その他のエッセイはこちら


- ローカルLLMでも今回の規模なら自動調整ループは十分回せた
- 追従性の差はモデル性能だけでなく、指示の時間軸の書き方でも大きく変わった
- 実運用では GPT-5.4 と GPT-5.4-nano が有力で、ローカルLLMも閉域用途では十分候補になる
- 合わせて読むことおすすめの記事
- ソースコードなど
- はじめに
- 比較表
- システム全体像
- 図1 全体構成
- 制御器とplantの接続構成
- 実験条件
- 1 trial の処理フロー
- prompt設計の前提
- 具体的なprompt例
- 短い追加指示が効かなかった理由
- 指示は助言ではなく探索計画として書く
- OpenAI API側が有利に見えた理由
- ローカルLLMの位置づけ
- trial別波形比較
- 実運用での選び方
- 制御工学の文脈で見た位置づけ
- FAQ
- まとめ
- 参考文献
- まず読むカテゴリ PIDと制御の芯を固める
- 手を動かすカテゴリ Pythonで制御を試したい
- 通信と実機寄りカテゴリ CANまわりを強める
- LLM活用カテゴリ 指示設計を言語化したい
- この順番で読むとハマりにくい
- 3冊だけ選ぶなら
合わせて読むことおすすめの記事


ソースコードなど
以下、Githubにて公開しています。
はじめに
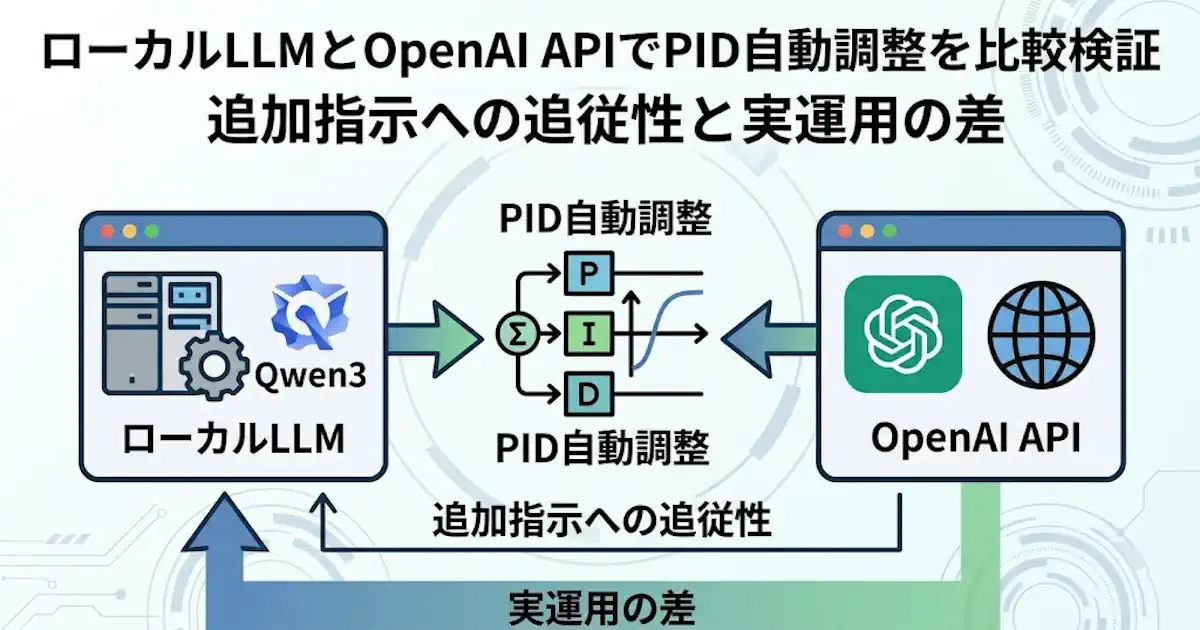
今回、PID係数自動適合システムのMVP(Minimum Viable Product)を実装し、ローカルLLMと OpenAI API の両方で同じ探索ループを実際に回しました。
このMVPでは、C言語のPID制御器、Python製プラント、評価器、オーケストレータ、LLM候補生成器を分離し、pid_params.h の更新、ビルド、閉ループ試験、評価、trial保存までを一連で自動化しています。trial 1 では initial_pid をそのまま評価し、trial 2 以降で LLM 候補生成へ入る構成です。
今回見たかったのは、単に「どちらが動くか」ではありません。
実運用で重要になるのは、運用者の追加指示にどれだけ追従するかです。たとえば次のような指示です。
- 一度オーバーシュートさせてから、安定化させる方向へチューニング
- オーバーシュートを出さず、単調応答寄りで進める
今回の比較は、1ケース・7 trial・second_order_tanh_switch 条件での観察であり、そのまま一般化するのではなく、今回の実験条件における傾向として読むのが適切です。
結論を先に書くと、ローカルLLMでもチューニング自体は十分実行できました。
ただし、短い追加指示に対してはあまり素直ではなく、少しずつ増やして、行き過ぎたら安定側へ寄せる探索へ寄りやすい傾向がありました。
一方で GPT-5.4 は、同じような短い指示でも multi-trial の探索方針として補完した可能性が高く、比較的意図に沿った動きを見せました。さらに検証すると、mini / nano / ローカルLLMでも、探索前半と後半を分けた書き方にすると、かなり指示どおりに動くようになりました。
比較表
今回の比較結果を、速度、best score、指示追従性、会話状態の扱い、向いている運用の観点でまとめると次のようになります。
| モデル | 1 trial あたり時間 | best score | 指示追従性の印象 | 会話状態の扱い | 向いている運用 |
|---|---|---|---|---|---|
| GPT-5.4 | 約17秒 | 0.834 | 最も素直。短い追加指示でも multi-trial 方針として読んだ可能性が高い | API側で run 全体の文脈を持たせやすい | 大量trial、追加指示重視 |
| GPT-5.4-mini | 約25秒 | 1.050 | nano と近い。短い指示では慎重寄りに見えやすい | API側で扱いやすい | コストも見つつ一定の追従性を確保したい運用 |
| GPT-5.4-nano | 約30秒 | 0.954 | mini とほぼ同格。短い指示では慎重寄りに見えやすい | API側で扱いやすい | 時間とコストのバランス重視 |
| Qwen3-8B(local_ovms) | 約120秒 | 1.515 | 短い指示では保守的。探索フェーズを明示するとかなり改善 | 履歴を厚くすると後半ほど重くなりやすい | 閉域運用、時間をかけてもローカルで回したい運用 |
今回の観察範囲では、best score は GPT-5.4 が最良で、mini と nano はスコア面ではほぼ同格と見てよさそうでした。
一方で、ローカルLLMも今回の規模では十分にループを回せており、閉域運用を重視するなら現実的な候補です。
システム全体像
今回のMVPでは、オーケストレータ、LLM、PID制御器、プラント、評価器、成果物保存の役割を分けています。
LLMは何でも実行する存在ではなく、候補提案と結果解釈を担う役割です。ビルド、実行、評価、保存の主体はオーケストレータ側に置いています。通信層は CAN 抽象I/F を境界にし、stub と vector_xl を選べる構成です。
- オーケストレータ
- trial全体の進行管理
- 内部prompt生成
pid_params.h更新- ビルド実行
- plant / controller 起動
