
バックナンバーはこちら

動画シリーズ
本記事は、YouTubeで公開している「G検定対策 究極カンペをつくろう」シリーズの第14回「データの収集・加工・分析・学習」を文字・図解で整理したものです。
動画では対話形式で解説していますが、この記事では試験直前に見返せるよう、講義ノート+因果関係図の形に圧縮しています。

到達目標
- AIの学習対象となるデータを取得・利用するときの注意点を説明できるようにします。
- 集めたデータを加工・分析・学習させるときの注意点を工程で整理します。
- データを共有しながら共同開発を進める場合の留意点を、事故パターンまで含めて押さえます。
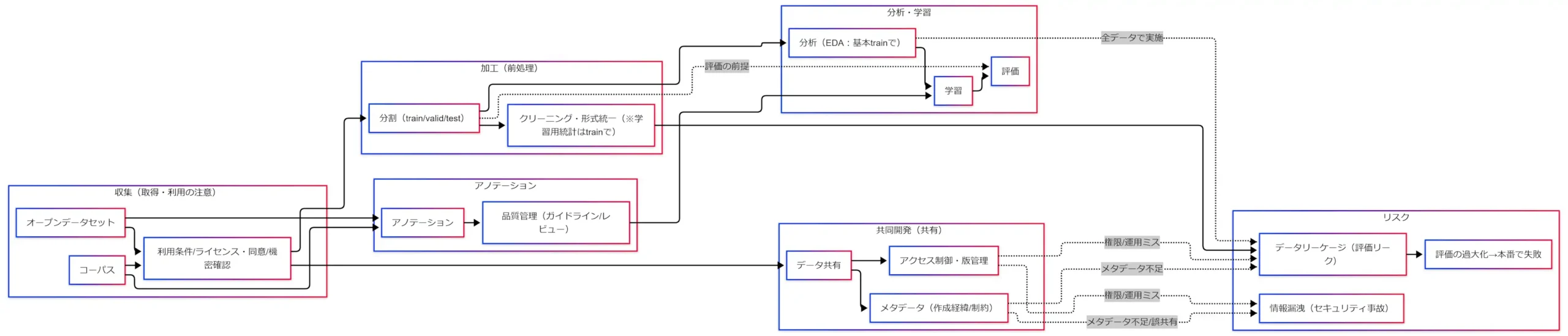
全体像:究極カンペの工程地図と奈落ルート
「評価は良いのに本番で失敗する」は、モデルが弱いというよりデータ運用が評価を壊しているケースが多いです。
そこで究極カンペは、用語暗記ではなく工程を一本につないで覚えます。
究極カンペの一本線
- 収集(取得・利用の注意)
- 加工(前処理)
- アノテーション
- 分析・学習
- 評価
- 共同開発(共有)が途中から合流
- 油断するとリスクへ落ちる(データリーケージ/情報漏洩)
- 評価の過大化 → 本番で失敗
収集:オープンデータセット/コーパスと利用条件の確認
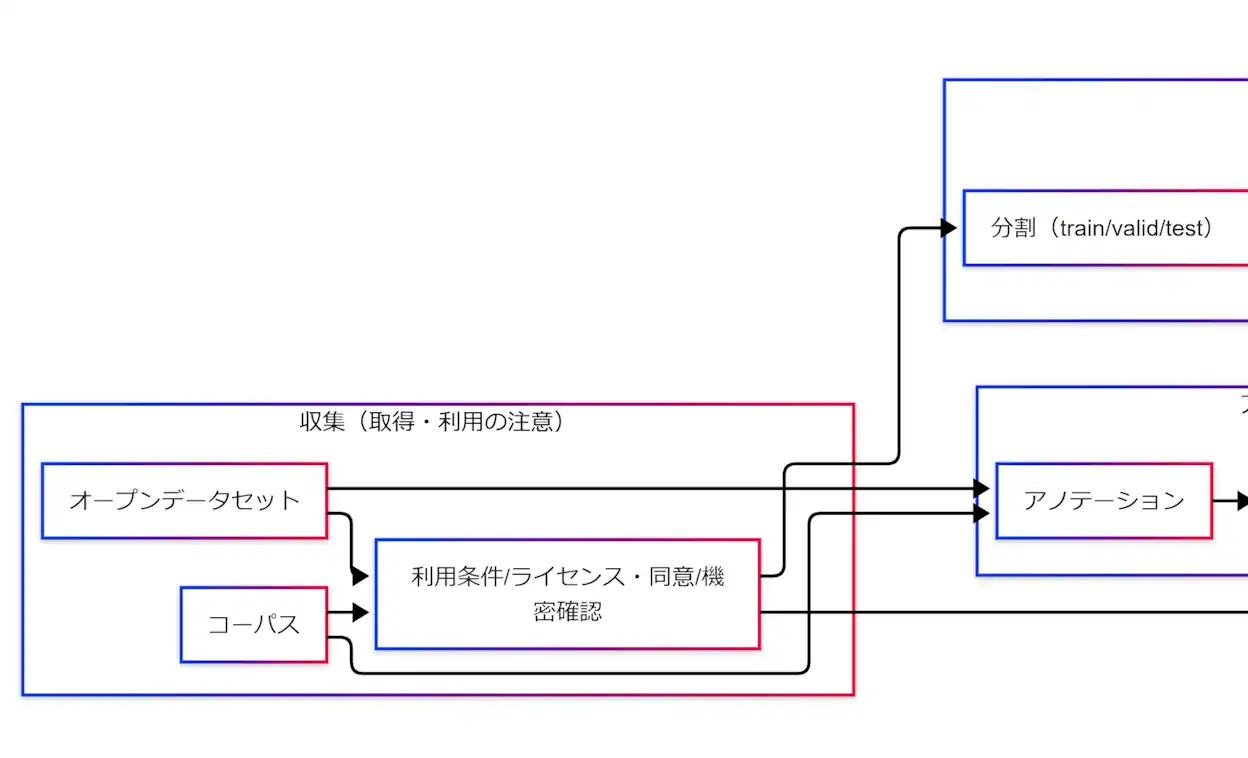
究極カンペの最初の関門は、「使えるデータ」ではなく「使ってよいデータ」です。
オープンデータセットやコーパスは便利ですが、利用条件を飛ばすと後戻りが最大になります。
オープンデータセットの確認ポイント
- 商用利用の可否
- 改変の可否
- 再配布の可否
- クレジット表記の要否
- 継承条件(同一ライセンスの要求など)
- 学習利用の可否(条文・README・利用規約で確認)
