
その他のエッセイはこちら

- 合わせて読むことおすすめの記事
- 解説動画
- 要約(3行)
- この記事で扱うこと:難易度論争ではなく「難化体感が生まれる構造」と戻し方
- まず温度計を固定:G検定の公式ゴールは「暗記」ではなく判断・説明
- なぜ今「暗記ゴール化(ゴール誤認)」が起きやすいのか:善意の“入口最適化”が中間ゴールを増幅する
- 「難化体感」として観測されやすい4つのメカニズム
- 暗記ゴール化を防ぐ勉強法:公式で較正して“線”に戻す4ステップ
- ステップ1:公式で較正する(週1回、10分)
- ステップ2:復習は「3行だけ」に固定(毎問・毎日)
- ステップ3:週次診断で“暗記モード”を早期に戻す(週5分)
- ステップ4:変化領域(法務・AIガバナンス)は一次情報で「境界だけ」押さえる
- 3行復習の実例:ResNet(用途・つながり・境界)
- 生成AIパスポート比較:なぜ“暗記事故”が表に出にくいのか
- 付録:情報量$I$と較正$A$で見る“ゴール誤認”の最小モデル(おもちゃ)
- FAQ
- まとめ:難化体感は“試験”だけでなく“情報環境”で増幅します
- 合わせて読むことおすすめの記事
- 参考文献
- まず「公式で較正」するための軸
- 「点→線」に戻す:ディープラーニング理解を固める
- 法務・AI倫理・ガバナンス
- 生成AI/LLM(比較パート・最新領域の補強)
- 情報過多に負けない「学習設計」
合わせて読むことおすすめの記事
G検定まとめ記事

G検定難化の関連(別視点)記事
本記事はゴール設定モデル(受験者側:学習ゴールのズレ)を扱います。
一方こちらは作問モデル(問いの作られ方・ひねり方)から整理します。
併読すると「どこでズレたか」を受験者側/試験側の両面で点検できます。

究極カンペ×用語集カンペ(暗記ゴールの先を認識できます)
用語集カンペ(暗記ゴールも網羅性という意味では重要な価値があることを認識できます)