- 評価と結果保存
- LLM
- 次のPID候補の提案
- 結果の解釈
- 必要なら探索モードの判断
- PID制御器
- C言語で実装した制御本体
- CAN経由で目標値、観測値、操作量を送受信
- 編集対象は
Kp,Ki,Kdのみ
- プラント
- Python製シミュレータ
- 一次遅れ、二次遅れ、無駄時間、ノイズ、非線形を組み合わせ可能
- 評価器
- rise time
- settling time
- overshoot
- steady-state error
- IAE / ISE / ITAE
- control variation
- oscillation
- divergence
- saturation
を計算し、総合スコア化
図1 全体構成
※ この図は処理順ではなく、各ブロックの接続関係だけを示す構成図
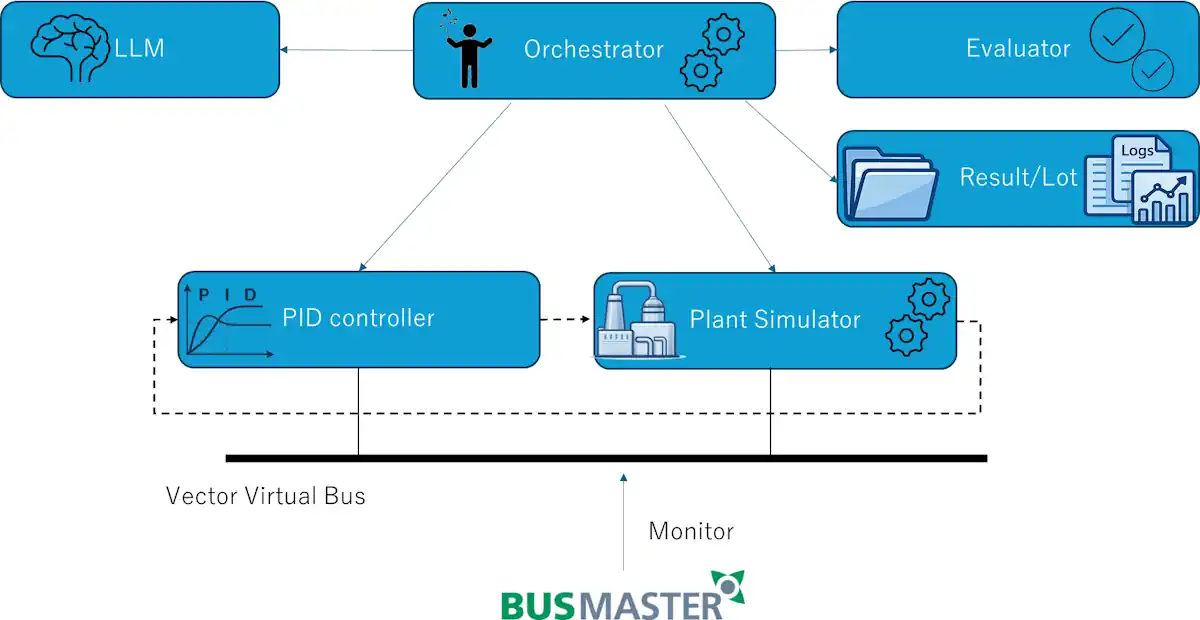
制御器とplantの接続構成
今回のMVPでは、制御器と plant の接続方法として stub と vector_xl の2パターンを用意しました。stub はアプリ内の仮想CANバスを使う構成、vector_xl は Vector XL Driver 経由の CAN チャネルを使う構成です。vector_xl 実行へ進めるには --build-mode msbuild と --can-adapter vector_xl の両方が必要で、mock のままでは virtual_stub 実行となるため BUSMASTER からは見えません。
今回の実験では、このうち vector_xl を使いました。
この構成では Vector 仮想バスを経由するため、制御器と plant のやり取りに対応する CAN フレームを BusMaster から覗き見できます。今回は専用の dbf / dbc も用意しており、BusMaster では dbf、CANoe や CANalyzer では dbc を使って各シグナルを参照できるようにしました。
ここは単に「動いた」と書くより重要です。
trial ごとのスコアや波形だけでなく、制御器と plant の間で何が流れていたかを外部ツールから追えるため、実験系としての可観測性がかなり高くなります。README でも、vector_xl 実行時に controller.exe が Vector XL 経由で CAN を送受信し、BusMaster から見えるのは主にそのやり取りに対応する CAN フレームだと整理しています。
実験条件
今回の検証環境は次のとおりです。
- CPU: Intel(R) Core(TM) Ultra 7 165U (1.70 GHz)
- RAM: 32GB
- OS: Windows 11
- IDE / Build: Visual Studio 2017 Express
- Python: 3.13.5
今回実行に使ったコマンドは以下です。
python orchestrator/main.py --config configs/target_response.yaml --case second_order_tanh_switch --max-trials 7 --build-mode msbuild --can-adapter vector_xl --user-instruction 最初の数trialは保守的にせず、あえて強めの係数を試してください。初期段階ではオーバーシュートしてもよいので、まず目標値に十分届く領域を見つけることを優先してください。currentbest付近の小さな調整は避け、KpとKiを意味のある大きさで増やしてください。その後のtrialで徐々に安定方向へ寄せてください。今回使った second_order_tanh_switch の条件は、二次遅れ、短い無駄時間、弱いガウスノイズ、tanh 非線形を含む設定でした。
このMVPでは plant case、評価条件、trial 上限、seed を設定ファイルと CLI 引数で与える形にしており、単一エントリは orchestrator/main.py です。
{
"name": "second_order_tanh_switch",
"enabled": true,
"plant": {
"type": "second_order",
"wn": 4.0,
"zeta": 0.50,
"gain": 1.0
},
"deadtime_sec": 0.04,
"noise": {
"type": "gaussian",
"stddev": 0.003
},
"nonlinear": {
"type": "tanh",
"gain": 2.2
},
"runtime": {
"duration_sec": 6.0,
"dt_sec": 0.01,
"seed": 1003
}
}1 trial の処理フロー
- Orchestrator が現在の履歴と目標条件をまとめる
- LLM に内部 prompt を送る
- LLM が次候補 Kp, Ki, Kd を返す
- Orchestrator が
pid_params.hを更新する - Controller をビルドする
- 実行モードを選ぶ
- stub: アプリ内仮想CANバスで接続
- vector_xl: Vector XL 経由で仮想バスへ接続
