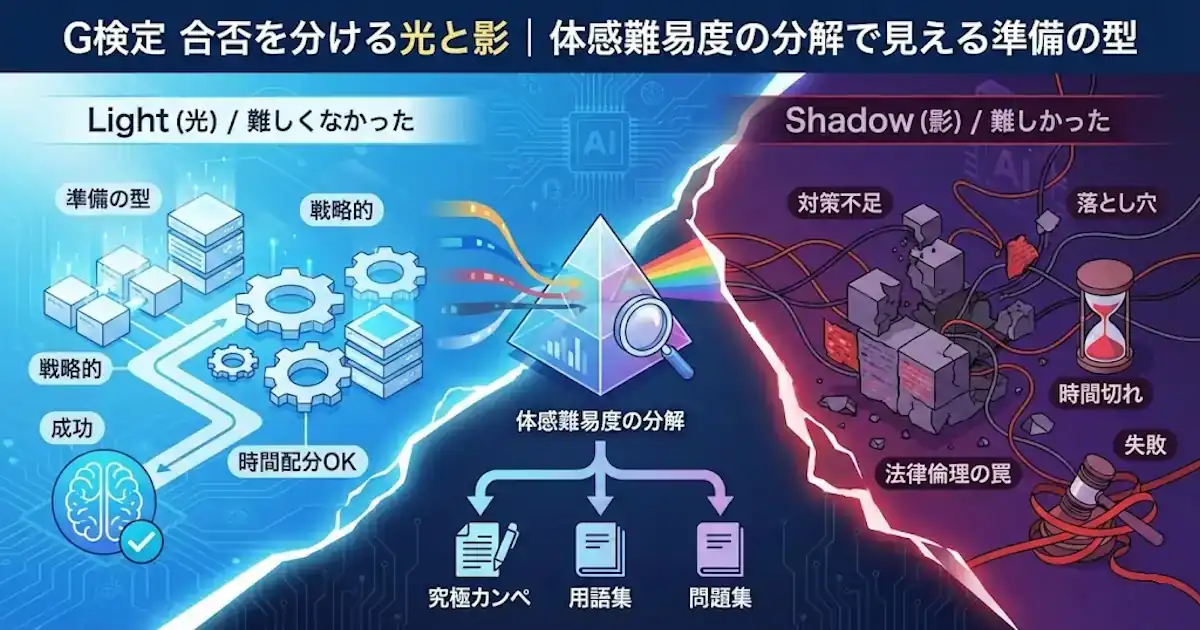
要約(3行)
・合否の境界は見えにくいので、合否だけで断定せず体感難易度の分解で整理します。
・難しかったの中身は「対策不足」と「対策しても難しい」に割れ、事故は法律倫理と時間配分に寄りやすいです。
・難しかったけど合格した体験談は有益な一方、鵜呑みにすると落ちやすい方向へ寄るリスクもあります。
- 合わせて読むことおすすめの記事
- 動画解説
- セルフ診断3問
- はじめに:合否の分け目は断定しない方針
- n=13の補足:どの回・オンライン/会場・学習量レンジ
- 観測データ:難しくなかった/難しかった(n=13)
- 難しかったの分解:対策不足/対策しても難しい
- n=13の内訳:職種ラベルは合否を決め切らない
- 光:難しくなかった側が先に固定している前提
- 影:対策不足パターンが崩れやすい理由
- 影の深掘り:対策しても難しいが割れる理由
- 統計としての限界:観測メモとSNSの読み方
- 注意:難しかったけど合格した体験談を信じすぎるリスク
- 時間配分:100分145問テンプレ
- 法律倫理:事故回避の設計
- 情報過多:カットラインと優先順位
- 実力測定:測るだけに寄せる
- カンペ問題:禁止前提、学習装置として活用
- 導線設計:究極カンペ/用語集カンペ/実力測定問題集
- まとめ
- FAQ
- 参考文献
- 合わせて読むことおすすめの記事
- 生存者バイアス/統計っぽい数字を疑う(認知バイアス・統計リテラシー)
- 情報過多を切る/優先順位固定(集中・選択・時間)
- 法律倫理/AI倫理・ガバナンス(「事故らない設計」の思想)
- シラバスの地図(深層学習の全体像を固める)
- 迷いを減らす/課題設定(「型」を作る思考法)
- 最小セット
合わせて読むことおすすめの記事





