- 要約
- 合わせて読むことおすすめの記事
- 解説動画
- G検定 数学不要論と今回の続編
- G検定で数式理解が有利になる理由
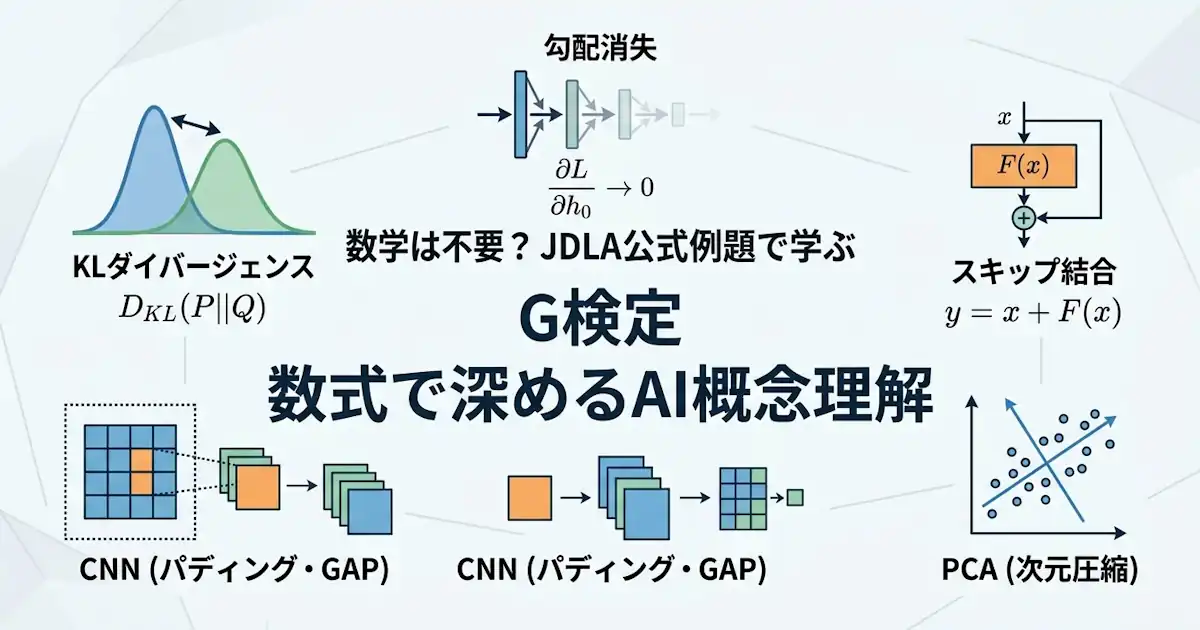
- KLダイバージェンス 非対称性が式で分かる
- 勾配消失 微分の積で見れば起こりやすい条件が分かる
- スキップ結合 $x+F(x)$ で見ると勾配との関係が分かる
- CNNのパディングとGAP 数式で役割の違いが明確になる
- PCAと重回帰分析 目的の違いが数式で見分けやすい
- 数式が苦手でも見る場所は限られる
- オリジナル例題 数式理解の効果を確認する
- 続編としての位置づけ
- FAQ
- 参考文献
- まとめ
- まず全体を押さえる本
- 数式がしんどい人向けの補助線
- 深層学習の仕組みを数式と実装でつなぐ本
- PCA・重回帰分析・評価を整理する本
- こう選ぶと外しにくい
要約
- G検定は数学必須ではないものの、KLダイバージェンス、勾配消失、スキップ結合、CNN、PCA では数式がかなり有効です
- JDLA公式の公開例題で触れられているテーマをもとに、数式が理解の助けになるポイントを整理します
- 数式で入力・出力・評価対象を整理すると、紛らわしい選択肢を見分けやすくなります
合わせて読むことおすすめの記事
G検定まとめ記事