- Plant と Controller を起動する
- 閉ループ試験を実行する
- Evaluator が波形を評価する
- Orchestrator が結果を保存する
- vector_xl の場合は BusMaster から CAN 通信を観測できる
- 次 trial の prompt を再生成する
prompt設計の前提
今回のMVPでは、prompt の役割を最初から分けています。
tuning run 全体で共通の非交渉ルールは system prompt、trial ごとに変わる状態は user prompt へ入れる構成です。system prompt には出力スキーマ、重複候補禁止、PID範囲制約、説明形式などを置き、user prompt には target、PID limits、current best、used candidates、recent trial history、必要なら operator instruction を入れます。recent-history window は 10 trial です。
この分け方はかなり効きました。
一方で、追加指示は user prompt 側に入るため、system 側の hard rule より前には出ません。
さらに今回の既定構成では trial 1 が initial_pid の評価なので、追加指示が探索へ効き始めるのは基本的に trial 2 以降です。--user-instruction は advisory であり、PID 範囲制約、重複禁止、JSON スキーマ、異常時 fallback を上書きしません。
具体的なprompt例
初回に与える条件の例
今回のMVPでは、ユーザーが毎 trial 手入力する運用ではなく、設定ファイルと CLI 引数で run 全体の条件を与え、必要なら初回だけ追加方針を渡す構成にしています。
first_order_nominal を対象に PID 自動調整を実行する。
目標は rise time 1.0 秒以内、settling time 2.5 秒以内、overshoot 5% 以下、
steady-state error 0.01 以下とする。
試行回数上限は 4 回。
既出候補の再利用は禁止。system prompt の例
You are a PID tuning candidate generator.
Return exactly one JSON object and no markdown.
Do not include chain-of-thought.
The JSON must contain mode, next_candidate, expectation, explanation.
Never repeat any previously used PID candidate.
If a proposed Kp, Ki, Kd triple already appeared in the prompt, choose a different triple.user prompt の例
You are selecting the next PID candidate for an automated tuning loop.
Return exactly one JSON object with keys: mode, next_candidate, expectation, explanation.
Do not return markdown. Do not return prose outside JSON.
Hard rule: never repeat any PID candidate that already appeared in previous trials.
Hard rule: if a candidate matches any previously used Kp, Ki, Kd triple, it is invalid.
Hard rule: next_candidate must be an object with numeric Kp, Ki, Kd. Never encode it as a string.
[Targets]
- rise_time <= 1.0
- settling_time <= 2.5
- overshoot <= 5.0
- steady_state_error <= 0.01
- allow_oscillation = False
- allow_divergence = False
- allow_saturation = False
[PID Limits]
- Kp: 0.01 ~ 10.0
- Ki: 0.0 ~ 5.0
- Kd: 0.0 ~ 2.0
[Current Best Candidate]
- Kp = 0.250000
- Ki = 0.100000
- Kd = 0.000000
- score = 6.560475期待するJSONの例
{
"mode": "fine",
"next_candidate": {
"Kp": 0.62,
"Ki": 0.08,
"Kd": 0.02
},
"expectation": "rise_too_slow",
"explanation": "Increase Kp and Ki slightly to speed up rise."