動画解説

セルフ診断3問
冒頭に分岐を置きます。模試・実力測定(なければ問題演習)を1回やった前提で答えると精度が上がります。ここは合否の断定ではなく、優先順位を間違えないための分岐です。
Q1: 100分で最後まで到達できましたか(未回答ゼロ)
Q2: 法律・倫理の正答率が、他分野より明確に低いですか
Q3: 30秒以上迷う設問が、全体の2割以上ありますか
判定(このページ内の優先順位)
- Q1がいいえ
最優先: 時間配分テンプレ(1周目80分+見直し20分)
次点: 実力測定(問題集)で「時間が足りない原因」を特定します
連動: 迷いの原因を究極カンペへ戻して潰します
https://www.simulationroom999.com/blog/g-test-measures-problem-collection/
https://www.simulationroom999.com/blog/g-kentei-ultimate-kanpe-learning-method/ - Q2がはい
最優先: 法律・倫理を「満点狙い」から「事故らない設計」へ切り替えます
次点: 用語集カンペで取りこぼしを塞ぎます
https://www.simulationroom999.com/blog/g-kentei-syllabus-2024-excel-glossary-cheatsheet/ - Q3がはい
最優先: 迷いが長い設問を後回しにします(10秒/30秒ルール)
次点: 実力測定(問題集)で迷いが長い設問の傾向を掴みます
連動: 結果を究極カンペ・用語集カンペへ反映します
https://www.simulationroom999.com/blog/g-test-measures-problem-collection/ - Q1がはい、Q2がいいえ、Q3がいいえ
方向性: 光(難しくなかった側)に寄っています
仕上げ: 情報過多の遮断と当日運用の固定でブレを減らします
https://www.simulationroom999.com/blog/gkentei-difficulty-perception-info-overload-rote-goal-misrecognition-official-calibration/
はじめに:合否の分け目は断定しない方針
読者が一番知りたいのは合否の分け目だと思います。ただ、受験者側から見える情報だけで、その分け目を正確に言い切るのは難しいです。合格ラインや得点が開示されない前提もあります。
https://www.jdla.org/g-qa/
そこでこの記事は、合否だけを材料に結論を出しません。代わりに、受験後に本人が感じた体感難易度を起点にして、
- 難しくなかった
- 難しかった
に分け、さらに難しかったを
- 対策不足
- 対策しても難しい
に分解して、光(うまくいきやすい型)と影(落とし穴)を整理します。
n=13の補足:どの回・オンライン/会場・学習量レンジ
ここで出てくるn=13は、身近な受験者から聞けた観測メモです。統計調査のサンプルではありません。一般化の根拠にしません。落ちやすい事故の型を言語化する材料として扱います。
前提(観測メモの注記)
- ヒアリング人数: 13人(知人・同僚)
- 受検回: 2024年~2026年
- 全員オンライン受験
- 2024年のシラバス改定後の範囲が前提(2024 #6)
https://www.jdla.org/news/20240514001/
https://www.jdla.org/download-category/syllabus/ - 学習量レンジ(目安)
対策不足: テキスト1周で止まる/テキスト2周+問題集1周で止まる、など
対策しても難しい: テキスト3周+問題集2周以上、など(量は足りても当日事故で割れやすい)
観測データ:難しくなかった/難しかった(n=13)
周辺ヒアリング(n=13)を、まず体感難易度で二分します。標本数が少ないので統計的な主張はしませんが、失敗パターンの切り分けには使えます。
| 体感 | 人数 | 内訳(合格 / 不合格) |
|---|---|---|
| 難しくなかった | 5 | 5 / 0 |
| 難しかった | 8 | 3 / 5 |
ポイントは、難しかったが不合格を意味しない点です。難しかったけど合格した人もいます。
難しかったの分解:対策不足/対策しても難しい
次に、難しかった(n=8)を二分します。
| 難しかったの内訳 | 人数 | 内訳(合格 / 不合格) |
|---|---|---|
| 対策不足 | 4 | 1 / 3 |
| 対策しても難しい | 4 | 2 / 2 |
