
バックナンバーはこちら

要約:
- 記述統計は、平均・中央値・分散・標準偏差・外れ値からデータの全体像をつかむ入口
- 確率分布と推定・検定は、不確実性を扱いながらモデルや仮説を評価する土台
- 相関・距離・類似度は、特徴量の関係やデータ同士の近さを理解する重要概念
動画シリーズ
本記事は、YouTubeで公開している「G検定対策 究極カンペをつくろう」シリーズの第15回「平均, 分散, 標準偏差, 確率分布, 仮説検定, 相関, 距離・類似度」を文字・図解で整理したものである。
動画では対話形式で解説しているが、この記事では試験直前に見返せるよう、講義ノート+因果関係図の形に圧縮している。

再生リスト

G検定対策 究極カンペをつくろう#15 AIに必要な数理・統計知識
今回のテーマは「AIに必要な数理・統計知識」です。
G検定では、平均、分散、標準偏差、確率分布、仮説検定、相関係数、距離、類似度など、数理・統計に関する用語が多く登場します。
用語だけを見ると難しく感じますが、ポイントは「AIや機械学習のどこで使うのか」という関係で整理することです。
数理・統計は、単なる暗記項目ではありません。データを理解し、モデルを評価し、特徴量の関係を見て、機械学習の判断を支えるための道具セットです。
今回の章立て
この記事では、次の流れで数理・統計知識を整理します。
- 記述統計
- 確率の基礎
- 代表的な確率分布
- 推定・検定
- 関係性の分析
- 距離・類似度
- 学習・判断への影響
- まとめ
最初にデータの様子を見ます。次に、確率で不確実性を扱います。そのあと、推定や検定、相関、距離へ進み、最後に機械学習での特徴理解へつなげます。
この順番で見ると、数理・統計の用語はばらばらな暗記リストではなく、ひとつの流れとして理解しやすくなります。
全体構成
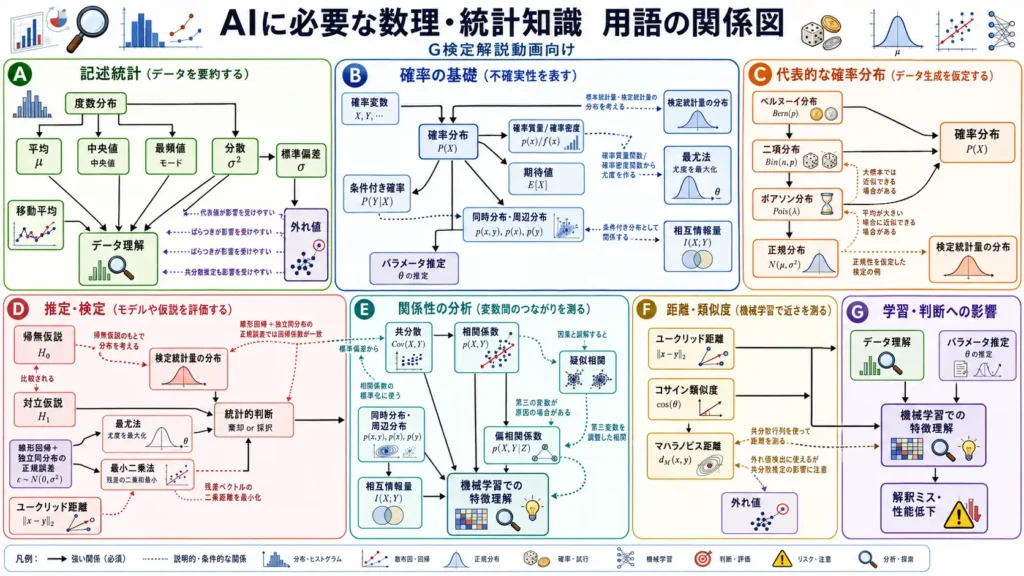
全体構成は、次の流れで見ると整理しやすいです。
- 記述統計: データを要約
- 確率の基礎: 不確実性を表現
- 代表的な確率分布: データの出方を仮定
- 推定・検定: モデルや仮説を評価
- 関係性の分析: 変数同士のつながりを確認
- 距離・類似度: データ同士の近さを測定
- 学習・判断への影響: 機械学習での特徴理解へ接続
記述統計でデータを要約し、確率で不確実性を扱い、確率分布でデータの出方を仮定します。
そのうえで、推定・検定によってモデルや仮説を評価し、相関や相互情報量で変数同士の関係を見ます。さらに、距離・類似度によってデータ同士の近さを測ります。
これらはすべて、機械学習における特徴理解や判断に関わります。
記述統計
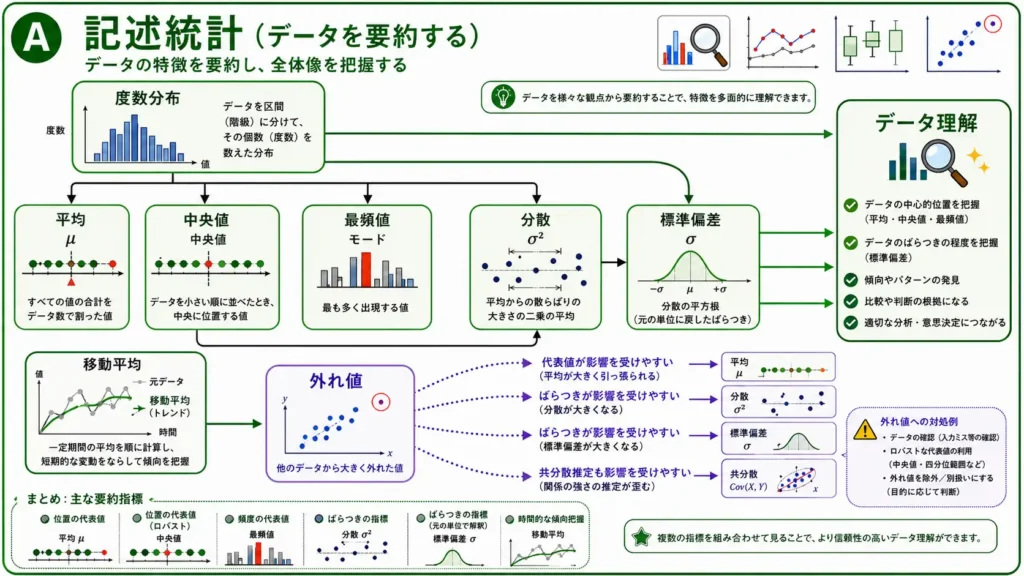
記述統計は、データの特徴を要約して全体像を把握するための考え方です。
大量のデータをそのまま見ても、傾向は分かりにくいです。そこで、平均、中央値、最頻値、分散、標準偏差などの指標を使って、データの中心やばらつきを見ます。
度数分布
度数分布は、データを範囲ごとに分け、それぞれに何個のデータが入るかを見る方法です。
ヒストグラムで表すと、山の形、偏り、外れ値の存在が見えやすくなります。平均だけでは分からないデータの形を見る入口になります。
平均
平均は、すべての値の合計をデータ数で割った値です。
$平均=\displaystyle\frac{値の合計}{データ数}$