ライセンス条文を確認する導線を、チームの運用に組み込んでおくのが安全です。
https://creativecommons.org/licenses/by/4.0/legalcode.en
https://opendatacommons.org/licenses/odbl/
コーパス利用で混ざりやすい論点
コーパスはNLPでよく出ますが、次の「地雷」が一緒に入ってきます。
- 収集元の規約(取得・再配布の可否)
- 収集範囲(期間・地域・媒体)による偏り
- 前処理・ラベル定義が不明で、後工程で事故が増える
この時点で「取扱説明書(メタデータ)」が必要だと気づけると、究極カンペ的にはかなり強いです。
加工:train/valid/test分割と前処理(統計はtrain基準)
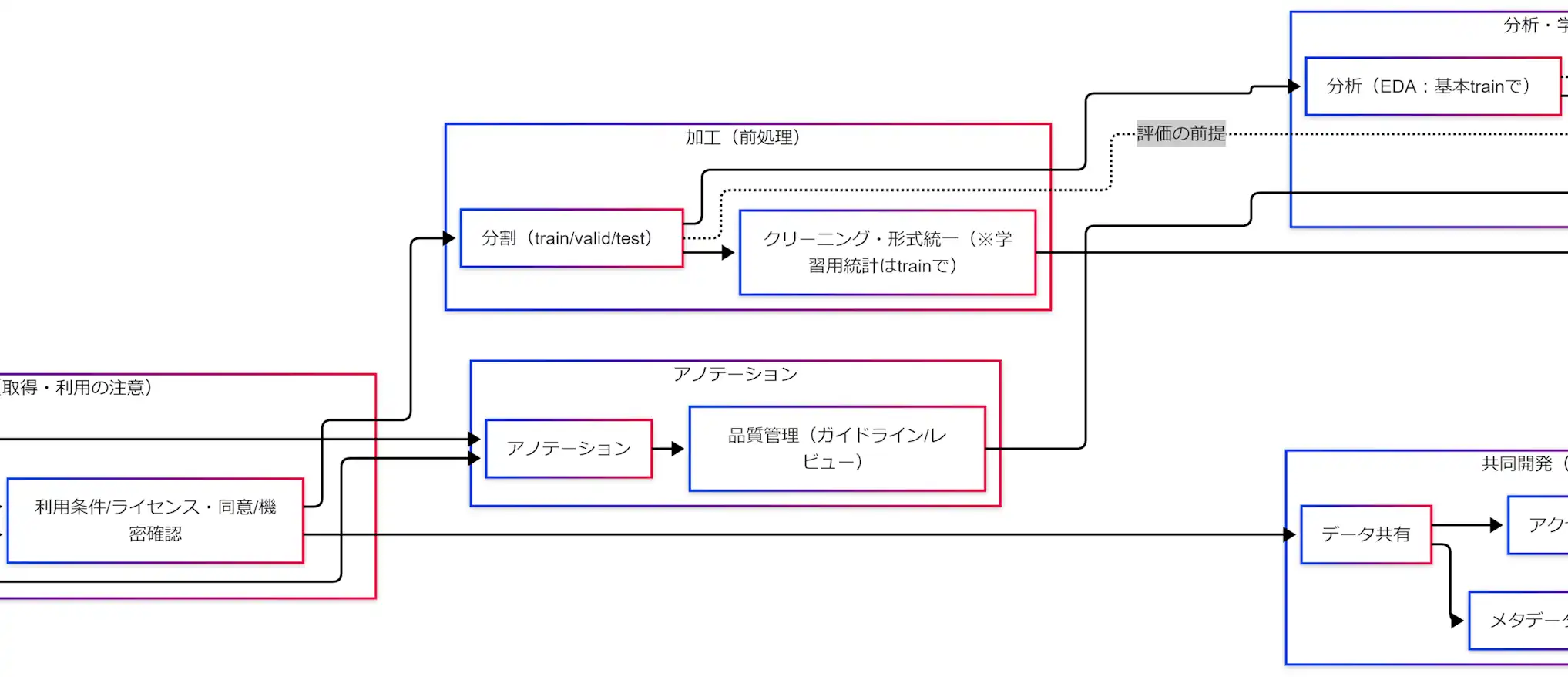
究極カンペの中核はここです。評価の信頼性は分割で決まります。
分割の鉄則
- 分割が先(train/valid/testを先に確定します)
- 前処理の学習用統計はtrainで作ります(平均・分散、欠損補完の統計、語彙、特徴量集計など)
データリーケージ(評価リーク)の典型パターンとして「分割前に前処理を当てる」問題が整理されています。
https://scikit-learn.org/stable/common_pitfalls.html
「全部きれいにしてから分ける」が危ない理由
全データで標準化や欠損補完をすると、test側の情報が混ざる可能性があります。
その結果、評価が実力以上に良く見えます。これがデータリーケージ(評価リーク)の入り口です。
アノテーション:ラベル付けと品質管理
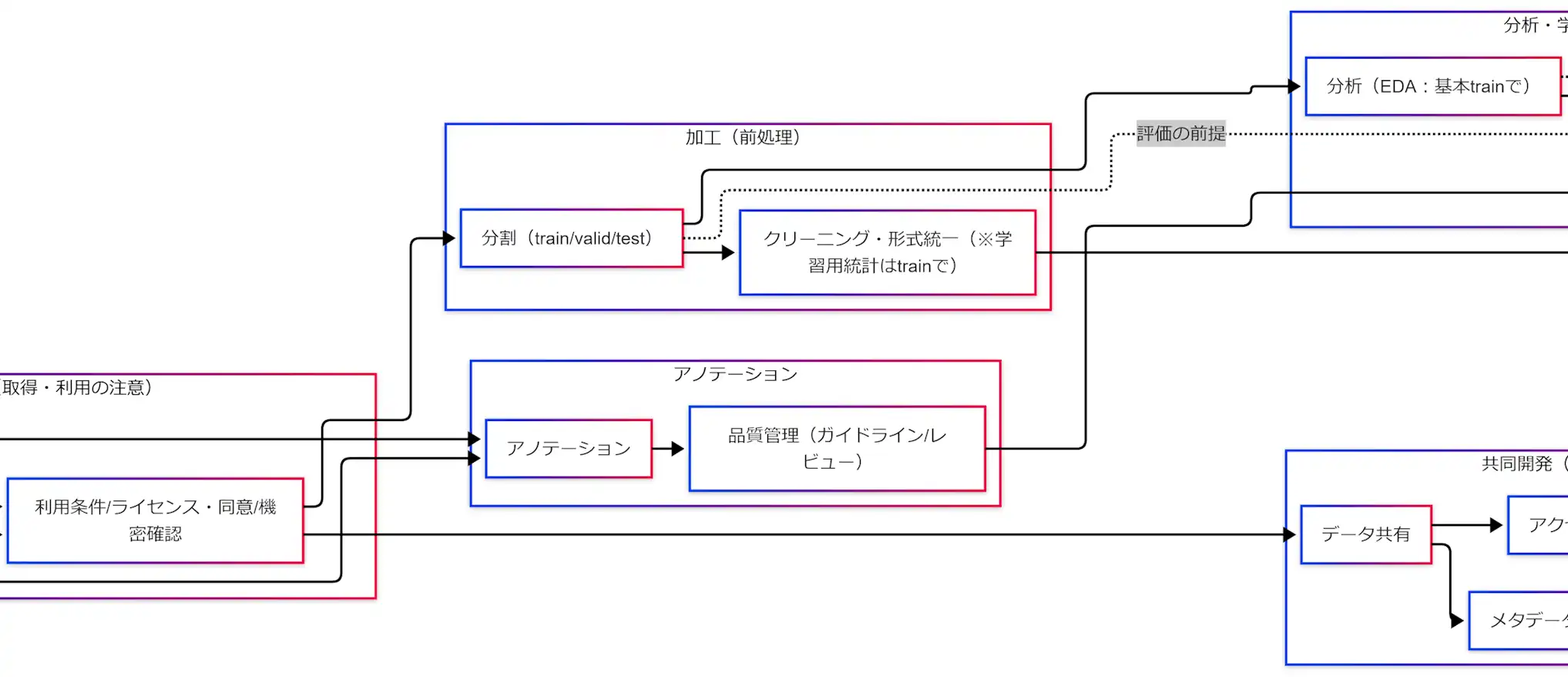
アノテーションはラベル付けですが、究極カンペでは「人の判断を再現可能な仕様にする作業」として押さえます。
仕様が曖昧だと、人ごとに判断が揺れ、モデルも揺れます。