ニューラルネットワークをG検定知識で読み解く
上記をかなりガッチリ気味に解説

同じく数式の必要性を問う兄弟記事

解説動画

G検定 数学不要論と今回の続編
G検定は、計算問題を解くための数学が必須の試験ではありません。
ただし、数式を読めると、用語どうしの関係や役割の違いが明確になり、「最も適切な説明を選べ」でかなり有利になります。
前回は、強化学習、ロジスティック回帰、sigmoid、softmax、勾配降下法、正則化を扱いました。
今回はその続編として、JDLA公式の公開例題で触れられているテーマをもとに、数式が理解の助けになるポイントを整理していきます。
JDLA公式の公開例題ページ
https://www.jdla.org/certificate/general/issues/
G検定公式ページ
https://www.jdla.org/certificate/general/
G検定の試験出題範囲(シラバス)G2024#6~
https://www.jdla.org/download/g%E6%A4%9C%E5%AE%9A%E3%81%AE%E8%A9%A6%E9%A8%93%E5%87%BA%E9%A1%8C%E7%AF%84%E5%9B%B2-%EF%BC%88%E3%82%B7%E3%83%A9%E3%83%90%E3%82%B9%EF%BC%892024/
G検定で数式理解が有利になる理由
G検定で厄介なのは、完全に間違っている選択肢ではなく、一部は正しいものの、説明としては少しずれている選択肢です。
このタイプは、日本語だけで覚えていると見分けにくくなります。
数式を押さえると、次の4点がはっきりします。
- 入力
- 出力
- 何を比較しているか
- 何を最小化または最大化しているか
この4点が見えるだけで、「それっぽい説明」と「位置づけまで正しい説明」の差が見えやすくなります。
今回扱う KLダイバージェンス、勾配消失、スキップ結合、CNN、PCA は、まさにこの差が正誤を分けやすい論点です。
KLダイバージェンス 非対称性が式で分かる
JDLA公式の公開例題ページでは、KLダイバージェンスについて「2つの確率分布がどの程度異なるかを定量的に評価する指標」であり、「非対称」であることを問う設問が公開されています。
式は次のように表せます。
$$
D_{\mathrm{KL}}(P | Q)=\sum_x P(x)\log \left( \displaystyle\frac{P(x)}{Q(x)} \right)
$$
この式を見ると、次のことが整理しやすくなります。
- 比べている対象 = 2つの確率分布 $P$ と $Q$
- 重み付け = $P(x)$
- 見ている量 = $P(x)$ と $Q(x)$ の比
- 重要な性質 = 一般に対称ではない
日本語だけで覚えると、「分布の違いを見る指標らしい」で止まりやすいです。
しかし式を見ると、$P$ と $Q$ の役割が入れ替われば別物になるので、$D_{\mathrm{KL}}(P | Q)$ と $D_{\mathrm{KL}}(Q | P)$ は一般に一致しないと理解しやすくなります。
G検定では、この「2分布のずれを見る」と「対称ではない」がそのまま判断材料になりやすいです。
勾配消失 微分の積で見れば起こりやすい条件が分かる
JDLA公式の公開例題ページでは、勾配消失が起こりやすい条件として「ネットワークの層が深い」が問われています。
まず、勾配消失そのものは連鎖律の形を見ると整理しやすいです。
$$
\displaystyle\frac{\partial L}{\partial h_0}=
\displaystyle\frac{\partial L}{\partial h_n}
\prod_{l=1}^{n}
\displaystyle\frac{\partial h_l}{\partial h_{l-1}}
$$
この式では、勾配が各層の微分の積になります。
そのため、各層で 1 より小さい値が何度も掛かると、勾配は急速に小さくなります。
この理解があると、次のことを整理しやすくなります。
- 層が深いほど起こりやすい
- 微分値が小さめの活性化関数だと起こりやすい
- 学習データ数の多さそのものは本質ではない
- バッチ正規化はむしろ緩和側で出てきやすい
G検定では「どれが本質要因か」を問う選択肢が出やすいので、微分の積として見ておくとかなり安定します。
スキップ結合 $x+F(x)$ で見ると勾配との関係が分かる
JDLA公式の公開例題ページでは、スキップ結合を特徴とするモデルとして ResNet が問われています。
ここは、勾配消失の話とつなげて理解するとかなり整理しやすくなります。
ResNet の考え方は、直接 $H(x)$ を学ぶのではなく、残差写像 $F(x)$ を学び、出力を次の形で表すところにあります。
$$
y=x+F(x)
$$
この形のポイントは、変換結果 $F(x)$ だけでなく、入力 $x$ 自体もそのまま足し合わされることです。
そのため、逆伝播では勾配が変換 $F(x)$ の経路だけに依存しにくくなります。
補足的に見ると、微分は次の形になります。
$$
\displaystyle\frac{\partial y}{\partial x}=
I+\displaystyle\frac{\partial F(x)}{\partial x}
$$
ここでの $I$ は恒等写像に対応する項です。