データの中心をざっくり見るときに便利です。ただし、非常に大きい値や小さい値があると、その影響を受けやすくなります。
中央値
中央値は、データを小さい順に並べたとき、中央に来る値です。
外れ値の影響を受けにくいため、所得や売上のように、一部の大きな値が全体の印象を変えやすいデータで役立ちます。
最頻値
最頻値は、最も多く出現する値です。
カテゴリデータや離散的な値を見るときに便利です。アンケートの回答、選択肢、出現回数の多いラベルなどを見るときに使いやすい代表値です。
分散と標準偏差
分散と標準偏差は、データのばらつきを見るための指標です。
平均が同じデータでも、値が平均の近くに集まっている場合と、広く散らばっている場合があります。この違いを見るのが分散と標準偏差です。
分散は、平均からの差をもとにばらつきを表します。
$分散=\displaystyle\frac{偏差の二乗の合計}{データ数}$
標準偏差は、分散の平方根です。
$標準偏差=\sqrt{分散}$
標準偏差は、正規分布、外れ値の判断、機械学習における標準化にも関わります。
移動平均
移動平均は、時系列データで一定期間の平均を順番に計算し、短期的な変動をならして傾向を見る方法です。
アクセス数、売上、株価、センサー値など、日々変動するデータを見るときに使われます。
ただし、期間の取り方によって見え方が変わるため、目的に合わせた設定が必要です。
外れ値
外れ値は、他のデータから大きく離れた値です。
入力ミスの場合もあれば、まれに発生した重要な現象の場合もあります。異常検知では、外れ値そのものが重要な分析対象になることもあります。
外れ値は、平均、分散、標準偏差、共分散などに影響します。そのため、データ理解の段階で確認しておくことが大切です。
確率の基礎
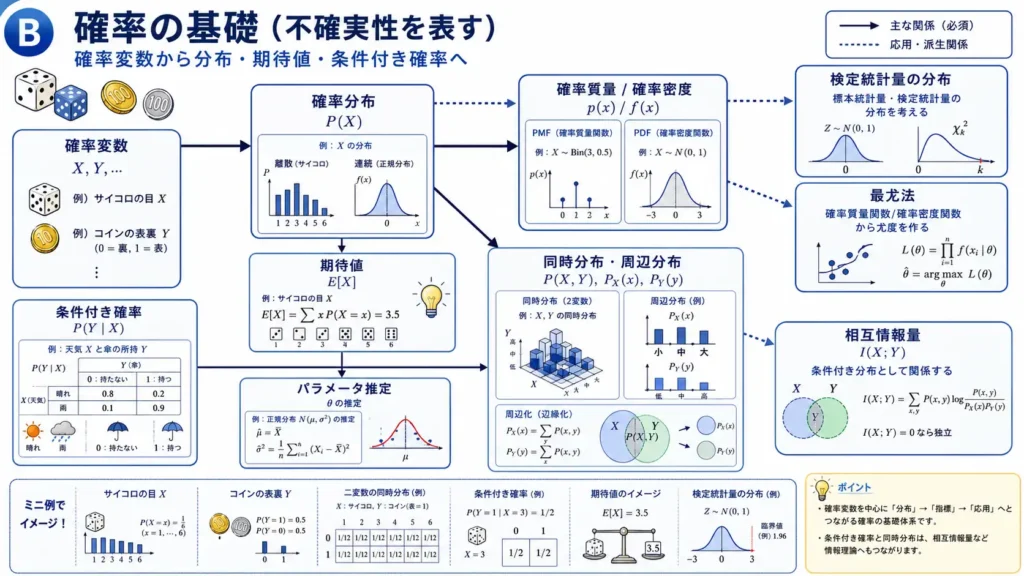
確率の基礎は、不確実性を数で扱うための考え方です。
機械学習では、データやラベルを確率変数として考えたり、予測の不確かさを確率分布で表したりします。確率は、AIの判断を支える重要な土台です。
確率変数
確率変数は、値が確率的に決まる変数です。
たとえば、サイコロの目をX、コインの表裏をYと置くような考え方です。確率変数を使うことで、偶然に見える現象を数理的に扱えるようになります。
確率分布
確率分布は、確率変数がどの値をどれくらい取りやすいかを表します。
離散的な値を扱う場合は確率質量関数、連続的な値を扱う場合は確率密度関数を使います。
- 確率質量関数: 離散値の確率
- 確率密度関数: 連続値の確率を範囲で表現
連続値では、ある一点だけの確率ではなく、範囲として確率を見る点が重要です。
期待値
期待値は、確率を重みとして考えた平均のような値です。
$期待値=\sum 値\times 確率$
たとえば、サイコロの期待値は、各目の値にその確率を掛けて合計します。
期待値は、損失の平均、リスク評価、推定、最適化などにも関わります。
条件付き確率
条件付き確率は、ある条件が分かっているときの確率です。
たとえば、「雨の日に傘を持っている確率」のように、条件によって確率の見方が変わります。
条件付き確率は、ベイズの定理、分類モデル、確率的な推論を理解するうえでも重要です。
同時分布と周辺分布
複数の変数を同時に見るときは同時分布を使います。
そこから一方の変数だけに注目すると周辺分布になります。
この考え方は、条件付き分布や相互情報量にもつながります。確率の基礎は、後の推定・検定や関係性の分析に広がっていきます。
代表的な確率分布
