その他のエッセイはこちら


- 要約
- 合わせて読むことをお勧めの記事
- はじめに
- incremental PIDの整理
- RNN-like incremental controllerの考え方
- このRNNは何を学習しているのか
- これはPIDなのか
- この構造の利点
- 限界と保護機能
- 既存研究との位置づけ
- quasi-sliding-modeを薄く足す考え方
- 普通のスライディングモードとの違い
- 滑り面 $s_t$ は何を表しているのか
- 比較条件の考え方
- シミュレーション設定
- Pythonコード:通常の速度型PID・RNN-like incremental controller・QSM付きRNNの比較
- シミュレーション結果の見方
- 実運用を考えるなら
- FAQ
- まとめ
- 参考文献
- 1. まず土台を固める本
- 2. PIDをちゃんと深く読む本
- 3. スライディングモードとロバスト性を学ぶ本
- 4. RNNと深層学習の基礎を押さえる本
- この記事との相性で並べるなら
- 迷ったらこの3冊
要約
- 速度型PIDの増分構造を残したまま、RNNで局面依存の増分生成を担わせる考え方。
- 比較用の通常PIDもある程度きちんと調整し、構造差を見やすくする方針。
- 目標値近傍の締まりを改善したいなら、quasi-sliding-modeを薄く重ねる構成が扱いやすい。
合わせて読むことをお勧めの記事


はじめに
RNNとPIDを組み合わせる発想は、思いつきとしてかなり自然です。
ただし、いきなり操作量そのものをRNNに直接出させると、制御器としての意味づけが急に弱くなります。
そこで扱いやすいのが、速度型PIDの増分構造を残し、その増分生成部だけをRNN風に置き換える考え方です。
今回の記事では、次の3つを同じ土俵で見ます。
- 通常の速度型PID
- RNN-like incremental controller
- RNN-like incremental controller + quasi-sliding-mode 補正
なお、数式モデルとPythonコードは補足です。
読み飛ばしても、本文だけで全体像は追えるようにしています。
incremental PIDの整理
incremental PID は、操作量そのものを直接決めるのではなく、前回からどれだけ増減させるかを計算するPIDです。
日本語では「増分型PID」や「速度型PID」と呼ばれることが多いです。
位置型PIDのイメージは次です。
$$
u_{t} = K_{P} e_{t} + K_{I} \sum_{k=0}^{t} e_{k} + K_{D} (e_{t} – e_{t-1})
$$
これに対して、incremental PID はまず増分 $\Delta u_{t}$ を計算し、それを積み上げます。
$$
\Delta u_{t}=
K_{P} (e_{t} – e_{t-1})
+
K_{I} e_{t}
+
K_{D} (e_{t} – 2 e_{t-1} + e_{t-2})
$$
$$
u_{t} = u_{t-1} + \Delta u_{t}
$$
この形の利点は、出力制限、増分制限、レートリミットを入れやすいことです。
デジタル制御との相性もよく、実装上の扱いやすさがあります。
RNN-like incremental controllerの考え方
今回の基本構造は次です。
$$
e_{t} = r_{t} – y_{t}
$$
$$
h_{t} = \mathrm{GRU}(e_{t}, h_{t-1})
$$
$$
\Delta u_{t}=
w_{P}^{\top} (h_{t} – h_{t-1})
+
w_{I}^{\top} h_{t}
+
w_{D}^{\top} (h_{t} – 2 h_{t-1} + h_{t-2})
$$
$$
u_{t} = \mathrm{clip}(u_{t-1} + \Delta u_{t}, u_{min}, u_{max})
$$
見た目の対応はかなり明快です。
- $h_{t} – h_{t-1}$ : P項相当
- $h_{t}$ : I項相当
- $h_{t} – 2 h_{t-1} + h_{t-2}$ : D項相当
- $u_{t-1} + \Delta u_{t}$ : 出力側の積分
つまり、速度型PIDの部品はかなり残っています。
ただし純粋なPIDとの違いは、差分演算の対象が誤差 $e_{t}$ そのものではなく、RNNが作った内部表現 $h_{t}$ になっていることです。
このRNNは何を学習しているのか
このRNNは、固定の $K_{P}$、$K_{I}$、$K_{D}$ をそのまま学習しているわけではありません。
学習しているのは、誤差の履歴から「次にどれだけ操作量を増減させるか」を決めるための内部表現です。
入力は各時刻の誤差だけです。
$$
e_{t} = r_{t} – y_{t}
$$
GRUはこの誤差系列を受け取り、隠れ状態 $h_{t}$ に履歴情報を圧縮します。
この $h_{t}$ には、現在誤差だけでなく、最近の増減傾向、ずれの継続、戻り始めたかどうかといった情報が内部状態として入ります。
そのうえで、次のように増分を作ります。
$$
\Delta u_{t}=
w_{P}^{\top} (h_{t} – h_{t-1})
+
w_{I}^{\top} h_{t}
+
w_{D}^{\top} (h_{t} – 2 h_{t-1} + h_{t-2})
$$
つまりこの制御器は、固定ゲインPIDではなく、誤差履歴から局面依存の増分則を作る再帰型制御器です。
これはPIDなのか
厳密には、純粋なPIDではありません。