厳密にはヤコビアンまで追うとより正確ですが、G検定対策としては「$x$ をそのまま通す経路が追加される」「その結果、勾配が変換側だけに依存しにくくなる」と押さえておけば十分です。
つまり、勾配消失は「微分の積」で理解し、スキップ結合は「恒等的な経路が追加される構造」として理解すると、概念どうしの関係がかなり分かりやすくなります。
CNNのパディングとGAP 数式で役割の違いが明確になる
JDLA公式の公開例題ページでは、CNN におけるパディングの効果として「出力サイズを調整することができる」が問われています。
また、出力層で全結合層に代わって用いられるものとして GAP が問われています。
パディング 出力サイズの式で理解する
畳み込み後の出力サイズは、典型的には次で表せます。
$$
H_{\mathrm{out}}=
\left\lfloor
\displaystyle\frac{H+2P-K}{S}
\right\rfloor + 1
$$
$$
W_{\mathrm{out}}=
\left\lfloor
\displaystyle\frac{W+2P-K}{S}
\right\rfloor + 1
$$
ここで、
- $H, W$ = 入力サイズ
- $K$ = カーネルサイズ
- $S$ = ストライド
- $P$ = パディング幅
です。
この式を見ると、パディングは単に「端を埋める処理」ではなく、出力サイズを左右するパラメータだと分かります。
そのため、「パディングは出力サイズの調整に関わる」がかなり強い判断材料になります。
GAP 各チャネルを1つの値にまとめる
グローバルアベレージプーリングは、各チャネルの特徴マップを空間方向に平均する処理です。
$$
y_c=
\displaystyle\frac{1}{HW}
\sum_{i=1}^{H}
\sum_{j=1}^{W}
x_{ijc}
$$
この式から分かるのは、GAP が
- チャネルごとに
- 空間方向を平均して
- 1つの値へ集約する
処理だということです。
この理解があると、最大値プーリングや平均値プーリングとの違いが見えやすくなります。
また、全結合層のように大量の重みで混ぜる処理ではないことも整理しやすくなります。
PCAと重回帰分析 目的の違いが数式で見分けやすい
JDLA公式の公開例題ページでは、重回帰分析の例として「地域の人口、店舗面積、販売品目数から売上高を予測する」問題が公開されています。
また、別の公開例題では、レコメンデーションの文脈で PCA を正答ではない選択肢として区別させています。
重回帰分析は、複数の説明変数から連続値を予測します。
$$
\hat{y}=
\beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_p x_p
$$
一方、PCA はデータを低次元に要約する手法で、分散が大きい方向を探します。
$$
w_1=
\arg\max_{\left\lVert w \right\rVert=1}
\mathrm{Var}(w^\top x)
$$
この2つは、どちらも複数の変数を扱いますが、目的がまったく違います。
- 重回帰分析 = 予測
- PCA = 次元圧縮
- 重回帰分析 = 目的変数あり
- PCA = 入力側の構造を要約
G検定では、売上予測のような問題を PCA やクラスタリングと取り違えないことが大事です。
式を見ておくと、予測なのか圧縮なのかを見分けやすくなります。
数式が苦手でも見る場所は限られる
数式が苦手でも、導出を全部追う必要はありません。
G検定対策としては、次の4点だけ見れば十分です。
- 何を入力するか
- 何を出力するか
- 何を比較するか
- 何を最小化または最大化するか
たとえば、KLダイバージェンスなら「2分布のずれ」と「非対称性」、勾配消失なら「微分の積」、スキップ結合なら「$x$ をそのまま足す経路」、パディングなら「出力サイズに入る」、GAP なら「各チャネルを平均して 1つの値にする」、PCA なら「予測ではなく次元圧縮」と見れば十分です。
オリジナル例題 数式理解の効果を確認する
以下の例題はオリジナルです。
JDLA公式の公開例題そのものではなく、公式例題で問われている論点を別角度から確認するためのものです。
例題1 KLダイバージェンス
問題
KLダイバージェンスに関する説明として、最も適切なものを選んでください。
A. KLダイバージェンスは、2つの確率分布のずれを測る指標であり、一般に対称である
B. KLダイバージェンスは、2つの確率分布のずれを測る指標であり、一般に対称ではない
C. KLダイバージェンスは、1つの分布が正規分布にどれだけ近いかだけを測る指標である
D. KLダイバージェンスは、2つの確率変数の平均値の差だけを測る指標である
■ 正解
B
■ 簡単な解説
KLダイバージェンスは 2つの確率分布のずれを評価する量で、一般に対称ではありません。
$$
D_{\mathrm{KL}}(P | Q)=\sum_x P(x)\log \left( \displaystyle\frac{P(x)}{Q(x)} \right)
$$
■ 正解の理由
式では $P$ と $Q$ の役割が同じではないため、向きを入れ替えると一般に別の値になります。
したがって、B が最も適切です。
■ 不正解の理由
A
対称ではありません。
C
正規分布との近さだけを見る指標ではありません。
D
平均値の差だけではなく、分布全体の違いを見ます。