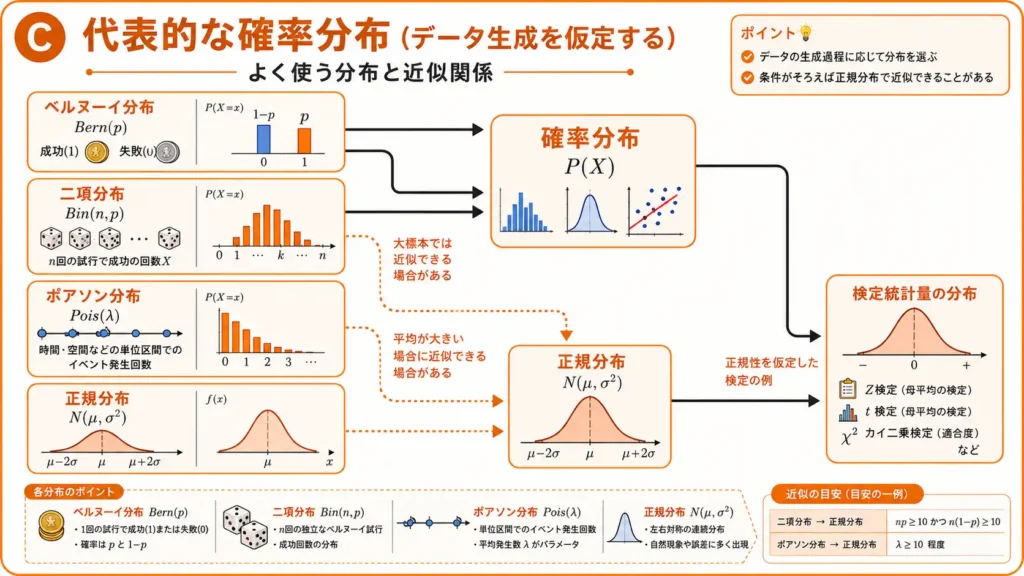
代表的な確率分布は、データの出方を仮定するための道具です。
G検定では、分布の名前だけでなく、「どのような場面で使うか」まで押さえることが重要です。
ベルヌーイ分布
ベルヌーイ分布は、1回の試行で成功か失敗か、0か1かを表す分布です。
- コインの表裏
- クリックするかしないか
- 購入するかしないか
- 正解か不正解か
二値分類の理解にもつながる分布です。
二項分布
二項分布は、独立なベルヌーイ試行を複数回行ったとき、成功回数がどのように分布するかを表します。
- 10回中何回成功するか
- 100人中何人が反応するか
- 複数回の試行で何回当たるか
ベルヌーイ分布が1回の成功・失敗なら、二項分布は複数回の成功回数を見る分布です。
ポアソン分布
ポアソン分布は、一定の時間や空間の中でイベントが何回起こるかを表します。
- 一定時間あたりのアクセス数
- 一定期間の問い合わせ件数
- 一定範囲での事故件数
- 一定時間内の故障発生数
平均発生回数を表すパラメータが重要です。
正規分布
正規分布は、左右対称の山型の分布です。平均と分散によって形が決まります。
自然現象や誤差のモデルとしてよく使われ、推定や仮説検定でも重要な役割を持ちます。
G検定では、二項分布やポアソン分布が条件によって正規分布で近似されることも押さえておきたいポイントです。
推定・検定
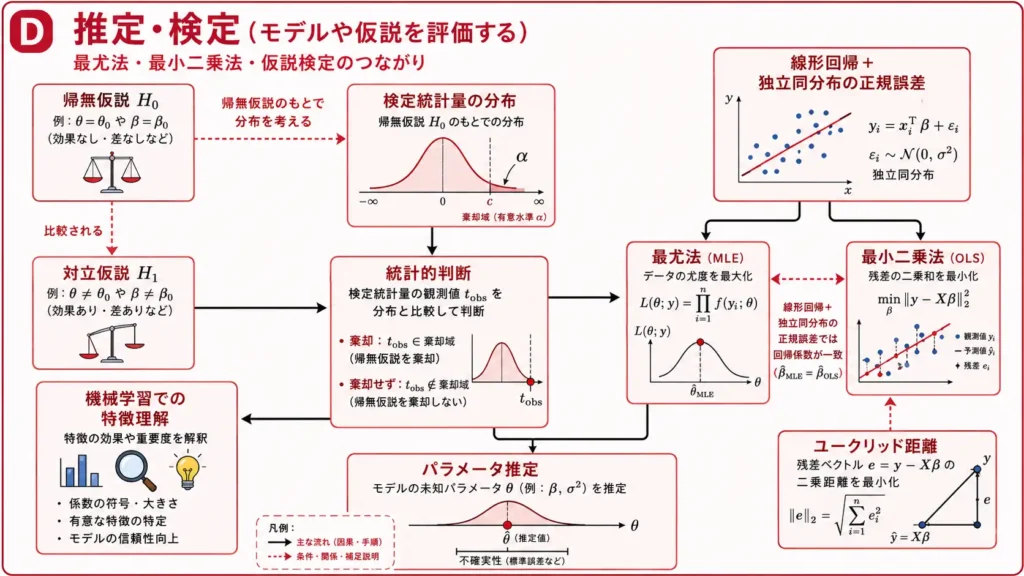
推定・検定は、モデルや仮説をデータで評価するための考え方です。
推定は、未知の値をデータから見積もることです。検定は、仮説をデータで判断することです。
パラメータ推定
パラメータ推定は、モデルの未知のパラメータをデータから見積もることです。
回帰係数、分散、確率分布のパラメータなどが対象になります。モデルを使うには、まずデータに合うパラメータを求める必要があります。
最尤法
最尤法は、観測されたデータが最も起こりやすくなるようにパラメータを選ぶ考え方です。
「このデータが得られたなら、最も自然に説明できる設定はどれか」を探す方法です。
確率分布を仮定し、その尤度が最大になるパラメータを求めます。分類モデルや確率モデルの理解にもつながります。
最小二乗法
最小二乗法は、予測値と観測値の差である残差の二乗和が小さくなるようにパラメータを選ぶ方法です。
線形回帰でよく使われます。散布図上の点の集まりに対して、なるべく合う直線を考えるイメージです。
$残差=観測値-予測値$
$最小二乗法=残差の二乗和を最小にする方法$
線形回帰で誤差が独立同分布の正規分布に従うと仮定すると、最尤法と最小二乗法の結果が一致する場合があります。
帰無仮説と対立仮説
仮説検定では、帰無仮説と対立仮説を考えます。
- 帰無仮説: 差がない、効果がない、などの基準となる仮説
- 対立仮説: 差がある、効果がある、などの示したい側の仮説
検定では、まず帰無仮説が成り立つと仮定します。そのうえで、観測されたデータがどれくらい珍しいかを、検定統計量の分布と比べて判断します。
「帰無仮説を棄却しない」は、「帰無仮説が正しいと証明した」という意味ではありません。今回のデータでは否定するほどの根拠が十分ではなかった、という意味です。
関係性の分析
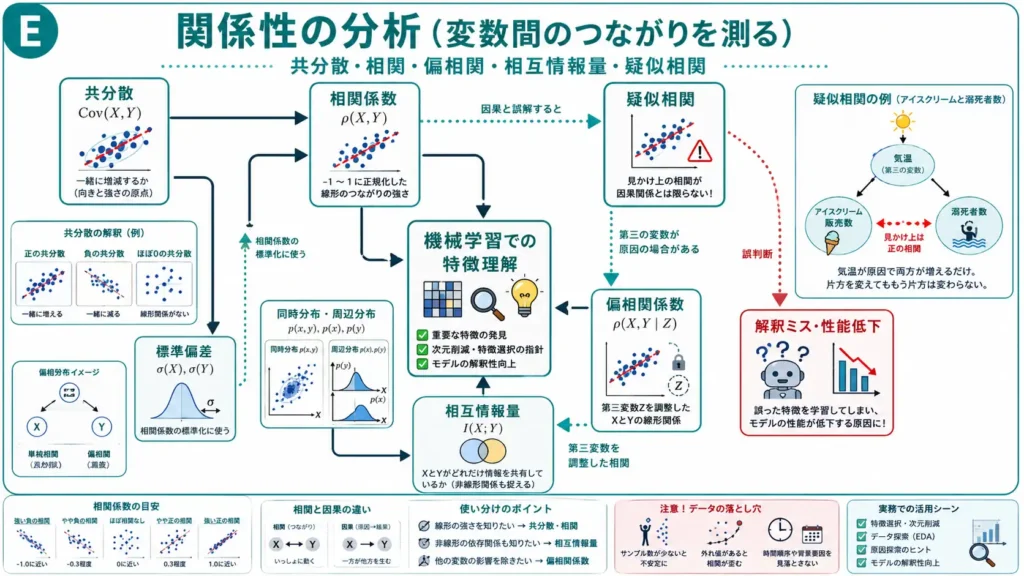
関係性の分析は、変数同士のつながりを見るための領域です。