}今回のMVPでは、LLM には基本的に候補だけ返させ、pid_params.h 更新はオーケストレータ側で機械的に行う設計を優先しています。
また、ローカル側では英語 prompt のほうが JSON 準拠と重複候補回避が安定しました。Qwen3-8B + OVMS で英語 prompt を既定にしたのはそのためです。
短い追加指示が効かなかった理由
最初に引っかかったのはここでした。
たとえば次のような短い追加指示です。
一度、オーバーシュートさせてから、安定化させる方向へチューニング人間には自然ですが、候補生成器から見るとこの文は曖昧です。
少なくとも次の2通りに読めます。
- 次の1 trial で攻めた候補を出せ
- 探索全体として、前半は攻めて後半で安定化しろ
PID 自動調整のような反復探索では、この違いはかなり大きいです。
前者なら single-trial 指示、後者なら multi-trial 方針です。
今回のMVPでは、--user-instruction は advisory であり、PID 範囲制約、重複禁止、JSON スキーマ、異常時 fallback を上書きしません。さらに trial 1 は initial_pid 評価です。そのため、曖昧な追加指示は hard rule より前に出にくく、保守的に解釈されやすい構造でした。README 側でも、係数を大きめに振って のような指示が効きにくい場合は、hard rule、重複禁止、temperature=0.0 の組み合わせで保守的に見えることがあると整理しています。
このため、GPT-5.4-mini / nano / ローカルLLMは、短い指示だけだと currentbest 近傍の小さな調整へ寄りやすかったと考えています。
一方で GPT-5.4 は、今回のタスクが複数 trial をまたぐ探索であることを比較的強く補完し、multi-trial 方針として解釈した可能性が高いです。
指示は助言ではなく探索計画として書く
今回いちばん実務的だった知見はここです。
追加指示は、短い自然文より「探索計画」として書いたほうが、モデル差をまたいで安定して効きました。
効きにくかったのはこの書き方です。
一度、オーバーシュートさせてから、安定化させる方向へチューニング効いたのはこの書き方です。
最初の数trialは保守的にせず、あえて強めの係数を試してください。
初期段階ではオーバーシュートしてもよいので、まず目標値に十分届く領域を見つけることを優先してください。
currentbest付近の小さな調整は避け、KpとKiを意味のある大きさで増やしてください。
その後のtrialで徐々に安定方向へ寄せてください。この指示が効いた理由はかなり明快です。
- いつ攻めるかが明示されている
- 何を優先するかが明示されている
- currentbest 近傍の微調整を避けることが明示されている
- 後半でどう振る舞うかも明示されている
つまり、1文の助言ではなく、探索前半と後半を分けた簡易戦略として書いたことが効いています。
今回の観察では、GPT-5.4-mini / nano / ローカルLLMも、この形にするとかなり意図どおり動くようになりました。
OpenAI API側が有利に見えた理由