PIDの本来の形は、誤差そのものに比例・積分・微分演算をかけて操作量を作るものです。
一方で今回の構造は、
- 誤差 $\rightarrow$ RNN内部表現 $h_{t}$
- $h_{t}$ に対して速度型PIDの差分構造を適用
- 最後に積分器で操作量へ変換
という流れです。
そのため、呼び方としてはいちばん自然なのは次のようなものです。
- RNNベースの速度型PID風制御器
- PID-like recurrent incremental controller
- PID構造を残したRNN増分制御器
ただし、部品として速度型PIDの骨格はかなり残っています。
「速度型PIDの差分演算と出力積分が、RNNと合体した形で残っている」と考えるのがもっとも自然です。
さらにこの構造は、完全なブラックボックス制御器より、学習後の人手調整余地を残しやすいです。
最終段がP項相当、I項相当、D項相当の3経路に分かれているため、どの寄与を強めるか、どこを少し抑えるかを比較的明示的に扱えます。
ただし、ここで直接触っているのは誤差そのものではなく、RNNが作った内部表現 $h_t$ への射影です。
そのため、古典PIDの $K_P,K_I,K_D$ のように一対一で意味が固定されているわけではなく、実際には「構造を保ったままの微調整がしやすい」と理解するのが自然です。
実務上は、$w_P,w_I,w_D$ の全成分を人が直接いじるというより、各経路の全体倍率 $\alpha_P,\alpha_I,\alpha_D$ を後段につけておき、学習後にそこを微調整する方が扱いやすいです。
※ 本記事では扱わないが以下が実務向けカスタム例
$$
\Delta u_t=
\alpha_P\, w_P^\top (h_t-h_{t-1})
+
\alpha_I\, w_I^\top h_t
+
\alpha_D\, w_D^\top (h_t-2h_{t-1}+h_{t-2})
$$
この構造の利点
この構造の利点は、単にニューラルネットワークを使えることではありません。
本質は、PIDの枠組みを壊しすぎずに、非線形や局面依存を吸収しやすくするところにあります。
効きやすい場面は次のようなものです。
- 非線形性の強い対象
- 動作点で特性が変わる対象
- 同じ誤差でも局面によって最適操作が変わる対象
- 履歴依存の判断が効く対象
固定ゲインPIDだと、これらを1組のゲインで妥協して見なければなりません。
RNNを入れると、立ち上がり中、整定直前、外乱直後、飽和近傍などで異なる増分を出し分けやすくなります。
PIDをニューラルネットワークで初期化・改良する流れは1990年代からあり、RNNでPIDを自動調整する流れや、PID-likeな再帰ネットワークとして構成する流れも実際にあります。
NeurIPS 1991: https://proceedings.neurips.cc/paper/1991/file/285e19f20beded7d215102b49d5c09a0-Paper.pdf
TUM Technical Report 2017: https://mediatum.ub.tum.de/doc/1381851/534530033346.pdf
限界と保護機能
ここはかなり重要です。
RNN-like incremental controller は、学習分布の中では強い一方、未知パターンでは危険側に外れることがあります。
たとえば危険になりやすいのは次のようなケースです。
- 想定外の負荷変動
- 学習時に少なかった目標値変化
- センサ異常
- 飽和近傍での特殊挙動
- モデル化していない遅れ
そのため、実運用を考えるなら保護機能を前提にした方がよいです。
- 通常PIDの並走
- $u_{rnn,t}$ と $u_{pid,t}$ の差分監視
- 出力制限
- 増分制限
- レートリミット
- 誤差の窓平均監視
- 飽和継続時間の監視
- フェイルバック
- PIDへのブレンド切替
アンチワインドアップや入力制限を考慮した制御設計は、古典制御でも重要なテーマです。
現代的な anti-windup の整理でも、飽和を含む系で安定性や性能を保つための構成法がまとめられています。
https://homepages.laas.fr/lzaccari/preprints/ZackEJC09.pdf
既存研究との位置づけ
この方向性は完全な新規ではありません。
少なくとも、PIDの式をニューラルネットワークへ埋め込む流れ、ニューラルネットワークでPIDゲインを自己調整する流れ、PID-like recurrent network を作る流れは、1990年代から現在まで続いています。
今回の構成は、その中でも「速度型PIDの差分構造をRNN内部表現に対して適用し、最終段の積分器と制約を残す」整理に寄せたものです。
完全に同一の定番名が広く固定されているわけではありませんが、系譜としては既存研究の延長上にあります。
関連する例:
- NeurIPS 1991
https://proceedings.neurips.cc/paper/1991/file/285e19f20beded7d215102b49d5c09a0-Paper.pdf - TUM Technical Report 2017
https://mediatum.ub.tum.de/doc/1381851/534530033346.pdf - ISA Transactions 2016
https://www.sciencedirect.com/science/article/pii/S0019057816000343
この流れは、古典的な適応PIDから見ると理解しやすいです。