機械学習では、特徴量同士の関係や、特徴量と目的変数の関係を理解するために重要です。
共分散
共分散は、2つの変数が一緒に増減する傾向を見る指標です。
- 正の共分散: 片方が増えるともう片方も増えやすい
- 負の共分散: 片方が増えるともう片方は減りやすい
- 0に近い共分散: 線形な関係が弱い
ただし、共分散は単位の影響を受けます。そのため、値の大きさだけでは関係の強さを比較しにくい場合があります。
相関係数
相関係数は、共分散を標準偏差で標準化した指標です。
$相関係数=\displaystyle\frac{共分散}{標準偏差A\cdot 標準偏差B}$
相関係数は、-1から1の範囲で線形関係の強さと向きを表します。
- 1に近い: 強い正の相関
- -1に近い: 強い負の相関
- 0に近い: 線形関係が弱い
ただし、相関係数は線形関係を見る指標です。曲線的な関係や複雑な関係は、相関係数だけでは見えにくい場合があります。
相互情報量
相互情報量は、2つの変数がどれだけ情報を共有しているかを見る指標です。
相関係数が主に線形関係を見るのに対し、相互情報量は非線形な関係も捉えられる場合があります。
特徴量選択や、目的変数と特徴量の関係を見る場面で重要です。
偏相関係数
偏相関係数は、第三の変数の影響を調整したうえで、2つの変数の関係を見る指標です。
見かけ上は関係がありそうでも、実は別の要因が両方に影響している場合があります。そのような場面で、偏相関係数の考え方が役立ちます。
疑似相関
疑似相関は、本質的な因果関係がないのに、別の要因の影響で相関があるように見える状態です。
代表例として、アイスクリーム販売数と溺死者数があります。一見すると関係がありそうでも、実際には気温という第三の要因が関係している可能性があります。
相関は因果を意味しません。
機械学習でも、見かけ上の関係だけを学習すると、本質的ではない特徴に頼ったモデルになる可能性があります。その結果、解釈ミスや性能低下につながります。
距離・類似度
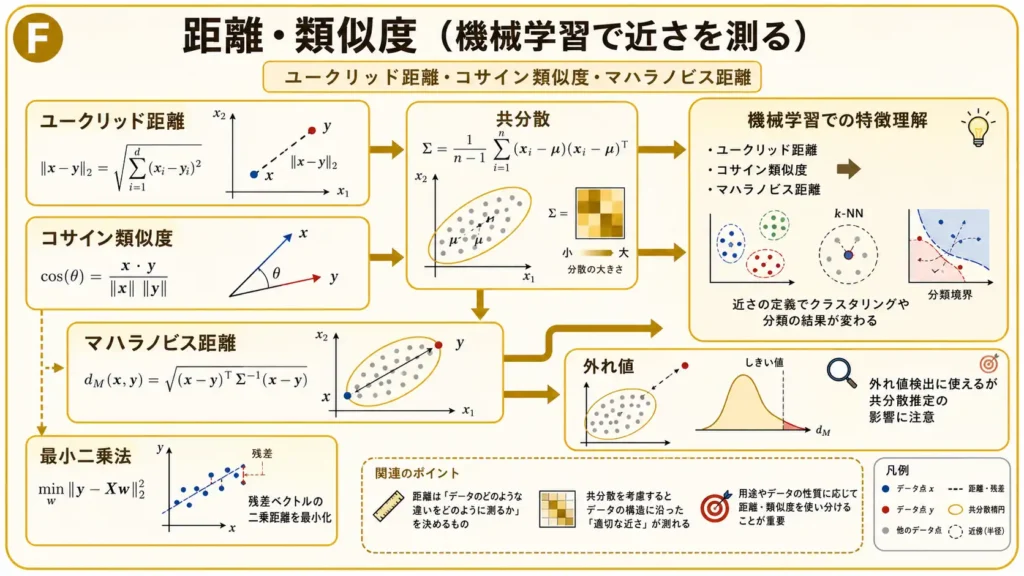
距離・類似度は、データ同士がどれくらい近いか、どれくらい似ているかを見るための考え方です。
分類、クラスタリング、検索、推薦、異常検知など、さまざまな機械学習タスクで使われます。
ユークリッド距離
ユークリッド距離は、2点間のまっすぐな距離です。
座標上の普通の距離としてイメージしやすく、k近傍法やクラスタリングでよく使われます。
2次元の点Aと点Bの距離は、次のように表せます。
$d=\sqrt{(x_A-x_B)^2+(y_A-y_B)^2}$
ただし、特徴量のスケールに影響されやすい点に注意が必要です。たとえば、身長のcmと年収の円をそのまま同じ空間で扱うと、数値の大きい特徴が強く影響します。
そのため、標準化や正規化とあわせて考えることが重要です。
コサイン類似度
コサイン類似度は、ベクトルの向きの近さを見る指標です。
$コサイン類似度=\displaystyle\frac{a\cdot b}{|a||b|}$
大きさよりも方向を見たい場面で役立ちます。文書ベクトル、推薦、検索などでよく使われます。
文章の長さが違っても、使われる単語の傾向が似ていれば、コサイン類似度は高くなりやすいです。
マハラノビス距離
マハラノビス距離は、データの分散や共分散を考慮した距離です。
単純な距離だけでなく、データがどの方向に広がっているかも見ます。データの広がりに沿った方向なら自然な位置に見え、広がりと異なる方向に離れている場合は外れ値として見えやすくなります。