解説動画

要約(3行)
- G検定の「難化体感」は、試験そのもの以上に“情報環境”が生む学習ゴールのズレ(暗記ゴール化)で増幅しやすいです。
- 対策の核は「公式(概要・例題/過去問・シラバス)で較正」して、問われ方の温度感に合わせ直すことです。
- 復習は「用途・つながり・境界」の3行固定で、暗記の点を“判断・説明”の線へ戻します。
この記事で扱うこと:難易度論争ではなく「難化体感が生まれる構造」と戻し方
本記事は「G検定が本当に難化したか」を断定しません。難化談が繰り返し出るなら、試験難度の変化だけでなく、情報環境と学習ゴールのズレが先に疑うべき変数だからです。
結論はシンプルです。
「暗記ゴール化(ゴール誤認)」を前提に設計し、公式で較正し、3行復習で線に戻す。
これが、情報が多いほど崩れやすい学習を立て直す最短ルートです。
まず温度計を固定:G検定の公式ゴールは「暗記」ではなく判断・説明
学習設計で最初にやるべきは、温度計(ゴール定義)を公式に固定することです。ここがブレると、努力の向きがズレます。
- G検定とは(狙い・全体像):https://www.jdla.org/certificate/general/
- 公式の例題・過去問(問われ方の温度感):https://www.jdla.org/certificate/general/issues/
- シラバス(出題範囲の地図):https://www.jdla.org/download-category/syllabus/
G検定は、AI・ディープラーニングを体系的に学び、活用可否や要件を理解する趣旨として説明されています。したがって、学習ゴールは「用語を言える」より、状況に対して概念を適用し、条件・限界(境界)まで含めて判断・説明できる側に置くのが筋です。
ここがズレると、勉強量を増やしても点数が伸びにくくなります。
なぜ今「暗記ゴール化(ゴール誤認)」が起きやすいのか:善意の“入口最適化”が中間ゴールを増幅する
受験者増×情報過多で「楽に始められる方法」が大量に供給されます
受験者が増えるほど、周辺情報(問題集・解説・動画・SNSのノウハウ)は増えます。たとえばJDLAは開催結果として受験者数・合格率などを公表しています。
https://www.jdla.org/news/20251125001/
ここで重要なのは、「情報が増える=悪」ではないことです。多くの発信は善意で作られています。初学者が止まりやすいのは自然なので、発信者は自然にこういう形へ最適化します。
- まず手を動かせる(やることが明確)
- すぐ成果が出る(覚えた実感が得られる)
- 不安が減る(“これだけやれば”が提示される)
- 時間が読める(短時間・頻出・まとめ)
これは、初学者が「とにかく動ける」ための仕掛けとして正しいです。最初の一歩を踏ませる「足場」だからです。
善意の「足場」が、そのまま“ゴール”に見えてしまう
発信者が提供しているのは、多くの場合 「手を動かしやすくするための中間ゴール」です。
たとえば「頻出用語を回す」「定義を言える」「暗記カードで回転数を上げる」は、初学者が前に進むための有効な手段です。
しかし情報が多い環境では、受け手(特に初学者)がこう誤認しやすくなります。
- 本来の中間ゴール:用語が言える/定義が言える/頻出が回せる(=動き出すための足場)
- 本来の最終ゴール:状況に対して概念を適用し、条件・限界(境界)まで判断・説明できる(=本番の要求)
このとき起きるのが、「足場(中間ゴール)=到達点(最終ゴール)」に見える現象です。
これが本記事でいう 暗記ゴール化(ゴール誤認)です。
暗記ゴール化は「努力不足」ではなく「設計ミス」で起きます
暗記ゴール化は、怠けているからではありません。むしろ逆で、努力の方向が“入口最適化”に固定されてしまうことで起きます。
- 入口の正解(まず覚えて動く)が、ずっと正解に見えてしまいます
- 点(用語・定義)を増やすほど、前に進んでいる感覚が強くなります
- その結果、線(適用・横断・境界)へ移るタイミングを失います
そして本番で求められる「適用・横断・境界」に触れた瞬間、ズレが露呈し、失速体験が「難化した」という体感に圧縮されやすくなります。
「難化体感」として観測されやすい4つのメカニズム
1)ズレが露呈した瞬間の失速が、強く記憶に残ります
暗記でも一定点は取れますが、適用・横断・境界の問いでズレが出ると失速体験が強く残り、「難化した」という言葉に圧縮されやすいです。
2)情報過多は点(断片処理)に寄せ、線(理解)を削ります
情報過多が意思決定やパフォーマンスに影響しうることは、レビューでも整理されています。
https://www.frontiersin.org/journals/psychology/articles/10.3389/fpsyg.2023.1122200/full
学習における認知負荷(処理資源の奪い合い)が学習効率を落としうる議論は古典的にもあります。
https://www.sciencedirect.com/science/article/pii/0364021388900237
3)難しかった設問だけが共有され、体感が上方に歪みます
拡散されやすいのは「ひねり」「迷い」「横断」です。全体難度ではなく“難しかった話”が前に出て、体感が上がりやすくなります。