今回のMVPでは、OpenAI 側は run 単位で会話状態を持たせやすい構成にしています。openai_responses では use_conversation_state: true を既定にし、tuning run 開始時に共通の system prompt を1回入れ、その後の各 trial では per-trial user prompt を送る設計です。ローカル側は system 側で会話履歴を持つ実装も可能ですが、実運用では use_conversation_state: false を推奨しており、履歴を厚くすると後半ほど応答が重くなりやすいです。
OpenAI の公式ドキュメントでも、Responses API は stateful interactions を扱えるインターフェースとして案内されており、conversation state の管理も別ガイドで整理されています。今回の run 単位の方針保持と相性がよかったのは、この設計思想とも噛み合っています。 (OpenAI Platform)
今回、GPT-5.4 が短い追加指示でも比較的それらしく動いたのは、モデル側の補完力だけでなく、run 全体の方針を保ちやすい構成も効いていたと見ています。
ローカルLLMの位置づけ
今回の比較から言うと、ローカルLLMは使えないわけではありません。
むしろ、今回のチューニング規模であれば、候補生成器として十分実用でした。
OVMS の LLM QuickStart でも、Windows 環境から OpenAI Python client を base_url="http://localhost:8000/v3" で使う例や、OpenVINO 系モデルを OpenVINO Model Server で扱う例が案内されています。今回の環境でも Qwen3-8B と Qwen3-14B は起動・推論が通り、30B 級はメモリ条件で外れました。こうした事情から、ローカル運用では Qwen3-8B を第一候補に置き、英語 prompt を既定にしています。 (OpenVINO Documentation)
つまり、ローカルLLMは「閉域で、時間をかけてもよいので候補を出し続ける探索器」としてかなり自然です。
ここに人の意図を強く乗せたいなら、自由文の追加指示だけではなく、探索フェーズを明示した文や構造化パラメータを使うほうが安定します。
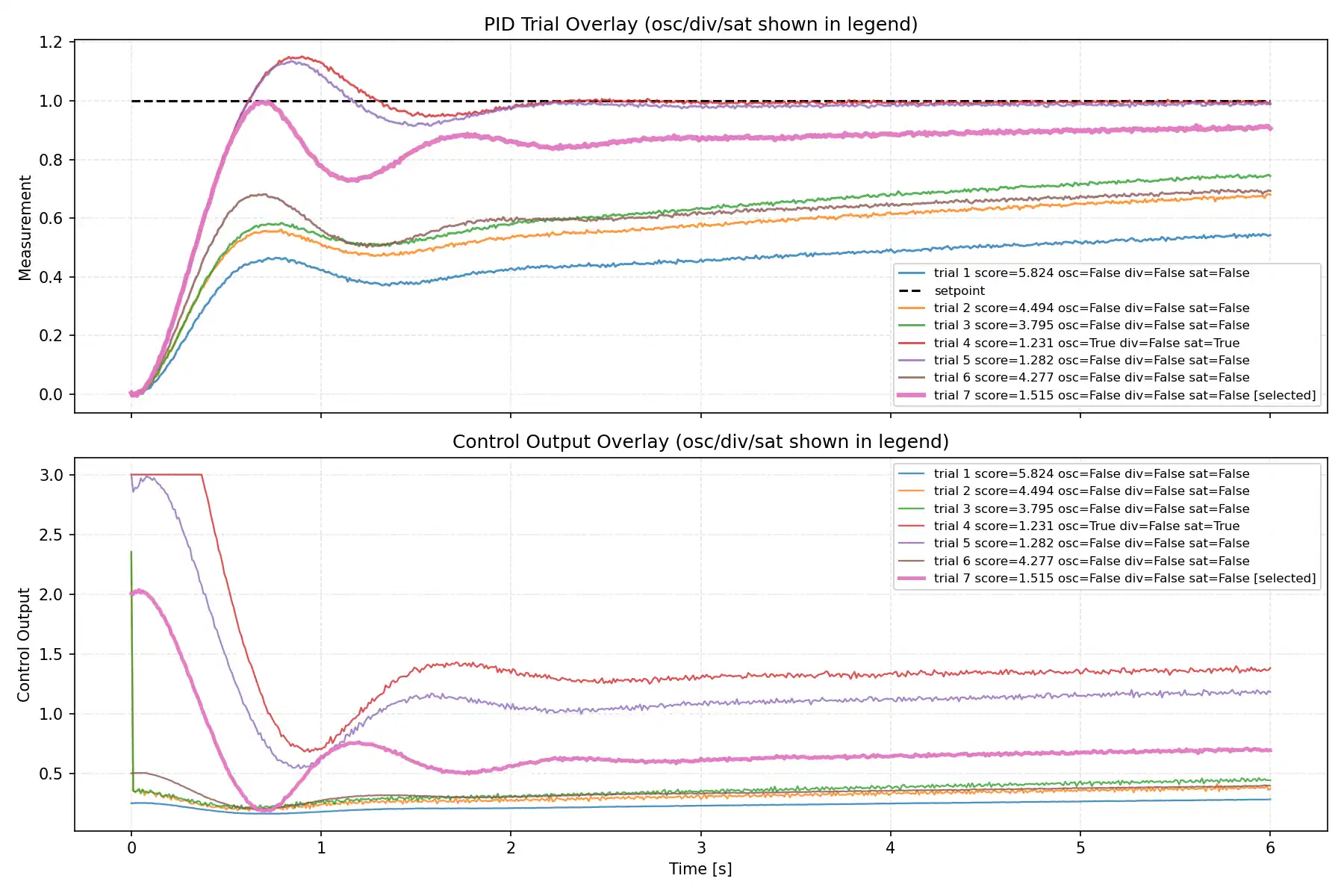
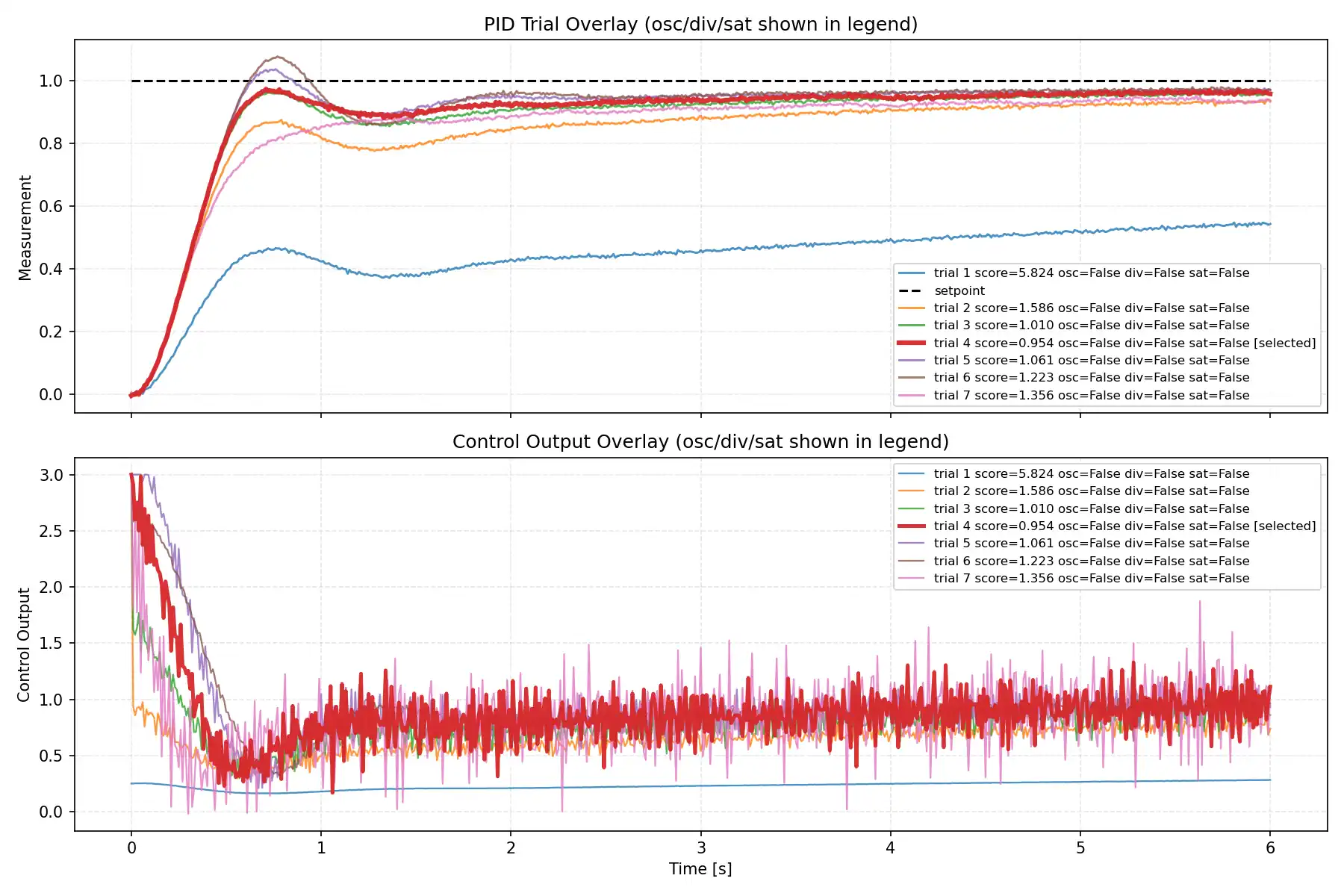
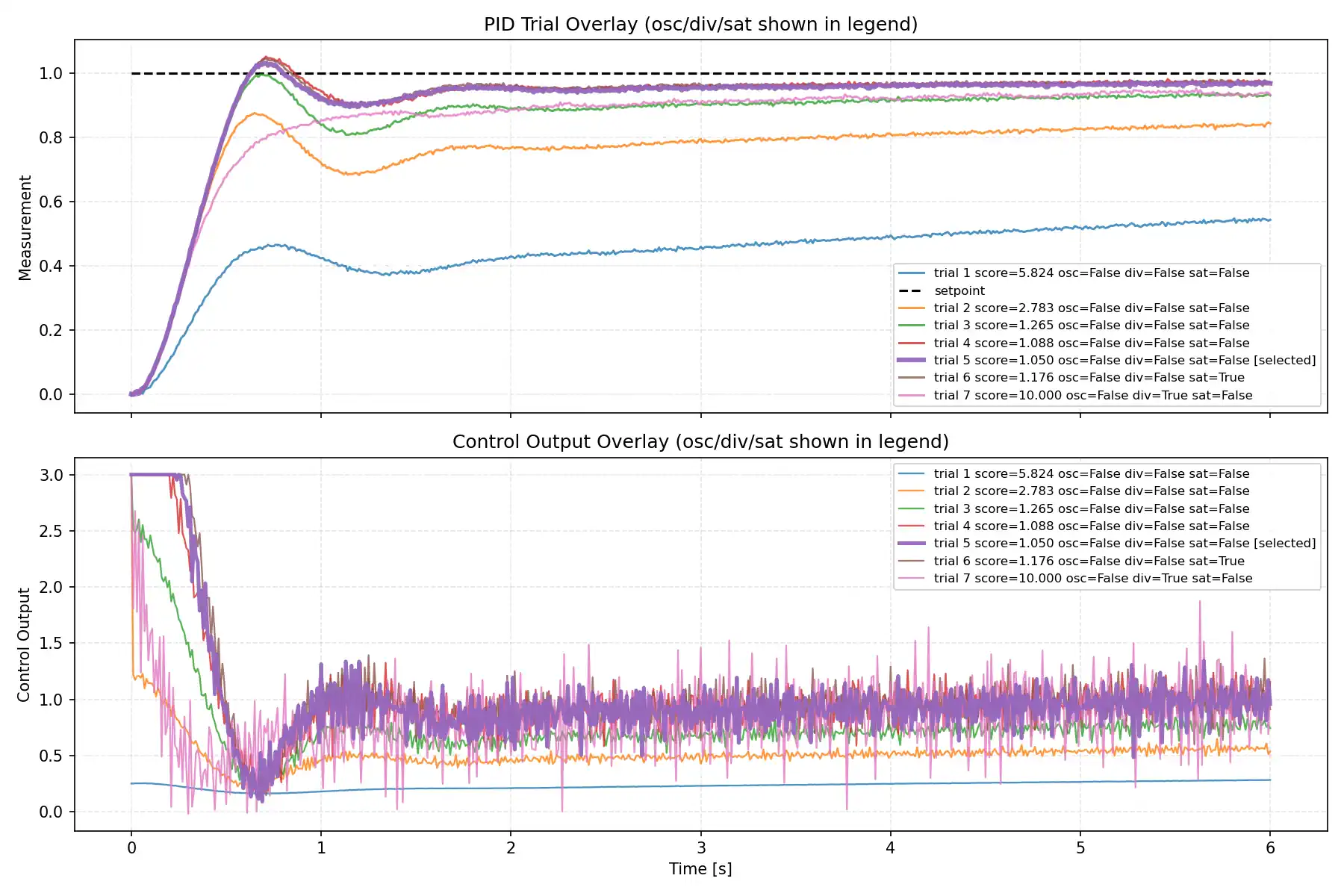
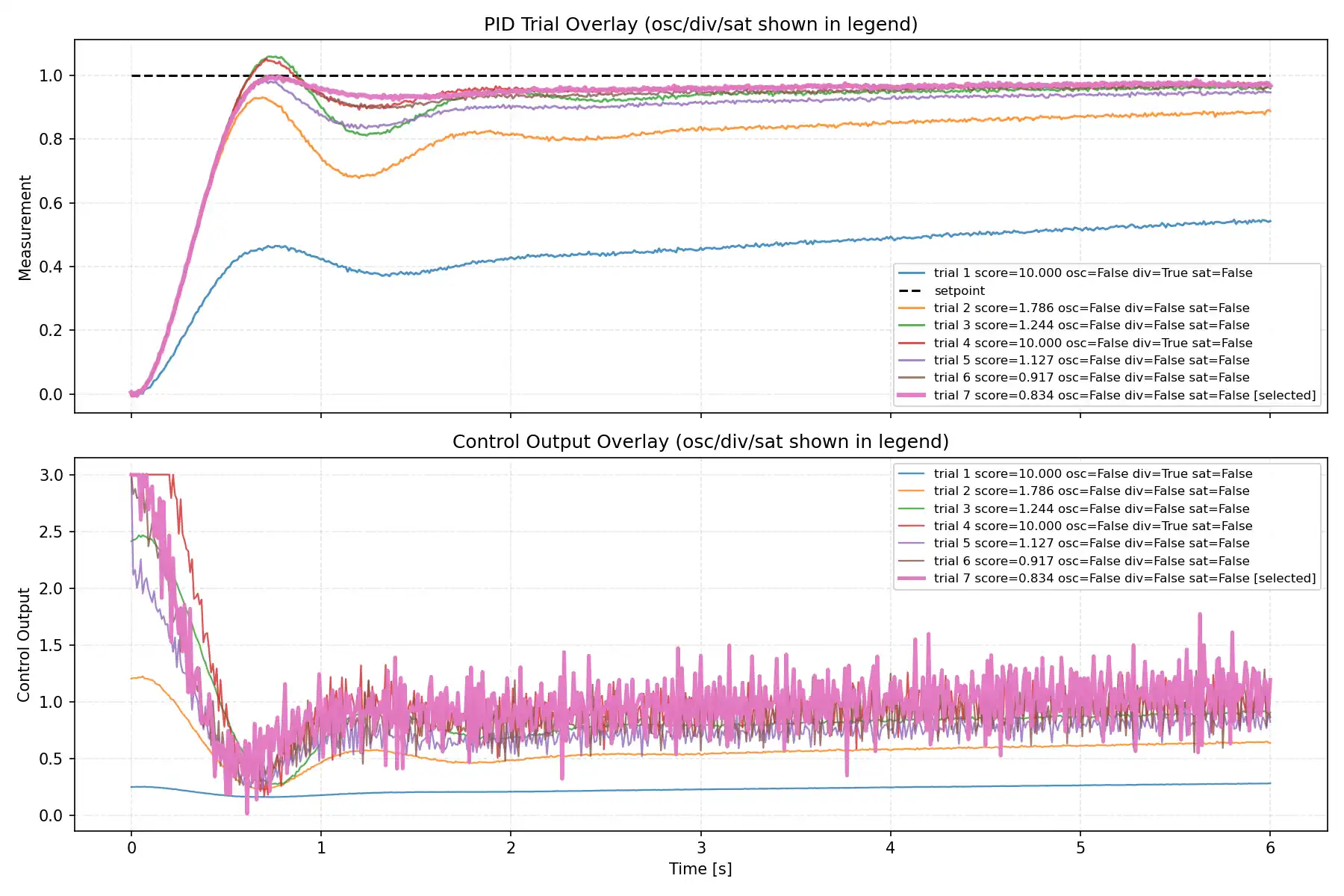
trial別波形比較
今回の検証では、各LLMについて trial ごとの measurement と control output を重ね描きしたグラフも取得しました。
この比較を入れると、単に best score だけを見るよりも、各モデルが探索前半でどれだけ攻め、後半でどれだけ収束側へ寄せたかが見えやすくなります。MVP 側でも waveform_overlay.png を自動生成し、上段に setpoint と measurement、下段に control_output を重ねて比較できるようにしています。
上段では、どの trial がどの程度 setpoint に届いているか、オーバーシュートがどれくらい出ているか、整定が早いかを見ます。
下段では、操作量がどれだけ荒れているか、前半で強めに振った trial があるか、後半で落ち着いていくかを見ます。measurement の見た目が改善しても、control_output 側では細かい変動が増えることがあるため、波形は score の補助ではなく、探索の性格そのものを見るために使うのがよいです。