異常検知や多変量データの分析で重要な考え方です。
学習・判断への影響
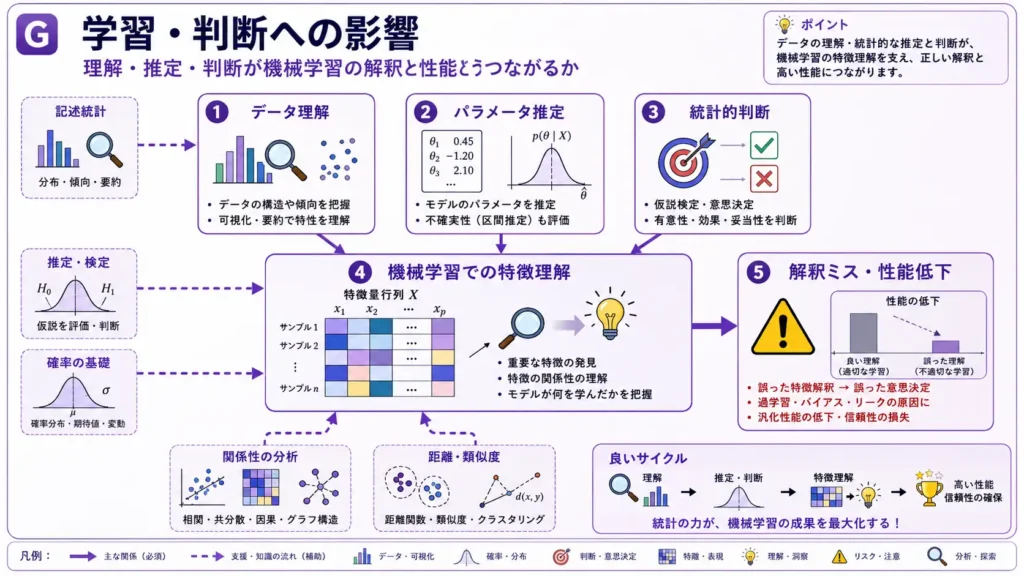
数理・統計は、G検定のためだけの暗記項目ではありません。機械学習を正しく使うための基礎です。
データ理解への影響
記述統計を使うと、データの中心、ばらつき、外れ値、分布の形が見えます。
データ理解が不足すると、前処理や特徴量設計を誤りやすくなります。モデルに学習させる前に、データの性質を見ることが重要です。
不確実性への影響
確率や確率分布は、予測の不確かさを理解するために必要です。
機械学習では、予測値だけでなく、その予測がどれくらい確からしいのかを考える場面があります。確率分布、期待値、条件付き確率は、そのための土台です。
統計的判断への影響
推定・検定は、モデルや施策を評価するために役立ちます。
「なんとなく良さそう」ではなく、データに基づいて判断するために、最尤法、最小二乗法、仮説検定の考え方が必要です。
特徴理解への影響
相関、共分散、相互情報量、偏相関係数は、特徴量同士の関係や、特徴量と目的変数の関係を見るために使われます。
ただし、疑似相関には注意が必要です。見かけ上の相関を因果と誤解すると、モデルの解釈を誤る可能性があります。
近さによる判断への影響
距離・類似度は、分類、クラスタリング、検索、推薦、異常検知に関わります。
どの距離や類似度を使うかによって、「似ているデータ」の見え方が変わります。データの性質に合わせて選ぶことが重要です。
まとめ
G検定の数理・統計は、用語が多く見える分野です。
しかし、記述統計、確率、確率分布、推定・検定、関係性の分析、距離・類似度という順番で見ると、機械学習を支える道具セットとして整理できます。
記述統計は、データを見るための入口です。確率や確率分布は、不確実性を扱うための土台です。推定・検定は、データに基づく判断に役立ちます。
相関や相互情報量は、特徴量の関係を見るために使います。距離・類似度は、データ同士の近さを測るために使います。
つまり、数理・統計は試験用の暗記項目ではなく、AIや機械学習を正しく理解するための基礎です。
まとめのまとめ
- 記述統計は、平均・中央値・分散・標準偏差・外れ値からデータ理解へ接続
- 確率分布と推定・検定は、不確実性と統計的判断の土台
- 相関・距離・類似度は、特徴理解とモデル解釈の重要ポイント
FAQ
G検定で数理・統計はどこまで覚える必要があるか
定義だけでなく、どの場面で使うかまで押さえることが大切です。平均や分散はデータ理解、確率分布は不確実性、仮説検定は統計的判断、相関や距離は特徴理解に関わります。
平均・中央値・最頻値の違いは何か
平均は合計をデータ数で割った値、中央値は小さい順に並べたとき中央に来る値、最頻値は最も多く出現する値です。外れ値がある場合は、平均だけでなく中央値も見ることが重要です。
分散と標準偏差は何が違うか
分散は平均からのばらつきを二乗で表す指標です。標準偏差は分散の平方根で、元のデータの単位に近い形でばらつきを見られます。
ベルヌーイ分布・二項分布・ポアソン分布・正規分布の違いは何か
ベルヌーイ分布は1回の成功・失敗、二項分布は複数回の成功回数、ポアソン分布は一定範囲のイベント発生回数、正規分布は連続値や誤差を表す山型の分布です。
推定と検定の違いは何か
推定は未知のパラメータをデータから見積もることです。検定は、帰無仮説と対立仮説を立て、データに基づいて仮説を判断することです。