■ まとめ
KLダイバージェンスは「2分布のずれ」と「非対称性」が見えているかどうかが分かれ目です。
例題2 勾配消失
問題
勾配消失に関する説明として、最も適切なものを選んでください。
A. 層が深く、各層の微分値が小さいと、勾配は前段に伝わるにつれて小さくなりやすい
B. 学習データ数が多いほど、勾配消失は必ず起きる
C. 勾配消失とは、勾配が極端に大きくなる現象である
D. 勾配消失は、出力クラス数が少ないときだけ起きる
■ 正解
A
■ 簡単な解説
勾配は連鎖律により各層の微分の積になります。
$$
\displaystyle\frac{\partial L}{\partial h_0}=
\displaystyle\frac{\partial L}{\partial h_n}
\prod_{l=1}^{n}
\displaystyle\frac{\partial h_l}{\partial h_{l-1}}
$$
■ 正解の理由
小さな値が何度も掛かると勾配が急速に小さくなるため、A が最も適切です。
■ 不正解の理由
B
データ数の多さそのものは本質ではありません。
C
それは勾配爆発に近い説明です。
D
クラス数だけで決まる問題ではありません。
■ まとめ
勾配消失は「微分の積」として理解すると、深い層が危ない理由まで説明しやすくなります。
例題3 スキップ結合
問題
スキップ結合に関する説明として、最も適切なものを選んでください。
A. スキップ結合では、出力は常に $y=F(x)$ となり、入力 $x$ は使われない
B. スキップ結合では、出力を $y=x+F(x)$ と表せるため、勾配が変換 $F(x)$ 側だけに依存しにくくなる
C. スキップ結合は、逆伝播そのものを不要にする
D. スキップ結合は、活性化関数を必ず線形関数に置き換える
■ 正解
B
■ 簡単な解説
残差ブロックでは、入力をそのまま足し合わせる経路を持ちます。
$$
y=x+F(x)
$$
補足的に見ると、
$$
\displaystyle\frac{\partial y}{\partial x}=
I+\displaystyle\frac{\partial F(x)}{\partial x}
$$
となるため、恒等写像に由来する項が加わります。
■ 正解の理由
B は、スキップ結合が入力 $x$ をそのまま通す経路を持ち、勾配が変換側だけに依存しにくくなることを正しく述べています。
■ 不正解の理由
A
スキップ結合のポイントは $x$ が加わることです。
C
逆伝播が不要になるわけではありません。
D
活性化関数を必ず線形にする仕組みではありません。
■ まとめ
スキップ結合は「$x$ をそのまま足す経路」と理解すると、勾配消失との関係を整理しやすくなります。
例題4 CNNのパディングとGAP
問題
CNN に関する説明として、最も適切なものを選んでください。
A. パディングはカーネル数を増やす処理であり、GAP は最大値だけを取り出す処理である
B. パディングは出力サイズに影響しうる処理であり、GAP は各チャネルを平均して 1つの値に集約する処理である
C. パディングはストライドを自動的に調整する処理であり、GAP は全結合層と同じである
D. パディングも GAP も、入力画像の解像度を上げることが主目的である
■ 正解
B
■ 簡単な解説
パディングは出力サイズの式に直接入ります。
$$
H_{\mathrm{out}}=
\left\lfloor
\displaystyle\frac{H+2P-K}{S}
\right\rfloor + 1
$$
GAP は各チャネルの特徴マップを平均して 1つの値へ集約します。
$$
y_c=
\displaystyle\frac{1}{HW}
\sum_{i=1}^{H}
\sum_{j=1}^{W}
x_{ijc}
$$
■ 正解の理由
B は、パディングと GAP の役割をどちらも正しく述べています。
■ 不正解の理由
A
パディングはカーネル数を増やしません。GAP は最大値ではなく平均です。
C
パディングはストライドを変えません。GAP は全結合層と同じではありません。
D
どちらも解像度向上を主目的とする処理ではありません。
■ まとめ
パディングは出力サイズ、GAP はチャネルごとの平均集約と理解すると混同しにくくなります。
例題5 PCAと重回帰分析
問題
PCA と重回帰分析に関する説明として、最も適切なものを選んでください。
A. PCA は複数の説明変数から売上高のような連続値を予測する手法である
B. 重回帰分析は、分散が最大になる方向へデータを射影して次元を削減する手法である
C. PCA はデータを低次元に要約する手法であり、重回帰分析は複数の説明変数から連続値を予測する手法である
D. PCA も重回帰分析も、目的変数を必要としない教師なし学習である
■ 正解
C
■ 簡単な解説
重回帰分析は、複数の説明変数から連続値を予測します。
$$
\hat{y}=
\beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_p x_p
$$
PCA は分散が大きい方向を探して次元を圧縮します。
$$
w_1=
\arg\max_{\left\lVert w \right\rVert=1}
\mathrm{Var}(w^\top x)
$$
■ 正解の理由