品質管理(ガイドライン/レビュー)
- ガイドライン(境界事例、判断フロー、禁止事項を明文化します)
- レビュー(二重化、サンプリング監査、フィードバックを回します)
- 一致度の確認(作業者間でズレが出ていないか見ます)
アノテーションの一致度(Inter-annotator agreement)の考え方は、品質評価として定番です。
https://aclanthology.org/J08-4004.pdf
分析・学習:EDAと評価設計(testは最後)
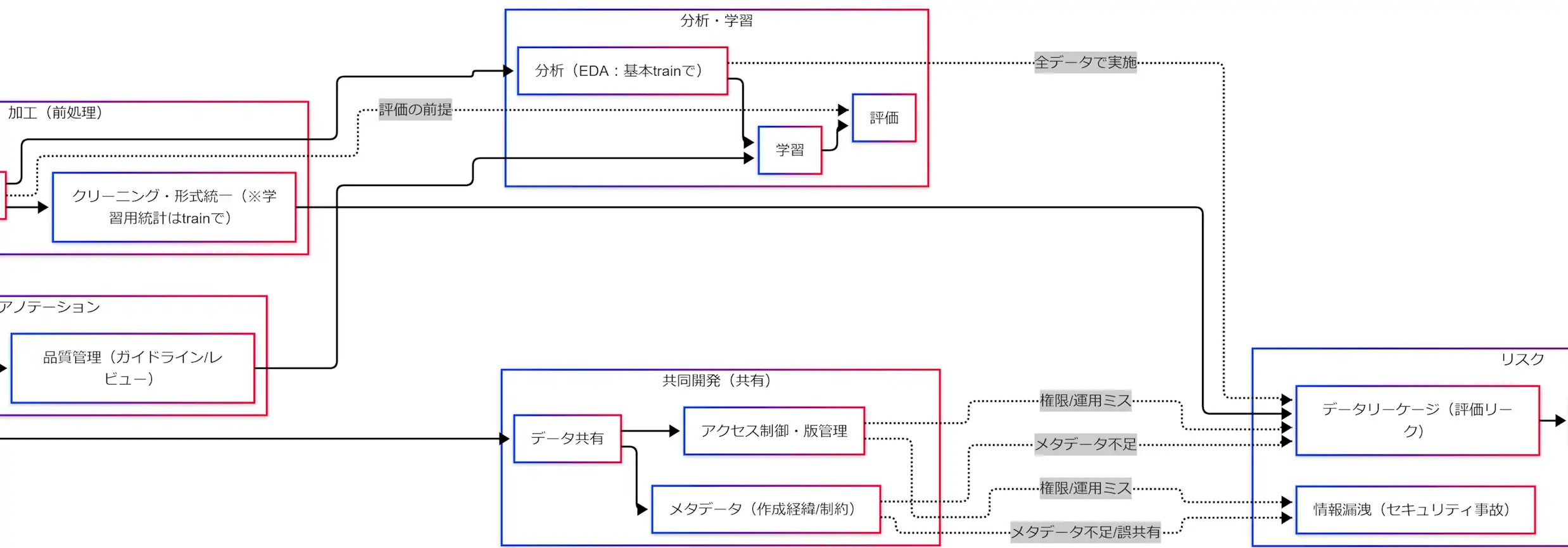
EDA(探索的データ分析)は便利ですが、究極カンペでは「やり方しだいでリークする」とセットで覚えます。
EDAの落とし穴
全データ(特にtest)を見た結果が、次に影響するとリークになります。
- 特徴量設計がtestの傾向に寄る
- 閾値や除外ルールがtestに最適化される
- そのまま評価が過大化する
運用の基本形
- train:学習と、前処理統計の作成に使います
- valid:調整に使います(ハイパーパラメータ、閾値など)
- test:最終確認に残します(原則、最後に一度)
「評価データでチューニングしない」は、究極カンペの合言葉にしておくと事故が減ります。
共同開発:データ共有、アクセス制御・版管理、メタデータ
共同開発でデータを共有すると速度は上がりますが、究極カンペでは「事故ルートも太くなる」と捉えます。
ここは3点セットで押さえます。
データ共有
必要な人に必要な範囲だけ共有します。目的外利用を防ぐため、利用条件も一緒に流します。
アクセス制御・版管理
- 誰が、どのデータ版を使ったか追えるようにします
- 評価用データが混ざる事故を防ぎます
- 再現性と監査の土台になります
情報セキュリティの管理策は、NIST SP 800-53などの体系で整理できます。