最尤法と最小二乗法の違いは何か
最尤法は、観測されたデータが最も起こりやすくなるようにパラメータを選ぶ方法です。最小二乗法は、予測値と観測値の差である残差の二乗和が小さくなるようにパラメータを選ぶ方法です。
相関と因果は同じか
相関と因果は同じではありません。相関は2つの変数が一緒に変化する傾向を表しますが、原因と結果の関係を示すとは限りません。第三の変数が影響している疑似相関にも注意が必要です。
ユークリッド距離とコサイン類似度の違いは何か
ユークリッド距離は2点間のまっすぐな距離を見ます。コサイン類似度はベクトルの向きの近さを見ます。大きさを重視するか、方向を重視するかで選びます。
マハラノビス距離は何に使うか
マハラノビス距離は、分散や共分散を考慮してデータ同士の距離を見る指標です。データの広がり方を踏まえて外れ値を見つけたい場合などに使われます。
バックナンバーはこちら
参考文献
一般社団法人日本ディープラーニング協会「G検定 公式ページ」
https://www.jdla.org/certificate/general/
NIST/SEMATECH e-Handbook of Statistical Methods
https://www.itl.nist.gov/div898/handbook/
NIST/SEMATECH e-Handbook of Statistical Methods「What are statistical tests?」
https://www.itl.nist.gov/div898/handbook/prc/section1/prc13.htm
Penn State STAT 414「Introduction to Probability Theory」
https://online.stat.psu.edu/stat414/
Penn State STAT 414「Conditional Probability」
https://online.stat.psu.edu/stat414/Lesson04
Penn State STAT 414「Approximations for Discrete Distributions」
https://online.stat.psu.edu/stat414/Lesson28
Penn State STAT 414「The Correlation Coefficient」
https://online.stat.psu.edu/stat414/Lesson18
Penn State STAT 415「Section 2: Hypothesis Testing」
https://online.stat.psu.edu/stat415/section/7
UMBC Computer Science and Electrical Engineering「IR Models: The Vector Space Model」
https://www.csee.umbc.edu/~ian/irF02/lectures/07Models-VSM.pdf
Bar-Ilan University「Mahalanobis Distance」
https://u.cs.biu.ac.il/~shahamu/lecture%20notes%20pdf%20files/Mahalanobis.pdf
この記事に合う書籍
G検定対策の軸になる本
深層学習教科書 ディープラーニング G検定 公式テキスト