まずSTRでは、対象や制御器を逐次調整する枠組みがあり、その中ではAR/ARXのような明示的な自己回帰モデルを使ってPIDゲインや制御則を更新する構成がよく取られます。
そこから見れば、RNNを使う構成は、明示モデルの代わりに履歴依存性を潜在状態へ持たせる方向の拡張と見なせます。
さらに今回の構成では、単にRNNでPIDを補助するのではなく、誤差そのものではなくRNN内部状態 $h_t$ に対して速度型PID風の差分構造を適用しています。
したがって可変対象はゲインそのものよりも、誤差履歴の要約表現に移っていると見る方が自然です。
quasi-sliding-modeを薄く足す考え方
RNN-like incremental controller だけでも動きますが、立ち上がりを強めると目標値近傍で軽いオーバーシュートが出やすいです。
このとき、RNNそのものをさらに複雑にするより、外側に quasi-sliding-mode 的な収束補正を薄く足す方が扱いやすいです。
今回の簡易な補正は次の形です。
$$
s_{t} = \lambda e_{t} + (e_{t} – e_{t-1})
$$
$$
\Delta u_{t}=
\Delta u_{t}^{rnn}
+
k \tanh\left(\displaystyle \frac{s_{t}}{\phi}\right)
$$
ここでの狙いは、目標値から遠いときはRNN主体で大きく運び、目標値近傍では滑り面に基づく補正で少し締めることです。
今回のシミュレーションでは、lam=0.30, k=0.06, phi=0.05 とすると、目標値近傍の締まりがかなり見やすくなりました。
ただし、QSMを足したからといって必ずオーバーシュートがゼロになるわけではありません。
離散時間、増分制限、出力制限、平滑化された $\tanh$ 補正を入れている以上、少し残ることは普通にあります。
そのため、QSMは「すべてを解決する主役」というより、「最後の締まりをよくする補正」と考える方が自然です。
普通のスライディングモードとの違い
古典的なスライディングモード制御では、滑り面 $s = 0$ へ状態を強く引き寄せるために、不連続な切換入力がよく使われます。
典型的には、次のような形です。
$$
u = u_{eq} – K ,\mathrm{sign}(s)
$$
ここで $u_{eq}$ は等価制御、$K$ は到達性を確保するためのゲイン、$s$ は滑り面です。
この形は、理想論としては滑り面へ強く引き寄せやすい一方で、実装ではチャタリングを起こしやすいです。
スライディングモード制御の基本整理や実装ガイドでは、まず滑り面へ軌道を収束させ、そのうえで不確かさや外乱に対してロバスト性を得るという説明が一般的です。
MathWorks の解説: https://www.mathworks.com/help/slcontrol/ug/design-sliding-mode-control-reaching-law.html
そのため、実装寄りのスライディングモード制御では、滑り面近傍の切換をなめらかにする工夫がよく行われます。
代表的なのは、sign をそのまま使わず、saturation や tanh で境界層を作る方法です。
$$
u = u_{eq} – K \tanh\left(\displaystyle \frac{s}{\phi}\right)
$$
この $\phi$ は境界層の厚みを表し、値が小さいほど sign に近づき、値が大きいほど滑らかになります。
つまり、今回のコードで tanh を使っているのは変則的な工夫ではなく、チャタリングを抑えたいときのかなり普通の実装寄りの考え方です。
MathWorks の説明でも、boundary layer を設けて hyperbolic tangent で滑らかにする考え方が示されています。
https://www.mathworks.com/help/slcontrol/ug/design-sliding-mode-control-reaching-law.html
ただし、今回の記事で扱っているものは、理想的な普通のスライディングモードをそのまま入れたものではありません。
RNN-like incremental controller に対して、滑り面近傍をなめらかにした quasi-sliding-mode 的な補正を薄く重ねています。
$$
s_{t} = \lambda e_{t} + (e_{t} – e_{t-1})
$$
$$
\Delta u_{t}=
\Delta u_{t}^{rnn}
+
k \tanh\left(\displaystyle \frac{s_{t}}{\phi}\right)
$$
そのため位置づけとしては、
- 普通の理想SMC:
sign(s)による不連続切換が主役 - 実装寄りのSMC:
saturationやtanhによる平滑化を導入 - 今回の構成: RNNの増分制御に quasi-sliding-mode 的な平滑化補正を重ねたハイブリッド
と考えるのが自然です。
離散時間の quasi-sliding-mode では、状態を滑り面そのものではなく、ある帯域内に保つ整理が使われます。
その考え方は次の文献が参考になります。
https://ir.lib.nycu.edu.tw/bitstream/11536/8467/1/000259154400007.pdf
滑り面 $s_t$ は何を表しているのか
滑り面 $s_t$ は、単なる誤差の大きさではなく、切り替え線に対する符号付きのずれを表す量として見ると分かりやすいです。
連続時間でよく使われる滑り面は、次のような形です。
$$
s = \dot e + \lambda e
$$
このとき、滑り面そのものは $s=0$ で表されます。
つまり、$(e,\dot e)$ 平面で見ると、