C は、PCA が次元圧縮、重回帰分析が予測という違いを正しく述べています。
■ 不正解の理由
A
それは重回帰分析の説明です。
B
それは PCA の説明です。
D
重回帰分析は目的変数を持つ予測手法です。
■ まとめ
PCA と重回帰分析は、どちらも複数変数を扱いますが、目的がまったく異なります。
続編としての位置づけ
前回の記事が「強化学習、ロジスティック回帰、sigmoid、softmax、正則化」なら、今回の記事は「JDLA公式の公開例題ページにある別論点を、数式で整理する」という役割にすると流れがきれいです。
役割の分け方は次のようになります。
- 前回 = よく知られた基本論点を数式で整理
- 今回 = 公式例題で公開されている別論点を数式で整理
- 共通テーマ = 「最も適切な説明」を見分けるための数式理解
この並びにすると、単なる論点追加ではなく、続編としての意味が出やすくなります。
FAQ
G検定で数式理解が特に役立つ分野はどこですか?
KLダイバージェンス、勾配消失、スキップ結合、CNNのパディング、GAP、PCA、重回帰分析などで特に有効です。
数式を見ると、何を入力として何を出力し、何を評価しているかが明確になります。
スキップ結合は勾配消失にどう効くのですか?
残差ブロックでは出力を $y=x+F(x)$ と表せます。
この形では入力 $x$ をそのまま通す経路があるため、勾配が変換 $F(x)$ 側だけに依存しにくくなり、深いネットワークでも学習しやすくなります。
CNNのパディングは何のために使うのですか?
出力サイズを調整し、端の情報が早く失われすぎるのを防ぐために使います。
出力サイズの式にパディング幅が直接入っているので、役割を整理しやすくなります。
PCAと重回帰分析はどう違いますか?
PCA は次元圧縮、重回帰分析は連続値予測です。
目的変数を予測しているのか、それとも入力の構造を要約しているのかで見分けると整理しやすくなります。
G検定で数式が苦手でも対策できますか?
対策できます。
ただし、入力、出力、比較している対象、最小化または最大化している対象の4点は押さえた方が、紛らわしい選択肢を見分けやすくなります。
参考文献
一般社団法人日本ディープラーニング協会「G検定の例題・過去問」
https://www.jdla.org/certificate/general/issues/
一般社団法人日本ディープラーニング協会「G検定とは」
https://www.jdla.org/certificate/general/
一般社団法人日本ディープラーニング協会「G検定の試験出題範囲(シラバス)G2024#6~」
https://www.jdla.org/download/g%E6%A4%9C%E5%AE%9A%E3%81%AE%E8%A9%A6%E9%A8%93%E5%87%BA%E9%A1%8C%E7%AF%84%E5%9B%B2-%EF%BC%88%E3%82%B7%E3%83%A9%E3%83%90%E3%82%B9%EF%BC%892024/
Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, “Deep Residual Learning for Image Recognition”
https://openaccess.thecvf.com/content_cvpr_2016/papers/He_Deep_Residual_Learning_CVPR_2016_paper.pdf
Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, “Identity Mappings in Deep Residual Networks”
https://arxiv.org/abs/1603.05027
S. Kullback, R. A. Leibler, “On Information and Sufficiency”
https://www.jstor.org/stable/2236703
Min Lin, Qiang Chen, Shuicheng Yan, “Network In Network”
https://arxiv.org/abs/1312.4400
NIST/SEMATECH e-Handbook of Statistical Methods, “Linear Least Squares Regression”
https://www.itl.nist.gov/div898/handbook/pmd/section1/pmd141.htm
まとめ
G検定に数学は不要という言い方は正しいです。
ただし、それは数式を知らなくても概念の違いが自然に分かるという意味ではありません。
とくに、KLダイバージェンス、勾配消失、スキップ結合、CNN のパディング、GAP、PCA、重回帰分析のような論点では、数式がそのまま判断の手がかりになります。
数式を見ることで、何を入力し、何を出力し、何を評価しているかが明確になり、似ているが少しずれている選択肢を見分けやすくなります。
- 数学必須ではないが、数式理解は強い判断材料
- 勾配消失は微分の積、スキップ結合は $x+F(x)$ の経路で整理
- 数式を見ると、選択肢の違いを言葉だけより整理しやすい
まず全体を押さえる本
深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト 第3版