4)シラバス更新が「不安→点回収→暗記ゴール化」を加速します
シラバス更新は地図の更新であり悪ではありません。ただ、不安が強いと「暗記リストを増やす」方向に反応しやすいです。範囲は公式シラバスで固定し、過不足を調整するのが安全です。
https://www.jdla.org/download-category/syllabus/
暗記ゴール化を防ぐ勉強法:公式で較正して“線”に戻す4ステップ
ここからが本題です。やることは増やしません。向きを戻すだけです。
- 週1:公式で較正(温度計を固定)
- 毎問・毎日:3行復習(点を線に戻す)
- 週5分:暗記モード診断(早期に戻す)
- 変化領域:一次情報で境界だけ固める
ステップ1:公式で較正する(週1回、10分)
参照先はこの3つで十分です。
- 概要(ゴール):https://www.jdla.org/certificate/general/
- 例題・過去問(問われ方):https://www.jdla.org/certificate/general/issues/
- シラバス(範囲):https://www.jdla.org/download-category/syllabus/
やることは3つです。
- 例題・過去問を見て「どこまで言えれば正解か」を短くメモします
- シラバス見出しで、抜けと偏り(得意だけ回す)を見つけます
- 外部教材は使ってOKですが、採用判断の温度計は“公式の温度感”に置きます
ステップ2:復習は「3行だけ」に固定(毎問・毎日)
増やすほど続かないので、どの問題も3行に固定します。
- 用途:何のための概念か(何を解決するか)
- つながり:どこに位置し、何と組み合わさるか(前提・関連)
- 境界:どこまで通用するか(例外・限界・条件、混同しやすさ)
コピペ用テンプレ:
【用途】(何を解決する?どんな場面で使う?)
【つながり】(前提は?関連する概念・手法・指標は?どこに位置づく?)
【境界】(何と混同しやすい?いつ使えない?例外・限界・条件は?)3行が書けない箇所は、「点はあるが線がない」サインです。そこだけ公式や一次情報で補強します。
ステップ3:週次診断で“暗記モード”を早期に戻す(週5分)
次の前兆が1つでもあれば診断します。
- 問題数は増えたのに正答率が横ばい/落ちてきます
- 同じ領域で毎回迷います(理由の説明ができません)
- 暗記カードやノートだけ増え、復習が追いつきません
- 新しい対策情報を探す時間が増え、公式例題・過去問が減ります
- 用語は言えるのに「いつ使うか/いつ使えないか」で詰まります
処方箋はシンプルです。
- 1週間だけ追加インプットを止め、3行復習を最優先します
- 公式例題・過去問で“境界の聞かれ方”に言い方を合わせ直します:https://www.jdla.org/certificate/general/issues/
- 3行のうち弱い行だけ埋めます(用途が弱い/境界が弱い、など)
ステップ4:変化領域(法務・AIガバナンス)は一次情報で「境界だけ」押さえる
変化が速い領域ほど、まとめより一次情報が堅いです。暗記項目を増やすのではなく、境界(何が求められるか・何がNGか)を固めます。
- 経済産業省:AI事業者ガイドライン(PDF)
https://www.meti.go.jp/shingikai/mono_info_service/ai_shakai_jisso/pdf/20250328_1.pdf - 内閣府:人工知能関連技術の研究開発及び活用の推進に関する法律(AI法)
https://www8.cao.go.jp/cstp/ai/ai_act/ai_act.html - デジタル庁:行政の進化と革新のための生成AIの調達・利活用に係るガイドライン(告知ページ)
https://www.digital.go.jp/news/3579c42d-b11c-4756-b66e-3d3e35175623
3行復習の実例:ResNet(用途・つながり・境界)
- 用途:深いCNNを学習しやすくして精度を上げるための設計です(深層化で最適化が難しくなる問題に効きます)。
- つながり:スキップ接続(残差)で $y=x+F(x)$ の形にし、勾配の流れを助けます。CNNやBatchNorm等と組み合わせ、深層化する文脈で出ます。
- 境界:万能ではありません(計算量・メモリ制約は残ります)。DenseNet等の接続設計と混同しやすいです。制約が強いなら軽量モデル(MobileNet等)が優先されることもあります。
原典(arXiv PDF):https://arxiv.org/pdf/1512.03385.pdf
生成AIパスポート比較:なぜ“暗記事故”が表に出にくいのか
生成AIパスポートは、生成AIの基礎知識・動向・活用に加え、情報漏洩や権利侵害などの注意点まで扱う狙いが明記されています。
https://guga.or.jp/outline/
また、シラバス改訂や適用時期、更新テストなどの告知がまとまり、アップデート対象が見えやすい設計です。
https://guga.or.jp/2025-10-01/1100-1
ここで言いたいのは優劣ではありません。中間ゴールが最終ゴールと乖離しやすいかという「学習設計上の事故りやすさ」の違いです。