G検定対策の中心に置きたい公式テキストです。
この記事で整理した「AIに必要な数理・統計知識」は、G検定全体の一部です。そのため、まずは公式テキストで試験範囲全体を確認し、数理・統計がどの位置づけにあるのかを押さえると学習しやすくなります。
特に、G検定をこれから受ける人は、この記事で数理・統計の地図をつかんだあと、公式テキストで用語の定義や出題範囲を確認する流れがおすすめです。
徹底攻略ディープラーニングG検定ジェネラリスト問題集

公式テキストで学んだ内容を、試験形式で確認するための問題集です。
数理・統計の用語は、分かったつもりでも問題になると迷いやすい分野です。平均、分散、標準偏差、確率分布、仮説検定、相関係数などを、選択肢の中で正しく見分ける練習に向いています。
G検定合格を優先するなら、公式テキストと問題集はセットで使うのが効率的です。
平均・分散・標準偏差・仮説検定を固める本
統計学入門 基礎統計学I

統計学を体系的に学びたい人向けの定番書です。
この記事で扱った、平均、中央値、分散、標準偏差、確率、確率分布、推定、仮説検定、回帰分析などを、きちんとした順番で学べます。
G検定だけを目的にするとやや本格的ですが、「統計をちゃんと理解したい」「試験後も使える知識にしたい」という人には相性が良い本です。
機械学習がわかる統計学入門