ここから言えるのは、難しかったという感想には別の種類が混ざっているということです。対策不足は分かりやすい一方で、対策しても難しいは学習の向きや当日事故で割れやすいです。
n=13の内訳:職種ラベルは合否を決め切らない
この分類は属性ラベルで、能力の優劣を決める意図はありません。ポイントは、職種だけで勝敗は決まらないということです。
n=13 の内訳(観測メモ)
- 3 数理的なものを業務扱っている。合格 2 / 3
- 8 いわゆるITエンジニア系。合格 4 / 8
- 2 非エンジニア。合格 2 / 2
ポイント(観測メモから見えた傾向)
- 数理的なものを業務で扱っている人でも、準備不足なら落ちます
落ち方は、知識がないより情報収集不足に寄りやすいです。具体的には、法律倫理が前半連発で精神的にやられた、時間配分を間違った、のような当日事故です。 - 標本数はかなり少ないですが、非エンジニア系も普通に受かります
シラバス準拠+時間配分の型+実力測定(問題集)が揃えば戦えます。 - いわゆるITエンジニア系の合格率が50%と低め見えますが、能力差というより対策時間の差として説明しやすいです
「業務負荷の都合で対策時間を取れたか取れなかった」が、結果に影響しているように見えます。
合格・不合格に関しては、いわゆる理系・文系の影響は少ないという見立てです。
実際、理系的な言葉が多い反面、歴史的背景、技術分野の大まかな地図、法律倫理などは文系的アプローチの方が筋が良い場合が多いです。
どれだけ効果的な対策ができたかが支配的と見た方が良いかと思います。
ただし、合格者の中で高得点を取っているのは理系側などの偏りはあるかもしれません。
当然これは、公式情報やn=13の情報からは特定できません。
光:難しくなかった側が先に固定している前提
難しくなかった側は、知識量だけで勝っているというより、試験の前提を先に固定している印象です。
- 物量と時間制限を前提として、迷い方を設計しています
オンライン試験は100分、問題数は145問程度と案内されています。
https://www.jdla.org/g-qa/
https://www.jdla.org/certificate/general/ - 当日トラブル時でも試験時間が止まらない前提で、環境確認と切り替えを準備しています
受験者向け操作マニュアルに、試験時間が止まらない旨が記載されています。
https://docs.jdla-exam.org/OperationManual_Examinees_JP.pdf
知識の上積みより前に、この2点を固定するだけで体感難易度が下がりやすいです。ここが光側です。
影:対策不足パターンが崩れやすい理由
対策不足パターンは、だいたい次の形に収束します。
- テキスト1周はしたが、問題集を回し切れていません
- テキスト2周+問題集1周で止まり、時間内に解き切る訓練が不足しています
- 出題範囲を眺めたが、当日のスピード感に合わせた出力が作れていません
この層の典型的な事故は、知識不足そのものより、時間の中で迷いを抱え続けることです。迷いが増えるほど、後半の焦りが増え、さらに迷いが増えます。影が濃くなります。
影の深掘り:対策しても難しいが割れる理由
対策しても難しいは、量より向きで割れやすいです。ここは影の中でも、気づきにくい影です。
問題演習偏重
問題を回すほど反射は速くなりますが、間違いの理由が言語化されないまま周回すると、当日も同じ迷いを繰り返します。分野ジャンプ耐性が弱いままだと、体感として難しくなります。
単語暗記偏重
用語を広く拾える一方で、条件・例外・背景が薄いと、選択肢の差分で落としやすいです。法律・倫理は特に、知っていると選べるがズレやすいです。
当日事故(法律倫理・時間配分・情報過多)
量は足りていても、当日事故で割れます。事故はだいたいこの3つに寄ります。
- 法律倫理で時間が溶ける/メンタルが削られる
- 時間配分が崩れて後半が雑になる
- 情報過多で準備の軸がブレる(直前に詰め込みすぎる)
統計としての限界:観測メモとSNSの読み方
ここは誤解されやすいので、強めに書きます。
- n=13の観測メモは統計情報ではありません
少数だと、試験回の癖や運の要素が結果を支配しやすくなります。さらに、知人の集まりなので母集団が偏ります。比率が簡単に動くので、一般化してはいけません。 - SNSやネットの統計っぽい情報も一旦はフィルタした方が安全です
受かった人は書きやすく、落ちた人は書きにくいので、生存者バイアスが強く効きます。投稿者の前提(素地・試験慣れ・業務負荷・学習時間)が見えないことも多く、母集団の偏りを補正できません。結果として、数字や割合が書いてあっても、そのまま統計情報として扱うのは危険です。