今回の波形比較も、1ケース・7 trial・second_order_tanh_switch 条件で得られた観察です。
小規模LLMほど気持ち消極的に見える傾向はありましたが、現時点ではそのように見えた程度に留めるのが適切です。
代表グラフ
実運用での選び方
今回の規模であれば、ざっくり次のように考えるのが自然です。
- ローカルLLM
- 時間はかかる
- 閉域で回しやすい
- 候補生成器としては十分実用
- 追加指示は探索計画として具体化したほうがよい
- GPT-5.4-nano
- 速度とコストのバランスがよい
- 短い追加指示では慎重寄りに見えやすい
- 探索前半 / 後半を明示した指示で改善しやすい
- GPT-5.4-mini
- nano より少し余裕を見たいときの候補
- 傾向は nano と近い
- 曖昧な指示では保守的になりやすい
- GPT-5.4
- 今回の比較では最も素直
- 曖昧な追加指示でも multi-trial の意図を補完した可能性が高い
- 大量 trial を回す用途でも有力
現実的には、今回の観察範囲では GPT-5.4-nano が時間とコストのバランスを取りやすい印象でした。
ただ、追加指示への補完力を優先するなら GPT-5.4 はやはり強いです。
一方で閉域やローカル運用を重視するなら、ローカルLLMも十分候補になります。
制御工学の文脈で見た位置づけ
PID チューニング自体は非常に長い歴史があり、古典的な経験則から最適化ベースの手法まで幅広い系譜があります。レビュー論文でも、古典的な PID から知能化・最適化を組み合わせた手法まで広く整理されています。今回のMVPは、その長い PID チューニングの流れの上に、LLM を「探索戦略を補助する候補生成器」として乗せたものと見るのが適切です。 (スプリンガーリンク)
また、今回の観察でも、最初に立ち上がりを優先して有望領域を見つけ、その後に安定側へ寄せるという考え方は、古典的チューニングの感覚とつながっています。Ziegler–Nichols 系の再検討研究でも、ステップ応答の特徴をもとに調整則を組み立てる枠組みが整理されています。 (ScienceDirect)
FAQ
ローカルLLMでもPID自動調整は実用になるか
今回のチューニング規模であれば十分実用になります。
trial あたりの時間は長めでしたが、候補生成、ビルド、評価、保存のループ自体は問題なく回せました。MVP 側でも、設定読込、pid_params.h 更新、trial 保存、CLI 実行、評価まで一連で通る構成にしています。
なぜ短い追加指示ではminiやnanoやローカルLLMが従いにくかったのか
single-trial 指示なのか multi-trial 方針なのかが曖昧だったからです。
今回のMVPでは追加指示は advisory で、hard rule を上書きしません。trial 1 も initial_pid をそのまま評価する構成なので、短く曖昧な助言文だけでは保守側へ倒れやすかったです。
どのような追加指示なら効きやすいのか
探索前半と後半を分けて書く指示です。
最初の数 trial では強めの係数を試し、その後で徐々に安定方向へ寄せる、という時間軸つきの指示にすると、mini / nano / ローカルLLMでもかなり改善しました。
今回の実験ではstubとvector_xlのどちらを使ったのか