この記事の土台にいちばん合うのは、やはりこれです。
新シラバス準拠で、基盤モデルや大規模言語モデル、法律・倫理まで含めて広くカバーしています。
この記事で扱っている KLダイバージェンス、勾配消失、CNN、GAP、PCA まわりを「G検定の出題範囲の中でどこに位置するか」を確認するのに向いています。
徹底攻略ディープラーニングG検定ジェネラリスト問題集 第3版

「理解した」だけで終わらせず、「選択肢で見分ける」練習に寄せるならこれが相性が良いです。
最新シラバス・出題形式・出題傾向に沿って全面改訂され、巻末に実戦形式の総仕上げ問題もあります。
この記事が目指している「数式で紛らわしい選択肢を見分ける感覚」を固めやすいです。
数式がしんどい人向けの補助線
データサイエンスのための数学入門

「いきなり専門書は重いが、数式の意味は押さえたい」という場合にかなり合います。
微積分・確率・線形代数・統計を、線形回帰・ロジスティック回帰・ニューラルネットワークのような実践的アルゴリズムと結びつけて学べる構成です。
「式の意味だけ分かれば十分」という読み方と相性が良いです。
データサイエンスのための統計学入門 第2版

PCA や回帰、分布、確率の話でつまずきやすいなら、こちらもかなり使いやすいです。
統計学と機械学習の基本概念を、最低限の数式・グラフ・R/Pythonコードで多面的に説明する本です。
KLダイバージェンスや回帰の理解を支える前提として、分布やモデル評価の感覚を補いやすいです。
深層学習の仕組みを数式と実装でつなぐ本
ゼロから作るDeep Learning

この記事で扱っている勾配消失、誤差逆伝播、CNN の話といちばん素直につながるのはこれです。
誤差逆伝播法や CNN、Batch Normalization、Dropout、Adam まで扱っていて、理論と実装をつなげながら理解できる本として整理されています。
スキップ結合そのものを主題にした本ではありませんが、「層が深くなると何が難しくなるか」を腹落ちさせる助けになります。
これならわかる深層学習入門

実装よりも、「理屈をちゃんと分かりたい」寄りならこちらが合います。
機械学習の予備知識がない読者でも、基礎から理論的に明快に理解できるように書かれています。
勾配消失や残差学習のように、構造の意味を式で押さえたい人向けです。
PCA・重回帰分析・評価を整理する本
Pythonではじめる機械学習

PCA、重回帰分析、特徴量、モデル評価をひとまとまりで整理したいなら、これがかなり強いです。
scikit-learn の開発に深く関わる著者が、特徴量エンジニアリングやモデルの評価・改善に多くのページを割いています。
この記事の「PCA は圧縮、重回帰は予測」という見分け方を、より実践寄りに確認しやすいです。
わかりやすいパターン認識 第2版

数式を避けずに、識別・誤差評価・特徴空間の変換まで整理したいなら、これがきれいにつながります。
基本項目に絞って重点的かつ詳細に解説し、学習と識別関数、誤差評価、特徴空間の変換などを扱っています。
PCA、識別、回帰周辺の概念を「名前」ではなく「役割の違い」として理解しやすいです。
こう選ぶと外しにくい
- G検定全体を押さえるなら
「公式テキスト」+「問題集」 - 数式への苦手意識を減らしたいなら
「データサイエンスのための数学入門」+「データサイエンスのための統計学入門 第2版」 - 勾配消失、CNN、誤差逆伝播をちゃんと理解したいなら
「ゼロから作るDeep Learning」+「これならわかる深層学習入門」 - PCA と重回帰分析の違いを整理したいなら
「Pythonではじめる機械学習」+「わかりやすいパターン認識 第2版」
コメント