生存者バイアスが調査結果の解釈に影響しうる点は、研究分野でも指摘されています。
https://www.cambridge.org/core/journals/epidemiology-and-psychiatric-sciences/article/uncovering-survivorship-bias-in-longitudinal-mental-health-surveys-during-the-covid19-pandemic/579D8517717288AD48682914FA35E116
結論として、現状そのまま統計情報として見てよいものは、公式が開示している情報だけだと思っておく方が安全です。
https://www.jdla.org/g-qa/
注意:難しかったけど合格した体験談を信じすぎるリスク
ここがこの記事で一番言いたい注意点です。
難しかったクラスタには合格者が含まれます。なのでネット上の合格体験記にも、
- 難しかったけど合格した人
- 難しかったし不合格だった人(書かれにくい)
が混在している可能性があります。
このとき、難しかった合格者の意見だけを強く信じると、落ちやすい方向に寄るリスクがあります。
まず、G検定は合格率が高く、対策がうまく行っていなくとも合格する可能性は十分にあります。
よって、
- 「難しかったけど合格した」という声には、対策が甘くても受かったケースが含まれうる
- 合格者の体験談だけが目立つと、不合格者の感覚が見えず、難易度認識が甘くなりやすい
- その結果、「難しくても受かるだろう」と見積もってしまい、必要な対策量を下回るリスクがある
SNS・ネットの合格記は参考になりますが、最終判断は公式情報と自分の実力測定(問題集)に寄せた方が安全です。
https://www.jdla.org/g-qa/
https://www.simulationroom999.com/blog/g-test-measures-problem-collection/
時間配分:100分145問テンプレ
オンライン試験は100分、問題数は145問程度と案内されています。
https://www.jdla.org/g-qa/
145問を100分で割ると、1問あたり約41秒です。ここで当日戦略の差が出ます。迷いを封じ込めるテンプレを固定します。
テンプレ(おすすめ)
- 1周目 80分
目的: 取れる問題を取り切り、迷いを抱えません
145問で80分なので平均約33秒です - 見直し 20分
目的: 1周目で印を付けた問題だけを回収します
1周目のルール(迷いの封じ込め)
- 10秒で方針が立たない問題は印を付けて飛ばします
- 30秒を超えて迷ったら、印を付けて飛ばします
- 調べる前提で粘りません(時間が溶けます)
見直しのルール(回収の最大化)
- 印を付けた問題だけを解く
- 未着手問題の探索はしない
- 法律倫理で削られても、テンプレどおりに淡々と回す
トラブル時の前提
- 操作トラブルがあっても試験時間は止まりません
https://docs.jdla-exam.org/OperationManual_Examinees_JP.pdf
法律倫理:事故回避の設計
法律・倫理は、分かっていないと焦り、焦ると時間が溶けます。ここは満点狙いより、事故らない設計にした方が合否に効きやすいです。
おすすめの割り切り
- 取る範囲を決めり
- 捨て問を作る
- 切り替えの速度を最優先にする
一次情報として最低限の地図に触れるなら、e-Govが使いやすいです。
個人情報保護法: https://laws.e-gov.go.jp/law/415AC0000000057
著作権法: https://laws.e-gov.go.jp/law/345AC0000000048/
実務寄りの全体像としては、経済産業省のAI事業者ガイドラインが読み物として有効です。
https://www.meti.go.jp/shingikai/mono_info_service/ai_shakai_jisso/20240419_report.html
情報過多:カットラインと優先順位
n=13もSNSも統計情報ではないので、数字っぽい情報は一旦フィルタします。生存者バイアスの影響を補正できない限り、統計としては扱いません。そのまま統計情報として見てよいものは、公式開示の情報だけだと思って進めます。
https://www.jdla.org/g-qa/
情報過多は、頑張っているのに落ちるを作りやすいです。先に優先順位を固定します。
優先順位
- 公式情報(試験時間・問題数・当日の運用)
https://www.jdla.org/g-qa/
https://docs.jdla-exam.org/OperationManual_Examinees_JP.pdf - シラバス(範囲の確定)