- G検定:最終ゴールが「適用・限界・条件(境界)まで含めた判断・説明」に寄ります。足場としての暗記を“ゴール”に誤認すると、ズレが本番で露呈しやすいです。
- 生成AIパスポート:設問によっては、用語理解(定義・注意点の把握)でも正答が作りやすい局面があり、中間ゴールが“たまたま”最終ゴールに近い状態で成立しやすい側面があります。
つまり、G検定は暗記ゴール化のダメージが表面化しやすい構造になりがちです。だからこそ「公式で較正」と「3行復習」で、早めに線へ戻すのが勝ち筋になります。
付録:情報量$I$と較正$A$で見る“ゴール誤認”の最小モデル(おもちゃ)
本文の主張(情報過多は誤認を増やし、公式較正は誤認を下げる)を、直感だけでなく最小構造でも補助します。合否や難易度を予測するものではありません。
変数の定義
- $I$:学習に流入する情報量(対策情報、暗記項目の増加など)
- $A$:公式・例題・一次情報で学習の向きを補正できる強さ
例として $A$ を3要素の平均で置きます。
$A=\displaystyle \frac{A_{\mathrm{official}}+A_{\mathrm{examples}}+A_{\mathrm{primary}}}{3}$
しきい値モデル(ゴール誤認の起きやすさ)
$p(I,A)=\displaystyle \frac{1}{1+\exp(-(k(I-I_0)-bA))}$
読み方はシンプルです。$I$が増えるほど誤認が増えやすい一方で、$A$が強いほど同じ$I$でも誤認が下がる、という最小構造です。
Pythonで比較(表示のみ)
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(z):
return 1 / (1 + np.exp(-z))
def p(I, A, k=1.4, I0=5.0, b=1.0):
# Toy model (not predictive)
return sigmoid(k * (I - I0) - b * A)
# "較正の強さ A" の違いとして2本の曲線を描く(数値は説明用の仮定)
A_gkentei = 1.8
A_genai_passport = 4.2
I = np.linspace(0, 10, 400)
plt.figure()
plt.plot(I, p(I, A_gkentei), label="G-kentei (A=1.8)")
plt.plot(I, p(I, A_genai_passport), label="GenAI Passport (A=4.2)")
plt.xlabel("Information volume I")
plt.ylabel("Goal misrecognition probability p")
plt.title("Toy comparison: p(I, A)")
plt.legend()
plt.tight_layout()
plt.show()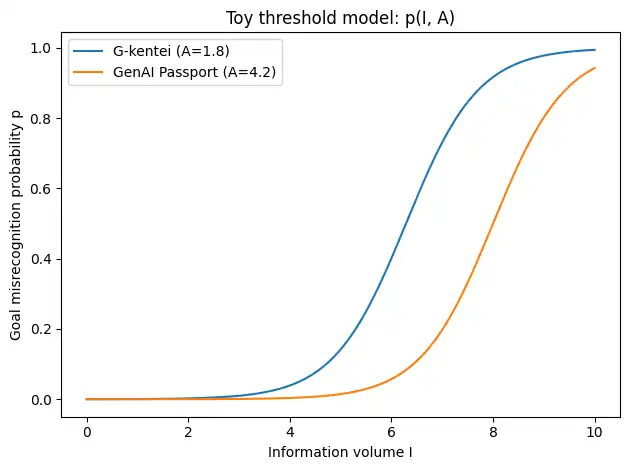
FAQ
Q1. 「難化した!」は本当に試験が難しくなった証拠ですか?
証拠にはなりにくいです。体感は、難しかった設問の記憶や拡散、そして暗記ゴール化(中間ゴールの最終ゴール化)の露呈に引っ張られやすいです。本記事は難化断定ではなく、ズレの検知と復帰手順(公式で較正+3行復習)に絞って扱います。
Q2. なぜ情報が増えるほど暗記ゴール化が起きるのですか?
善意の発信ほど「初学者が手を動かしやすい形(用語・頻出・短時間)」に最適化されます。これは動き出すための足場として有効ですが、その足場を“ゴール”と誤認すると、最終ゴール(適用・境界・説明)への移行が遅れ、ズレが本番で露呈しやすくなります。
Q3. 公式の例題・過去問はどう使えばいいですか?
「何が問われ、どこまで言えれば正解か」を掴む温度計として使います。数を増やすより、3行復習(用途・つながり・境界)の言い方を公式の問い方に合わせて揃えるほうが効きます。
https://www.jdla.org/certificate/general/issues/
Q4. 外部の問題集や講座は使わない方がいいですか?
使ってOKです。ただし採用判断の温度計は公式(概要・例題/過去問・シラバス)に置くのが安全です。
https://www.jdla.org/certificate/general/
Q5. 3行復習がうまく書けません。どうすればいいですか?
書けない箇所は「点はあるが線がない」サインです。定義を増やす前に、用途(いつ使うか)と境界(いつ使えないか)を、公式の問い方に合わせて補強してください。
Q6. 法務・AIガバナンスはどう勉強すればいいですか?
暗記項目を増やすより、一次情報で「境界(求められること/NG)」を押さえるのが安全です。更新が速い領域ほど、まとめより一次情報が堅いです。
https://www.meti.go.jp/shingikai/mono_info_service/ai_shakai_jisso/pdf/20250328_1.pdf
https://www8.cao.go.jp/cstp/ai/ai_act/ai_act.html
まとめ:難化体感は“試験”だけでなく“情報環境”で増幅します