この記事との相性がかなり良い統計入門書です。
平均値、分散、相関、共分散、確率分布、線形回帰、ロジスティック回帰、マハラノビス距離など、機械学習と統計の接点を意識して学べます。
「統計学入門 基礎統計学I」よりも、機械学習でどう使うかを意識しやすいため、G検定対策と実務寄りの理解をつなげたい人に向いています。
AIに必要な数学を補強する本
人工知能プログラミングのための数学がわかる本

数学に苦手意識がある人向けの入門書です。
ベクトル、行列、微分、確率・統計など、AIや機械学習で必要になる数学をやさしく整理できます。
この記事では数式を最小限にしていますが、「なぜ分散や標準偏差が重要なのか」「なぜ距離や類似度にベクトルが出てくるのか」をもう少し理解したい場合に役立ちます。
最短コースでわかる ディープラーニングの数学

ディープラーニングに必要な数学を、効率よく学びたい人向けの本です。
最小二乗法、微分、勾配降下法、誤差逆伝播など、G検定の数理・統計から一歩進んだ内容に接続できます。
G検定対策だけでなく、ニューラルネットワークの仕組みを数式面から理解したい人に合います。
相関・距離・類似度・分類を深める本
はじめてのパターン認識

分類、特徴量、距離、類似度をもう少し深めたい人向けの入門書です。
この記事の後半で扱った、ユークリッド距離、コサイン類似度、マハラノビス距離、特徴理解、分類などに関心がある人に向いています。
「データ同士が似ているとはどういうことか」「特徴量を使ってどう分類するのか」を、機械学習の文脈で学びたい場合におすすめです。
パターン認識と機械学習 上・下

機械学習理論を本格的に学びたい人向けの定番書です。
ベイズ理論、確率分布、回帰、識別、ニューラルネットワークなどを体系的に扱います。
ただし、内容はかなり本格的です。G検定の直前対策というより、合格後に理論を深めたい人向けです。
確率・統計から機械学習を本格的に学ぶ本
確率的機械学習:入門編 I

確率と統計の視点から、機械学習を本格的に学びたい人向けの本です。
この記事で扱った、確率変数、確率分布、期待値、最尤法、推定、統計的判断などを、より深い機械学習理論へつなげられます。
かなり厚みのある本なので、G検定対策中に無理に読む必要はありません。合格後に、機械学習を理論から理解したい人に向いています。
実装寄りに進みたい人向け
ゼロから作るDeep Learning

数理・統計の知識を、実際のニューラルネットワーク実装につなげたい人向けの本です。
Pythonを使いながら、ニューラルネットワーク、損失関数、勾配、学習の仕組みを理解できます。
この記事自体はPythonコードなしで読める構成ですが、G検定後に「実際にAIモデルがどう動くのか」を手を動かして学びたい場合におすすめです。
ゼロから作るDeep Learning ❻ LLM編

LLMに興味がある人向けの発展学習本です。
G検定の数理・統計対策というより、生成AIや大規模言語モデルの仕組みを実装面から学びたい人向けです。
G検定合格後に、TransformerやLLMの理解へ進みたい場合の候補になります。


コメント