https://www.jdla.org/download-category/syllabus/ - 実力測定(問題集)(正答率・迷いの長い設問の傾向)
https://www.simulationroom999.com/blog/g-test-measures-problem-collection/ - その他(SNS、まとめ、合格記)
仮説として読み、手元の実力測定で裏が取れたものだけ採用します
カットライン(迷ったらこれ)
- 公式情報で決まることは、SNSで上書きしない
- シラバスにない話は、直前期に増やさない
- 実力測定で改善が見えない勉強は、捨てる
実力測定:測るだけに寄せる
問題集や演習は、暗記の道具というより測る道具として使う方が安全です。ここで細かいログの付け方や表の作り方は書きません。この記事の役割は、優先順位と当日事故の回避を固めることだからです。
この段階でやることはシンプルに2つだけです。
- 正答率の低い分野を見つけます
- 迷いが長い設問が多い分野を見つけます
その結果を、次の学習装置に戻して補正します。
- 判断軸が曖昧なら究極カンペへ戻します
https://www.simulationroom999.com/blog/g-kentei-ultimate-kanpe-learning-method/ - 用語の取りこぼしなら用語集カンペで塞ぎます
https://www.simulationroom999.com/blog/g-kentei-syllabus-2024-excel-glossary-cheatsheet/
問題集を実力測定として回す考え方は、こちらにまとめています。
https://www.simulationroom999.com/blog/g-test-measures-problem-collection/
カンペ問題:禁止前提、学習装置として活用
本番でカンペが許可されるかどうかは、公式情報と当日表示の受験規約に従うしかありません。当日の規約確認は受験直前になりやすいので、準備はカンペ禁止前提で組むのが安全です。
ただし、カンペを作る行為は学習装置として強力なので推奨できます。作る過程で判断軸が言語化され、迷い時間が短くなります。
https://www.simulationroom999.com/blog/g-kentei-kanpe-kinshi/
導線設計:究極カンペ/用語集カンペ/実力測定問題集
この記事を読んだ人が次に迷いやすいのは、何から手を付けるかです。おすすめの導線は、学習の役割で分けます。
究極カンペ:理解を接続する装置
問題演習偏重や単語暗記偏重を避けたいなら、学習装置としての設計思想を押さえるのが早いです。
https://www.simulationroom999.com/blog/g-kentei-ultimate-kanpe-learning-method/
作り方の流れはバックナンバーへ繋げます。
https://www.simulationroom999.com/blog/g-test-preparation-make-the-ultimate-cheat-papers-back-number/
用語集カンペ:範囲の取りこぼしを塞ぐ装置
覚えていない用語が残っている状態だと、難しかった側に寄りやすいです。漏れを塞ぐ用途で使います。
https://www.simulationroom999.com/blog/g-kentei-syllabus-2024-excel-glossary-cheatsheet/
学習時間感を掴みたい場合は、こちらも相性が良いです。
https://www.simulationroom999.com/blog/gtest-syllabus-study-time-self-transformer/
問題集:暗記の道具ではなく実力測定の道具
問題集は周回すると強くなりますが、目的が暗記になると見たことがあるから解けるに寄ります。おすすめは、実力測定を主目的にして、
- 分野別の弱点を可視化します
- 時間事故の芽(迷いが長い設問)を特定します
- 間違いの理由を究極カンペ/用語集カンペへ反映します
という往復にすることです。
https://www.simulationroom999.com/blog/g-test-measures-problem-collection/
まとめ
合否の分け目は断定しにくいので、体感難易度(難しくなかった/難しかった)を起点に、難しかったを分解して落とし穴を潰す方が再現性が上がります。特に法律倫理と時間配分は、知識量と別軸で事故を起こします。試験の前提(時間・トラブル時の挙動)を先に固定し、学習装置(究極カンペ・用語集カンペ)と実力測定(問題集)を役割分担させるのが安全です。