$$
\dot e = -\lambda e
$$
という直線が切り替え線に相当します。
ここでの $s$ は、この直線のどちら側にいるかと、どの程度ずれているかをまとめた量です。
厳密には幾何学的な距離そのものではありませんが、切り替え線からの符号付き距離に比例する量と考えると直感的です。
実際、直線 $\dot e + \lambda e = 0$ に対する符号付き距離は、正規化すると次のように書けます。
$$
\displaystyle \frac{\dot e + \lambda e}{\sqrt{1+\lambda^2}}
$$
したがって、$s=\dot e+\lambda e$ は、正規化前の符号付き距離に対応していると見なせます。
今回の離散時間版では、$\dot e$ の代わりに誤差差分 $(e_t-e_{t-1})$ を使っているため、滑り面を次のように置いています。
$$
s_t = \lambda e_t + (e_t – e_{t-1})
$$
この式も考え方は同じです。
$s_t=0$ が切り替え線に相当し、$s_t$ の符号が線のどちら側にいるかを表します。
また、$|s_t|$ が大きいほど、その線からのずれも大きいと考えられます。
この $s_t$ をそのまま sign に入れると不連続な切換になりますが、本記事では実装を穏やかにするため、次のように tanh を使っています。
$$
\Delta u_t=
\Delta u_t^{rnn}
+
k \tanh\left(\displaystyle \frac{s_t}{\phi}\right)
$$
ここで重要なのは、切り替え線 $s_t=0$ が、そのまま tanh にとっての 0 になっていることです。
- $s_t=0$ なら $\tanh(0)=0$
- $s_t>0$ なら正の補正
- $s_t<0$ なら負の補正
つまり、tanh は切り替え線からの符号付きずれを、なめらかな補正信号へ変換していると解釈できます。
この意味で、本記事の quasi-sliding-mode 補正は、切り替え線との関係を見ながら制御入力を切り替える考え方を保ちつつ、sign の代わりに tanh を使って実装を滑らかにしたものです。
比較条件の考え方
比較用の通常PIDが未調整だと、構造差ではなくチューニング差を見てしまいやすいです。
そこで今回は、通常の速度型PIDも、このシミュレーション条件で応答性が近づくように再調整しています。
具体的には、比較用の速度型PIDは次のように置きます。
- $K_{P} = 1.00$
- $K_{I} = 0.80$
- $K_{D} = 0.08$
この設定にすると、通常PIDもかなりしっかり追従し、比較が見やすくなります。
そのうえで、
- 通常PIDは固定ゲインの基準系
- RNN版は局面依存の増分生成
- QSM付きRNN版は目標値近傍の締まり改善
という違いを見ます。
シミュレーション設定
以下のコードでは、同じ非線形離散時間プラントを使います。
特定の実機モデルではなく、比較用の簡易モデルです。
$$
y_{t+1} = 0.88 y_{t} + 0.32 \tanh(u_{t}) – 0.01 y_{t}^{3}
$$
目標値はステップ状に切り替えます。
また、比較を見やすくするために、各目標値の滞在時間はやや長めに取っています。
数式とコードは補足です。
読み飛ばしても、記事の主張自体は追えます。
Pythonコード:通常の速度型PID・RNN-like incremental controller・QSM付きRNNの比較
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
# --------------------------------------------------
# 基本設定
# --------------------------------------------------
# 乱数シードを固定
# 毎回まったく同じ結果になることを完全保証するものではないが、
# 少なくとも再現しやすくするために入れておく
torch.manual_seed(0)
np.random.seed(0)
# シミュレーション長
T = 160
# 操作量の上下限制限
U_MIN, U_MAX = -3.0, 3.0
# 1ステップあたりの増分制限
DU_MAX = 0.35
# --------------------------------------------------
# 参照値とプラント
# --------------------------------------------------
def make_reference(length: int) -> torch.Tensor:
"""
比較しやすいように、複数のステップ目標値を並べる
"""
r = torch.zeros(length)
r[20:60] = 0.8
r[60:100] = -0.5
r[100:] = 0.6
return r
def plant_step(y: torch.Tensor, u: torch.Tensor) -> torch.Tensor:
"""
軽い非線形を持つ離散時間プラント
tanh(u) により、大入力時に飽和っぽい性質を持たせる
"""
return 0.88 * y + 0.32 * torch.tanh(u) - 0.01 * y**3
# --------------------------------------------------
# 通常の速度型PID
# --------------------------------------------------
def simulate_incremental_pid(
