やコードリーディング支援を前提に、「何ができるか」「どうすればよりよく活用できるか」を解説する本。
「バイブコーディングは万能ではなく、条件が合えば強く効く」という温度感にかなり近い。
既存システムやレガシーの現場で効く本
AI 支援は試作ではうまく見えやすい一方、既存コードベースに入った瞬間に難しくなる。そこを補う本。
レガシーコードからの脱却

壊れやすく拡張が難しいコードを生まないための 9 つのプラクティスを解説している。
「局所解の固定化」「理解不足のまま差分だけ増やす」といったリスクに対して、チーム開発の習慣から立て直したいときに合う。
分散システムやデータ整合の重い領域に進むなら
会計、在庫、数理モデル、本番補正のような高責任領域を強く警戒しているなら、このカテゴリも合う。
データ指向アプリケーションデザイン

スケーラビリティ、一貫性、信頼性、効率性、保守性をどう扱うか、レプリケーション、パーティション、トランザクション、バッチ処理、ストリーム処理まで含めて解説している。
「本番では説明可能性と妥当性が重要」という主張を、データ基盤や分散システムの視点から深めたい人向け。
迷ったらこの順
- まず読む
リーダブルコード
改訂新版 良いコード/悪いコードで学ぶ設計入門 - 次に読む
単体テストの考え方/使い方
[入門]ドメイン駆動設計 - その後で読む
ソフトウェアアーキテクチャの基礎 第2版
コード×AI
ひとことで分けると
- 「AI が書いたコードを人が読める形にしたい」
リーダブルコード、良いコード/悪いコードで学ぶ設計入門 - 「テストが通るだけでは不安」
単体テストの考え方/使い方、Web API設計実践入門 - 「業務ロジックを壊したくない」
[入門]ドメイン駆動設計、Clean Architecture - 「AI 支援を現場にどう入れるか知りたい」
コード×AI、ソフトウェアアーキテクチャの基礎 第2版

コメント