今回の実験では vector_xl を使いました。stub と vector_xl の両方を持つ構成ですが、比較実験では Vector XL Driver 経由の実経路を選びました。vector_xl 実行には --build-mode msbuild と --can-adapter vector_xl の両方が必要です。
現実的にどのモデルを選ぶのがよいのか
大量に回したいなら GPT-5.4 が有力です。
コストも意識するなら mini / nano も候補です。
今回の観察範囲では、時間とコストのバランスは GPT-5.4-nano が取りやすい印象でした。
まとめ
今回の比較で最初に見えたのは、ローカルLLMより OpenAI API のほうが追加指示に従いやすい、という差でした。
ただ、追加で詰めていくと、より本質的だったのは「指示の時間軸が明確かどうか」でした。
短い指示のままだと、GPT-5.4-mini / nano / ローカルLLMは、次の1 trial への指示なのか、探索全体の方針なのかを安全側に解釈しやすかったです。
一方で GPT-5.4 は、探索が複数回続く前提を比較的強く補完し、multi-trial 方針として受け取った可能性が高いです。
そして、探索前半と後半を分けた指示へ書き換えることで、mini / nano / ローカルLLMでもかなり素直に動くようになりました。
また、今回の比較は 1ケース・7 trial・second_order_tanh_switch 条件での観察です。
そのため、ここでの差をそのまま一般化するのではなく、今回の条件における実験結果として扱うのが妥当です。
- モデル差だけでなく、指示の時間軸の明確さが効く
- GPT-5.4 は曖昧な指示を multi-trial 方針として補完しやすかった可能性が高い
- mini / nano / ローカルLLMでも、探索フェーズを明示すればかなり改善する
参考文献
- OpenAI API Reference: Responses
https://platform.openai.com/docs/api-reference/responses/object - OpenAI Guide: Conversation state
https://platform.openai.com/docs/guides/conversation-state - OpenVINO Model Server QuickStart – LLM models
https://docs.openvino.ai/2026/model-server/ovms_docs_llm_quickstart.html - Pawar, S. N. et al., A review of PID control, tuning methods and applications
https://link.springer.com/article/10.1007/s40435-020-00665-4 - Åström, K. J. and Hägglund, T., Revisiting the Ziegler–Nichols step response method for PID control
https://www.sciencedirect.com/science/article/pii/S0959152404000034
まず読むカテゴリ PIDと制御の芯を固める
『PID制御の基礎と応用(第2版)』

PIDそのものを正面から押さえたいなら、まずこれが合います。