まとめのまとめ(3行)
・まず体感を「難しくなかった/難しかった」に分け、難しかったを原因別に分解します。
・事故は法律倫理と時間配分に寄りやすいので、公式情報で前提を固定します。
・難しかった合格体験談は参考にしつつ、鵜呑みにせず実力測定(問題集)で補正します。
FAQ
セルフ診断3問はいつ使うべきですか
模試・実力測定(なければ問題演習)を1回やった後に使うのが向いています。時間不足、法律倫理の弱さ、迷い時間の長さのどれが主因かが見えやすくなります。
難しかったは不合格という意味ですか
違います。難しかったけど合格した人もいます。難しかったという感想だけで学習方針を決めない方が安全です。
SNSやネットの統計っぽい情報は信じていいですか
そのまま統計情報として扱うのは危険です。受かった人の声が出やすいなど、生存者バイアスの影響を補正できないためです。統計情報として見てよいものは、公式が開示している情報だけだと思っておく方が安全です。
https://www.jdla.org/g-qa/
試験時間と問題数の前提はどこで確認すればいいですか
公式情報で確認します。オンラインは100分、問題数は145問程度と案内されています。
https://www.jdla.org/g-qa/
https://www.jdla.org/certificate/general/
試験中にトラブルが起きたら時間は止まりますか
止まりません。受験者向け操作マニュアルに、試験時間が止まらない旨が記載されています。
https://docs.jdla-exam.org/OperationManual_Examinees_JP.pdf
カンペは使っていいですか
本番で使えるかは当日表示の規約に従う前提です。準備はカンペ禁止前提で組み、学習装置としてカンペ作成を活用するのが安全です。
https://www.simulationroom999.com/blog/g-kentei-kanpe-kinshi/
参考文献
- 一般社団法人日本ディープラーニング協会(JDLA)G検定のよくある質問
https://www.jdla.org/g-qa/ - 一般社団法人日本ディープラーニング協会(JDLA)G検定(ジェネラリスト検定)公式ページ
https://www.jdla.org/certificate/general/ - 一般社団法人日本ディープラーニング協会(JDLA)シラバス配布ページ
https://www.jdla.org/download-category/syllabus/ - 一般社団法人日本ディープラーニング協会(JDLA)シラバス改訂および公式テキスト改訂のお知らせ(2024 #6)
https://www.jdla.org/news/20240514001/ - JDLA 受験者向け操作マニュアル(PDF)
https://docs.jdla-exam.org/OperationManual_Examinees_JP.pdf - 経済産業省 AI事業者ガイドライン
https://www.meti.go.jp/shingikai/mono_info_service/ai_shakai_jisso/20240419_report.html - e-Gov法令検索 個人情報の保護に関する法律
https://laws.e-gov.go.jp/law/415AC0000000057 - e-Gov法令検索 著作権法
https://laws.e-gov.go.jp/law/345AC0000000048/ - Epidemiology and Psychiatric Sciences(Cambridge)Uncovering survivorship bias in longitudinal mental health surveys during the COVID-19 pandemic
https://www.cambridge.org/core/journals/epidemiology-and-psychiatric-sciences/article/uncovering-survivorship-bias-in-longitudinal-mental-health-surveys-during-the-covid19-pandemic/579D8517717288AD48682914FA35E116
合わせて読むことおすすめの記事
生存者バイアス/統計っぽい数字を疑う(認知バイアス・統計リテラシー)
『ファスト&スロー あなたの意思はどのように決まるか?(上・下)』ダニエル・カーネマン