https://csrc.nist.gov/publications/detail/sp/800-53/rev-5/final
メタデータ(取扱説明書)
最低限これがあると、究極カンペ的に事故率が下がります。
- 作成経緯(収集元、期間、対象範囲、除外条件)
- 利用制約(ライセンス、同意、再配布可否、機密区分)
- ラベル定義(クラス定義、境界事例、ガイドライン版)
- 分割ルール(分割単位、リーク防止設計)
- 前処理履歴(統計の算出範囲、フィルタ条件、特徴量定義)
データ文書化の代表的提案として、Datasheets for Datasets や Dataset Nutrition Label が知られています。
https://arxiv.org/abs/1803.09010
https://arxiv.org/abs/1805.03677
リスク:データリーケージ(評価リーク)と情報漏洩
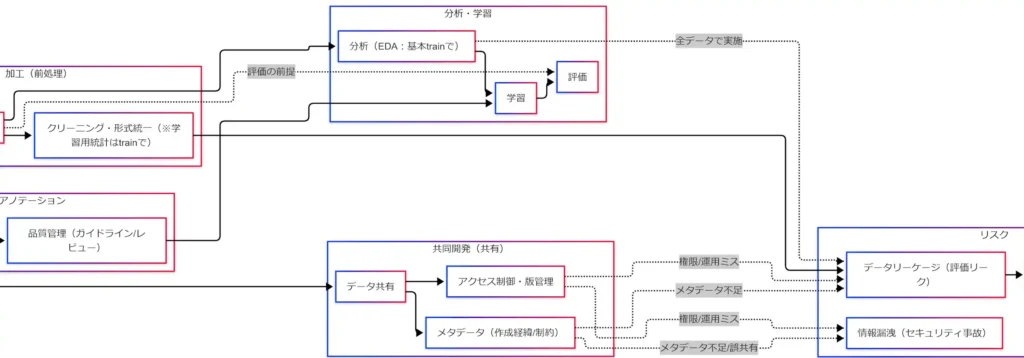
データリーケージ(評価リーク)
入り口はだいたい次のどれかです。
- 分割前に前処理の統計を作る
- EDAを全データでやり、設計判断に混ぜる
- 共有データに評価用データが混ざる
- メタデータ不足で「それがtest相当だと気づけない」
その結果、「評価の過大化 → 本番で失敗」につながります。
究極カンペでは「混ぜない」「最後に評価」が最重要です。
情報漏洩(セキュリティ事故)
- 権限設定ミス(見える/落とせる人が増える)
- 誤配布(ライセンス違反・契約違反)
- 匿名化不足(個人情報が残る)
AIのリスク整理は NIST AI RMF でも枠組み化されています。
https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.100-1.pdf
究極カンペチェックリスト
- 分割(train/valid/test)を最初に行っていますか