ラプラス変換と伝達関数、周波数特性、安定性、PID制御の基本形とバリエーション、チューニング、複合ループ、フィードフォワード、むだ時間プロセス、代表的プロセス制御まで入っています。今回の記事で扱っている「オーバーシュート」「整定」「むだ時間」「チューニング方針」を、古典的な制御の文脈で整理し直すのに向いています。
『制御工学入門』

制御の全体像を一冊で持ちたいならこれです。
前半が伝達関数に基づく古典制御、後半が状態方程式に基づく現代制御で、授業に合うようにまとめた入門書です。PIDだけでなく、記事に出てくる「応答」「安定性」「状態フィードバック」まで視野を広げたいときに使いやすいです。
手を動かすカテゴリ Pythonで制御を試したい
『Pythonによる制御工学入門(改訂2版)』

今回の記事は、Pythonの plant、波形評価、trial の比較まで入っているので、この本との相性がかなりいいです。
Pythonを使って制御工学を学ぶ入門書で、「使ってみる、やってみる」を通して体感できる構成になっており、PID制御、2自由度制御、限界感度法、モデルマッチング法、状態フィードバック、ロバスト制御、ディジタル実装、最適制御まで扱っています。実験系を自分でも組みたい人には特に合います。
通信と実機寄りカテゴリ CANまわりを強める
『CAN入門講座 組込みマイコンで学ぶCANプロトコルとプログラミング』

今回の記事では vector_xl、BusMaster、dbc / dbf、CAN 経由の制御器と plant の接続が出てくるので、CAN を本として補強するならこれが直球です。
CAN規格の仕様と使い方を実際のマイコンに沿って解説し、M16C、H8、SuperH 内蔵マイコンによる CAN 制御プログラムを収録しています。いまどきの車載ネットワーク全体を広く学ぶ本というより、「まずCANを実装する・触る」寄りで読むのが合っています。
LLM活用カテゴリ 指示設計を言語化したい
『LLMのプロンプトエンジニアリング』

今回の記事の核心は、「短い追加指示が効かない理由」と「探索前半・後半を分けた指示の効き方」でした。そこを体系化したいならこれがいちばん近いです。
LLMの理解から始め、プロンプトに何を組み込み、どのような構造にすべきかという本来の意味でのプロンプトエンジニアリングを説明しており、評価手法や設計判断まで扱っています。今回のような multi-trial の指示設計を整理するのに向いています。
『ChatGPT はじめてのプロンプトエンジニアリング』

もう少し軽く入りたいならこちらです。
初心者向けにプロンプトを基本要素から理解し、徐々に要素を組み合わせて応用力を身につける構成で、具体的な作例と回答例が豊富です。記事の読者が「追加指示の書き方」を実務的にまねしたいなら、入り口としてかなり使いやすいです。
この順番で読むとハマりにくい
最短で記事テーマにつなげるなら、この順番が無難です。
- まず『PID制御の基礎と応用(第2版)』でPIDの判断軸を固める
- 次に『Pythonによる制御工学入門(改訂2版)』で、波形・シミュレーション・実装寄りの感覚をつかむ
- CANを追いたいなら『CAN入門講座』を足す
- LLMの指示設計を整理したいなら『LLMのプロンプトエンジニアリング』か『ChatGPT はじめてのプロンプトエンジニアリング』へ進む
3冊だけ選ぶなら
記事との相性だけで絞るなら、この3冊です。
- 『PID制御の基礎と応用(第2版)』
制御の判断軸を作る本。 - 『Pythonによる制御工学入門(改訂2版)』
実験系と波形比較に強い本。 - 『LLMのプロンプトエンジニアリング』
追加指示の効き方を言語化しやすい本。
コメント