G検定の「難化体感」は、実難化だけでなく、情報過多によって「用語暗記=ゴール」と誤認しやすくなる構造でも生まれます。
対策は、公式(概要・例題/過去問・シラバス)で温度計を固定し、復習を「用途・つながり・境界」の3行に固定して、点学習を判断・説明へ戻すことです。
まとめのまとめ(3行)
- 善意の対策情報ほど“始めやすい足場”として有効ですが、足場をゴールと誤認すると失速しやすいです。
- そのズレは本番の適用・横断・境界で露呈し、「難化した」という体感に圧縮されやすいです。
- 「公式で較正」+「用途・つながり・境界」の3行復習で、点を線に戻すのが最短です。
その他のエッセイはこちら
合わせて読むことおすすめの記事
G検定まとめ記事
G検定難化の関連(別視点)記事
本記事はゴール設定モデル(受験者側:学習ゴールのズレ)を扱います。
一方こちらは作問モデル(問いの作られ方・ひねり方)から整理します。
併読すると「どこでズレたか」を受験者側/試験側の両面で点検できます。
究極カンペ×用語集カンペ(暗記ゴールの先を認識できます)
用語集カンペ(暗記ゴールも網羅性という意味では重要な価値があることを認識できます)
参考文献
- 一般社団法人日本ディープラーニング協会(JDLA)「G検定とは」https://www.jdla.org/certificate/general/
- 一般社団法人日本ディープラーニング協会(JDLA)「G検定の例題・過去問」https://www.jdla.org/certificate/general/issues/
- 一般社団法人日本ディープラーニング協会(JDLA)「シラバス(出題範囲)」https://www.jdla.org/download-category/syllabus/
- 一般社団法人日本ディープラーニング協会(JDLA)「2025年 第6回 G検定(ジェネラリスト検定)開催結果」https://www.jdla.org/news/20251125001/
- 生成AI活用普及協会(GUGA)「生成AIパスポート(概要)」https://guga.or.jp/outline/
- 生成AI活用普及協会(GUGA)「生成AIパスポート:2026年試験のシラバス改訂」https://guga.or.jp/2025-10-01/1100-1
- Frontiers in Psychology (2023) “Dealing with information overload: a comprehensive review” https://www.frontiersin.org/journals/psychology/articles/10.3389/fpsyg.2023.1122200/full
- Sweller, J. (1988) “Cognitive load during problem solving: Effects on learning” https://www.sciencedirect.com/science/article/pii/0364021388900237
- He, K., Zhang, X., Ren, S., Sun, J. (2015) “Deep Residual Learning for Image Recognition” https://arxiv.org/pdf/1512.03385.pdf
- 経済産業省「AI事業者ガイドライン(PDF)」https://www.meti.go.jp/shingikai/mono_info_service/ai_shakai_jisso/pdf/20250328_1.pdf
- 内閣府「人工知能関連技術の研究開発及び活用の推進に関する法律(AI法)」https://www8.cao.go.jp/cstp/ai/ai_act/ai_act.html
- デジタル庁「行政の進化と革新のための生成AIの調達・利活用に係るガイドライン」https://www.digital.go.jp/news/3579c42d-b11c-4756-b66e-3d3e35175623
まず「公式で較正」するための軸
『深層学習教科書 ディープラーニングG検定(ジェネラリスト)公式テキスト

徹底攻略ディープラーニングG検定ジェネラリスト問題集

「点→線」に戻す:ディープラーニング理解を固める
ゼロから作るDeep Learning Pythonで学ぶディープラーニングの理論と実装

深層学習(Deep Learning)

法務・AI倫理・ガバナンス
ディープラーニングG検定(ジェネラリスト)法律・倫理テキスト

AIガバナンス入門 リスクマネジメントから社会設計まで

生成AIの法律実務

AIと法 実務大全

AIの倫理リスクをどうとらえるか 実装のための考え方

生成AI/LLM(比較パート・最新領域の補強)
公式テキス 生成AIパスポート テキスト&問題集

誰でもわかる大規模言語モデル入門

仕組みからわかる大規模言語モデル 生成AI時代のソフトウェア開発入門

生成AIのしくみ

LangChainとLangGraphによるRAG・AIエージェント[実践]入門

情報過多に負けない「学習設計」
使える脳の鍛え方 成功する学習の科学

認知負荷理論


コメント