reference: torch.Tensor,
kp: float = 1.00,
ki: float = 0.80,
kd: float = 0.08,
):
"""
比較用の通常の速度型PID
今回は比較しやすいよう、ある程度応答性が近づくように調整している
"""
y = torch.tensor(0.0)
u = torch.tensor(0.0)
e_prev = torch.tensor(0.0)
e_prev2 = torch.tensor(0.0)
ys = []
us = []
for t in range(len(reference)):
# 現在の誤差
e = reference[t] - y
# 速度型PIDの増分式
du = (
kp * (e - e_prev)
+ ki * e
+ kd * (e - 2 * e_prev + e_prev2)
)
# 増分制限
du = torch.clamp(du, -DU_MAX, DU_MAX)
# リミット付き積分
u = torch.clamp(u + du, U_MIN, U_MAX)
# プラント更新
y = plant_step(y, u)
ys.append(y.item())
us.append(u.item())
# 過去誤差更新
e_prev2 = e_prev
e_prev = e
return np.array(ys), np.array(us)
# --------------------------------------------------
# RNNベース制御器
# --------------------------------------------------
class RNNIncrementalController(nn.Module):
def __init__(self, hidden_size: int = 6):
super().__init__()
# 誤差のみを入力とするGRU
self.gru = nn.GRUCell(1, hidden_size)
# 速度型PID風の各項
self.term_p = nn.Linear(hidden_size, 1, bias=False)
self.term_i = nn.Linear(hidden_size, 1)
self.term_d = nn.Linear(hidden_size, 1, bias=False)
def rollout(
self,
reference: torch.Tensor,
use_qsm: bool = False,
lam: float = 0.30,
k: float = 0.06,
phi: float = 0.05,
):
"""
use_qsm=False:
RNN-like incremental controller
use_qsm=True:
quasi-sliding-mode 補正を追加
"""
y = torch.tensor(0.0)
u = torch.tensor(0.0)
# 現在と過去の隠れ状態
h = torch.zeros(1, self.gru.hidden_size)
h_prev = torch.zeros_like(h)
h_prev2 = torch.zeros_like(h)
# QSM用の前回誤差
e_prev = torch.tensor(0.0)
ys = []
us = []
for t in range(len(reference)):
# 誤差だけをRNNへ入れる
e = reference[t] - y
h_new = self.gru(e.view(1, 1), h)
# 速度型PID風の差分構造
# P項相当: h_t - h_{t-1}
# I項相当: h_t
# D項相当: h_t - 2 h_{t-1} + h_{t-2}
du_rnn = (
self.term_p(h_new - h_prev)
+ self.term_i(h_new)
+ self.term_d(h_new - 2 * h_prev + h_prev2)
).squeeze()
if use_qsm:
# quasi-sliding-mode 的な補正
# sign をそのまま使わず、tanh で滑らかにする
# 目標値近傍の締まりを改善する狙い
s = lam * e + (e - e_prev)
du_qsm = k * torch.tanh(s / phi)
du = du_rnn + du_qsm
else:
du = du_rnn
# 増分制限
du = torch.clamp(du, -DU_MAX, DU_MAX)
# リミット付き積分
u = torch.clamp(u + du, U_MIN, U_MAX)
# プラント更新
y = plant_step(y, u)
ys.append(y)
us.append(u)
# 状態更新
h_prev2 = h_prev
h_prev = h_new
h = h_new
e_prev = e
return torch.stack(ys), torch.stack(us)
def forward(self, reference: torch.Tensor):
"""
学習時はQSMなしのRNN本体だけを学習する
"""
return self.rollout(reference, use_qsm=False)
def loss_fn(y: torch.Tensor, u: torch.Tensor, reference: torch.Tensor) -> torch.Tensor:
"""
学習用損失