- 学習用統計(標準化、欠損補完、語彙、集計)をtrainだけで作っていますか
- valid/testを見て、特徴量・閾値・除外条件を調整していませんか
- 共有データに、評価用データ(test相当)が混ざっていませんか
- メタデータに、分割ルール・前処理履歴・利用制約が書かれていますか
- アクセス制御と版管理で、誰がどの版を扱ったか追えますか
まとめ
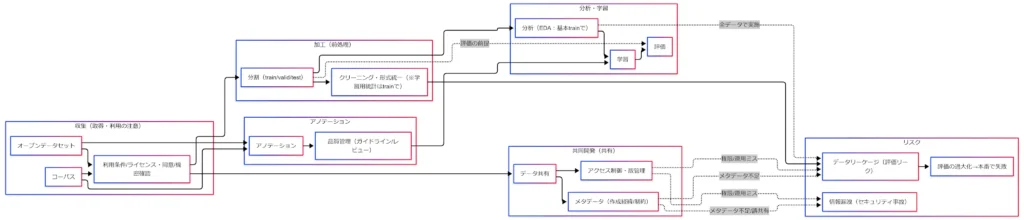
今回の究極カンペは、データ工程を「収集→加工→アノテーション→分析・学習→評価」の一本線で覚え、共同開発の合流点で「アクセス制御・版管理・メタデータ」を足す形です。
この線を外れると、データリーケージ(評価リーク)や情報漏洩に落ちて、評価の過大化から本番失敗につながりやすくなります。
G検定でも現場でも、「どの工程で何を守るべきか」を因果で説明できるのが究極カンペとして強いです。
- 分割は最初、統計はtrain基準
- EDAはtrain中心、testは最後に一度
- 共同開発はアクセス制御・版管理・メタデータで事故を止める
FAQ
データリーケージ(評価リーク)とは何ですか
評価に使うデータ(test相当)の情報が、前処理・特徴量・学習・意思決定に混ざり、評価が実力より良く見える現象です。分割前の前処理や、testを見たチューニングで起きやすいです。
なぜ「分割→前処理(train基準)」が鉄則なのですか
標準化や欠損補完などの統計を全データで作ると、testの情報がtrain側へ流れ込みリークにつながるからです。分割後にtrainだけで統計を作ると混入を減らせます。
https://scikit-learn.org/stable/common_pitfalls.html
EDAはどこまで見てよいですか
基本はtrain中心が安全です。全データ(特にtest)を見て特徴量や閾値を決めると、意思決定にtest情報が混ざりやすくなります。validは調整に使い、testは最終確認に残す運用が基本です。