直感と判断のズレを体系的に扱う。SNSの体験談や“それっぽい数字”に引っ張られる理由を言語化しやすい。
『NOISE 組織はなぜ判断を誤るのか?(上・下)』ダニエル・カーネマンほか

「バイアス」より一段踏み込んで、判断の“ばらつき”そのものを扱う。学習方針や当日運用のブレを減らす発想と相性がいい。
『FACTFULNESS(ファクトフルネス)』ハンス・ロスリング

思い込み(直感)とデータのズレを、読みやすい形で矯正してくれる。情報過多を切る基準づくりにも効く。
『まぐれ―投資家はなぜ、運を実力と勘違いするのか』ナシム・ニコラス・タレブ

「生き残った話だけが残る」構造そのものへの感度が上がる。記事の“難しかった合格体験談の罠”と直結。
『統計学が最強の学問である』西内啓

「統計っぽい情報」と距離を取るための基礎体力がつく。試験に限らず、数字の扱いを武器にする系。
情報過多を切る/優先順位固定(集中・選択・時間)
『エッセンシャル思考 最少の時間で成果を最大にする』グレッグ・マキューン

「何を捨てるか」を決める本。記事の“情報過多のカットライン”を、生活・学習に落とし込むのに向く。
『エフォートレス思考』グレッグ・マキューン

“頑張りすぎて崩れる”側(影)に効く。型を回すために、摩擦を減らす発想が入る。
『限りある時間の使い方』オリバー・バークマン

「全部やる」幻想を捨てる系。直前期の詰め込み暴走を止めるのに効く。
『SLOW 仕事の減らし方』カル・ニューポート

“仕事量(タスク)を減らして本質に集中する”思想。試験対策でも「減らして勝つ」視点が入る。
法律倫理/AI倫理・ガバナンス(「事故らない設計」の思想)
『AIの倫理学』マーク・クーケルバーグ

AIの倫理論点を網羅的に整理するタイプ。法律倫理を「恐怖」ではなく「論点の地図」に変えやすい。
『あなたを支配し、社会を破壊する、AI・ビッグデータの罠』キャシー・オニール

モデルの不透明性・偏り・社会的影響を具体例で掴める。法律倫理の“事故回避”の腹落ちが強くなる。
『私たちはAIを信頼できるか』大澤真幸ほか

“信頼”という切り口で、技術・社会・言語など複数視点を行き来できる。倫理を暗記から思考へ戻したい時に向く。
シラバスの地図(深層学習の全体像を固める)
『ゼロから作るDeep Learning』斎藤康毅

手を動かしながら「なぜそうなるか」を理解する入門。用語暗記偏重を避けたい時に強い。
『深層学習』イアン・グッドフェローほか

理論まで含めて体系的に押さえる教科書枠。G検定レベルを超えて“地図”を作りたい人向け。
迷いを減らす/課題設定(「型」を作る思考法)
『新版 思考の整理学』外山滋比古

情報を集めるだけで終わらせず、整理して“自分の言葉の軸”にする発想が入る。
『イシューからはじめよ[改訂版]』安宅和人

「何を解くべきか」を先に決める本。直前期の情報過多を止める武器になる。
最小セット
- 生存者バイアス/統計っぽさ:『ファスト&スロー』+『ファクトフルネス』
- 情報過多カット:『エッセンシャル思考』
- 法律倫理の腹落ち:『あなたを支配し、社会を破壊する、AI・ビッグデータの罠』
- DLの地図:『ゼロから作るDeep Learning』
コメント