- 追従誤差
- 操作量の大きさ
- 操作量変化の荒さ
"""
tracking = torch.mean((y - reference) ** 2)
effort = 0.0005 * torch.mean(u ** 2)
rate = 0.002 * torch.mean((u[1:] - u[:-1]) ** 2)
return tracking + effort + rate
# --------------------------------------------------
# 学習と比較
# --------------------------------------------------
# 参照値を用意
reference = make_reference(T)
# RNN制御器を作成
controller = RNNIncrementalController(hidden_size=6)
# 最適化器
optimizer = torch.optim.Adam(controller.parameters(), lr=0.01)
# RNN本体を学習
for epoch in range(180):
y_pred, u_pred = controller(reference)
loss = loss_fn(y_pred, u_pred, reference)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 学習後に3系統を同条件で比較
with torch.no_grad():
y_rnn, u_rnn = controller.rollout(reference, use_qsm=False)
y_qsm, u_qsm = controller.rollout(
reference,
use_qsm=True,
lam=0.30,
k=0.06,
phi=0.05,
)
y_pid, u_pid = simulate_incremental_pid(reference)
# MSEを表示
mse_pid = np.mean((y_pid - reference.numpy()) ** 2)
mse_rnn = torch.mean((y_rnn - reference) ** 2).item()
mse_qsm = torch.mean((y_qsm - reference) ** 2).item()
print(f"Incremental PID MSE: {mse_pid:.6f}")
print(f"RNN-like incremental controller MSE: {mse_rnn:.6f}")
print(f"RNN + quasi-sliding-mode MSE: {mse_qsm:.6f}")
# --------------------------------------------------
# グラフ1: 出力応答の比較
# --------------------------------------------------
plt.figure(figsize=(10, 5))
plt.plot(reference.numpy(), label="reference")
plt.plot(y_pid, label="incremental_pid")
plt.plot(y_rnn.numpy(), label="rnn_like_incremental")
plt.plot(y_qsm.numpy(), label="rnn_plus_qsm")
plt.xlabel("time step")
plt.ylabel("output")
plt.title("Incremental PID vs RNN-like vs RNN + quasi-sliding-mode")
plt.legend()
plt.tight_layout()
plt.show()
# --------------------------------------------------
# グラフ2: 操作量の比較
# --------------------------------------------------
plt.figure(figsize=(10, 5))
plt.plot(u_pid, label="u_pid")
plt.plot(u_rnn.numpy(), label="u_rnn")
plt.plot(u_qsm.numpy(), label="u_qsm")
plt.xlabel("time step")
plt.ylabel("control input")
plt.title("Control input comparison")
plt.legend()
plt.tight_layout()
plt.show()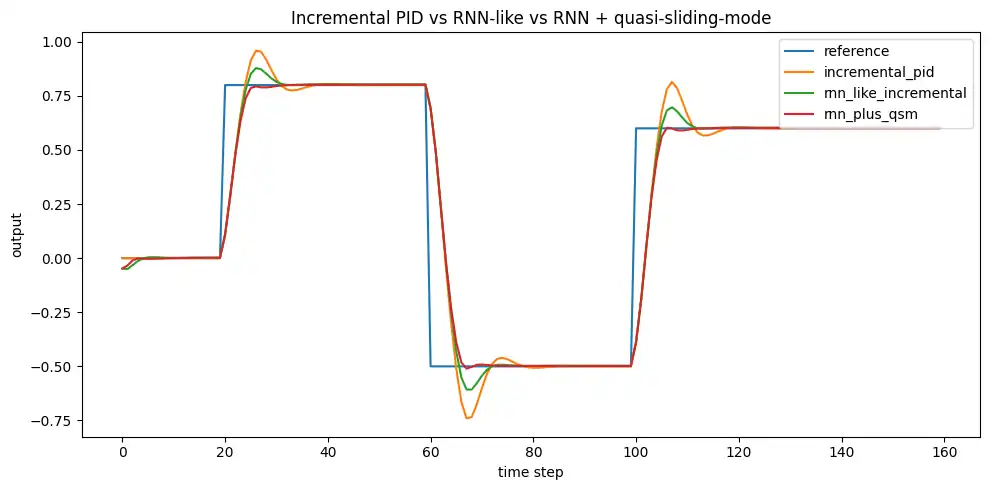
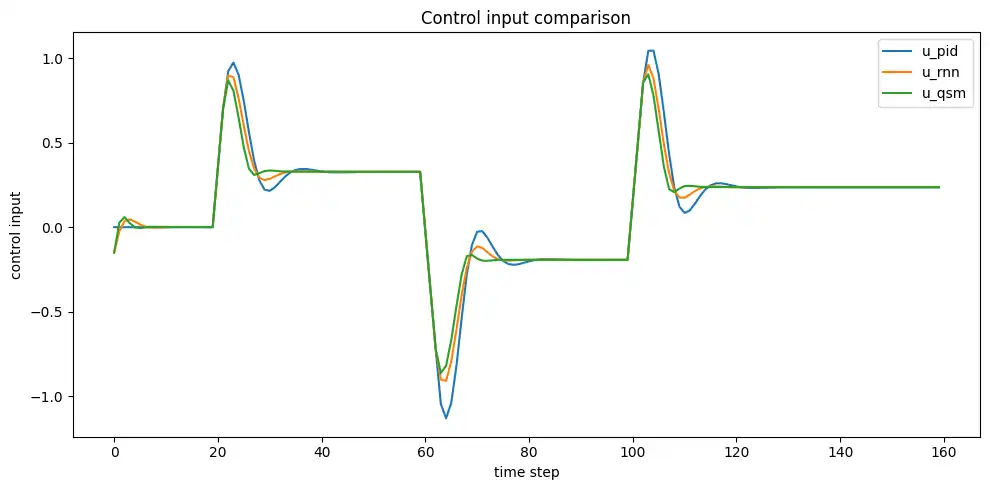
シミュレーション結果の見方
今回のコードでは、通常の速度型PID、RNN-like incremental controller、quasi-sliding-mode 補正付きのRNN制御器を同じプラント、同じ参照値、同じ出力制限、同じ増分制限で比較しています。
また、操作量のグラフも合わせて見ることで、追従誤差だけでなく、どの制御器がどのくらい強く入力を動かしているかも確認できます。
実際の数値は PyTorch のバージョンや実行環境で多少変わりますが、見たいポイントは次です。
- 通常PID: 固定ゲインの基準系
- RNN版: 局面依存の増分生成
- QSM付きRNN版: 目標値近傍の締まり改善