アノテーション品質は何で担保しますか
ガイドライン(仕様)とレビュー(運用)をセットで回します。作業者間の一致度を確認し、境界事例の定義を更新していくとラベルの揺れが減ります。
https://aclanthology.org/J08-4004.pdf
共同開発で最低限必要なメタデータは何ですか
作成経緯、利用制約、ラベル定義、分割ルール、前処理履歴が最低限です。不足すると誤共有・誤利用・再現不能につながります。
オープンデータセットなら自由に使ってよいですか
「オープン=無条件」ではありません。商用利用、改変、再配布、クレジット表記、継承条件などがライセンスで指定されます。条文と配布元の利用規約を確認する運用が必要です。
https://creativecommons.org/licenses/by/4.0/legalcode.en
https://opendatacommons.org/licenses/odbl/
参考文献
- scikit-learn: Common pitfalls and recommended practices(Data leakageの注意点)
https://scikit-learn.org/stable/common_pitfalls.html - Gebru, T. et al. “Datasheets for Datasets” (arXiv)
https://arxiv.org/abs/1803.09010 - Holland, S. et al. “The Dataset Nutrition Label” (arXiv)
https://arxiv.org/abs/1805.03677 - Artstein, R., Poesio, M. “Inter-Coder Agreement for Computational Linguistics” (ACL Anthology PDF)
https://aclanthology.org/J08-4004.pdf - NIST “Artificial Intelligence Risk Management Framework (AI RMF 1.0)” (PDF)
https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.100-1.pdf - NIST “Security and Privacy Controls for Information Systems and Organizations (SP 800-53 Rev. 5)”
https://csrc.nist.gov/publications/detail/sp/800-53/rev-5/final - Creative Commons “Attribution 4.0 International (CC BY 4.0) Legal Code”
https://creativecommons.org/licenses/by/4.0/legalcode.en - Open Data Commons “Open Database License (ODbL) v1.0”
https://opendatacommons.org/licenses/odbl/ - EUR-Lex “Regulation (EU) 2016/679 (GDPR) Official Journal”
https://eur-lex.europa.eu/eli/reg/2016/679/oj/eng
バックナンバーはこちら
深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト

徹底攻略ディープラーニングG検定ジェネラリスト問題集

ディープラーニングG検定(ジェネラリスト) 法律・倫理テキスト


コメント