なお、QSM付きでも少しのオーバーシュートが残ることはあります。
これは失敗ではなく、離散時間、増分制限、出力制限、平滑化補正を同時に入れている以上、ある程度自然な挙動です。
QSMは主役ではなく、最後の締まりを改善する補正と考える方が自然です。
実運用を考えるなら
この種の制御器を実運用へ近づけるなら、RNN単独で信用しきるより、通常PIDと並走させる方が安全です。
たとえば次のような構成が考えやすいです。
- 通常PID: 安全側の基準
- RNN-like incremental controller: 高性能側の補償
- 監視ロジック: 安全管理
監視対象としては次のようなものが候補になります。
- $u_{rnn,t}$ と $u_{pid,t}$ の乖離
- 誤差の窓平均
- 飽和継続時間
- 増分の急変
- 高周波振動の増加
異常時には、PIDへ切り替えるか、あるいは両者をブレンドしてRNN寄りの比率を下げる構成が扱いやすいです。
FAQ
incremental PIDとは何か
incremental PID は、操作量そのものではなく前回からの増分を計算するPIDです。
増分を積み上げて操作量にするため、出力制限やレートリミットを入れやすいです。
このRNNは何を学習しているのか
固定ゲインをそのまま覚えているのではなく、誤差の履歴から次の増分をどう作るかを学習しています。
誤差系列を内部状態へ圧縮し、その内部状態に対して速度型PIDに似た差分構造を当てています。
quasi-sliding-mode を加えると、もうPIDではないのか
純粋なPIDではありません。
ただし、速度型PIDの1階差分、恒等、2階差分、出力積分という骨格は部品として残っています。
そのため、PID-likeなRNN増分制御器にquasi-sliding-mode補正を加えたハイブリッド制御器と見るのが自然です。
RNNだけで実運用してよいか
学習分布の中では高性能が期待できますが、未知パターンでは危険です。
通常のPIDを並走させた差分監視、出力制限、レートリミット、誤差の継続監視、フェイルバックを組み合わせる方が安全です。
quasi-sliding-mode を足す利点は何か
目標値近傍での収束の締まりをよくしやすい点です。
RNNだけだと立ち上がり重視で軽いオーバーシュートが出ることがありますが、滑り面ベースの補正を薄く加えると、近傍でブレーキをかけやすくなります。
まとめ
RNNで速度型PIDの増分生成部を置き換える考え方は、単なる思いつきではなく、既存研究の流れにもつながる整理です。
しかも、最後の積分器や制約処理を残すことで、完全なブラックボックス制御より扱いやすい構造になります。
比較用の通常PIDもきちんと調整しておくと、構造差が見やすくなります。
そのうえで、RNN版は局面依存の出し分け、QSM付きRNN版は目標値近傍の締まり改善という役割分担が見えてきます。
今回の quasi-sliding-mode 補正で tanh を使っているのは、普通のスライディングモードから外れた特殊な工夫ではありません。
むしろ、sign をそのまま使った理想的な切換入力を、実装向けに滑り面近傍でなめらかにした、よくある整理に近いです。
MathWorks の説明: https://www.mathworks.com/help/slcontrol/ug/design-sliding-mode-control-reaching-law.html
- 速度型PIDの骨格は部品としてかなり残る
- RNNは誤差履歴から増分則を学習する
- QSMは主役ではなく最後の締まりを改善する補正
その他のエッセイはこちら
参考文献
- Gary M. Scott, Jude W. Shavlik, W. Harmon Ray, “Refining PID Controllers using Neural Networks,” NeurIPS 1991
https://proceedings.neurips.cc/paper/1991/file/285e19f20beded7d215102b49d5c09a0-Paper.pdf - Elias Reichensdörfer, Johannes Günther, Klaus Diepold, “Recurrent Neural Networks for PID Auto-tuning,” TUM Technical Report, 2017
https://mediatum.ub.tum.de/doc/1381851/534530033346.pdf - S. Cong, Y. Liang, “An adaptive PID like controller using mix locally recurrent neural network for robotic manipulator with variable payload,” ISA Transactions, 2016
https://www.sciencedirect.com/science/article/pii/S0019057816000343 - Sergio Galeani, Sophie Tarbouriech, Matthew Turner, Luca Zaccarian, “A Tutorial on Modern Anti-windup Design”
https://homepages.laas.fr/lzaccari/preprints/ZackEJC09.pdf - MathWorks, “Sliding Mode Control”
https://www.mathworks.com/help/slcontrol/ug/design-sliding-mode-control-reaching-law.html - S.-D. Xu, Y.-W. Liang, S.-W. Chiou, “Discrete-time quasi-sliding-mode control for a class of nonlinear control systems”
https://ir.lib.nycu.edu.tw/bitstream/11536/8467/1/000259154400007.pdf - “Discrete-Time Sliding Mode Control Strategies—State of the Art,” Energies, 2024
https://www.mdpi.com/1996-1073/17/18/4564 - 野波健蔵, 西村秀和, 平田光男, 「入力制限を考慮したスライディングモード制御系の設計」, 計測自動制御学会論文集
https://www.jstage.jst.go.jp/article/sicetr1965/33/12/33_12_1148/_pdf - 和田直樹, 「入力飽和システムのAnti-windup制御」
https://home.hiroshima-u.ac.jp/nwada/ISCIE02_expo.pdf - “Neural network-based sliding mode controllers applied to robotic manipulators: A review of the current state of the art,” Neurocomputing, 2023
https://www.sciencedirect.com/science/article/pii/S0925231223010196
1. まず土台を固める本
『制御工学(第2版) フィードバック制御の考え方』
いちばん素直な入口です。森北出版の紹介では、古典制御の基本を詳述した定番教科書で、補償器設計を手厚く説明し、自学自習にも向くとされています。今回の記事で出てくる「速度型PIDをどう位置づけるか」を整理する土台としてかなり相性がいいです。

『Pythonによる制御工学入門(改訂2版)』
記事の雰囲気にいちばん近い実践本はこれです。Pythonを使って制御工学を学ぶための入門書で、「使ってみる、やってみる」を通して制御工学を体感できる構成になっています。Pythonでシミュレーションを回しながら理解したいなら、かなり噛み合います。

2. PIDをちゃんと深く読む本
『PID制御 現代制御論の視点から』
この記事の中心テーマにいちばん近い本です。古典制御の伝達関数ベースではなく、状態方程式に基づく現代制御の視点からPID制御を解説しており、安定性理論、受動性、LMI、出力フィードバック、PID制御器の最適化、非線形システムのPIDまで扱っています。単なる「PIDの入門」を超えて、PIDを研究寄りに見たいなら最有力です。

3. スライディングモードとロバスト性を学ぶ本
『スライディングモード制御入門』
今回の quasi-sliding-mode の話に直結するなら、まずこれです。旧版のロングセラーを大幅に刷新し、基本的な考え方と基本構造から、実用的な最近の設計法までまとめた専門書とされています。この記事で触れた「理想的な sign 型SMC」と「tanh で平滑化した実装寄りのSMC」の橋渡しを理解しやすいです。

『線形ロバスト制御』
ロバスト制御、$H_2$ 制御、$H_\infty$ 制御、$\mu$ 設計法を網羅し、厳密性とわかりやすさを両立した教科書です。この記事そのものはPID・RNN・QSMが主役ですが、「未知パターンに対してどう守るか」を考え始めると、ロバスト制御の考え方が効いてきます。

『非線形最適制御入門』
非線形最適制御やモデル予測制御について、最適化の基礎から数値解法まで自己完結的かつ平易に解説した本です。今回の記事の「RNNで局面依存にうまく増分を出す」という感覚を、別方向から整理したいときに向いています。PIDやSMCとは別の軸で、“より合理的な制御則” を考えたい人向けです。

4. RNNと深層学習の基礎を押さえる本
『深層学習』(岡谷貴之)
SGD、自己符号化器、CNN、RNN、ボルツマンマシンまでを無理なく学べる構成で、第7章に再帰型ニューラルネットがあります。今回の記事でやっている「RNNが何を学習しているか」を日本語でつかむには、とても相性がいいです。

『深層学習』(Ian Goodfellow, Yoshua Bengio, Aaron Courville)
深層学習に必要な数学から、ニューラルネットワークの基礎、CNN、RNN、さらに研究寄りの内容までを広くカバーした世界的な教科書です。理論まで腰を据えてやるならこちらの方が強いです。「RNN側の理解をもっと厳密にしたい」と思ったときの本命です。

この記事との相性で並べるなら
まず読むなら
- 『Pythonによる制御工学入門(改訂2版)』
- 『制御工学(第2版) フィードバック制御の考え方』
この2冊で、速度型PIDとシミュレーションの感覚がかなり整います。
次に読むなら
- 『PID制御 現代制御論の視点から』
- 『スライディングモード制御入門』
この記事の本題である「PID風RNN」「QSM補正」の理解に直接つながります。
RNN側を強くしたいなら
- 『深層学習』(岡谷貴之)
- 『深層学習』(Goodfellow ほか)
前者は入りやすさ、後者は厚みで選ぶ感じです。
迷ったらこの3冊
- 『Pythonによる制御工学入門(改訂2版)』
- 『PID制御 現代制御論の視点から』
- 『スライディングモード制御入門』
この記事の流れにいちばんそのまま接続しやすい3冊です。
コメント